基于四维光场数据的深度估计算法
2016-08-05陈佃文赵松年
陈佃文, 邱 钧, 刘 畅, 赵松年
(1. 北京信息科技大学 应用数学研究所, 北京 100101; 2. 北京大学 数学科学学院, 北京 100871;3. 中国科学院大气物理研究所, 北京 100029)
基于四维光场数据的深度估计算法
陈佃文1, 邱钧1, 刘畅2, 赵松年3
(1. 北京信息科技大学 应用数学研究所, 北京 100101; 2. 北京大学 数学科学学院, 北京 100871;3. 中国科学院大气物理研究所, 北京 100029)
摘要:基于光场数据的四维结构信息, 提出一种具有像素级精度的深度估计算法, 为三维表面重构提供精确的深度信息. 首先, 由光场数据中视差与视点位移的等比关系, 给出基于光场数据的区域匹配算法, 得到初步视差图. 其次, 基于区域匹配的误差来源建立新的置信函数, 对误匹配像素进行分类并优化, 得到高精度的深度图. 采用公开的HCI标准光场数据和实拍的光场数据进行了算法验证和成像精度评测. 结果表明, 与已有的算法相比, 新算法具有更好的计算精度, 在平滑区域和边缘遮挡区域有较好效果.
关键词:深度估计; 光场; 视差图; 区域匹配
0引言
光场是空间中光线辐照度信息的集合, 是对场景发出的光线的形式化描述. 最初被提出来用于形式化描述光线信息的七维全光函数L(x,y,z,θ,φ,λ,t), 描述了空间中任意波长的光线在任意时刻的辐照度信息[1]. Levoy, Gortler等人提出了光场的双平面参数化表征[2-3], 即四维光场L(x,y,u,v). 基于四维光场的理论, Ng和Levoy等人设计出基于微透镜阵列采集系统的手持相机[4], 实现了单次曝光下的四维光场数据采集和重聚焦成像. 四维光场数据包含光线的空间和角度信息, 可用于场景的深度信息获取与三维重构.
由光场数据获取场景的深度信息可以通过物点的视差计算得到, 或者由聚焦堆栈获取. 物点的视差获取方法主要分为两类:一类基于多视点像素匹配, 该方法将四维光场重排得到一组不同视点下的二维图像, 通过像素匹配获取任意物点在所有视点下的视差信息[5-7]; 另一类基于极线图(EpipolarImages)的性质, 物点对应的像素在极线图呈直线状分布, 计算梯度方向[8-9]或者尺度变换求极值[10]得到极线图中直线的斜率, 进而获取视差. 由聚焦堆栈中获取深度的基本思想是, 物点清晰成像时对应的聚焦堆栈为该物点的深度信息[11-12].
本文在四维光场数据中, 利用区域匹配方法, 计算出相邻视点图像之间的视差图(Disparity Map), 在此基础上, 利用一种新的置信函数将获取的视差图中的误差分类, 并对每种误差采用相应的优化准则进行优化, 精确地计算出每个像点对应的物体的深度信息. 同时对本文提出的算法进行了测试, 并给出相应的实验结果和分析.
1四维光场数据中视差与深度的关系
与普通相机的结构不同, 基于微透镜阵列的光场相机在主透镜(Main Lens)和探测器(Sensor)之间放置微透镜阵列(Microlens Array), 如图 1 所示. 主透镜平面和探测器平面关于微透镜共轭, 使得一个探测器单元对应四维光场的一条光线. 因此探测器记录了由主透镜平面和微透镜阵列平面参数化的光场数据, 实现了四维光场数据的采集.
考察光场相机中视差与深度的关系. 在图 2 中,u1,u2为(u,v)平面上的视点,B为视点距离,A1为物点A对应的像点,s为物点A在视点u1,u2下在(x,y)平面上的视差.F为(x,y)平面到(u,v)平面之间的距离,F1为像点A1到(u,v)平面的距离.
