基于核超限学习机的中文文本情感分类
2016-08-01于海燕陈丽如郑文斌
于海燕,陈丽如,郑文斌
(中国计量大学 信息工程学院,浙江 杭州 310018)
基于核超限学习机的中文文本情感分类
于海燕,陈丽如,郑文斌
(中国计量大学 信息工程学院,浙江 杭州 310018)
【摘要】针对传统情感分类算法存在的参数学习困难及分类性能较低等问题,提出了一种基于核超限学习机的中文文本情感分类方法.首先通过信息增益对训练数据进行特征选择以降低输入维数,然后通过构建基于小波核超限学习机的分类器实现对中文文本的情感分类.实验结果表明,新方法参数学习容易,且其文本情感分类性能通常优于支持向量机和朴素贝叶斯.
【关键词】核超限学习机;情感分类;中文文本
随着科学技术的发展,互联网越来越普及,Web2.0给人们带来了很大的互动性,人们不仅可以阅读网页,而且还可以在网上对商品的满意度、当下热点话题、时事政治等发表自己的观点和表明态度.商业公司、用户等迫切需要计算机能够有效地判断这些观点和态度的情感倾向性,以帮助他们做出正确的决策.文本情感分类获得越来越多的关注.
情感分类主要是判断文本的情感倾向性,即褒贬性[1-3].当前研究使用的技术主要分为两大类:一类是基于词典的方法[4,5],通过构建情感词典,并计算情感文本中正负情感词的个数以实现情感分类;另一类是基于机器学习的方法[1,6,7],如:朴素贝叶斯[8](Naive Bayes,NB)、支持向量机[9](Support Vector Machine,SVM)等.当前很多研究结果表明,基于机器学习的方法比基于词典的方法性能好[1,2].然而,这些方法仍然存在一些问题,如:NB完全忽略了特征项之间的联系[10],而文本特征间明显存在关联;SVM分类模型性能较好,但是其参数学习比较困难[11].
近年来,黄广斌等提出了一种新的学习算法即超限学习机(Extreme Learning Machine,ELM)[12],它是一种单隐藏层前馈神经网络,可以解析求出网络的输出权值,具有学习速度快、外权求解全局最优等特点.但是,ELM的隐藏层输入权值随机产生,使得最终结果带有一定的随机性.Huang等[13]通过进一步研究,对比ELM与SVM的建模和求解过程,提出了核超限学习机(Kernel Extreme Learning Machine,KELM)算法,其可调参数少、性能稳定,且核函数的引入使非线性映射隐含在线性学习器中同步进行,有利于学习速度进一步提高.
本文提出一种基于KELM的中文文本情感分类方法:首先采用信息增益实现情感文本的特征选择以降低输入维度,从而降低KELM的网络规模.之后根据KELM网络特点设计分类器并实现情感分类.主要贡献有:1)探索基于KELM的分类器实现文本情感分类的可行性;2)探索KELM相关参数对分类器性能的影响;3)将KELM与流行的相关分类模型进行性能比较.
本文其他章节安排如下:第1节介绍了基于核超限学习机的情感分类的具体实现;第2节呈现了相关实验结果及实验分析;第3节给出相应总结及展望.
1基于KELM的中文文本情感分类实现
1.1文本表示及特征选择
本文采用TF-IDF[14]方法实现文本的特征表示.TF-IDF特征权值不但考虑了特征项在每篇文档中出现的次数,而且还考虑了特征项在整个数据集中的情况,其基本公式为
TF-IDF(ti,d)=tf(ti,d)×idf(ti).
(1)
其中,t和d分别表示特征项和文档,tf(ti,d)是特征项ti在文档d中出现的次数,idf(ti)是逆文档频率,idf(ti)=log(N/df(ti)),N是指训练集中总的文档数,df(ti)指训练集中包含ti的文档数.
将TF-IDF特征权值归一化如式(2),这样可以消除不同文档长度的影响.
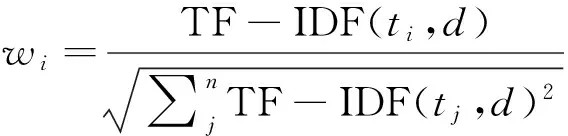
(2)
其中,n是特征空间的维数,wi是文档d中特征项ti的权值.
