鲁棒PPLS模型及其在过程监控中的应用
2016-08-06陈家益赵忠盖
陈家益,赵忠盖,刘 飞
鲁棒PPLS模型及其在过程监控中的应用
陈家益,赵忠盖,刘飞
(江南大学自动化研究所,轻工过程先进控制教育部重点实验室,江苏 无锡 214122)
摘要:概率偏最小二乘(PPLS)模型建立的条件是主元和误差都服从高斯分布,但是高斯分布的期望和方差容易受到离群点的影响,导致模型的鲁棒性较差。针对 PPLS模型的不足,提出一种鲁棒概率偏最小二乘(RPPLS)方法,用拖尾更宽的T分布代替高斯分布,通过调整自由度参数,使模型对含离群点数据的拟合效果更好。更进一步,将RPPLS引入过程监控中,提出GT2和GSPE两个监控指标,分别监控过程的受控状态以及模型关系的变化。PPLS和RPPLS在TE过程监控的应用结果表明RPPLS不仅能更准确检测故障的产生,而且能更有效降低故障的漏报率。
关键词:鲁棒概率偏最小二乘算法;T分布;参数估值;监控指标;模型
引 言
随着人们对高质量和多品种产品的需求日益增长,工业生产越来越趋向大型化和间歇化,为了保证生产过程的安全平稳运行和产品质量,对过程变量进行全面有效地监控变得非常重要[1-2]。多元统计过程控制(MSPC)方法通过将高维数据投影到低维空间,大大简化和改进了过程的监控程序,在工业监控过程中得到了广泛的应用[3-4]。偏最小二乘(PLS)是常用的统计建模方法,不仅可以完成降维和特征提取,还考虑了输入输出之间的回归关系,从而提高了预测模型的准确性[5-6],但 PLS模型没有考虑到主元和误差的概率分布情况。Li等[7]将概率分布引入PLS模型提出概率偏最小二乘(PPLS)方法,考虑到每个变量的概率分布,在主元和误差都服从高斯分布的条件下,通过求解极大似然函数得到模型参数。但是在工业过程中,现场环境恶劣,检测离群点普遍存在,而高斯分布的期望和方差容易受到离群点的影响,导致建立的模型鲁棒性较差。为了解决这个问题,拖尾更宽的T分布被引入用于代替高斯分布[8-9]。高斯分布是T分布的自由度趋于无穷大时的一种特殊情况,显然不受约束的T分布更能反映实际工程下数据的分布状况。T分布能通过调整自由度的大小改变拖尾宽度,减小中间的概率空间,增加两边的概率空间,从而能够包含更多的离群点,使模型对含离群值数据的拟合效果更好,因此得到广泛应用。Archambeau等[10-11]提出了鲁棒概率主元分析(RPPCA)模型和混合RPPCA模型,Chen等[12]将RPPCA模型推广到处理数据缺失问题并进行了贡献分析,Zhu等[13]提出了鲁棒混合PPCA模型。但是,这些方法主要是针对概率主元分析(PPCA)的改进。
本文首先分析了离群点对PPLS模型的影响,然后提出一种鲁棒概率偏最小二乘(RPPLS)方法,用T分布来代替高斯分布,使生成模型对离群点具有更好的鲁棒性,弥补PPLS模型的不足。考虑到建立RPPLS模型时,不仅模型参数未知,而且有关主元分布的参数,包括自由度、均值和方差均未知,故引入最大期望(EM)算法进行参数估计。更进一步,基于RPPLS模型,通过构建GT2和GSPE两个监控指标,将RPPLS引入到过程监控,通过监控过程的受控状态以及模型关系的变化,判断过程正常运行程度或故障。最后将PPLS和RPPLS分别应用在TE过程监控,对检测故障的准确性和降低故障的漏报率进行对比。
1 PPLS模型
PPLS是一种高斯隐变量模型[14-15],假设经过归一化后数据的过程变量和输出变量分别为:。其中Dx、Dy分别为过程变量和输出变量个数,N为样本采样数,则PPLS模型可以表示如下
其中,P∈RDx×K,C∈RDy×K,K 由式(5)和已知条件,用贝叶斯公式求tn的后验分布 E步 M步 反复迭代E步和M步,直到算法收敛,PPLS模型建立完成,具体步骤参考算法 1。最后考虑到输入输出回归关系,对式(2)取xn的条件期望,将式(6)代入式(2)得到 yn的近似值,计算如下 由式(15)得到xn关于yn的回归系数矩阵如下 算法1 基于PPLS模型的EM算法 (1)输入:X、Y、K。 (2)标准化:X、Y。 σx=1,σy=1,k=0,P=X(:,1:K),P=X(:,1:K)。 (4)计算E步 (5)计算M步 2.1 RPPLS模型 式中,矩阵Σ是正定矩阵,当ν>1,μ为均值向量,当ν>2时,x的协方差矩阵等于vΣ/(v-2)。Γ(·)表示 Gamma函数,其概率密度函数定义为:T分布通过调整自由度ν的大小,可以改变拖尾宽度,当ν∞时,t(ν,μ,Σ)就是N(μ,Σ),所以正态分布只是T分布的一种特殊形式。 