多层次MSER自然场景文本检测
2016-08-01唐有宝邬向前
唐有宝, 卜 巍, 邬向前
(1. 哈尔滨工业大学 计算机科学与技术学院, 黑龙江 哈尔滨 150001;2. 哈尔滨工业大学 媒体技术与艺术系, 黑龙江 哈尔滨 150001)
多层次MSER自然场景文本检测
唐有宝1, 卜巍2, 邬向前1
(1. 哈尔滨工业大学 计算机科学与技术学院, 黑龙江 哈尔滨 150001;2. 哈尔滨工业大学 媒体技术与艺术系, 黑龙江 哈尔滨 150001)
摘要:提出一种新的基于多层次最大稳定极值区域(MSER)的自然场景文本检测方法,其由候选区域的提取和文本检测组成.在候选区域提取过程中,采用多层次MSER区域提取方法:通过对原始图像进行多个颜色空间变换和多尺度放缩得到多个变换后的图像,采用多个阈值对其进行MSER区域检测,并将检测到的区域作为候选区域用于文本检测.检测过程中,对候选区域提取手工设计的底层特征和基于卷积神经网络(CNN)的深层特征,训练一个随机森林回归器对特征进行分类得到字符区域,再将其合并成单词区域,并进行相似的特征提取和分类,从而得到最终的文本检测结果.使用2个标准的数据库(ICDAR2011和ICDAR2013)对提出的方法进行性能评价,F指标在ICDAR2011和ICDAR2013上均为0.79,表明了所提出的自然场景文本检测方法的有效性.
关键词:自然场景文本检测;多层次最大稳定极值区域(MSER);卷积神经网络(CNN); 随机森林回归器
在自然场景图像中,传统的低水平图像特征(如:关键点、边缘等)通常提供模糊的信息,而文本直接提供清晰明了的高层语义信息,并为大量的计算机视觉任务(如:图像搜索、图像理解等)提供有效的指导.
自然场景文本检测是指判断不同场景图像(警示牌、街道标志等)中是否存在文本,若存在,则定位文本所在的位置.为了促进自然场景文本检测技术的发展,国际上举办了多次竞赛[1-2],发布了多个包含不同场景的数据库.近年来,尽管在自然场景文字检测方面进行了大量的研究工作,但仍然存在很多问题未解决,主要原因有以下3点:1)场景文本的多样性,即文本在不可控的环境中可拥有完全不同的字体、颜色、尺度和方向等;2)背景的复杂性,即自然场景图像中的背景通常是复杂的,且存在大量和真实文本十分相似的物体(如:砖块、窗户、栅栏等),因此容易导致混淆和错误;3)其他外界因素的干扰,如:扭曲、部分遮挡、光照不均匀等.
Ye等[3]将自然场景文本检测方法划分为两大类:基于滑动窗口的方法和基于连通体的方法.基于滑动窗口的方法[4-7]是将多尺度窗口在图像中所有可能的位置上进行滑动,然后从滑动窗口内的图像区域提取特征,根据提取的特征对其进行分类,因此,从滑动窗口中提取的特征优劣决定着该方法的性能.起初,一些手工设计的底层特征被用于文本检测[4-6],比如局部二值模式(localbinarypattern,LBP)、尺度不变特征变换描述符(scale-invariantfeaturetransform,SIFT)、梯度方向直方图(histogramoforientedgradient,HOG)等,随着卷积神经网络(convolutionalneuralnetwork,CNN)在计算机视觉任务中的成功应用,Jaderber等[7]开始利用CNN从滑动窗口图像区域中学习深层特征并用于文本检测,取得了目前最好的检测结果.虽然基于滑动窗口的方法过程简单直观,但为了实现优良的检测性能,通常需要滑动大量的窗口,并需要对每个窗口中的图像区域进行分类,导致计算复杂度高.