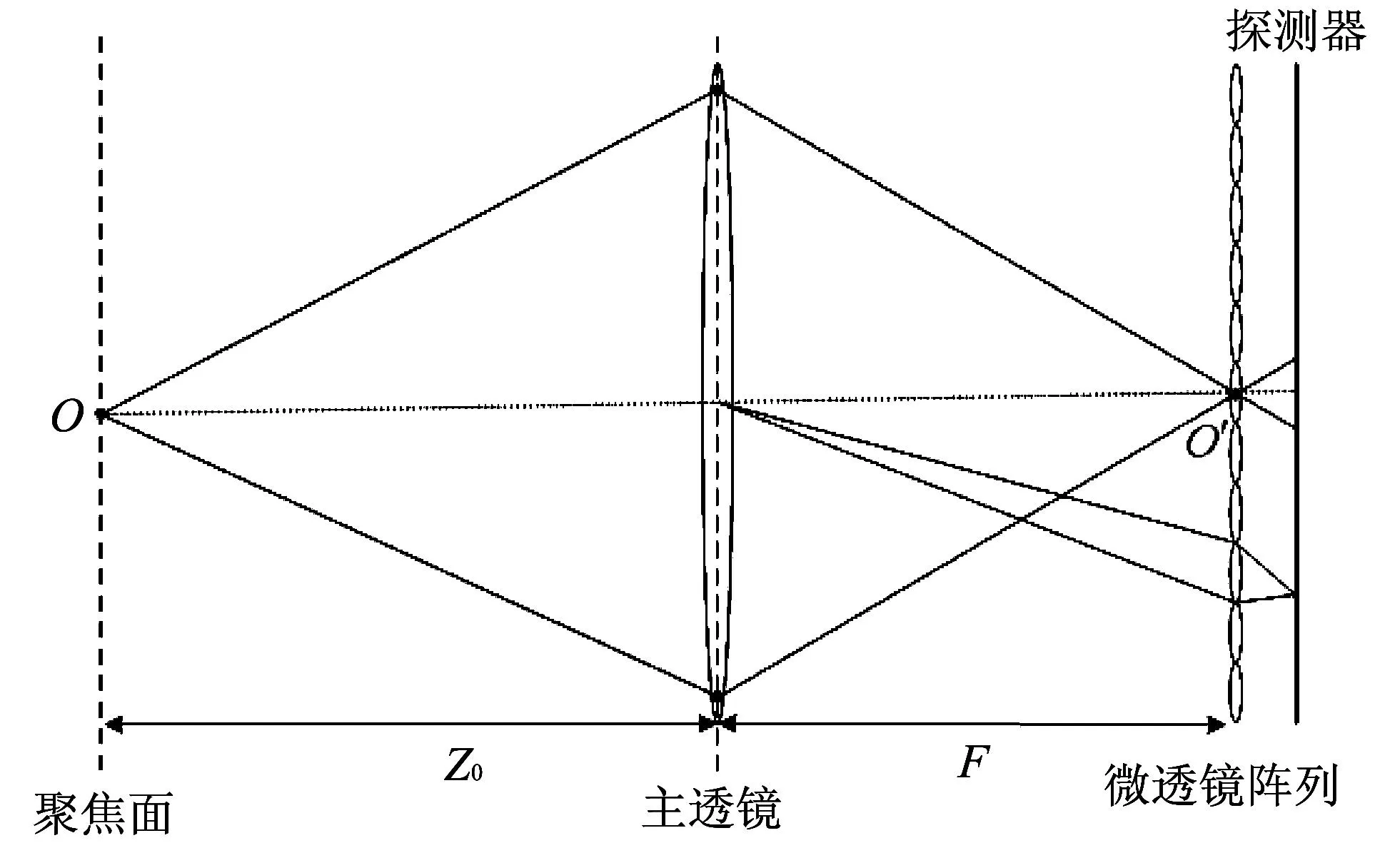
图 1 基于微透镜列的光场相机结构示意图Fig.1 Diagram of light field camera with microlens array
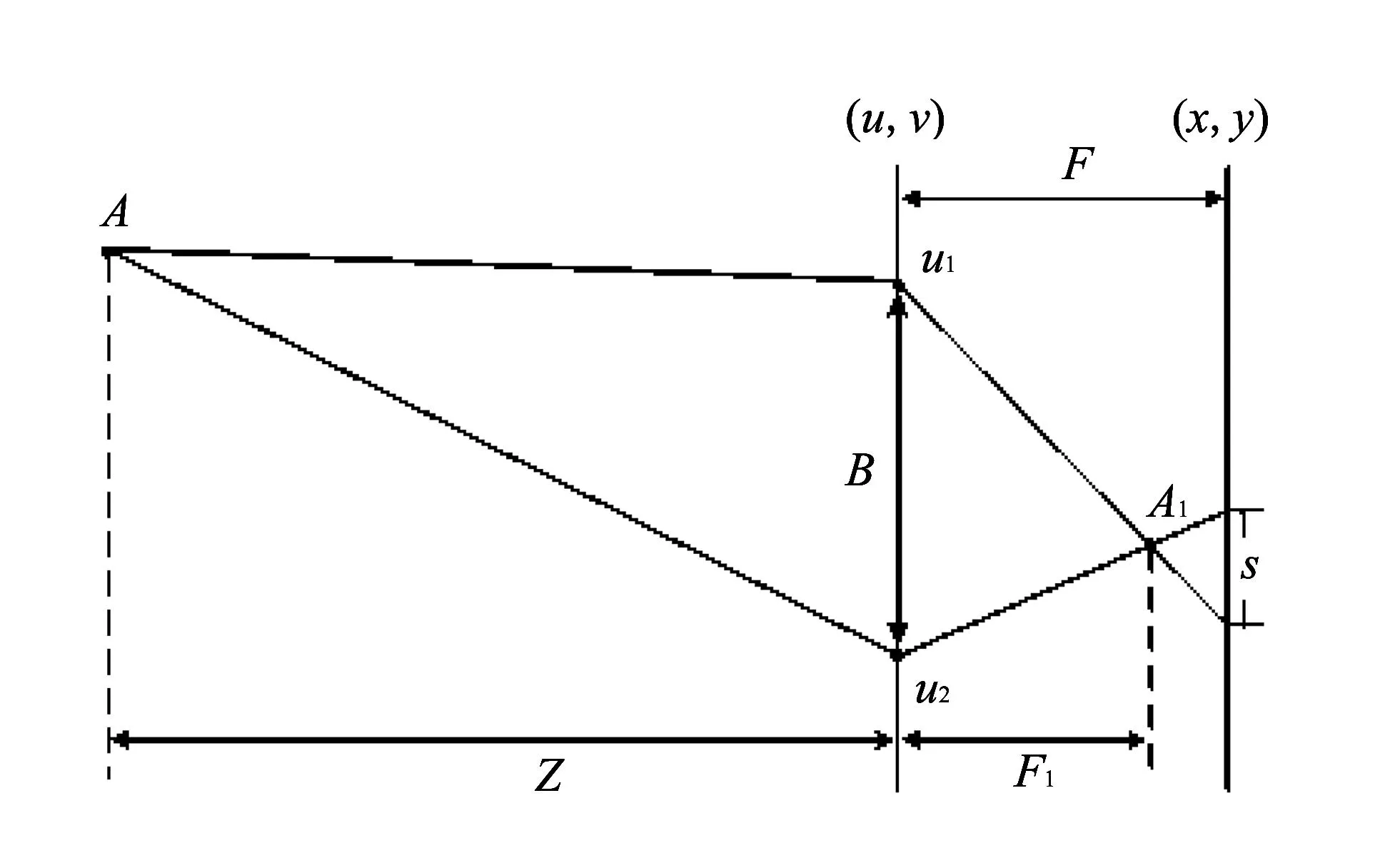
图 2 四维光场中视差与深度的关系示意图Fig.2 Diagram of the relationship between disparity and depth in 4D light field
由图 2 可知, 物点A在视点u1,u2下的视差s与视点距离B满足
(1)
主透镜焦距为f, 物点A的深度为Z, 主透镜的聚焦深度为Z0, 高斯成像公式为
(2)
(3)
由式(1)~式(3)得视差和深度的关系式
(4)
由式(4)可知, 视差与视点位移成等比关系. 在四维光场数据中, 令B为相邻视点之间的距离(光场采样的视点间隔),s为物点x在相邻视点下的视差. 两个视点的距离为kB(k=1,2,…)时, 物点x对应的视差为ks(k=1,2,…).
2深度估计
在光场数据中, 利用视差与视点位移的等比关系建立区域匹配算法, 得到相邻视差的初步视差图. 对初步视差图中的误匹配像素, 基于区域匹配的误差来源建立新的置信函数, 对误匹配像素进行分类, 优化视差图得到高精度的深度图.