由于文本特征维数较高,特别是中文文本在分词后特征维数很高,所以需要特征选择以提高分类的效率.本文采用具有较好性能的信息增益[15]进行文本特征选择,其计算公式为

(3)
其中,c表示情感类别,P(t,c)表示特征项和类别的共现概率.
1.2分类模型实现

(4)
其中,
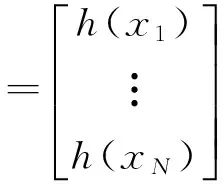
(5)
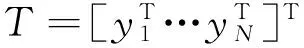
(6)
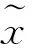
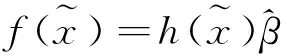
(7)
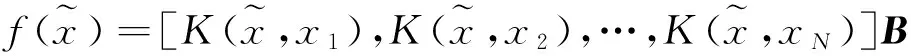
(8)
其中,
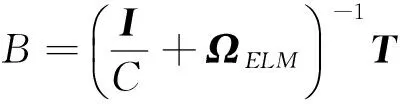
(9)
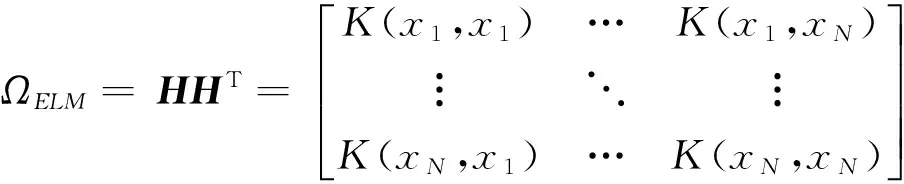
(10)
K(xi,xj)是核函数的形式,常用的核函数有多项式核函数、高斯径向基核函数、线性核函数、小波核函数等.
1.3算法描述
基于核超限学习机的中文文本情感分类的具体算法流程如下.
输出:测试样本类别标签c;
1)对训练样本与测试样本分别进行分词、去停用词;
2)通过公式(3)计算训练样本初始特征的信息增益,按信息增益从大到小的顺序选取前n维特征作为文本特征向量,n为预选取的特征维数;
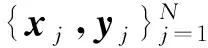
2实验
实验中所采用的计算机配置环境为:处理器为Intel(R)Core(TM)i3-4150CPU@3.50GHz,内存为4GB,操作系统为Windows7.计算软件是MATLAB7.11.0(R2010b);SVM分类算法调用的是LIBSVM工具箱*http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
2.1数据集与预处理
本文采用了两个领域的语料集:书籍(BOOK)评论、笔记本(NOTEBOOK)评论,均来源于谭松波博士搜集整理的中文文本语料*http://www.datatang.com/datares/go.aspx?dataid=605301.实验中每个数据集选用正负向文本各1 000篇.
预处理过程中,首先对情感文本进行分词并去除停用词.分词调用的是NLPIR2015汉语分词系统中的开源代码*http://ictclas.nlpir.org/.然后进行特征选择,构造特征向量空间.
2.2性能评价
在实际的情感分类系统中,不仅需要考虑分类的准确率,而且还要考虑计算成本.本文从准确率(Accuracy)、训练时间(TrainingTime)、测试时间(TestingTime)等多角度评价分类系统.其中准确率为情感分类正确的文本数与总的文本数的百分比;训练时间和测试时间主要是针对分类算法的训练和测试过程,不包含前期的预处理过程.
2.3实验结果与分析
为能够客观评价分类器性能,实验结果中采用5折交叉验证取平均值的方法.分类器输入特征维数在50维到4 000维之间进行取值.分类算法有NB、SVM和KELM,后两种算法都会涉及到参数的选择,支持向量机需要选择的是惩罚因子和核参数,核超限学习机需要选择核参数和正则化参数.实验中用网格交叉验证法选择各算法的相关参数.
核超限学习机中的核函数有多项式核函数、高斯径向基核函数、线性核函数、小波核函数等.其中,小波核函数中的小波函数选用的是morlet小波函数,则小波核函数为
exp(-(xi-xi′)2/2a2)].
(11)通过对比以上四种核函数的性能,选取最优核函数.
