一种基于SSD的高性能Hadoop系统的设计与应用
2016-07-31陈丽,王锐,胡刚
陈 丽,王 锐,胡 刚
(1.广东交通职业技术学院,广东 广州 510650;2.中国移动通信集团广东有限公司,广东 广州 510623;3.星环信息科技(上海)有限公司,上海 200233)
一种基于SSD的高性能Hadoop系统的设计与应用
陈 丽1,王 锐2,胡 刚3
(1.广东交通职业技术学院,广东 广州 510650;2.中国移动通信集团广东有限公司,广东 广州 510623;3.星环信息科技(上海)有限公司,上海 200233)
在大数据平台中,随第一代Hadoop出现的基于磁盘的批处理计算框架MapReduce的局限日益显现:数据读入和中间结果数据均依赖于大量磁盘I/O,性能有限。基于内存计算的Spark成为当前重点,对比MapReduce性能可提升10-100倍,但内存使用的成本依旧高昂。采用超高速且相对廉价的SSD作为大数据的缓存解决方案,阐述了SSD和HDD的混合存储架构;同时,结合高效的Spark计算引擎和行列混合式文件结构等优化技术,设计了一种基于SSD的高性能Hadoop系统,能有效地解决大数据计算系统的性能问题和存储空间问题,实验结果显示取得数倍性能提升。
大数据;Hadoop;Spark;SSD;行列混合式存储
数据作为企业最重要的资产,一直以来都是企业应用、技术、架构和服务等创新的源泉。随着信息数据化和互联网技术的发展,企业数据正在迅速增长,从GB级别跨入到TB和PB级别。这些数据的特征可以概括为“4个V”:体量大(volume), 格式多样(variety),更新速度快(velocity)和蕴含巨大的商业价值(value)。拥有“4V”特点的数据以及数据的处理方式被赋予“大数据(big data)”[1]这个名字,正在带来IT产业的重大技术变革。
在这场变革中,快速占据主流的技术是Hadoop[2]分布式系统架构。Hadoop最核心的设计是分布式文件系统HDFS[3](Hadoop Distributed File System)和MapReduce[4]计算模型。HDFS被设计部署在价格低廉的硬件上,依靠数据冗余达到高度容错,提供高吞吐量的数据访问,适合批量处理大量数据。MapReduce将复杂的计算过程抽象为多组map和reduce步骤,map和reduce各由多个mapper和reducer函数执行,将不同mapper和reducer分配至不同的计算节点,实现了在大型计算集群上的高效分布式计算处理。Hadoop还具有高扩展性,即计算机集群可以通过添加计算节点无限增加计算能力。
当用户要求Hadoop作为一个全栈平台,同时兼容批处理、交互迭代式查询和流处理时,Hadoop架构的局限性日益显现。最大的瓶颈之一是MapReduce的大量中间结果需要向磁盘进行读写,当计算量大时,磁盘I/O的瓶颈导致MapReduce不适合迭代式(Iterative)和交互式(Interactive)应用。
本文针对这个问题,提出一个新的高性能Hadoop系统的设计和实现,内容包括:采用基于内存计算的大数据处理框架Spark来代替MapReduce作为计算引擎,提高计算速度。引入SSD代替内存作缓存,让SSD和内存、HDD(Hard Disk Drive,机械硬盘)共同组成混合存储体系;针对SSD硬件特性而优化的存储格式,采用行列混合式文件结构ORCFile,进一步提升存储空间利用率和处理效率。
1 混合存储模型开始引入SSD