基于连通体的自然场景文本检测方法首先根据图像中像素间属性(如:颜色、纹理、笔画宽度等)的相似性对像素进行聚类合,生成大量的连通体区域;然后从连通体图像区域中提取特征(包括手工设计的底层特征和基于CNN的深层特征),并将其按文本区域、非文本区域进行分类,从而完成文本检测.在基于连通体的方法中,连通体候选区域提取是重要的步骤,目前使用最广泛的两种提取方法为笔画宽度变换(strokewidthtransform,SWT)[8]和最大稳定极值区域(maximallystableextremalregions,MSER)[9].SWT和MSER的有效性和稳定性使得基于SWT[8,10-13]或MSER[14-19]的自然场景文本检测方法能有效完成文本检测任务,但是SWT和MSER对光照、颜色变化和噪声等因素比较敏感,影响检测性能.
为了增加文本检测方法对光照等因素的鲁棒性,本文扩展了基于MSER的候选区域提取方法,并提出一种基于多层次MSER的自然场景文本检测方法.多层次体现在以下3方面:1)多颜色空间,将原始图像的RGB颜色空间变换成HIS空间,得到R、G、B、H、S、I六个颜色分量图像;2)多尺度,将上述得到的不同颜色分量图像进行放缩变换得到多个不同尺度下的图像;3)多阈值,对上述得到的图像应用MSER检测在多个阈值下进行连通体区域提取.本文采用的连通体候选区域提取方法对自然场景中文本的尺度和颜色变化等因素更加鲁棒,并综合使用手工设计的底层特征、基于CNN的深层特征增强区域分类精度,从而进一步提高文本检测性能.
1多层次MSER候选区域提取
在进行候选区域提取之前,首先对图像进行平滑处理,以免噪声干扰提取结果.由于文本轮廓是用于区分文本和背景区域的重要因素,本文采用保边平滑滤波器[23]对图像进行去噪处理.
MSER是对灰度图像进行操作,因此,如何将RGB彩色图像转换为灰度图像,在一定程度上将影响MSER的检测结果.为了尽可能克服光照、颜色变化等因素的干扰,本文采用多个颜色空间的各个分量图像作为MSER检测的灰度图像:RGB和HIS两个颜色空间6个分量图像IC={Ir,Ig,Ib,Ih,Ii,Is}.在不同分量图像中,区域的稳定性不同,因此,从其中提取的MSER连通体区域将具有互补性,即在某个分量图像中没有被提取到的区域,在其他分量图像中将会被提取到.如图1(a)所示为从不同颜色分量图像中提取的MSER区域互补的实例.

图1 基于多层次MSER的候选区域提取实例Fig.1 Extraction examples of candidate regions based on multi-level MSER
在不同的自然场景图像以及同一个自然场景图像中,文本之间的尺度变化会较大.虽然MSER在一定程度上具有尺度不变性,但对同一个连通体区域而言,不同尺度情况下连通体区域内的灰度值变化存在一定的差异性.因此,当固定其他参数(如不同的颜色分量、不同的MSER检测阈值等)时,某些连通体区域在某一尺度下不能被检测到,但将图像放缩到另一尺度时则能被检测到.由此可见,不同尺度的图像中,MSER检测到的区域也具有一定的互补性.本文将采用IS={0.25,0.50,1.00}对原始图像进行缩放变换,得到3种不同尺度下的图像.如图1(b)所示为在不同尺度图像中提取的MSER区域互补的实例.
由于场景图像中文本的多样性,对于给定的一幅自然场景图像,虽然同一文本区域内的像素灰度值变化平缓,但不同文本区域间的变化存在一定的差异.因此,当使用固定的阈值对不同的文本区域进行MSER检测时,某些灰度值变化较小的区域会被检测到,而灰度值变化相对较大的区域不能被检测到.为了解决上述问题,本文采用多个阈值来进行MSER区域检测,通过对图像进行多尺度的放缩变换,弥补区域灰度值变化较大的情况.通过对训练集进行不同阈值下的MSER检测,判断不同阈值下的互补性、效率,确定使用2个阈值IT={2,4}进行检测.如图1(c)所示为使用不同阈值时检测到的MSER区域之间互补的实例.