将PPLS模型中的高斯分布全部用T分布代替可以得到RPPLS模型,RPPLS模型可以表示成如下形式 其中,系数矩阵P、C,均值μx、μy和PPLS模型一样,而残差满足,主元满足 2.2 极大似然公式推导 直接用T分布计算非常困难,本文引入中间随机变量un[19],当un服从伽马分布,则服从T分布的变量x关于un的条件分布x|un服从正态分布。通过引入un,可以把T分布转化成正态分布计算,具体转化过程如下 由式(18)、式(19)、式(21)、式(22)可以分别得到xn、yn关于tn、un的条件分布 由式(24)、式(25)可以得到xn、yn关于tn、un的联合分布如下 由式(23)、式(24),用贝叶斯公式求tn关于xn、un的后验分布 由于在RPPLS模型中tn、un是两个隐含变量,很难直接用贝叶斯公式求解后验分布,因此本文把p(tn, un| zn;Θ)分成如下两个部分求解,可以得到p(tn, un| zn;Θ)的期望值[10,20] 2.3 EM算法估计模型参数 在E步,根据p(tn, un| zn;Θ)的期望求L(Θ)期望〈L(Θ)〉,然后对〈L(Θ)〉求偏导,求出更新值Θ~。具体求解过程见文献[10],参数的迭代公式如下: E步 其中,A=(WWT+Φ)-1, B=(I+WTΦ-1W)-1。M步 其中,带有波浪号上标的表示更新值,函数ψ(x)=(dlnΓ (x)/dx)。反复迭代E步和M步,直到收敛,RPPLS模型建立完成,EM算法的具体步骤参考算法2。同样考虑到输入输出回归关系,对式(19) 取xn、un的条件期望,并将式(27)代入式(19),可以得到yn的近似值,计算如下 由式(40)得到xn关于yn的回归系数矩阵如下 算法2 基于RPPLS模型的EM算法 (1)输入:X、Y、K、v。 (2)标准化:X、Y。 (4)计算E步 (5)计算M步 2.4 鲁棒性分析 概率偏最小二乘(PPLS)建立的条件是主元和误差都服从高斯分布,但是高斯分布的期望和方差容易受到离群点的影响,导致模型的鲁棒性较差。本文用T分布来代替正态分布,在PPLS的基础上提出一种鲁棒RPPLS方法,由于T分布能调节参数自由度的大小从而改变拖尾宽度,使模型对离群点的鲁棒性更好。 为了验证T分布对含离群点数据的拟合效果更好,下面给出一个分别用正态分布和T分布拟合离群点数据的仿真例子:首先随机生成一组满足μ=0,σ=0的标准正态分布数据X∈R1×100,然后在概率空间右半边分别添加 1%、3%、5%、7%的离群点,再分别用正态分布和T分布去拟合添加了离群点的数据,拟合曲线受离群点影响变化如图1、图2所示。 图1 正态分布拟合离群点数据的效果Fig.1 Fitting chart of outliers by normal distribution 图2 T分布拟合离群点数据的效果Fig.2 Fitting chart of different outliers by T distribution 比较图1、图2可得:当用正态分布去拟合含有离群点数据时,随着离群点的增加,曲线向右移动并且变得矮胖,经计算可以得到μ1=0.1884,σ1=1.2029,μ2=0.5332,σ2=2.8396,μ3=0.9983,σ3=4.4623,μ4=1.1813,σ4=4.6438,说明正态分布只能通过调整均值和方差才能拟合含离群点数据,这样必然导致拟合效果不好;而用T分布去拟合含有离群点数据时,T分布可以通过调整自由度v1=6.0222,v2=2.5099,v3=1.7787,v4=1.5550,使拟合曲线即使在含较多离群点时,依然能够得到较好的拟合效果,这就表明T分布比正态分布的鲁棒性更好。 3.1 对主元空间的监控 主元反映了影响过程变化的主要因素,RPPLS模型根据对主元的监控,来判断过程的受控状态,类似于PLS监控算法中的T2监控指标。参考文献[21],按照T2定义一个T2的扩展监控指标GT2,这里采用 tn后验的期望值〈tn〉= E(tn|zn,un; Θ)= BWTΦ-1(zn-μ)来代替tn。而由式(23)可得tn服从N(0,IK/un),其中un是随机变量,这里采用期望值〈un〉代替,由式(20)及伽马分布的性质可得〈un〉=1,故tn近似服从N(0,IK),并用其标准差进行规范化,则GT2定义如下 3.2 对残差空间的监控 残差反映了过程变量与模型的拟合程度,本文通过对残差空间的监控,来判断过程工作情况,类似PLS监控算法中的SPE监控指标。同样仿效文献[21],定义一个基于马氏距离的SPE的扩展监控指标 GSPE[22],这里同样可以用 en的期望值〈en〉= E(en|zn,un; Θ)=(I-WBWTΦ-1)(zn-μ)代替en,则GSPE可以定义如下 田纳西-伊斯曼过程(TEP)是基于真实工业过程的仿真平台,因其能对各种监控方法有效性进行评价而被广泛应用。