近年来,固态硬盘(Solid State Driver, SSD)已经作为一种可以持久化保存数据的存储设备逐步被广泛使用。SSD有以下几个特点:1)性能方面,SSD因为不需要像HDD一样寻道,有远高于机械硬盘的随机读速度,写速度也同样明显高于HDD;2)价格方面,SSD的价格要高于HDD,但远低于内存,并且每存储单位的价格还在下降。实践证明SSD只有内存价格的十分之一,但计算性能是内存的90%;3)使用寿命方面,市场上主流的NAND型闪存SSD具有写前擦除的特点,每块闪存芯片的擦除次数是有限的,目前已经有通过SSD磨损均衡的研究成果[5]来提升SSD的使用寿命,而且从实际使用经验值来看,如果每天完全读写3次,一般可使用4年,基本上也是IT硬件产品的更新周期。
表1[6]列出了SSD和HDD的一些平均关键指标对比(具体值会依据品牌和型号有微小不同)。SSD相对HDD有非常高的I/O性能,访问速度快100-120倍。因此引入SSD到现有存储体系中是非常有价值的,利用两者优点来设计混合存储系统是当前存储系统的研究热点。

Table1 Performance Comparison of SSD and HDD表1 SSD和HDD性能对比
很多研究机构和公司针对SDD和HDD的混合存储模型已经开展过大量研究和优化,取得了不错的成果。陈志广等人[7]提出一种高性能的混合存储方案,其主要想法是SSD响应所有I/O请求,获得较高的性能,另外用多块磁盘协作备份SSD数据,解决单块SSD上的突发写问题,并提高可靠性。杨濮源等人[8]针对SSD和HDD混合存储提出了一个时间敏感的模型,即结合数据页的访问次数以及访问热度实现分类,将读倾向负载的hot页面分配到SSD存储,写倾向负载的页面或者cold页面分配到HDD存储,从而整体上取得显著的性能提升。Facebook公司利用SSD的特性,设计了一个混合存储系统flashcache[9],利用SSD作为加速I/O引擎的核心,形成了一个通用的块级混合存储软件方案。
另一方面,因为SSD良好的随机读和顺序写性能,可将SSD设计为扩展缓存,缩短对磁盘的读写访问时间,进而提高整个系统的性能。Taeho Kgil等人[10]提出了在内存和磁盘之间增加由闪存构成的缓存层,从而减少对磁盘的访问,进而减少能耗。Biplob Debnath等人[11]设计固态硬盘作为磁盘的写缓存,为微软多人在线游戏系统和数据去重系统大幅提高了性能。针对MapReduce 处理框架,Seok-Hoon Kang等人[12]提出引入SSD提高系统性能。
Hadoop系统在2.6.0版本中引入混合存储层(Heterogeneous Storage Tiers)的概念[13-14],开始支持基于SSD的混合存储体系,实现更好的性能扩展。因此,基于SSD的混合存储模型会逐渐成为Hadoop系统的重要基础。
2 高性能Hadoop系统基本框架
现阶段Hadoop系统主要基于MapReduce计算模型,其所有操作都要转化成Map、Shuffle和Reduce等核心阶段,即将对数据集的计算分发到每个节点并将中间结果进行汇总,中间结果需要向HDFS文件系统读写,同时计算模型数据需要网络传输,加上磁盘I/O存在瓶颈,所以现阶段的Hadoop系统在处理迭代式、交互式等复杂运算方面存在不足。
本文提出的高性能Hadoop系统是从计算和存储两大核心模型出发,建立一个统一的、高性能的大数据计算平台(如图1)。核心计算模型采用Spark[15]:支持数据缓存在内存、通用DAG执行和调度、延迟计算和高效优化等优点,具体有极低的调度和启动开销。核心存储模型采用行列混合式文件结构:支持更高效的数据压缩和更快速的数据加载。