综上所述,基于多层次MSER的候选区域检测方法,多层次体现在多颜色空间、多尺度、以及多阈值上.不同情况下的MSER检测结果中可能包含不同的文本区域,为了充分利用不同检测结果之间的互补性,去掉重复的MSER区域,将剩下所有情况下的检测区域作为最终的候选区域用于分类.相比基于SWT或单一的MSER检测方法,本文提出的基于多层次MSER方法能在一定程度上解决文本分割问题,可提取更多的真实文本候选区域,进一步提高该方法的通用性和有效性.然而,MSER方法会增加很多非文本的候选区域,在一定程度上增加了算法的复杂性,增加整个过程的处理时间,对于实时性要求高的场合具有一定的局限性.为了能有效地从更多的候选区域中提取出文本区域,下一部分将重点介绍基于区域的特征提取和分类过程.
2基于多层次MSER的文本检测
对于给定的一幅如图2(a)所示的自然场景图像,在使用多层次MSER候选区域检测后,会得到大量连通体候选区域,如图2(b)所示,其包括字符区域和背景区域.因此,需要将字符区域和背景区域区分开来,并将字符区域合并成文本区域,以完成文本检测任务.

图2 字符区域提取过程示意图Fig.2 Illustration of character regions extraction process
2.1区域特征提取和分类
为了区分字符区域和背景区域,首先从提取到的候选区域中提取特征来表达其特性.与以往仅提取手工设计的底层特征或基于CNN的深层特征的方法不同,本文综合使用这两类特征来增强特征的表述能力:在底层特征方面,本文提取了颜色特征和纹理特征;在深层特征方面,本文提取了基于CNN的深层特征.
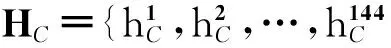


给定一个候选区域,对其提取完颜色特征、纹理特征及深层特征之后,将它们拼接成一个239维的特征向量H=[HC,HT,HD]来表述该区域的特性,并将每一维线性归一化到0和1之间.由于该特征向量能很好的刻画字符区域和背景区域之间的差异性,本文用其对候选区域进行分类:首先,使用训练集中的候选区域特征样本训练1个随机森林回归器(random forest regressor)[25];然后,给定一幅自然场景图像,提取大量的候选区域,对于每个候选区域,利用训练好的随机森林回归器可以得到1个分数;最后,根据所有候选区域的得分(如图2(c)所示)计算自适应阈值来完成候选区域的分类.如图2(d)所示为从图2(a)检测到的字符区域.
2.2文本检测
由于在上述候选区域分类过程中,我们只考虑了单个字符区域与背景区域的差异,因此,对候选区域进行分类后,在得到的字符区域中可能会存在某些和字符很相似的背景区域(如:砖块、窗户等).为了尽可能的排除此类情况,本文综合考虑相邻字符区域之间的关系,将字符区域合并成单词区域,对其进行特征提取和分类,从而进一步排除某些类似字符的背景区域.
真正的字符区域通常是按照一定的规律(或先验知识)出现的,比如文本方向通常近似水平、单词间的间隔通常要大于同一单词内不同字符间的间隔等,本文将根据上述规律将字符区域合并成单词区域.给定一幅自然场景图像,通过对候选区域进行分类后可得到大量的字符区域并可容易获得其最小外接矩形,字符区域合并过程如下:
1) 找到未被处理的最左侧区域,然后迭代的在水平方向上寻找与其最近的区域,当该相邻两个区域的高度比在[0.50,2.00]之内时,将其进行合并,直到相邻区域之间的距离大于其平均高度的3倍时迭代停止.