该过程包括过程变量、成分变量和控制变量共52个可测量变量以及21种预设定的故障模式,TE过程的详细介绍见文献[23]。本文建立模型的500组正常数据是通过每次仿真运行25 h,每间隔3 min对变量采样一次得到;采用同样的采样率,而每次仿真运行48 h,得到960组用于监控的故障数据。本文以故障 5为例,对 PPLS和RPPLS的监控效果进行比较。故障5在采样时刻160处引入,首先冷凝器冷却水入口温度产生一个阶跃变化,然后冷凝器冷却水流量受到影响也产生阶跃变化,使冷凝器出口流量增加,进而导致汽液分离器的温度和分离器冷却水出口温度均升高。当故障发生后,控制回路能做出反应,通过调节控制器使分离器中的温度返回到正常值。当达到新的稳定状态后,故障检测指标不能保持,而是要回到正常状态。 在建立PPLS和RPPLS模型时,TE过程共有52个测量变量,其中过程测量变量 XMEAS(1)~XMEAS(23)表示A进料(流1)、D进料(流2)、E进料(流3)等过程参数,成分测量变量XMEAS(22)~XMEAS(41)分别表示流6、流9和流11的进料成分,操作测量变量XMV(1)~XMV(11)表示D进料量(流2)、E进料(流3)、A进料(流1)等控制参数。参考文献[24],本文选取 XMEAS(1)~XMEAS(36)和XMV(1)~XMV(11)共47个为输入变量X,而选取流11的成分变量XMEAS(37)~XMEAS(41)共5个为输出变量 Y。由交叉验证方法,这里主元个数都选取为14个。为了验证RPPLS模型的鲁棒性,首先,将500个正常数据归一化,然后在随机选取3% 共15个正常数据样本点,并使每个变量在该15个样本点原值的基础上扩大10倍得到15个离群点。本文根据“3σ准则”定义离群点:与平均值的偏差超过3倍标准差的测定值称为离群值。这里仅画出变量x1的正常数据和离群数据如图3所示。 图3(a)为正常数据的分布情况,数据规律分布,上下波动不大;而当加入离群点之后,数据如图3(b)所示,在原数据基础上放大10倍后得到15个数据点不仅远离正常数据,而且超过3倍的标准差,即得到了15个离群点。对每个变量做同样处理,得到含离群值数据。 然后分别用正常数据和含有离群点的数据建立PPLS和RPPLS模型。为了便于比较两种情况下PPLS和RPPLS模型的鲁棒性,本文定义回归系数矩阵M的均方根误差(RMSE)表达式如下 式中,M0表示用含离群点建立模型的回归系数矩阵;M1表示用正常数据建立模型的系数矩阵;RMSE表示模型的稳定程度,RMSE越小,模型的稳定性越高,鲁棒性越好。 首先分别应用正常数据和含离群值数据建立PPLS和RPPLS模型,得到正常数据和含离群值数据模型下的系数回归矩阵,最后将回归矩阵代入式(44),得到表1。 表1 PPLS和RPPLS在3%离群点时回归系数矩阵M的RMSETable 1 RMSE of matrix M by PPLS and RPPLS with 3% outliers 由表1可得,RPPLS在离群点为0和3%情况下回归系数矩阵M的RMSE远远小于PPLS,表明RPPLS在离群点情况下建立的模型和正常数据建立的模型偏离程度较小,即离群点对RPPLS影响较小;而PPLS在离群点情况下建立的模型和正常数据建立的模型偏离程度较大,即离群点对PPLS影响较大,也就是RPPLS比PPLS鲁棒性更好。 图3 变量x1正常数据和含离群点数据Fig.3 Data charts for variable x1with normal data and outliers data 然后将含 3%离群点数据建立的 PPLS和RPPLS模型应用于TE过程监控。将960组故障数据归一化后分别代入式(42)、式(43),得到PPLS和RPPLS模型的监控图分别如图4、图5所示。 比较图4、图5可得:图4(a)中GT2值和图4(b) 中GSPE值分别在采样时刻175和179超过控制线,而虽然图5(a)中GT2值也是在175超过控制线,但是图5(b)中GSPE值在采样时刻163超过控制线,故障5的故障引入是在采样时刻160,这就表明RPPLS模型能较及时准确地判断故障的发生。图4(a)的漏报率为0.8177,图4(b)的漏报率为0.8402,而图 5(a)的漏报率为 0.7453,图 5(b)的漏报率为0.7715,由此可得相较于PPLS模型,RPPLS能显著降低漏报率。从故障持续时间来看,图4(a)为146,图4(b)为128,而图5(a)为204,图5(b)为183,RPPLS的故障的持续时间比PPLS多出大约 50个采样时间,RPPLS故障持续时间更长,有利于现场监控人员及时找出故障原因,实现故障诊断。 