2.1初步视差的获取
以中心视点图像L(x,y,u0,v0)为参照, 利用区域匹配算法获取L(x,y,u0,v0)对应的视差图s(x,y).
在四维光场L(x,y,u,v)中, 基于视差与视点位移的等比关系, 建立视差s(x,y)的目标函数
(5)

式中:(u0,v0)为中心视点位置; (ui,vj)为任意视点位置, Δui=ui-u0, Δvj=vj-v0;E(s)为中心视图像素(x,y)在视差为s时与所有视点图像中对应像素的差异累加和的度量函数.
由于图像区域的像素值相近, 以及噪声等因素, 单个像素点作为匹配基元的匹配方法鲁棒性较差. 本文采用以目标像素点为中心的矩形区域来代替单个像素点作为匹配基元, 提高匹配方法的鲁棒性. 采用区域匹配方法, 视差s(x,y)的目标函数为
(6)
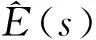

(7)
2.2置信函数与视差优化
由式(7)获取的初步视差图, 在平滑区域和遮挡区域存在误匹配. 其原因是, 平滑区域和遮挡区域在匹配过程中, 其目标函数中存在较多与最小值相等或相近的函数值, 误匹配概率较大. 本文建立关于视差的置信函数, 旨在标识出误匹配区域, 进而设置阈值对其进行分类. 在此基础上, 对平滑区域, 采用TV-L1模型进行平滑处理; 对遮挡区域, 采用二次匹配的方法获取精确的视差.
建立关于视差图s(x,y)的置信函数, 来刻画区域匹配结果的置信度. 定义如下
(8)
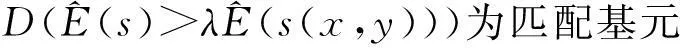
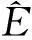
(9)
式中:label(x,y)为像素(x,y)的分类标签, 0为准确匹配区域, 1为平滑区域, 2为遮挡区域.
对于平滑区域, 本文采用TV-L1模型进行优化
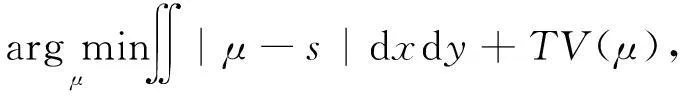
(10)
式中:μ(x,y)是优化后的估计视差图;TV(μ)为视差图μ(x,y)的全变分.
对于遮挡区域, 本文通过视点平移和遮挡的关系, 筛选出可用于遮挡区域深度计算的视点. 计算遮挡区域在该组视点下关于视差的目标函数, 获取视差.
图 3 给出了该分类优化方法对初步视差图的优化结果, 调整参数和阈值选取为

图 3 视差图的优化Fig.3 Optimization of disparity map
2.3深度计算
基于优化得到的视差图μ(x,y), 利用式(4)计算得到场景的深度图
(11)
3实验结果
本文算法验证与数据实验设计如下:第一组实验采用Heidelberg Collaboratory for Image Processing (HCI) 公开的标准光场数据[13], 给出了相关算法的误差比较与分析. 第二组实验采用相机实拍, 利用三轴平移台获取实测光场数据, 给出实际场景的深度估计和三维点云图.
3.1 HCI光场数据试验
本文的算法测试和精度比较采用了12组HCI基准光场数据, 其中7组为模拟光场数据, 利用计算机模拟合成, 5组为实测光场数据, 通过相机实拍获取. 该基准光场数据对全球科研机构与人员开放, 用于相关算法的测试. 详细描述参阅文献[13]. 实验结果及误差分析如图 4 所示.

图 4 HCI模拟光场数据实验结果Fig.4 Results for some synthetic light fields of HCI datasets
图 4 给出2组HCI模拟光场数据的试验结果. 误差图中, 当估计视差的相对误差小于0.05时为白色, 大于0.05时为黑色. 在深度连续变化区域, 本文提出的算法具有较高的计算精度, 对边缘遮挡区域也有较好的深度估计结果.
图 5 中为2组HCI实测光场数据的实验结果. HCI通过单相机多次采集图像的方式获取实测光场数据[13]. 可以看出, 对于实际场景, 本文算法具有很好的深度分辨能力.