图1、2对比了四种核函数在两个数据集上的分类性能.从图中可以看出小波核函数(wavelet-kernel)的性能在大部分情况下都优于其他三个核函数.维数大于等于1 000维时,小波核函数的性能保持不变或有所提高,且基本上均优于其它核函数.整体上,在3 000维到4 000维时性能要优于其他维数时的性能.根据此实验结果,接下来的实验中采用小波核作为核超限学习机的核函数.

图1 BOOK数据集上四种核函数的性能对比Figure 1 Performance comparison of the four kernel functions on the BOOK data set
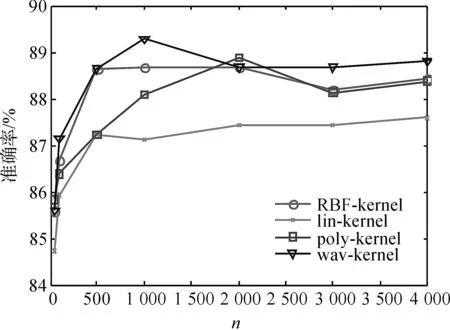
图2 NOTEBOOK数据集上四种核函数的性能对比Figure 2 Performance comparison of the four kernel functions on the NOTEBOOK data set
图3、4分别给出了KELM的参数在BOOK和NOTEBOOK数据集上的一个网格交叉验证结果.可以看出正则化参数C对性能的影响要弱于核参数.从整体上看,当C较大时,KELM对核参数的选择并不敏感.这有利于方便高效地选择核参数.
