高速公路车辆行驶路径模糊匹配分析
2016-07-29桑美英
桑美英
(交通运输部科学研究院,北京,100029)
高速公路车辆行驶路径模糊匹配分析
桑美英
(交通运输部科学研究院,北京,100029)
摘要:高速公路车辆行驶路径在省界站处被自然分隔为两段,不能真实反映行驶车辆在高速公路上的路径信息。本文选取收费系统中车牌号、出入口时间、轴型、车货总重等字段信息,利用贝叶斯方法对分隔路径进行模糊匹配,从而得出行驶车辆在高速公路的全路径信息。
关键词:高速公路;行驶路径;贝叶斯;模糊匹配
随着高速公路的快速发展,全国各省高速公路联网收费系统也逐渐建立起来。目前高速公路联网收费系统仍为省内联网、省内统一清分结算,高速公路行驶车辆在通过各省省界站时对出省进省分别进行通行费结算,因此车辆行驶路径也同时被自然分隔为两段,不能真实反映行驶车辆在高速公路上的路径信息。高速公路的路径信息依托于联网收费系统中的车牌号、出入口时间、车型、轴型、车货总重等字段信息。为了能更加真实的反应区域间的经济往来,本文基于行驶字段信息来还原出入省界车辆在高速公路上的行驶路径。
1 高速公路基本情况
1.1高速公路省界收费站基本情况
由于各省(市)实行省(市)内联网收费,跨不同联网收费区域的高速公路行驶车辆的全路径在省界站被分隔,行驶车辆在省界站完成在行驶省份的交易额结算并领邻省卡在邻省行驶,从而在各省联网收费系统中分别生成一条收费记录。不同的省份省界站设置不同,具体分类见表1.
1.2高速公路字段指标基本情况
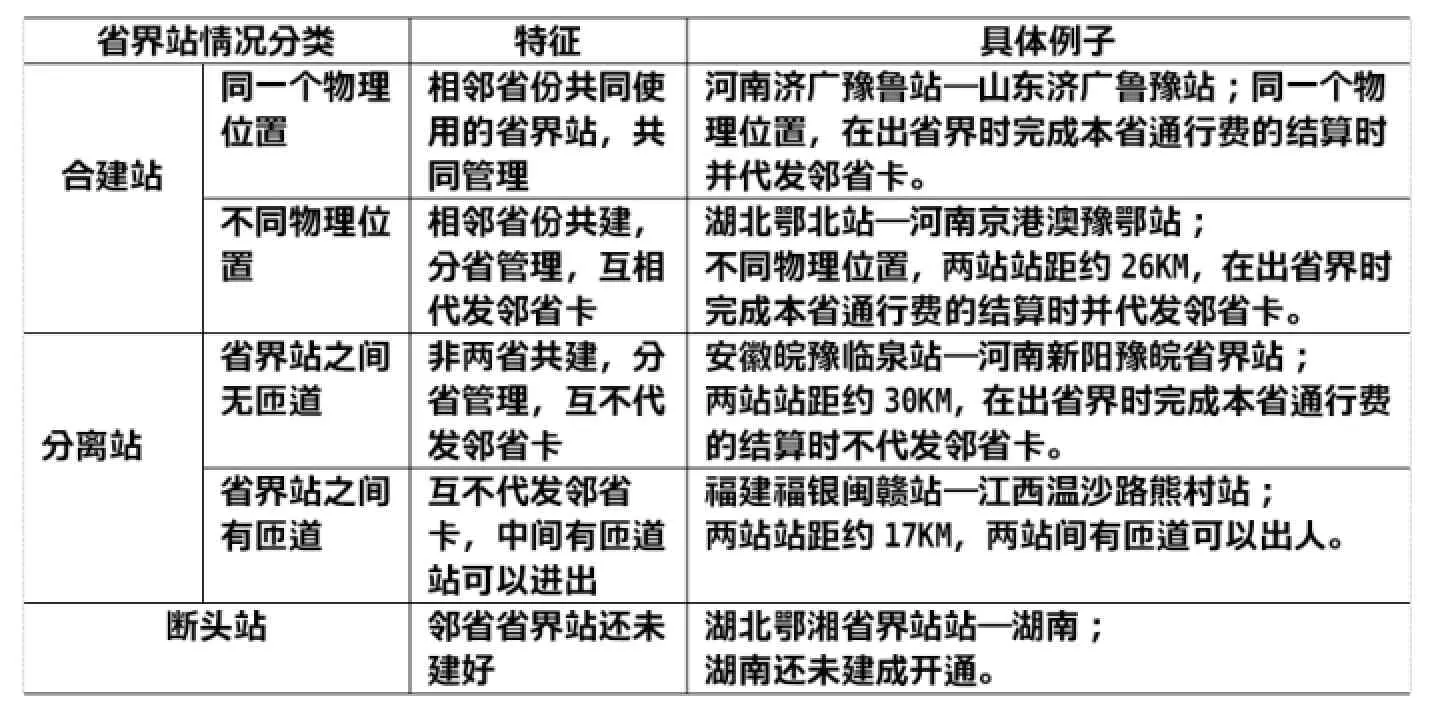
表1 省界站情况分类
