基于大数据的设备家族性缺陷分析
2016-08-01陈毅波
武 江 王 宁 陈毅波 刘 琪 王 梓 王 刚
基于大数据的设备家族性缺陷分析
武江1王宁2陈毅波3刘琪1王梓4王刚1
1.南瑞集团北京科东公司;2.国网黑龙江省电力有限公司;3.国网湖南省电力公司;4.国网天津市电力公司
行业曲线
大数据时代的到来,特别是大数据技术在数据存储、数据挖掘等领域的广泛应用,为电网运行数据进行深度挖掘提供了可能。针对原有的设备家族性缺陷分析需要依靠人工记录和判断的现状,本文通过研究大数据在数据存储与数据挖掘方面的最新技术,结合设备家族性缺陷分析的业务特点,提出了基于大数据的设备家族性缺陷分析系统架构,实现了设备家族性缺陷的智能分析与预测,提高了电网监控专业的业务水平与工作效率,保障了电网的安全稳定运行。
在当前电网运行环境中,电力设备发生缺陷,尤其是危急和严重缺陷,会危及人身的安全和设备、电网的可靠稳定运行,电力设备在设计、制造、安装、运行、检修等环节的任何一个过程、环节稍有不慎,都会给设备带来缺陷或者隐患。
目前针对设备运行中出现的缺陷与故障,主要靠人为上报确认,当设备发生缺陷或故障时,会伴随发生相关的告警信息,站端人员通过电话沟通通知主站的监控人员,监控人员将缺陷或故障信息记录到监控日志当中。
随着“大数据时代”的到来,许多行业将大数据技术应用于存储、分析与处理海量的结构化/非结构化数据,突破了原有的技术壁垒,也为电网公司分析、处理海量数据,多维度挖掘设备与事件之间的关联关系提供了新的方向。
国调设备监控专业“十三五”规划明确提出了开展设备运行大数据分析的要求,实现设备履历与设备缺陷、告警信息等的关联应用,寻找设备家族性的缺陷,达到保障电网稳定运行目的,提高电网监控业务故障分析的智能化水平,现提出基于大数据的设备家族性缺陷分析方案。
本文首先依据电网数据的存储特点与原理,结合设备家族性缺陷分析的业务特点,提出了基于大数据的设备家族性缺陷分析的系统架构,从数据采集->数据存储->数据挖掘->数据应用建立了一套完成的解决方案,不仅解决了数据源的接入与存储从而形成了用于设备家族性缺陷分析的大数据,同时通过数据挖掘技术,设定分析规则与模型,为上层的分析应用提供了技术支撑。最后,通过展示具体的应用案例,验证了本方案的可行性与有效性。
总体架构
本系统通过整合D5000系统设备遥信、遥测等数据、OMS系统设备缺陷、故障、检修、台账等数据,基于大数据平台建立以设备为核心的数据模型,利用数据挖掘技术建立设备缺陷、故障识别模型,自动识别设备缺陷、故障告警信息,同时支持自定义设备缺陷、故障规则定制,正向判定存在缺陷、故障设备,实现设备家族性缺陷分析。系统架构图如图1所示。
关键技术研究
缺陷规则定义
依据人为定义的缺陷规则找出缺陷设备,并展示其家族设备缺陷情况、检修情况、告警信息等。
缺陷断线=控制回路断线,即对于断路器,包含“控制回路断线”的告警内容在6秒内频发次数大于3,可确认此开关存在设备缺陷的概率为80%。Sql:select * from“PSIDP”.”HISDB”.”YX_BW_OVER_2015_06”a where 信号内容 like ‘%断线%’ and 设备表ID=407 order by 发生时间,以设备为出发点,查询告警数据中的内容,结合缺陷规则定义及关键字锁定此设备的ID,同时关联设备台帐,寻找同一厂家生产的设备,遍历所有与这些设备的关联的特征数据信息,得出此厂家生产了多少设备,其中拥有家族性缺陷的设备数量,以及此类设备拥有家族性缺陷的概率。
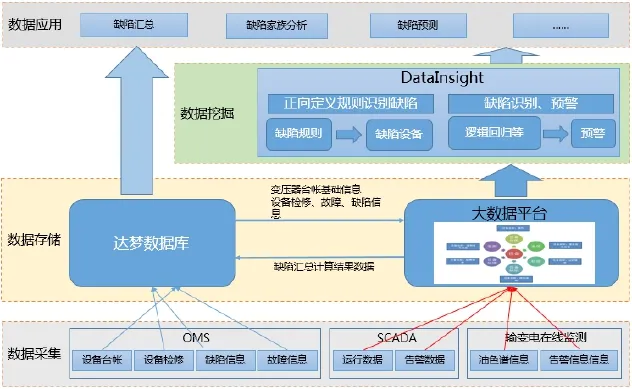
图1 系统架构图
设备缺陷识别预警模型
将设备缺陷、故障识别看成一个分类问题,通过首先采集一批样本,这批样本已经标注了故障类型,通过故障设备的遥信、遥测数据及人工上报的故障文本数据作为特征,使用分类算法,建立分类模型,分类模型可以识别出未标注故障类型的设备故障种类。
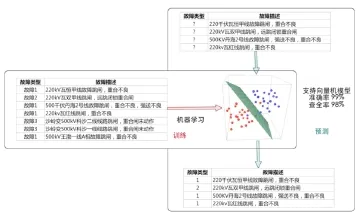
图2 文本分类模型
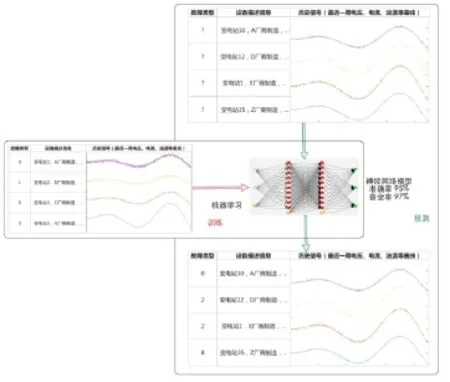
图3 设备缺陷识别分析
缺陷识别分类