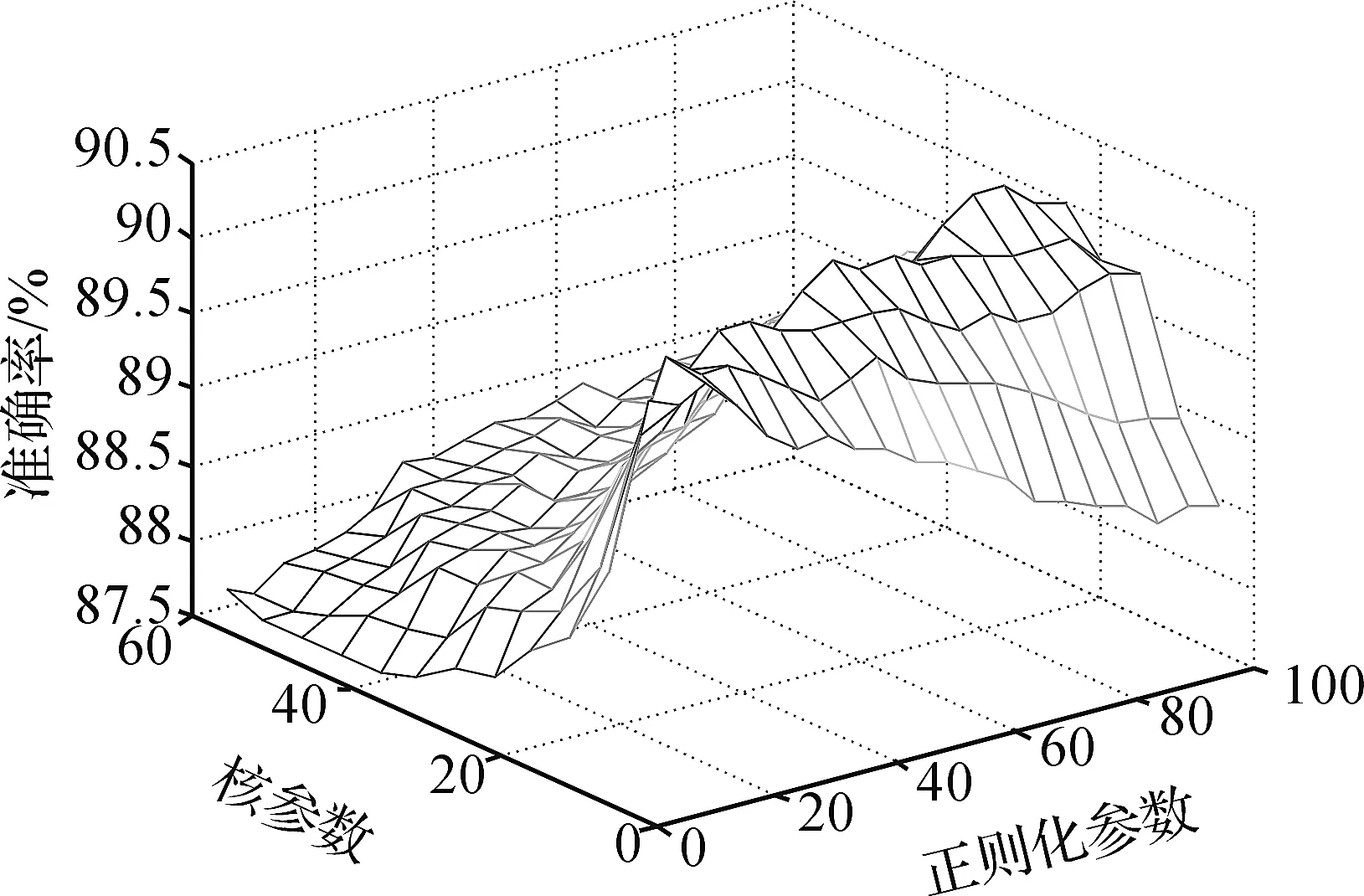
图3 KELM的参数在BOOK数据集上的一个网格交叉验证结果Figure 3 Grid cross validation of the KELM parameters on the BOOK data set
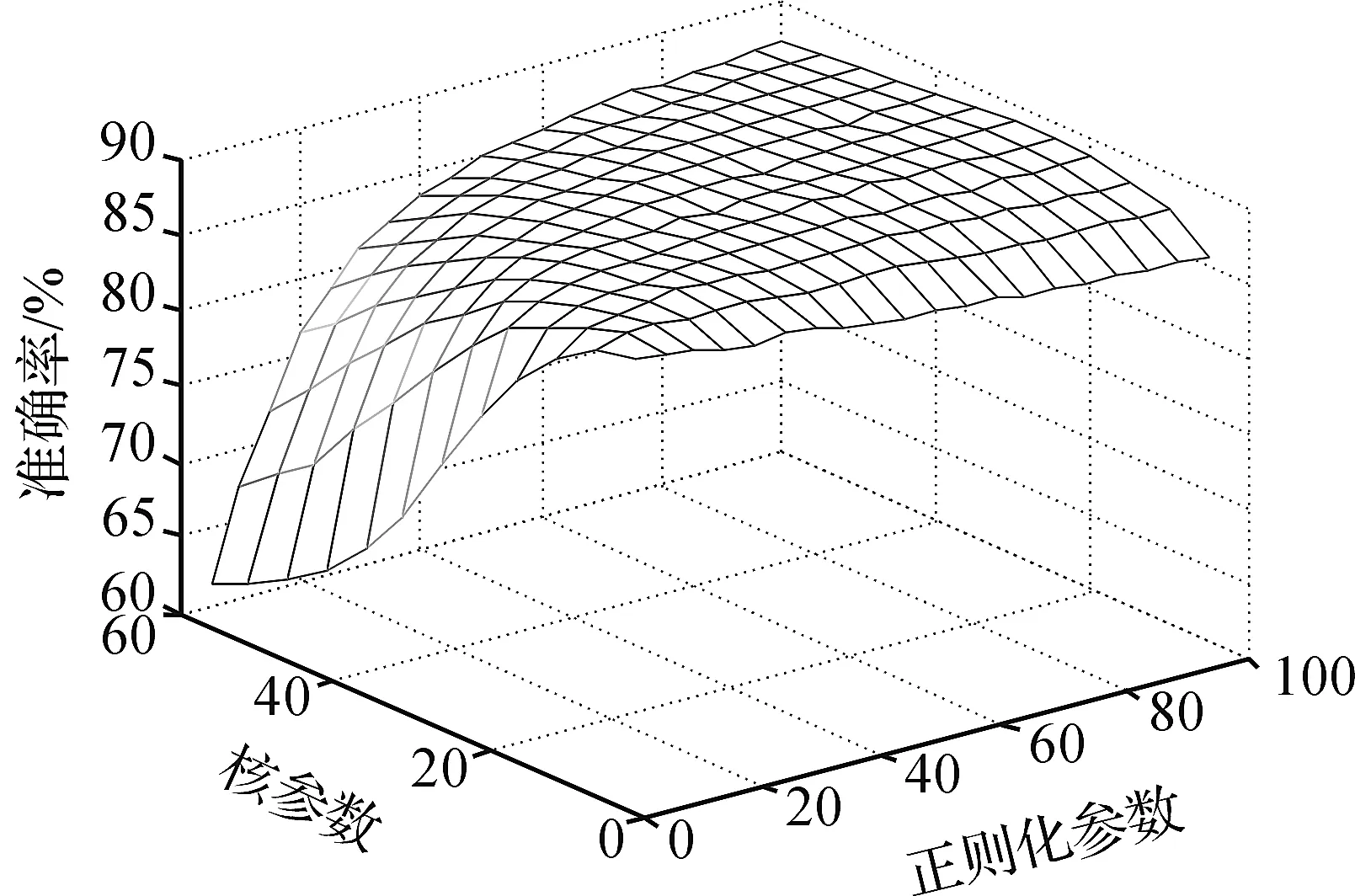
图4 KELM的参数在NOTEBOOK数据集上的一个网格交叉验证结果Figure 4 Grid cross validation of the KELM parameters on the NOTEBOOK data set
表1和表2分别给出了KELM、SVM、NB三种分类模型在BOOK和NOTEBOOK数据集上的分类准确率.可以看出KELM的准确率通常优于SVM,随着维数的升高,这种差距越明显.而NB分类模型的准确率较低,虽然其性能随着特征维数的增加也增加,但是依然低于KELM.
表1、2均反映出KELM在高维情况下的性能仍然稳定,而且其准确率随特征维度的升高而升高.但是在4 000维时略微有所下降,这说明特征维数并不是越高越好,因为维数过高容易引入较多的噪声特征.

表1 不同分类模型在BOOK数据集上的准确率对比

表2 不同分类模型在NOTEBOOK数据集上的准确率对比