高速公路原始收费系统里蕴含了大量的字段信息、卡口视频图像、车牌识别图片,其中包括出入口收费站编号、出入口日期及时间、出入口车道编号、出入口车牌号及颜色、出入口车型车种信息、收费金额、收费员信息、行驶里程、货重等近100个字段。在海量高速公路收费记录中,车牌号是一辆车的唯一标识,因此从逻辑上讲,车牌号、出入口时间、出入口站点编码的组合即可判断两条记录是否属于同一辆车的一次出行。但由于关键字段“车牌号”在各省收费系统中的质量参差不齐,存在缺失、识别错误、识别不完整等情况,需结合其他属性字段进行模糊判别。
2 行驶路径模糊匹配分析
2.1行驶路径模糊匹配指标分析
由于各省收费系统中“车牌”数据表现会有差异,不能作为唯一识别指标,需要关联其他指标。例如,车牌为豫A 12345的货车在从河南到湖北跨省行驶时,其行驶轨迹被分割为河南省内和湖北省内两段:在河南高速公路收费系统中,其行驶记录包含如车牌号、轴数、车货总重等指标,根据识别情况,各项指标数据为车牌豫A 1**4*、轴数6轴、车货总重20000千克;在湖北高速公路收费系统中,相应识别为车牌*A ***45、轴数6轴、车货总重21000千克,客观上无法直接通过车牌确认两条行驶记录为同一辆车跨省行驶记录,因此,需结合其他相关指标,如轴数、车货总重、进出收费站时间等指标,且这些指标能够共同识别唯一车辆。
2.2行驶路径模糊匹配思路
所谓路径匹配,即对于A、B两省的相邻省界收费站,判别A省省界收费站的某条收费记录与B省省界收费站的某条收费记录,属于同一辆车的同一次出行。将属于同一辆车的同一次出行的两条记录进行串接,还原其真实路径。如图一所示。
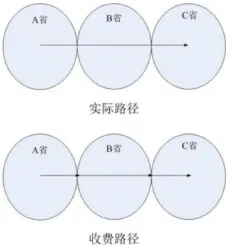