2) 对每组合并的区域进行单词分割,首先计算所有相邻区域之间的平均距离,然后在相邻区域间距离大于平均距离的1.2倍处进行分割.

图3 基于字符区域的文本检测过程Fig.3 Process of text detection based on characterregions
3) 重复上述2个步骤,在所有未被处理的区域都被处理后结束整个过程.
经过上述合并过程,得到比合并前数量少很多的单词区域,如图3(a)所示为由图2(d)分割得到的单词区域.然后采用同候选区域特征提取和分类类似的过程来完成单词区域的分类,从而得到最终的文本检测结果.如图3(b)所示为图3(a)对应的由单词区域经过随机森林回归器的得分图,图3(c)和图3(d)分别为单词区域分类结果和最终的文本检测结果(实线矩形框)与ICDAR2011真实结果(虚线矩形框)的对比图.
3实验结果与分析
3.1数据库及评价准则
使用ICDAR2011[1]和ICDAR2013[2]自然场景文本检测竞赛数据库对本文提出的自然场景文本检测方法进行评价.其中ICDAR2011数据库包含了299幅训练图像和255幅测试图像,ICDAR2013数据库包含了229幅训练图像和233幅测试图像.实际上,ICDAR2013测试集是ICDAR2011测试集的一个子集,ICDAR2013去掉了后者重复出现的图像并修改了一部分手工标注的真实结果.由于本文需要训练CNN网络和随机森林回归器,从ICDAR2011训练集中分别提取5 000个字符区域正样本和20 000个负样本以及1 000个单词区域正样本和5 000个负样本用于训练.
本文采用数据库对应的竞赛评价准则来对提出的方法进行性能评价,所采用的评价指标分别为准确率P、召回率R、和F综合指标.准确率是指正确检测到的文本数与所有检测到的文本总数的比值,召回率是指正确检测到的文本数与真实文本总数的比值,而综合指标则是准确率和召回率之间的调和平均数.各项评价准则的详细信息可参考文献[1-2]中所述.
3.2实验结果与分析
如表1和2所示为本文提出的自然场景文本检测方法和其他当前最好的文本检测方法在ICDAR2011和ICDAR2013两个数据库上的实验对比,相比可知:本文提出的方法在ICDAR2011和ICDAR2013两个数据库上获得了最好的召回率,分别为0.76和0.75,比当前最好方法分别提高了0.05[15]和0.05[19],说明本文提出的方法能正确检测到更多的真实文本.本文提出的方法得益于以下两方面:1)基于多层次MSER的候选区域提取方法能提取到更多的真实字符区域;2)本文进行区域分类时,综合使用了手工设计的底层特征和基于CNN的深层特征,从而增强了特征的区分能力并,提高了分类精度.从表1~2可知,相比其他方法,本文提出方法的综合性能(F指标)也得到了最好的结果.
如图4所示为几个本文方法文本检测的结果,其中实线矩形框和虚线矩形框分别表示本文方法检测的结果和ICDAR2011中标注的真实结果,为了显示更加清晰,图中没有给出ICDAR2013中标注的真实结果.由图4可知,本文的方法在不同的场景中均能成功检测到文本,且检测结果和手工标注的真实结果十分接近,证明了本文提出的自然场景文本检测方法的有效性.