图4 基于PPLS对故障五的监控Fig.4 Monitoring charts for fault 5 based on PPLS 图5 基于RPPLS对故障五的监控Fig.5 Monitoring charts for fault 5 based on RPPLS 表3 TE过程故障描述Table 2 Process fault description in TE process 最后分别用PPLS、RPPCA和RPPLS对TE过程前13种故障模式进行监控,故障描述见表2,故障均在采样时刻160引入,监控效果如表3、表4、表 5所示,表中综合了两个监控指标的检测时间(DT)、漏报率(MAR)和故障持续时间(FDT)3个方面。在13种故障中,故障3和9难以检测且对过程影响较小,PPLS难以检测出来,而RPPLS虽然漏报率很高,但却能较准确检测出来。而对于故障1、2、4、6、7、13,RPPLS比PPLS漏报率更低,但不明显。对于故障5、8,RPPLS比PPLS的漏报率降低6%,而对于故障10、11、12的漏报率更是降低高达10%以上。同样比较RPPCA与PPLS模型的监控效果,也能得出采用 T分布的 RPPCA比PPLS的检测效果更好。而对比采用T分布的RPPLS 和T分布的RPPCA,由于都采用T分布,故模型对离群数据处理的效果都比较好,但是 RPPLS的GT2指标要优于RPPCA。 表3 基于PPLS对TE过程的监控结果Table 3 Monitoring results in TE process based on PPLS 表4 基于RPPCA对TE过程的监控结果Table 4 Monitoring results in TE process based on RPPCA 表5 基于RPPLS对TE过程的监控结果Table 5 Monitoring results in TE process based on RPPLS 考虑离群点对模型的影响,本文在PPLS模型中引入T分布,提出RPPLS模型,能够较好地克服离群点对模型的影响,提高了模型的鲁棒性。通过PPLS和RPPLS在TE过程中的监控应用表明,采用EM算法能够较准确地估计模型的未知参数(主元和误差的均值、方差和自由度)。本文提出GT2和GSPE两个监控指标,能够准确及时地反映出监控过程的受控状态以及模型关系的变化。 References [1] KANO M, NAKAGAWA Y. Data-based process monitoring process control and quality improvement: recent developments and applications in steel industry[J]. Computers & Chemical Engineering, 2008, 32(1/2): 12-24. DOI: 10.1016/j.compchemeng.2007.07.005. [2] 李秀喜, 袁延江. 基于流程模拟的化工故障检测技术[J].化工学报, 2014, 65(11): 4472-4476.DOI: 10.3969/j.issn.0438-1157.2014.11036. LI X X, YUAN Y J. Chemical process fault detection technology based on process simulation[J].CIESC Journal, 2014, 65(11): 4472-4476.DOI: 10.3969/j.issn.0438-1157.2014.11.036. [3] SIMOGLOU A, MARTIN E B, MORRIS A J. Multivariate statistical process control of an industrial process fluidised-bed reactor[J]. Control Engineering Practice, 2000, 8(8): 893-909. DOI: 10.1016/S0967-0661(00)00015-0. [4] 王海清, 宋执环, 王慧. PCA过程监测方法的故障检测行为分析[J].化 工 学 报 , 2002, 53(3): 297-301.DOI: 10.3321/j.issn: 0438-1157.2002.03.016. WANG H Q, SONG Z H, WANG H. Fault detection behavior analysis of PCA based process monimring approach[J]. Journal of Chemical Industry and Engineering(China), 2002, 53(3): 297-301.DOI: 10.3321/j.issn: 0438-1157. 