图1 按省(市)联网收费收费路径示意图
本文利用贝叶斯的方法对行驶车辆进行模糊匹配。在车辆匹配中,选取“车牌号”、出入口时间、轴数、车货总重等指标;即在分别读取A省出口收费站和B省入口收费站数据后,在合理的时间范围T内,匹配车牌完整且完全相同的记录,将成功匹配记录记入新文件,同时将不匹配记录记回原文件;通过对匹配记录的数据分析,分别得到匹配车辆的相关属性指标(时间、轴数、重量等)差异的分布特征,记匹配车辆进出站时间差的最大可能分布范围为t;同时运用统计模拟的方法计算出不匹配车辆的相关属性指标分布特征;对于每一个入口收费站车辆,以其入口记录时间为基准,选择t范围内的所有出口记录,运用贝叶斯定律计算彼此车辆间的贝叶斯匹配概率P,统计车辆间的贝叶斯匹配概率与车牌相似度M加权之和,将得分最高的出口车辆作为与该入口车辆匹配;由于可能存在多个入口车辆匹配同一辆出口车辆的情况,还需要在所有匹配记录中选择得分最高的那对匹配记录作为最终的匹配结果。
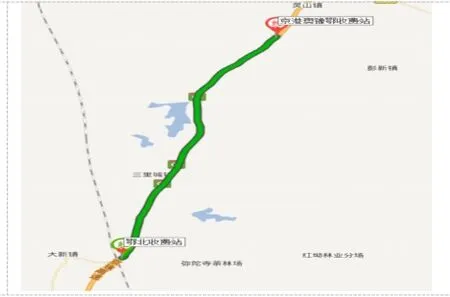
图2 京港澳豫鄂站(河南)和鄂北站(湖北)位置图
3 行驶路径模糊匹配实例应用分析
本文选取京港澳豫鄂界(河南)和鄂北站(湖北)2015年9月份某一天货车的数据量为例,该两站是一对共建省界站,分省管理,分别位于河南省信阳市罗山县和湖北省孝感市大悟县,两站站距约为26.2公里,正常通过时间间隔为17-19分钟。其位置如下图1所示。两站站编码和车流量总体情况如下表2所示。
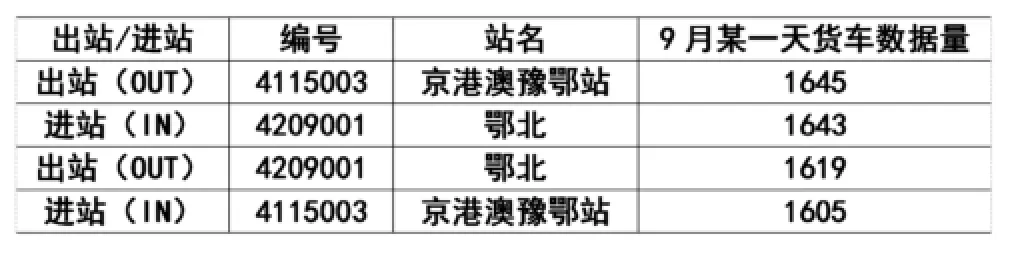