图4 本文方法进行文本检测成功的实例Fig.4 Successful examples of our text detectionmethod
Tab.2Comparison of experimental results of different methods on ICDAR2011 dataset
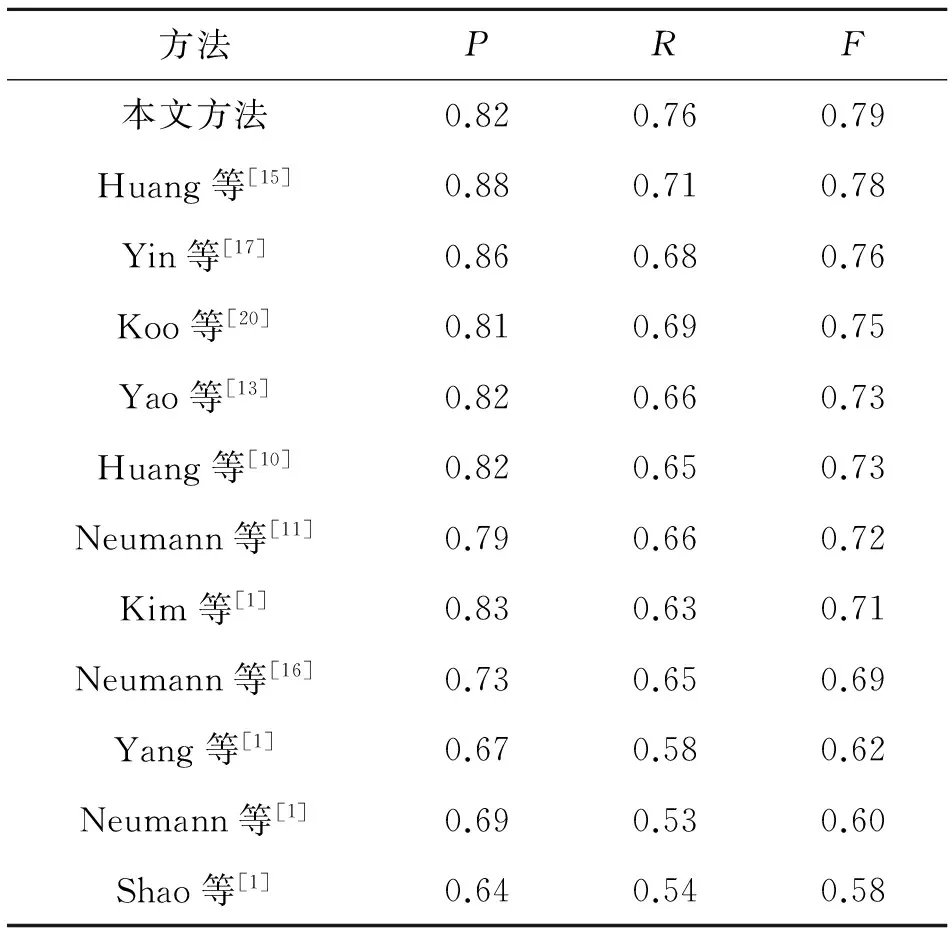
方法PRF本文方法0.820.760.79Huang等[15]0.880.710.78Yin等[17]0.860.680.76Koo等[20]0.810.690.75Yao等[13]0.820.660.73Huang等[10]0.820.650.73Neumann等[11]0.790.660.72Kim等[1]0.830.630.71Neumann等[16]0.730.650.69Yang等[1]0.670.580.62Neumann等[1]0.690.530.60Shao等[1]0.640.540.58
表2不同方法在ICDAR2013库中的实验结果比较
Tab.2Comparison of experimental results of different methods on ICDAR2013 dataset

方法PRF本文方法0.830.750.79iwrr2014[19]0.860.700.77USTBTexStar[17]0.880.660.76TextSpotter[2]0.880.650.74CASIA_NLPR[2]0.790.680.73I2R_NUS_FAR[2]0.750.690.72I2R_NUS[2]0.730.660.69TH-TextLoc[2]0.700.650.67
尽管本文方法在2个标准的数据库上都得到了最好的综合结果,且在大部分情况下都能准确地检测到文本,但在某些情况下仍然不能成功地进行文本检测.例如,当字符区域内的像素颜色变化较大时,说明该区域不够稳定,使用MSER方法难以提取到完整的字符区域,使得文本检测失败,如图5(a)所示.当字符区域和背景区域颜色很相似时,使用MSER方法得到的区域既包含了文本区域,也包含了背景区域,从而使得文本检测失败,如图5(b)所示.