Fig.1 High-Performance Hadoop architecture Based on SSD图1 基于SSD的高性能Hadoop系统框架图
2.1 计算模型-基于混合存储的Spark
Spark是发源于UC Berkeley AMP lab的集群计算平台。它立足于内存计算,从多迭代批量处理出发,提供一体化的解决方案,将MapReduce、Streaming、SQL、Machine Learning、Graph Processing等模型统一到一个平台下,成为全新的、高性能的分布式计算引擎。但大数据动辄TB级别,内存基本在GB级别,所以引入SSD作为Spark计算的缓存层来代替内存,既可以加快I/O吞吐,同时解决内存空间不足以应对大数据量的局限;SSD软件存储层采用行列混合式文件结构,充分发挥SSD硬件特性,提升处理性能和压缩空间。
Spark创造性提出弹性分布式数据集(Resilient Distributed Datasets, RDD)[16-17]的概念。RDD作为Spark最核心的内容,可以缓存到内存中,每次对RDD数据集操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘读写操作,这对于迭代式运算、交互式运算的效率提升非常大。
同时,RDD的基本操作组成有向无环图(Directed Acyclic Graph, DAG)[18]作业任务。分析DAG中任务之间的依赖性,可以把相邻的任务合并,从而减少大量中间结果的输出,极大减少了I/O,使复杂数据的分析任务更高效。通过DAG的执行和调度,消除了不必要的步骤,从而支持了延迟计算和高效优化,测试结果显示Spark平均比Hadoop快10至100倍[15]。
Spark支持内存/SSD混合分布式存储,根据数据需求,用户可以选择不同的级别的存储来缓存RDD。目前SSD相对于HDD有10倍以上的性能提升,而内存相较于SSD有3-4倍的提升。因此SSD的性能已经开始向内存接近,同时价格也在迅速下降,因此用SSD替代大内存作为缓存是一种高性价比的方案,有以下优点:
1)可以处理大数据。单台机器处理数据过大,Spark常出现内存不够或者无法运行出结果。而采用SSD替代大容量昂贵的内存作为缓存,一方面可以提供跟纯内存缓存接近的性能,另一方面也可处理更大的数据。
2)性能更加稳定。原有方案由于大量数据被缓存在内存中,Java垃圾回收缓慢的现象严重,导致Spark的性能不稳定,在复杂场景SQL的性能甚至不如现有的MapReduce。因此,采用SSD存储作为缓存,可以大幅减少GC的影响,提升性能稳定性。
因此,基于SSD的混合存储模型和Spark计算框架的Hadoop系统可根据数据的量级(如图2)和应用数据使用策略来合理设置存储方案,实现高性能的处理能力。
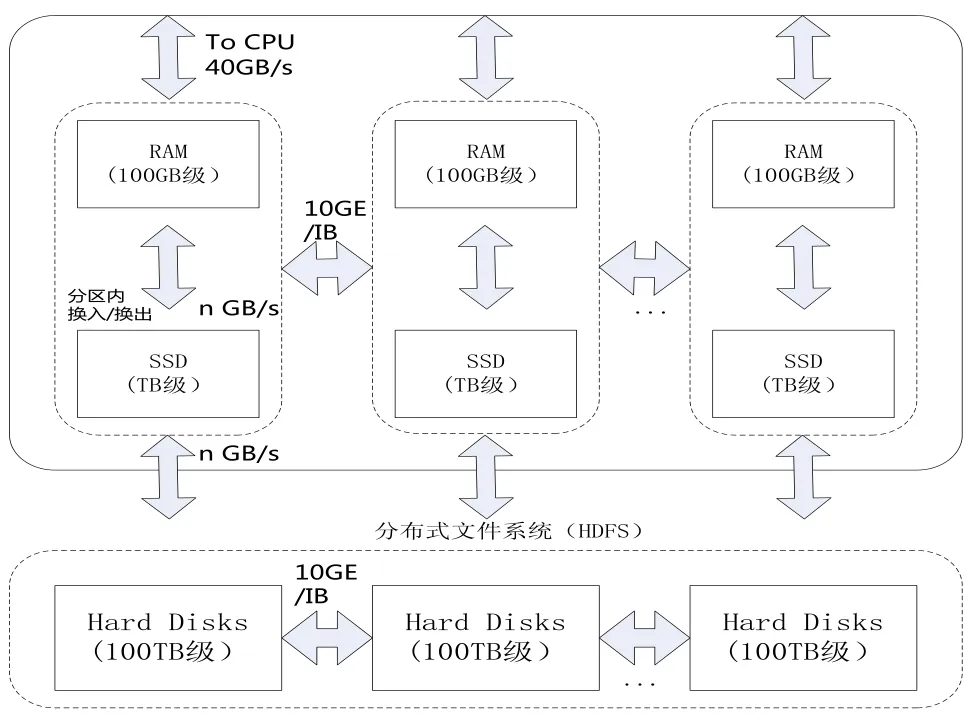
Fig.2 Heterogeneous Storage Magnitude-setting Schema图2 混合存储量级设置方案
总结上文,Spark是一个轻量级的调度框架和多线程计算模型,提供缓存机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销,同时兼容Hadoop存储API,可以读写存储在HDFS或HBase上的数据,在Spark基础上可以实现批处理、交互式分析、迭代式机器学习、流处理。因此Spark是一个用途广泛的计算引擎,并有望在未来取代MapReduce的地位。
2.2 存储模型-行列混合式文件结构