表 1 中在三方面给出HCI光场数据实验的结果分析, 包括平均绝对误差(Mean Absolute Error, MAE), 平均平方误差(Mean Squared Error , MSE )和误匹配像素的百分比(Percentage of Bad Matching Pixels , BMP). 结果表明, 利用本文提出的算法估计的视差图, 具有明显误差的像素所占比例较少.

图 5 HCI实测光场数据实验结果Fig.5 Results for some real light fields of HCI datasets
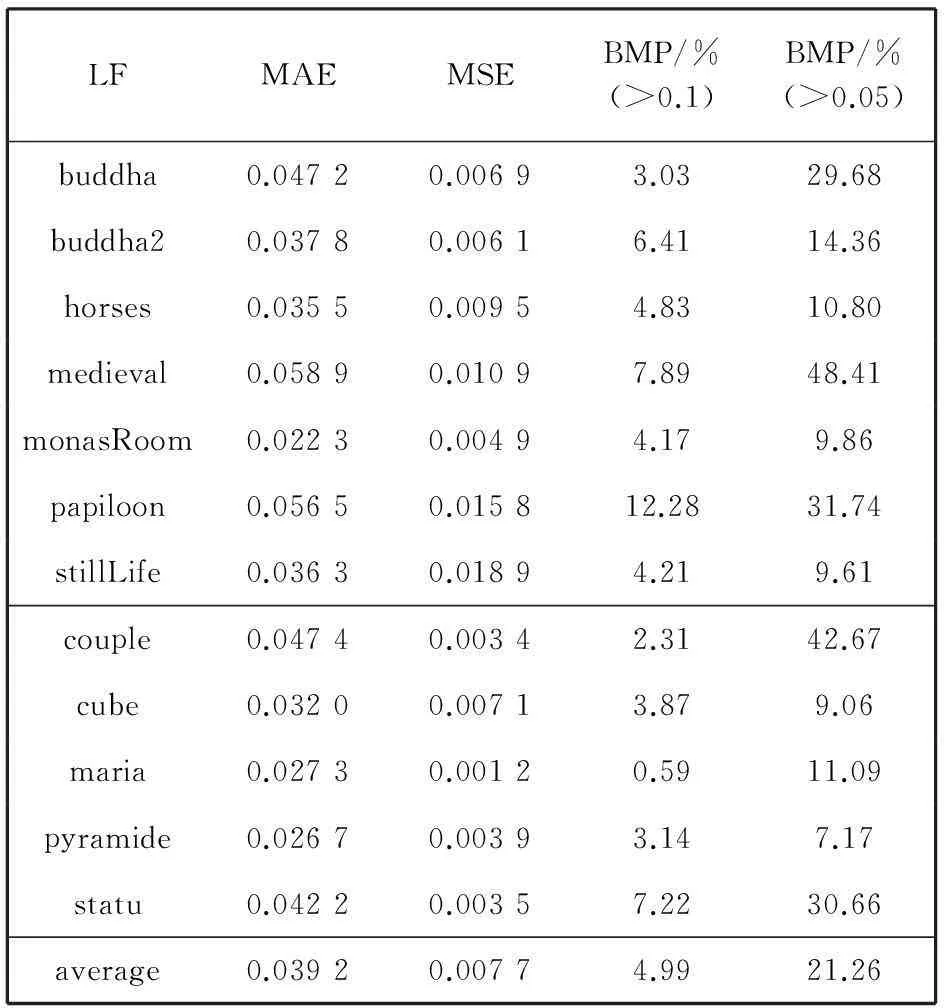
LFMAEMSEBMP/%(>0.1)BMP/%(>0.05)buddha0.04720.00693.0329.68buddha20.03780.00616.4114.36horses0.03550.00954.8310.80medieval0.05890.01097.8948.41monasRoom0.02230.00494.179.86papiloon0.05650.015812.2831.74stillLife0.03630.01894.219.61couple0.04740.00342.3142.67cube0.03200.00713.879.06maria0.02730.00120.5911.09pyramide0.02670.00393.147.17statu0.04220.00357.2230.66average0.03920.00774.9921.26
表 2 中给出了本文提出的算法与已有的算法在计算精度方面的比较结果. HCI官方网站给出了已有算法在平均平方误差(MSE )意义下计算精度的定量分析. 其中EPI_L(G/S/C)类型的算法是利用极线图的结构计算深度信息; ST_AV_L(G/S)是基于立体视觉, 利用所有的视点计算深度的方法; ST_CH_L(G/S)类型的方法是利用穿过中心视点的水平和竖直方向上的视点进行深度估计. 由表2中的数据可知, 本文提出算法的结果在平均平方误差方面(MSE)优于HCI官方网站公布的已有算法的结果.