图5 本文方法进行文本检测失败的实例Fig.5 Failure examples of our text detection method
4结语
本文提出了一种基于多层次MSER的自然场景文本检测方法,相比传统的基于MSER的候选区域提取方法,基于多层次MSER的候选区域提取方法能提取到更多真实的字符区域,同时对字符区域的颜色变化和尺度变化更加鲁棒.相比以往的区域分类方法,本文综合使用了手工设计的底层特征和基于CNN的深层特征来增强特征的区分能力,从而提高了最终的区域分类精度.在2个标准的数据库上的结果表明:本文提出的自然场景文本检测方法有效,且能得到更好的召回率.
参考文献(References):
[1] SHAHAB A, SHAFAIT F, DENGEL A. ICDAR 2011 robust reading competition challenge 2: reading text in scene images [C] ∥ Proceeding of International Conference on Document Analysis and Recognition. Beijing: IEEE, 2011: 1491-1496.
[2] KARATZAS D, SHAFAIT F, UCHIDA S, et al. ICDAR 2013 robust reading competition [C] ∥ Proceeding of International Conference on Document Analysis and Recognition. Washington: IEEE, 2013: 1484-1493.
[3] YE Q, DOERMANN D. Text detection and recognition in imagery: a survey [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 37(7):1480-1500.
[4] CHEN X, YUILLE A. Detecting and reading text in natural scenes [C] ∥ Proceeding of IEEE Conference on Computer Vision and Pattern Recognition. Washington: IEEE, 2004: 366-373.
[5] WANG K, BABENKO B, BELONGIE S. End-to-end scene text recognition [C] ∥ Proceeding of International Conference on Computer Vision. Barcelona: IEEE, 2011: 1457-1464.
[6] MISHRA A, ALAHARI K, JAWAHAR C. Top-down and bottom-up cues for scene text recognition [C] ∥ Proceeding of IEEE Conference on Computer Vision and Pattern Recognition. Providence: IEEE, 2012: 2687-2694.
[7] JADERBERG M, VEDALDI A, ZISSERMAN A. Deep features for text spotting [C] ∥ Proceeding of European Conference on Computer Vision. Zurich: Springer, 2014: 512-528.
[8] EPSHTEIN B, OFEK E, WEXLER Y. Detecting text in natural scenes with stroke width transform [C] ∥ Proceeding of IEEE Conference on Computer Vision and Pattern Recognition. San Francisco: IEEE, 2010:2963-2970.
[9] MATAS J, CHUM O, URBAN M, et al. Robust wide baseline stereo from maximally stable extremal regions [C] ∥ Proceeding of British Machine Vision Conference. Cardiff: Elsevier, 2002: 761-767.
[10] HUANG W, LIN Z, YANG J, et al. Text localization in natural images using stroke feature transform and text covariance descriptors [C] ∥ Proceeding of International Conference on Computer Vision. Sydney: IEEE, 2013: 1241-1248.
[11] NEUMANN L, MATAS J. Scene text localization and recognition with oriented stroke detection [C] ∥ Proceeding of International Conference on Computer Vision. Sydney: IEEE, 2013: 97-104.
[12] YAO C, BAI X, LIU W, et al. Detecting texts of arbitrary orientations in natural images [C] ∥ Proceeding of IEEE Conference on Computer Vision and Pattern Recognition. Providence: IEEE, 2012: 1083-1090.
[13] YAO C, BAI X, LIU W. A unified framework for multioriented text detection and recognition [J]. IEEE Transactions on Image Processing, 2014, 23(11):4737-4749.
[14] LI Y, JIA W, SHEN C, et al. Characterness: An indicator of text in the wild [J]. IEEE Transactions on Image Processing, 2014, 23(4): 1666-1677.
[15] HUANG W, QIAO Y, TANG X. Robust scene text detection with convolution neural network induced MSER trees [C] ∥ Proceeding of European Conference on Computer Vision. Zurich: Springer, 2014: 497-511.