强大的计算引擎搭配针对分布式计算设计的文件存储结构可以获得更高的性能。基于混合的Spark在数据持久化时采用行列混合式文件结构,可以获得更大数据压缩比,让SSD可以支撑更大数据体量,从而整个集群获得更高性能。
传统的数据库系统中,主要有三种数据存储结构[19]:
1)水平的行存储结构(horizontal row-store structure):数据按行存储,同一行中包括所有的列的数据存在同一个物理位置,在HDFS中则存在同一个HDFS块上。其优点在于快速数据加载和动态查询的高适应能力。行存储也存在缺点,例如查询仅仅针对多列表中的少数几列,但行存储的文件必须被整行扫描,而不能跳过不必要的列读取。另外,压缩文件时要同时压缩不同列,由于不同的列数据类型不同,压缩比不高。
2)垂直的列存储结构(vertical column-store structure):数据按列存储,也就是同一列的数据存在同一个物理位置。列存储在执行查询时可以跳过不必要的列,而且同列的数据类型一致,压缩数据能达到比较高的压缩比。但也存在相应缺点,比如列存储不能保证一个记录的所有域在同一个集群节点上,记录的重构将导致通过集群节点网络的大量数据传输,不适合高负载动态模式。
3)混合的 PAX 存储结构(hybrid PAX store structure): 行列混合存储方式,结合了前两者的优点并且可以提升CPU缓存利用率,但并不能直接用到HDFS中。
基于PAX的行列混合存储思想,本文提出在HDFS上使用同是行列混合存储的ORCFile。ORCFile的前身是一种高效的数据存储结构RCFile(Record Columnar File)[19],并被应用于后来发展为Apache Hive的Facebook的数据仓库中。与传统数据库的数据存储结构相比,RCFile更有效地满足基于MapReduce的数据仓库的四个关键需求,即快速加载数据、快速处理查询、高效利用存储空间和高度适应动态工作负载。
RCFile的核心思想是首先把表水平切分成多个行组(row groups),然后组内按照列垂直切分,这样行组之内便按列存储。当一个行组内的所有列写到磁盘时,RCFile就会以列为单位对数据使用类zlib/lzo的算法进行压缩。当读取列数据的时候使用惰性解压策略(lazy decompression),也就是说用户的某个查询如果只是涉及到部分列,RCFile只会解压涉及到的列而跳过无关列。通过在facebook的数据仓库中选取有代表性的例子实验,RCFile能够提供5倍的压缩比。
ORC File(Optimized Row Columnar File)[20]的设计思想与RCFile类似,但做了优化,相比有以下优点:1)每个task只输出单个文件,这样可以减少NameNode的负载;2)支持比RCFile更多的数据类型;3)文件中存储了一些轻量级的索引数据;4)基于数据类型的块模式压缩;5)用多个互相独立的RecordReaders并行读相同的文件;6)无需扫描markers就可以分割文件;7)控制读写所需要的内存量。
Spark应用程序的输入输出采用行列混合式模型作为存储结构,通过下文的实验验证,确实可以显著地提升程序性能。
3 实验
本文分别针对高性能Hadoop系统的技术特点和应用场景做了相应测试。
3.1 SSD性能评测
本文采用TPC-DS国际标准测试集进行了一系列测试,数据量为300GB。测试平台是一个4台服务器的集群(每台服务器的硬件配置为2*E5-2620/256GB Mem/8*1TB HDD, 600GB SSD)。
测试TPC-DS中SQL语句运行所花时间对比的结果见表2和图3。我们能看到,SSD和内存的性能都远远好于机械硬盘。而SSD相比内存,其性能最多相差在20%以内,平均差10%以内。