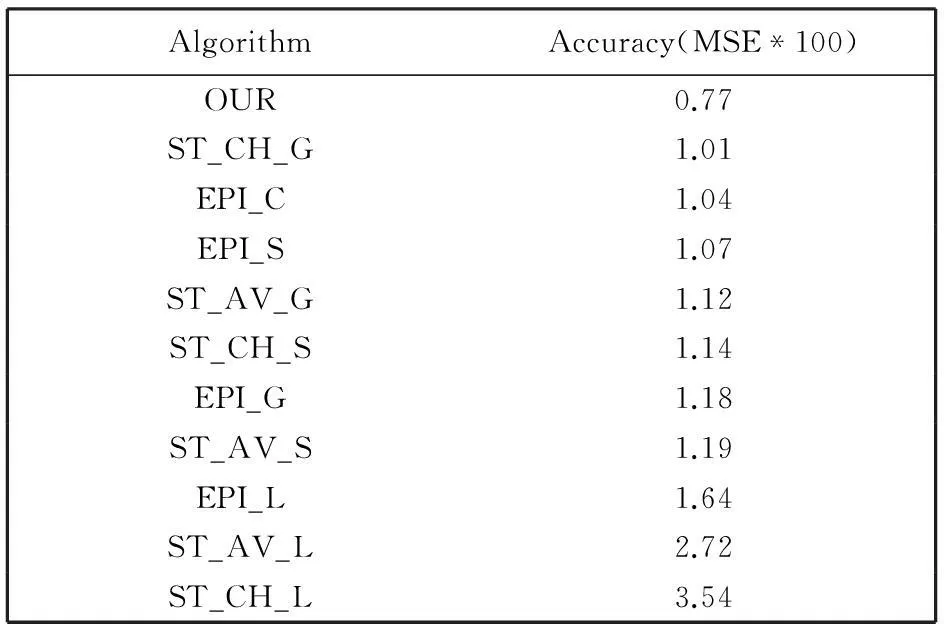
表 2 算法精度
通过上述实验结果及误差分析可知, 采用二次匹配和分类优化方法有效降低了平滑区域和边缘遮挡区域的深度估计误差. 与已有的算法相比, 新算法具有更好的计算精度.
3.2实测光场数据实验
本文设计了光场数据采集的过程. 采用SONY NEX-5C相机, 固定于精度为1 μm的GCM-125302AM三轴平移台上. 以Δcam=500 μm为视点间隔, 采集同一平面内9×9视点阵列中每个视点位置下的二维图像, 获取四维光场数据. 同时给出该实际场景的深度估计结果和三维点云图.
实验过程中, 相机获取的单幅图像初始分辨率为4 592×3 056. 本文采用包含物体信息的图像中心区域用于计算, 其中单幅Dog图像的分辨率为1 500×1 200, 单幅Flower图像的分辨率为1 600×1 400, 单幅Fairies图像的分辨率为2 000×1 600.
图 6 中给出了本文实际采集的光场数据的实验结果. 结果表明, 本文提出的算法对平滑区域和边缘区域具有很好的深度估计效果, 利用计算出的深度信息, 可以实现较为精确的窄视角下三维表面重构.

图 6 实测光场数据实验结果Fig.6 Results for some light fields of measured dataset
4结语
本文利用四维光场数据对场景进行估计深度, 提出一种具有像素级精度的深度估计方法. 该方法利用光场数据中视差与视点位移的等比关系, 以区域匹配方法为基础, 与四维光场的结构特点结合起来, 精确地计算出相邻视图之间的视差图. 此外, 本文基于区域匹配的误差来源建立新的置信函数, 对误匹配像素进行分类, 优化提高深度计算精度. 本文方法可进一步用于光场相机的深度信息获取, 以及为三维场景重构提供精确的深度信息.
参考文献:
[1]AdelsonE H, Bergen J R. The plenoptic function and the elements of early vision[J]. Computational Models of Visual Processing, 1991: 3-20.