2002.03.016. [5] WOLD S, SJÖSTRÖMA M, ERIKSSONB L. PLS-regression: a basic tool of chemometrics[J]. Chemometrics and Intelligent Laboratory Systems, 2001, 58(2): 109-130. DOI: 10.1016/S0169-7439(01)00155-1. [6] MEHMOOD T, LILAND K H, SNIPEN L, et al. A review of variable selection methods in partial least squares regression[J]. Chemometrics and Intelligent Laboratory Systems, 2012, 118: 62-69. DOI: 10.1016/j.chemolab.2012.07.010. [7] LI S, GAO J, NYAGILO J O, et al. Probabilistic partial least square regression: a robust model for quantitative analysis of Raman spectroscopy data[C]// IEEE International Conference on Bioinformatics and Biomedicine. Atlanta: IEEE, 2011: 526-530. [8] LANGE K L, LITTLE R J A, TAYLOR J M G. Robust statistical modeling using the t distribution[J]. Journal of the American Statistical Association, 1989, 84(408): 881-896. DOI: 10.1080/01621459.1989.10478852. [9] SHOHAM S. Robust clustering by deterministic agglomeration EM of mixtures of multivariate t-distributions[J]. Pattern Recognition Society, 2002, 35(5): 1127-1142. DOI: 10.1016/S0031-3203(01)00080-2. [10] ARCHAMBEAU C, DELANNAY N, VERLEYSEN M. Robust probabilistic projections[C]//Proceedings of 23rd International Conference on Machine Learning. New York: ACM, 2006: 33-40. [11] ARCHAMBEAU C, DELANNAY N, VERLEYSEN M. Mixtures of robust probabilistic principal component analyzers[J]. Neurocomputing, 2008, 71(7/8/9): 1274-1282. DOI: 10.1016/j. neucom.2007.11.029. [12] CHEN T, MARTIN E, MONTAGUE G. Robust probabilistic PCA with missing data and contribution analysis for outlier detection[J]. Computational Statistics and Data Analysis, 2009, 53(10): 3706-3716. DOI: 10.1016/j.csda.2009.03.014. [13] ZHU J L, GE Z Q, SONG Z H. Robust modeling of mixture probabilistic principal component analysis and process monitoring application[J]. AIChE