Table2 Comparison of DISK/RAM/SSD Testing Results表2 DISK/RAM/SSD测试结果比较
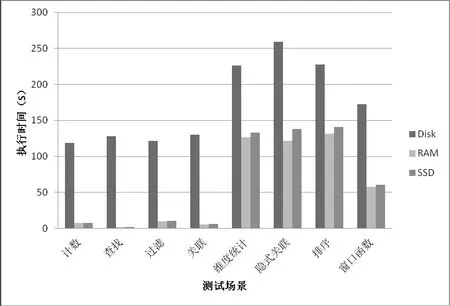
Fig.3 DISK/RAM/SSD Testing Result图3 DISK/RAM/SSD测试结果
3.2 不同文件格式在SSD的性能评测
下面用IO密集的SQL语句测试不同文件存储格式在不同介质上的运算速度。测试分别比较:将文本文件从Spark中缓存到HDD上、将文本文件从Spark中缓存到SSD上和将ORCFile文件缓存到SSD上的性能。设计的三大场景如下:

Table3 Testing scenarios表3 测试场景
TPC-DS中I/O密集的测试集结果如图4显示,文本存储格式(SequenceFile)搭配SSD缓存相较文本文件搭配HDD缓存,计算性能有所提高。但是当采用行列混合存储格式(ORCFile)搭配SSD做缓存时,计算性能出现了大幅提升数倍。总结测试结果,使用ORCFile作为文件存储格式和SSD作为缓存可以大幅提高Spark的计算性能。
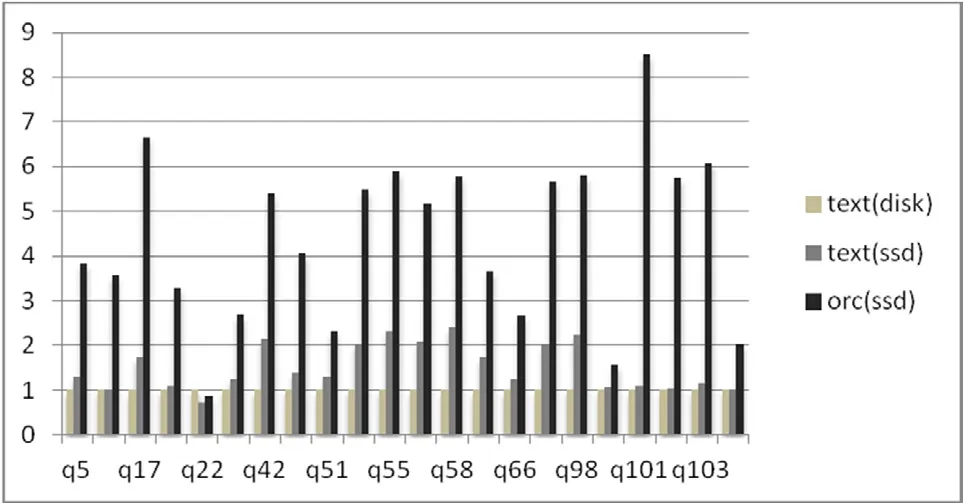
Fig.4 Testing Comparison of Different formats on Different media图4 对比不同格式在不同介质上的测试结果
3.3 基于SSD的Hadoop系统的性能评测
结合某省移动流量经营平台的测试案例,分别采用10台机器(IBM X3650, 2*E5-2670/128GB Mem/16*800G HDD, 1TB SSD),数据源每天4TB。结合表4,其中方案一采用SSD+Spark(即基于SSD的Spark全栈)的技术方案,SSD完全代替了内存计算引擎中的内存存储介质的作用,既能实现90%的内存计算引擎速度,同时又能完全存放3-4TB的流量经营分析的大数据量。方案二主要采用Hadoop发行商用版本MapReduce和Spark引擎。结果显示,基于SSD+Spark的技术方案性能提升2x-5x。

Table4 Testing Comparison of Different Hadoop system表4 Hadoop系统对比测试结果
4 结束语
本文从基于SSD的混合存储体系、Spark高性能计算模型和行列混合文件存储结构等方面进行阐述和分析,提出了一种高性能Hadoop的设计思路和实践,结合实验测试结果,论证了基于SSD的高性能Hadoop系统的设计具有更高的性能,同时能满足大数据应用场景。
同时也发现今后的研究空间可侧重以下方面:
1)数据存储结构优化。当前ORCFile文件格式已经有助于性能提升,但还需要结合SSD,进一步研究提升高效、低延时、高压缩比的方法。
2)通用性、稳定性更高的混合存储模型的实现和优化。Hadoop系统已经开始支持混合存储模型,未来SSD如何合理有效的应用将是一个重要的研究方向。
3)新一代Spark计算模型的优化。将内存计算转移到SSD计算,提升大数据处理平台的硬件资源的性价比和利用率,并结合大数据自身特点,构建统一高效的计算模型。
[1] Fabian Suchane, Gerhard Weikum. Knowledge harvesting in the big data era[C]//Proc of the 40th ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2013: 933-938.