表2 京港澳豫鄂界(河南)和鄂北站(湖北)总数据量情况
3.1车牌号数据质量分析
京港澳豫鄂界(河南)和鄂北站(湖北)的的车牌号数据质量如表3所示。可以看出,两站的车牌号质量差异较大,湖北的鄂北站车牌号数据质量相当好,双方向完整车牌比例(不含车牌颜色)达到了96%以上;河南的京港澳豫鄂界数据质量相对较差,尤其出站方向,完整车牌比例不足50%。
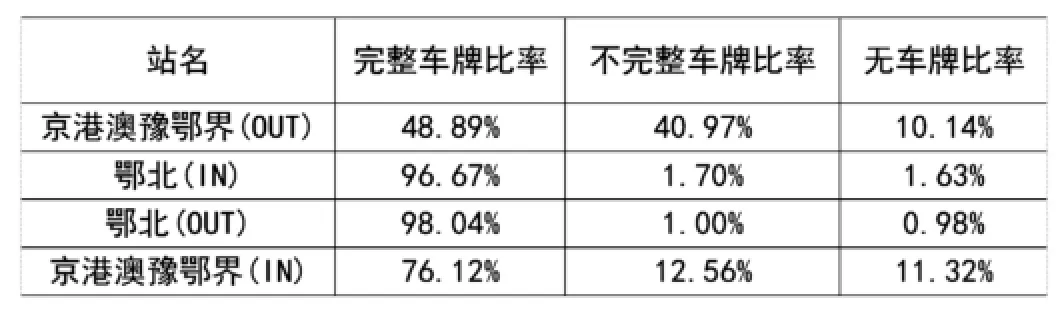
表3 京港澳豫鄂界(河南)和鄂北站(湖北)车牌号数据质量
由于无车牌和不完整车牌数据的大量存在,导致利用车牌号直接实现匹配的成功率不高,如下表4所示。为此,本文引入了贝叶斯方法对货车车辆通过模糊匹配提高车辆的匹配率。
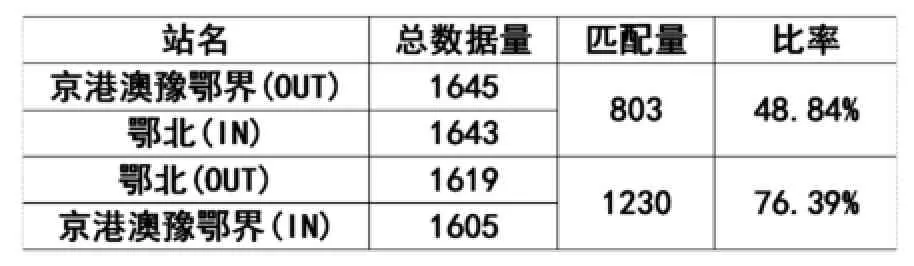
表4 京港澳豫鄂界(河南)和鄂北站(湖北)车牌直接匹配情况
3.2货车匹配过程及结果分析
考虑到车牌匹配的准确度更高和贝叶斯方法在干扰数据少的情况下准确度更高,货车匹配分为如下步骤:
1. 在读取2015年9月某一天京港澳豫鄂站、鄂北站出口收费站和入口收费站货车数据后,先在时间范围T(1000秒)内,匹配车牌完整且完全相同的记录。将成功匹配记录写入新文件,同时将不匹配记录写回原文件。
2. 利用构建的样例集数据,比较不同备选属性指标组合下的贝叶斯计算精度,最终获得车辆匹配效果最好的属性指标组合:“进出站时间差”、“进出站车货总重变化比”和“进出站轴差”三个指标。
3. 读取直接匹配的货车属性,计算车辆对的特征指标。在t时间窗(-150,50)秒内,计算得出每对车辆的“进出站时间差”、“进出站车货总重变化比”和“进出站轴差”上述三个指标后,再计算配对车辆这三个指标的分布特征。如下图3所示。