Journal, 2014, 60(6): 2143-2157. DOI: 10.1002/aic.14419. [14] SILVA R, SCHEINES R, GLYMOURl C, et al. Learning the structure of linear latent variable models[J]. Machine Learning Research, 2006, 7(2): 191-246. [15] KOURTI T. Application of latent variable methods to process control and multivariate statistical process control in industry[J]. International Journal of Adaptive Control and Signal Processing, 2005, 19(4): 213-246. DOI: 10.1002/acs.859. [16] STOICA P, XU L Z, LI J. A new type of parameter estimation algorithm for missing data problems[J]. Statistics & Probability Letters, 2005, 75(3): 219-229. DOI: 10.1016/j.spl.2005.05.018. [17] WU C F. On the convergence properties of the EM algorithm[J]. The Annals of Statistics, 1983, 11(1): 95-103. [18] MURPHY K P. Machine Learning: A Probabilistic Perspective[M]. London: MIT Press, 2012: 46-49. [19] LIU C H, RUBIN D B. ML estimation of the t distribution using EM and its extensions, ECM and ECME[J]. Statistica Sinica, 1995, 5(1): 19-39. [20] BISHOP C M. Pattern Recognition and Machine Learning[M]. New York : Springer Press, 2006: 91-93. [21] KIM D, LEE I B. Process monitoring based on probabilistic PCA[J]. Chemometrics and Intelligent Laboratory Systems, 2003, 67(2): 109-123. DOI: 10.1016/S0169-7439(03)00063-7. [22] 马贺贺, 胡益, 侍洪波.基于马氏距离局部离群因子方法的复杂化工过程故障检测[J].化工学报, 2013, 64(5): 1675-1682.DOI: 10.3969/j.issn.0438-1157.2013.05.02. MA H H, HU Y, SHI H B. Fault detection of complex chemical processes using Mahalanobis distance-based local outlier factor[J].CIESC Journal, 2013, 64(5): 1675-1682. DOI: 10.3969/j.issn. 0438-1157.2013.05.02. [23] CHIANG L H, RUSSELL E L, BRAATZ R D. Fault Detection and Diagnosis in Industrial Systems[M]. London: Springer London, 2001: 99-106. [24] QIN S J, ZHENG Y Y. Quality-relevant and process-relevant fault monitoring with concurrent projection to latent structures[J]. AIChE Journal, 2013, 59(2): 496-504.DOI: 10.1002/aic.13959. 2015-09-11收到初稿,2016-04-29收到修改稿。 联系人:赵忠盖。