[2]Levoy M,Hanrahan P. Light field rendering[J]. In Siggraph 96, 1996:31-42.
[3]Gortler S J, Grzeszczuk R, Szeliski R, et al. The lumigraph[J]. In Siggraph 96,1996:43-54.
[4]Ren N, Levoy M, Bredif M, et al. Light field photography with a hand-held plenoptic camera[J]. Stanford Tech Report CTSR, 2005(2):1-10.
[5]BishopTE,FavaroP.Plenopticdepthestimationfrommultiplealiasedviews[C].IEEE12thInternationalConferenceonComputerVisionWorkshops, 2009:1622-1629.
[6]AtanassovK,GomaS,RamachandraV,etal.Content-baseddepthestimationinfocusedplenopticcamera[J].SPIE-IS&TElectronicImaging, 2009, 7864, 78640G:1-10.
[7]OhashiK,TakahashiK,FujiiT.Jointestimationofhighresolutionimagesanddepthmapsfromlightfieldcameras[J].StereoscopicDisplays&ApplicationsXXV, 2014, 9011(12):2978-2982.
[8]WannerS,GoldlueckeB.Globallyconsistentdepthlabelingof4Dlightfields[C].IEEEConferenceonComputerVisionandPatternRecognition(CVPR), 2012, 4:1-8.
[9]LukeJP,RosaF,Marichal-HernandezJG,etal.Depthfromlightfieldsanalyzing4Dlocalstructure[J].JournalofDisplayTechnology,IEEE, 2013, 11(11):900-907.
[10]TosicI,BerknerK.Lightfieldscale-depthspacetransformfordensedepthestimation[C]. 2014IEEEConferenceonComputerVisionandPatternRecognitionWorkshops(CVPRW), 2014:441-448.
[11]肖相国, 王忠厚, 孙传东, 等. 基于光场摄像技术的对焦测距方法的研究[J].光子学报, 2009, 37(12): 2539-2543.
XiaoXiangguo,WangZhonghou,SunChuandong,etal.Arangefocusingmeasurementtechnologybasedonlightfieldphotography[J].ActaPhotonicaSinica, 2009, 37(12):2539-2543. (inChinese)
[12]杨德刚, 肖照林, 杨恒, 等. 基于光场分析的多线索融合深度估计方法[J]. 计算机学报, 2014, 37(97):1-15.
YangDegang,XiaoZhaolin,YangHeng,etal.Depthestimationfromlightfieldanalysisbasedmultiplecuesfusion[J].ChineseJournalofComputers, 2014, 37(97):1-15. (inChinese)
[13]WannerS,MeisterS,GoldlueckeB.Datasetsandbenchmarksfordenselysampled4Dlightfields[J].Vision,ModellingandVisualization(VMV), 2013: 225-226.
文章编号:1673-3193(2016)04-0395-06
收稿日期:2015-12-31
基金项目:国家自然科学基金资助项目(61271425,61372150)
作者简介:陈佃文(1987-), 男, 硕士生, 主要从事图像重建的研究.
中图分类号:TP391
文献标识码:A
doi:10.3969/j.issn.1673-3193.2016.04.014
A Depth Estimation Algorithm Using 4D Light Field Data
CHEN Dian-wen1, QIU Jun1, LIU Chang2, ZHAO Song-nian3
(1. Institute of Applied Mathematics, Beijing Information Science & Technology University, Beijing 100101, China;2. School of Mathematical Sciences, Peking University, Beijing 100871, China;3. Institute of Atmospheric Physics, Chinese Academy of Sciences, Beijing 100029, China)
Abstract:A depth estimation algorithm was proposed based on the four-dimensional structure information of the light field data, which has pixel-level precision and provides the accurate depth information for 3D surface reconstruction. First, the area-based matching algorithm based on the light field data was presented according to the proportional relationship between the disparity and the transposition of the viewpoints in light field data.The preliminary disparity map can be achieved. Then a confidence function was proposed based on the roots of the matching error to classify and optimize the pixels with matching error.The depth map with high accuracy can be achieved. The publicly benchmark simulated light field datasets from HCI and real light field datasets were used to verify the proposed algorithm and evaluate the accuracy of the disparity map. The results show that the proposed algorithm has better accuracy than the existing algorithms, especially in the smooth and occlusions regions.
Key words:depth estimation; light field; disparity map; area-based matching