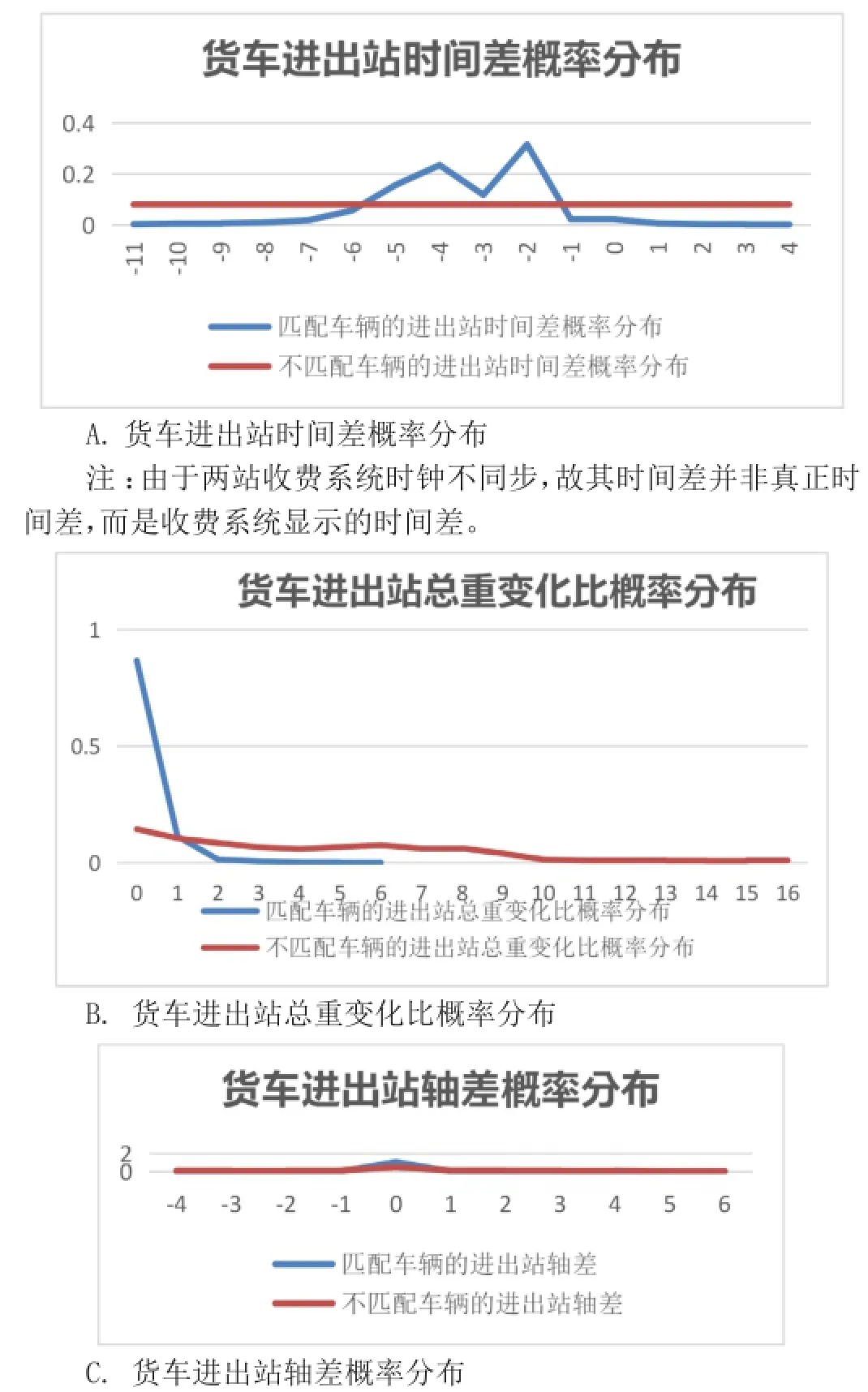
图3 京港澳豫鄂站(河南)和鄂北站(湖北)货车特征概率分布
4. 对于每一个入口货车,以其入口记录时间为基准,选择进出站时间差窗口(-150,50)秒范围内的所有出口车辆记录,计算三个指标取值,在此基础上运用贝叶斯定律计算彼此车辆间的贝叶斯得分。计算车辆间的贝叶斯得分与车牌相似度加权之和,将得分最高的出口车辆作为和该入口车辆匹配的车辆记录,并将匹配好的车辆从原数据集中删掉。匹配结果如下表5所示。
5. 从剩下的未配对车辆中(大部分是无车牌记录),重复上述贝叶斯计算,对于每一个入口货车,从满足进出站时间差窗口(-150,50)秒要求和贝叶斯得分阈值要求(P>=0.57)的车辆中,选择贝叶斯得分最高的车辆作为配对车辆。匹配结果示例如下表6。
4 结论
通过这一方法,车牌号可以直接匹配的有2489条记录;运用“贝叶斯匹配+车牌相似度”找到197条记录;运用单纯贝叶斯匹配也找到了275条记录,从测试数据看具有较高的准确度。该方法既充分利用了车牌信息,又减少了在无车牌数据配对时的干扰源,从而提高了数据配对的准确度,高效串接了在省界站处被分隔的行驶车辆,进一步摸清了行驶车辆在高速公路上的轨迹路径。
参考文献
[1] 卢桢. 高速公路路径识别设计及应用[J].科技与创新,2014 (12).
[2] 许永存. 基于车牌的高速公路路径识别技术应用研究[J].技术,2015(10).
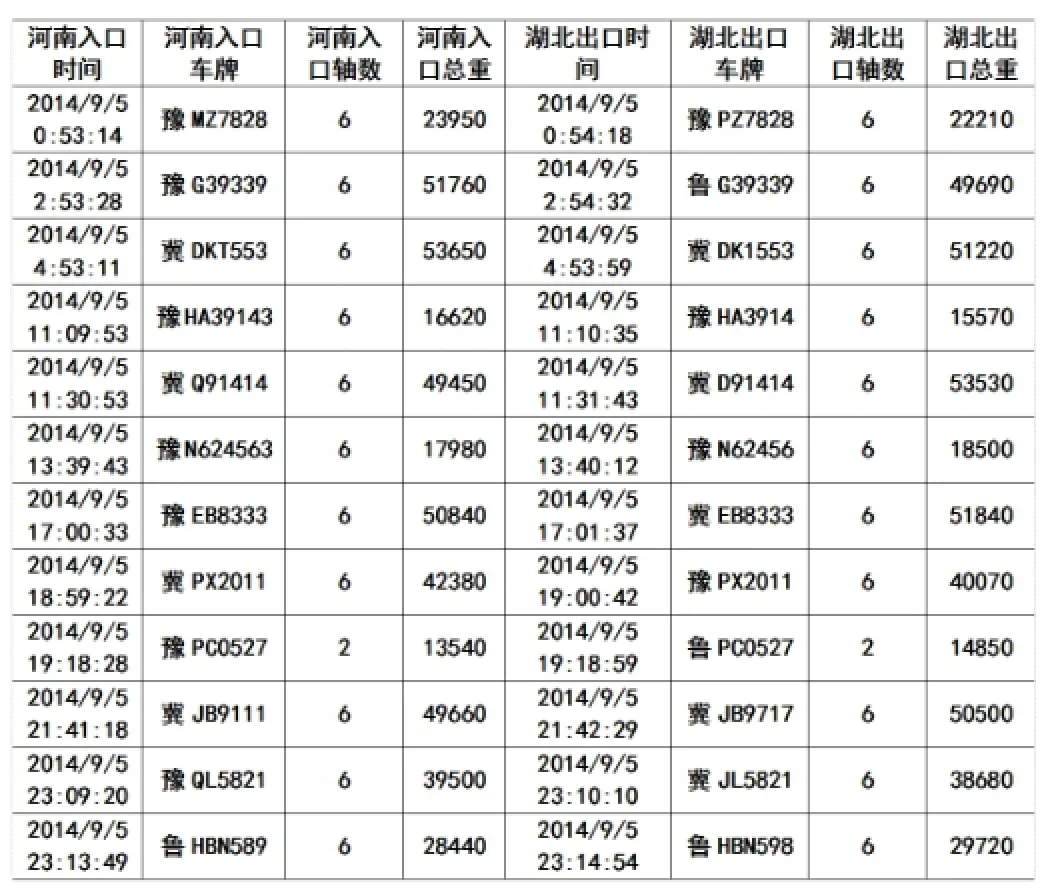