图5、6分别给出了三种分类模型在BOOK数据集上的训练时间和测试时间.从图5中可以看出KELM在保证取得较高分类准确率的情况下,其训练时间接近SVM快于NB.在测试阶段,KELM所需的时间低于SVM,NB算法的测试时间虽然很短,但是其分类精度较低.综合起来,KELM的整体性能优于其他两种算法.
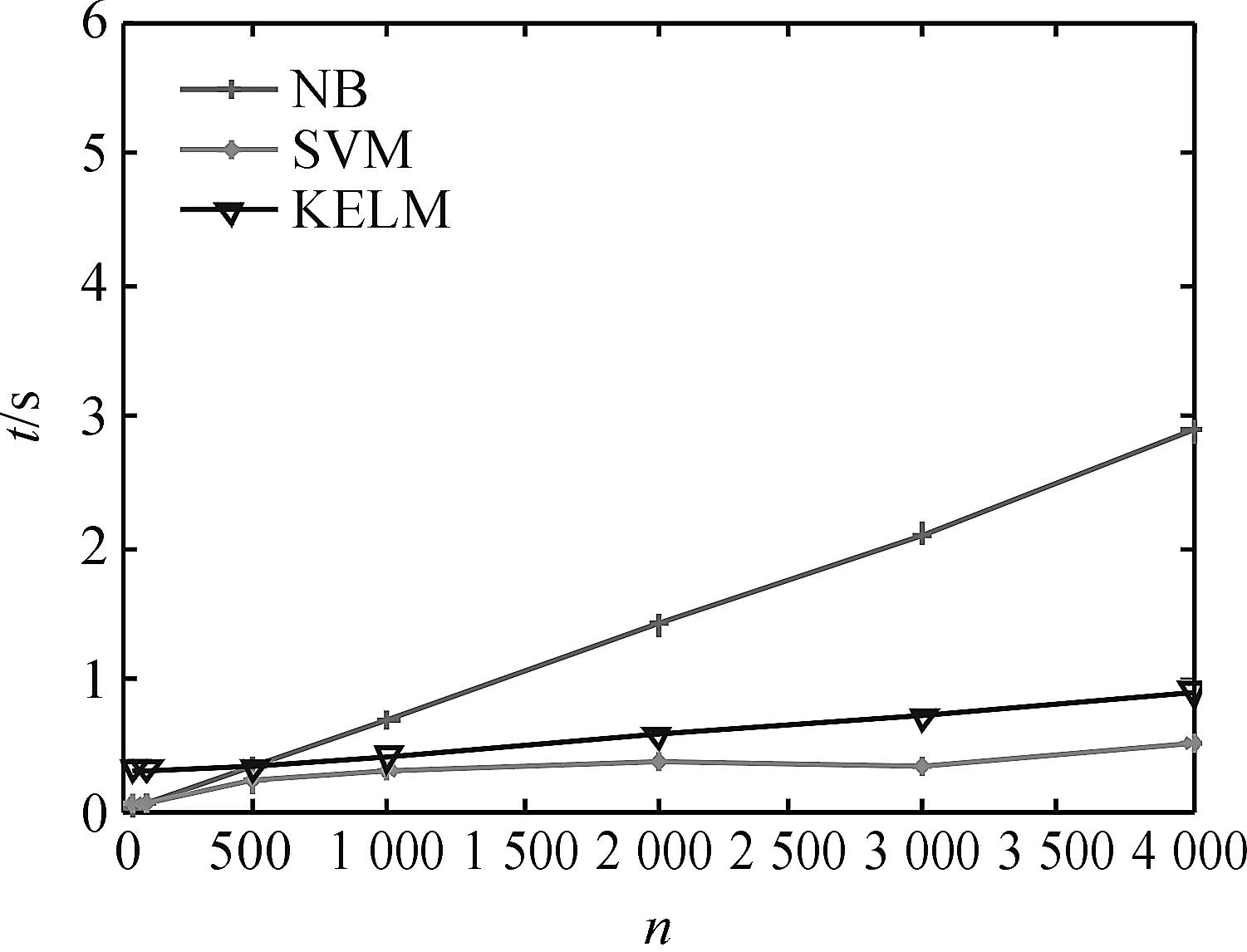
图5 BOOK数据集上各分类模型的训练时间对比 Figure 5 Training time comparison of the different classification models on the BOOK data set
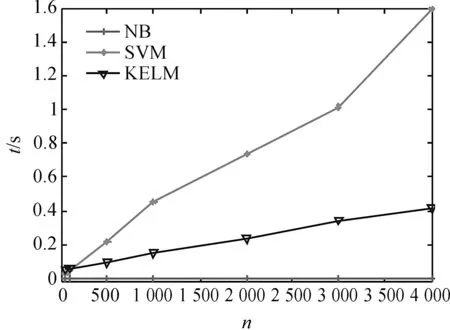
图6 BOOK数据集上各分类模型的测试时间对比 Figure 6 Testing time comparison of the different classification models on the BOOK data set
3总结与展望
本文提出了一种基于KELM的中文文本情感分类方法,探索了核参数以及正则化参数的选择变化对系统性能的影响.进一步对比了KELM与SVM、NB在不同输入维数下的分类准确率以及训练时间和分类时间.实验表明:当正则化参数较大时,小波核超限学习机对核参数的选择并不敏感,有利于方便高效地学习参数.在分类性能方面,KELM的准确率一般优于SVM和NB,其所需的训练时间和测试时间也较少.因此KELM的整体性能优于其他两种算法.在将来的工作中,将研究如何有效降低特征的维度,以进一步减少核函数矩阵的计算花销以及如何进一步优化小波核函数,以获得更好的中文文本情感分类性能.
【参考文献】
[1]PANG B, LEE L, VAITHYANATHAN S. Thumbs up: sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, USA: Association for Computational Linguistics,2002:79-86.
[2]TAN S, ZHANG J. An empirical study of sentiment analysis for Chinese documents[J]. Expert Systems with Applications,2008,34(4):2622-2629.
[3]王素格,李德玉,魏英杰.基于赋权粗糙隶属度的文本情感分类方法[J].计算机研究与发展,2015,48(5):855-861.