对于已经发生的缺陷,基于其描述信息(如“一次性设备缺陷”中的“内容”等)和历史信号(如“遥信、遥测数据”等),对其进行自动归类,从而为最终人工判定提供辅助。
比如,对于一个新发生的缺陷,模型基于该一次性设备缺陷信息的内容和最近一周的电压等传感器信号,对其进行归类,输出可能的缺陷类型及其对应的可能性,一个可能的输出为:”重合闸未动作90%;重合不良10%”。建模流程:
1.缺陷描述信息规范化,对于关系型数据库“监控日志”中的“一次设备缺陷”的非结构化设备缺陷描述(“内容”字段)进行结构化处理。建立缺陷字典(比如,1代表”重合闸未动作“,2代表”重合不良“等),将每一条缺陷描述指定到对应的类别ID。本环节是一个典型的文本分类问题。首先,人工标注部分的缺陷描述数据,比如一共有10W条缺陷描述,人工将其中的1W条归类到对应的类别ID。接着使用TF-IDF + BiGram算法提取文本特征,即将一条描述文本转换为一个高维特征向量。然后基于1W条缺陷的类别ID和特征向量,利用支持向量机算法训练出一个文本分类子模型。子模型调试完毕,对其余9W条故障描述进行分类,从而得到所有文本描述的类别ID。文本分类模型如图3所示。
2.特征编码。基于所有已经发生的缺陷数据,从描述信息和历史信号中提取出相应特征,并将之编码为一个特征向量。
3.训练缺陷识别模型。结合缺陷类别ID和特征向量,分别使用随机森林(RandomForest)、逻辑回归(Logistic Regression)、卷积神经网络(Convolutional Neural Network)等算法调试建立一系列子模型。最后,基于融合方法(Ensemble),将上述子模型融合成为一个最终模型。该模型的输入是设备的描述信息和历史信号,输出是发生设备缺陷的分类及概率值。利用标注数据,建立神经网络子模型如图4所示,并对全量缺陷数据进行归类。
缺陷预测
对于正常运行中的设备,同样基于其描述信息(如“设备台账数据”中的“生产厂家”等)和历史信号(如“遥信数据”等),预测其未来一段时间(比如一周)内出现缺陷的概率,从而有针对性的指引设备检修和应对措施。
比如,对于一个正常运行的设备,模型基于该设备的描述信息和最近一周的电压等传感器信号,对其进行缺陷预测,输出可能的缺陷类型及其发生的概念,一个可能的输出为:”未来一周内,出现重合闸未动作30%;出现重合不良20%;出现未归类缺陷5%”。
建模流程:
1.缺陷描述信息规范化,同”缺陷分类“中的方法。
2.选取样本。发生的每一条缺陷,以其缺陷分类ID为准;对于正常运行超过一个月的设备,该正常运行记录作为正常类。
3.特征编码。基于所有已经发生的缺陷数据,从描述信息和历史信号中提取出相应特征,并将之编码为一个特征向量。这一步骤类似”缺陷分类“中的方法。
4.建立缺陷预测模型。结合类别ID(各个缺陷类别和正常类别)和特征向量,分别使用随机森林(RandomForest)、逻辑回归(Logistic Regression)、卷积神经网络(Convolutional Neural Network)等算法调试建立一系列子模型。最后,基于融合方法(Ensemble),将上述子模型融合成为一个最终模型。该模型的输入是设备的描述信息和最近一个月的历史信号,输出是该设备未来一周出现各种缺陷的概率。图5利用样本数据(故障记录+正常运行记录),建立神经网络子模型,并对未来一周缺陷发生进行预测。
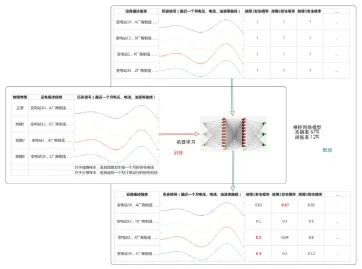
图4 缺陷预测分析
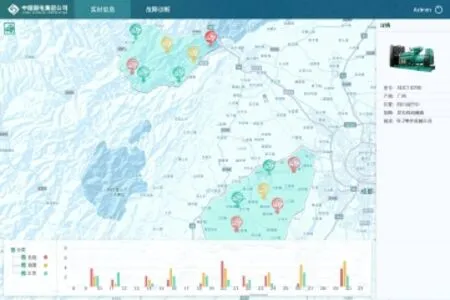
图5 设备缺陷实时信息分析
应用实例
基于上述设备家族性缺陷分析技术和大数据平台,本系统在实际的应用情况如图6所示。图中显示选中的存在缺陷或者故障的设备的信息情况,包括基本信息、故障描述等内容。点击型号、厂商显示同一商场、型号设备的缺陷故障情况。点击具体设备查看设备其他相关信息,包括检修、运行情况及警告情况。
结语
本文通过分析设备运行大数据的分类及特点,建立设备家族性缺陷分析的大数据平台,利用数据挖掘技术实现了设备履历与设备缺陷、告警信息等的关联应用,不仅提高了寻找设备家族性缺陷的效率,达到保障电网稳定运行目的,而且提高了电网监控业务故障分析的智能化水平。
DOI:10.3969/j.issn.1001- 8972.2016.13.039