第一作者:陈家益(1990—),男,硕士研究生。 Received date: 2015-09-11. 中图分类号:TP 277 文献标志码:A 文章编号:0438—1157(2016)07—2907—09 DOI:10.11949/j.issn.0438-1157.20151439 基金项目:国家自然科学基金项目(61573169);江苏省六大人才高峰项目(2014-ZBZZ-010)。 Corresponding author:ZHAO Zhonggai,gaizihao@ jiangnan.edu.cn supported by the National Natural Science Foundation of China (61573169) and the Six Talent Peaks Project of Jiangsu Province (2014-ZBZZ-010). Robust PPLS model and its applications in process monitoring CHEN Jiayi, ZHAO Zhonggai, LIU Fei Abstract:A probability model can be developed by probabilistic partial least squares (PPLS) under the conditions that both principal components and errors satisfy Gaussian distribution. However, the expectation and variance of the Gaussian distribution is susceptible to outliers. As a result, the model is not robust for the real industrial process. This paper improves the robustness of the PPLS model based on the assumption that the raw data satisfy T distribution rather than Gaussian distribution. By adjusting the freedom degree of T distribution, the proposed robust probabilistic partial least squares (RPPLS) model can overcome the shortcomings of PPLS model. Furthermore, on the basis of RPPLS model, two monitoring indicators GT2and GSPE are proposed to monitor the process state and the model changes, respectively. Comparing the monitoring performance in the TE process based on PPLS and RPPLS shows that RPPLS is more effective than PPLS in terms of the fault accuracy and the missing alarm rate. Key words:robust probabilistic partial least squares algorithm;T distribution;parameter estimation;monitoring indices;model
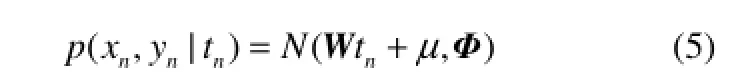









2 RPPLS 模型
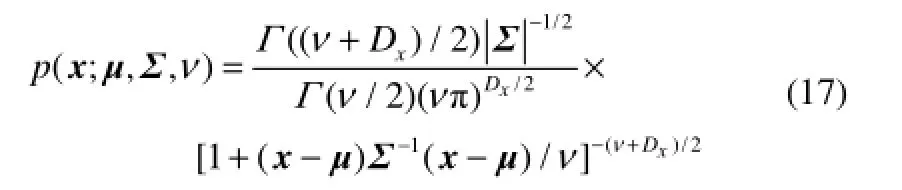









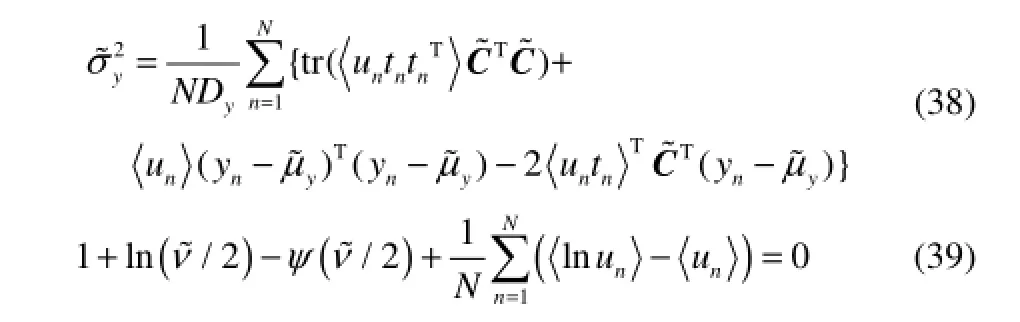






3 基于RPPLS模型的监控


4 仿真实例









5 结 论
(Key Laboratory of Advanced Process Control for Light Industry (Ministry of Education), Institute of Automation, Jiangnan University, Wuxi 214122, Jiangsu, China)