[2] Apache Hadoop[EB/OL]. [2015-10-07]. http://hadoop.apache.org
[3] HDFS Architecture[EB/OL]. [2015-10-07]. http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
[4] MapReduce Tutorial. [2015-10-07]. http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
[5] Ma DZ, Feng JH, Li GL. LazyFTL:A page-level flash translation layer optimized for NAND flash memory [C]//Proc. of the 2011 ACM SIGMOD Int’l Conf. on Management of Data. New York: ACM Press, 2011:1-12.
[6] SSD White Paper[EB/OL]. [2015-10-07]. http://www.samsung.com/global/business/semiconductor/minisite/SSD/global/html/whitepaper/whitepaper.html
[7] Chen Zhiguang, Xiao Nong, Liu Fang, et al.A High Performance Reliable Storage System Using HDDs as the Backup of SSDs[J].Journal of Computer Research and Development,2013,50(1):80-89.
[8] YANG Pu-Yuan , JIN Pei-Quan, YUE Li-Hua.A Time-Sensitive and Efficient Hybrid Storage Model Involving SSD and HDD[J].Chinese Journal of Computers,2012,35(11):2294-2305.
[9] Facebook Flashcache[EB/OL]. [2015-10-07]. https://github.com/facebook/flashcache
[10] T. Kgil, D. Roberts, T. Mudge. Improving NAND Flash Based Disk Caches[C]//Proc of the 35th int'l Symp. on Computer Architecture, 2008:327-338,2008.
[11] B. Debnath, S. Sengupta, J. Li. Flashstore:High throught persistent key-value store[J].Proceedings of the Very Large Data Base (VLDB) Endowment,2010,(02):1414-1425.
[12] Seok-Hoon Kang, Dong-Hyun Koo, Woon-Hak Kang,et al.A Case for Flash Memory SSD in Hadoop Applications[J].International Journal of Control and Automation,2013,6(1):201-209.
[13] Apache Hadoop[EB/OL]. [2015-10-07]. http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html
[14] Arpit Agarwal. Heterogeneous Storages in HDFS[EB/OL]. (2013-11-20)[2015-10-07] .https://issues.apache.org/jira/secure/attachment/12615761/20131125-HeterogeneousStorage.pdf
[15] Apache Spark[EB/OL]. [2015-10-07]. http://spark.apache.org
[16] Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin,et al.Spark: Cluster Computing withWorking Sets[C/OL].[2015-10-07]. http://www.cs.berkeley.edu/~matei/papers/2010/hotcloud_spark.pdf
[17] Matei Zaharia, Mosharaf Chowdhury, Tathagata Das,et al. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing[C/OL].[2015-10-07] .
[18] http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf
[19] Matei Zaharia.An Architecture for Fast and General Data Processing on Large Clusters [D].Berkeley:EECS Department University of California, Berkeley, 2013.
[20] Yongqiang He, Rubao Lee, Yin Huai, et al.RCFile:a fast and space-efficient data placement structure in MapReduce-based warehouse systems[C]//Proc of International Conference on Data Engineering (ICDE 2011).Hannover, Germany,2011:1199-1208.
[21] ORC File Format[EB/OL]. [2015-10-07]. https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
Design and Application of a High Performance SSD-based Hadoop System
CHEN Li1, WANG Rui2, HU Gang3
(1 Guangdong Communication Polytechnic, Guangzhou 510650, China; 2 China Mobile Group Guangdong Co., Ltd.,Guangzhou 510623, China; 3 Transwarp(Shanghai) Co., Ltd., Shanghai 200233, China)
In the big data platform, the deficiency of MapReduce begins to emerge, which is designed for batch computation with the first generation of Ha-doop. Data read and intermediate results depend a lot on disk I/O, and the performance is limited. The memory based computation, spark, is more important. While the cost is too high, though it is 10-100 times faster than Hadoop MapReduce. This papers proposes a storage solution with SSD as big data caches,which is faster and cheaper. A SSD/HDD hybrid storage architecture is explored. Meanwhile, with the optimization techniques of efficient Spark computation engine and hybrid row-column data placement structure respectively, this paper proposes a high performance Hadoop system based on SSD, an effective solution to processing performance and storage space in the big data computing system. The experimental results show that the improvement the system is significant.
big data; hadoop; spark; SSD; row-column storage
TP311
A
1672-2841(2016)01-0039-06
2016-02-28
广东省高职高专云计算与大数据专业委员会教育科研课题(GDYJSKT14-03)。
陈丽,女,讲师,硕士,研究领域为大数据技术及应用、信息系统管理。