[16] NEUMANN L, MATAS J. Real-time scene text localization and recognition [C] ∥ Proceeding of IEEE Conference on Computer Vision and Pattern Recognition. Providence: IEEE, 2012: 3538-3545.
[17] YIN X, YIN X, HUANG K, et al. Robust text detection in natural scene images [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(5): 970-983.
[18] NEUMANN L, MATAS J. A method for text localization and recognition in real-world images [C] ∥ Proceeding of Asian Conference on Computer Vision. Queenstown: Springer, 2010: 770-783.
[19] ZAMBERLETTI A, NOCE L, GALLO I. Text localization based on fast feature pyramids and multi-resolution maximally stable extremal regions [C] ∥ Proceeding of ACCV Workshops on Robust Reading. Singapore: Springer, 2014: 91-105.
[20] KOO H, KIM D. Scene text detection via connected component clustering and nontext filtering [J]. IEEE Transactions on Image Processing, 2013, 22(6):2296-2305.
[21] KANG L, LI Y, DOERMANN D. Orientation robust text line detection in natural images [C] ∥ Proceeding of IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 4034-4041.
[22] WANG T, WU D, COATES A, et al. End-to-end text recognition with convolutional neural networks [C] ∥ Proceeding of International Conference on Pattern Recognition. Tsukuba: IEEE, 2012: 3304-3308.
[23] ZHANG Q, XU L, JIA J. 100+ times faster weighted median filter (WMF) [C] ∥ Proceeding of IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 2830-2837.
[24] KRIZHEVSKY A, HINTON G. Convolutional deep belief networks on cifar-10 [J]. Unpublished manuscript, 2010, 40.
[25] BREIMAN L. Random forests [J]. Machine learning, 2001, 45(1): 5-32.
收稿日期:2016-01-10.
基金项目:国家自然科学基金资助项目(61073125, 61350004);中央高校基本科研业务费专项资金资助项目(HIT.NSRIF.2013091, HIT.HSS. 201407).
作者简介:唐有宝(1987—),男,博士生,从事图像处理、模式识别、计算机视觉及生物特征识别研究. ORCID:0000-0001-8719-3375. E-mail: tangyoubao@hit.edu.cn 通信联系人:卜巍,女,副教授. ORCID:0000-0002-9996-3733. E-mail: buwei@hit.edu.cn
DOI:10.3785/j.issn.1008-973X.2016.06.017
中图分类号:TP 391.41
文献标志码:A
文章编号:1008-973X(2016)06-1134-07
Naturalscenetextdetectionbasedonmulti-levelMSER
TANGYou-bao1,BUWei2,WUXiang-qian1
(1. School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China;2. Department of New Media Technologies and Arts, Harbin Institute of Technology, Harbin 150001, China)
Abstract:A novel scene text detection method based on multi-level maximally stable extremal regions (MSER) was proposed, which consisted of two main stages, including candidate regions extraction and text regions detection. In the stage of candidate regions extraction, a multi-level MSER region extraction technique was developed by considering multiple color spaces, multiple scale transformations of original image and multiple thresholds of MSER detection. All extracted regions from the input image were used as candidate character regions for text region detection. In the stage of text detection, the hand-designed bottom features and CNN based features were extracted for each candidate character region as first, then a random forest regressor trained from training datasets was used to get the character regions. After that, the character regions were merged to form candidate word regions, from which the features were extracted and classified to get the final text detection results by using the similar process of candidate character region classification. The proposed method was evaluated on two standard benchmark datasets, including ICDAR2011 and ICDAR2013, and both got the F-measure performance of 0.79, respectively, Which demonstrates the effectiveness of the proposed natural scene text detection method.
Key words:scene text detection; multi-level maximally stable extremal regions (MSER); convolutional neural network (CNN); random forest regressor