WANG Suge, LI Deyu, WEI Yingjie. A method of text sentiment classification based on weighted rough membership[J]. Journal of Computer Research and Development,2015,48(5):855-861.
[4]ANDREEVSKAIA A, BERGLER S. Mining WordNet for a fuzzy sentiment: sentiment tag extraction from WordNet glosses[C]// Proceedings EACL-06, the 11th Conference of the European Chapter of the Association for Computational Linguistics. Trento, Italy: EACL,2006:209-216.
[5]KENNEDY A, INKPEN D. Sentiment classification of movie reviews using contextual valence shifters[J]. Computational Intelligence,2006,22(2):110-125.
[6]叶佳骏,冯俊,任欢,等.IG-RS-SVM的电子商务产品质量舆情分析研究[J].中国计量学院学报,2015,26(3):285-290.
YE Jiajun, FENG Jun, REN Huan, et al. Analysis of pubilic opinon on E-commerce product quality based on IG-RS-SVM[J]. Journal of China University of Metrology,2015,26(3):285-290.
[7]CHEN P, FU X, TENG S, et al. Research on micro-blog sentiment polarity classification based on SVM[M]. Switzerland: Springer International Publishing,2015:392-404.
[8]MCCALLUM A, NIGAM K. A comparison of event models for naive bayes text classification[C]//AAAI-98 Workshop on Learning for Text Categorization. USA: AAAI,1998:41-48.
[9]GODBOLE S, SARAWAGI S, CHAKRABARTI S. Scaling multi-class support vector machines using inter-class confusion[C]//Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.USA:ACM,2002:513-518.
[10]LU S H, CHIANG D A, KEH H C, et al. Chinese text classification by the Naive Bayes classifier and the associative classifier with multiple confidence threshold values[J]. Knowledge-Based Systems,2010,23(6):598-604.
[11]祁亨年.支持向量机及其应用研究综述[J].计算机工程,2004,30(10):6-9.
QI Hengnian. Support vector machines and application research overview[J]. Computer Engineering,2004,30(10):6-9.
[12]HUANG G B, ZHU Q Y, SIEW C K. Extreme learning machine: a new learning scheme of feedforward neural networks[C]//2004 IEEE International Joint Conference on Neural Networks. America: IEEE,2004:985-990.
[13]HUANG G B, ZHOU H, DING X, et al. Extreme learning machine for regression and multi-class classification[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics),2011,42(2):513-529.
[14]SALTON G, BUCKLEY C. Term-weighting approaches in automatic text retrieval[J]. Information Processing & Management,1988,24(5):513-523.
[15]LEE C, LEE G G. Information gain and divergence-based feature selection for machine learning-based text categorization[J]. Information Processing & Management,2006,42(1):155-165.
【文章编号】1004-1540(2016)02-0228-06
DOI:10.3969/j.issn.1004-1540.2016.02.018
【收稿日期】2015-12-30《中国计量学院学报》网址:zgjl.cbpt.cnki.net
【基金项目】国家自然科学基金资助项目(No.61272315,11391240180),浙江省自然科学基金资助项目(No.LY14F020041,LY15A020003).
【作者简介】于海燕(1991-),女,河南省南阳人,硕士研究生,主要研究领域为文本情感分类.E-mail:diyyhy@163.com 通信联系人:郑文斌,男,副教授.E-mail:zwb@zju.edu.cn
【中图分类号】TP391
【文献标志码】A
Chinese text sentiment classification based on kernel extreme learning machines
YU Haiyan, CHEN Liru, ZHENG Wenbin
(College of Information Engineering, China Jiliang University, Hangzhou 310018, China)
Abstract:Aiming at the disadvantages of traditional classification algorithms for sentiment classification, such as complicated parameter learning and low classification performance, this paper proposed a novel Chinese text sentiment classification approach based on kernel extreme learning machines. First, the feature selection for training data via the information gain technology was implemented to reduce the input dimensionality. Then, a classifier based on the wavelet kernel extreme learning machine was constructed for Chinese text sentiment classification. The experimental results show that the model parameters of the proposed method are easier to learn and the Chinese text sentiment classification performance of the proposed method is usually superior to support vector machines or naive bayes.
Key words:kernel extreme learning machine; sentiment classification; Chinese texts