表5 京港澳豫鄂界(河南)和鄂北站(湖北)部分货车综合匹配结果
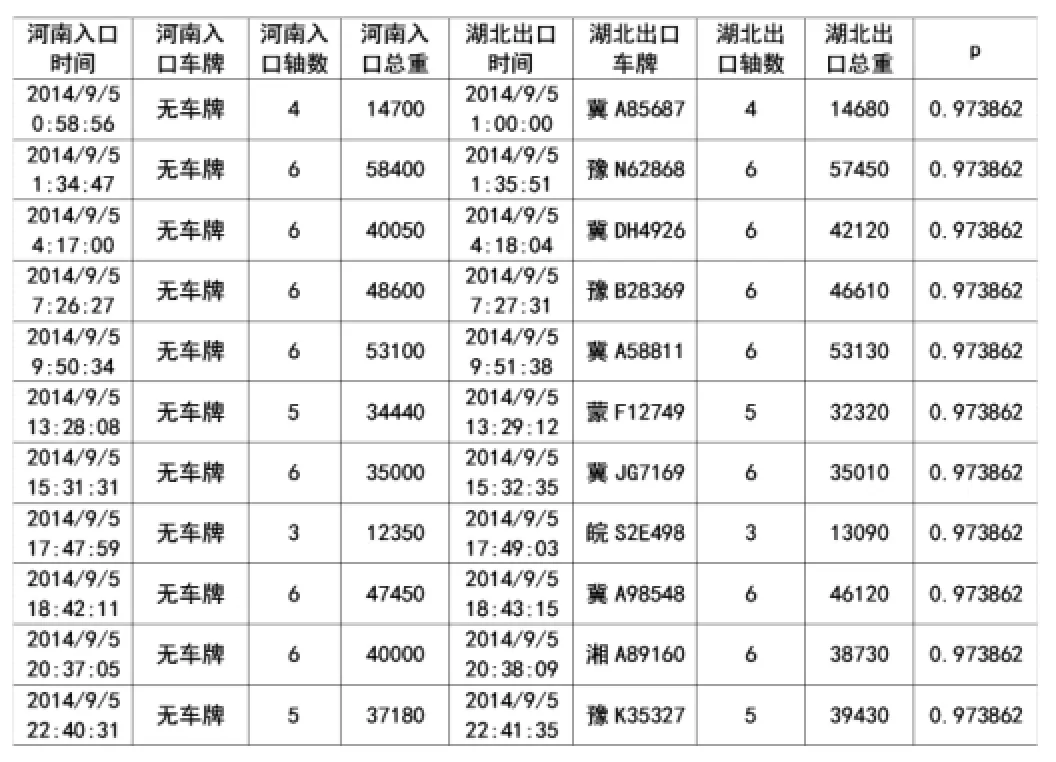
表6 京港澳豫鄂界(河南)和鄂北站(湖北)部分货车贝叶斯匹配结果

表7 货车路径模糊匹配结果
Analysis on the fuzzy matching of highway vehicle routing path
Sang Meiying
(China Academy of Transportation Sciences,Beijing,100029)
Abstract:Vehicle highway route in provincial boundary station is naturally separated into two segments,wh ich can not reflect the real route information of vehicle traveling on the highway. This paper selected lic ense plate number,a time portal,axle,truck weight from the charging system ,use Bayesian methods to separat e path for fuzzy matching,thus obtains full path information of the vehicles on the expressway.
Keywords:highway;travel path;Bayesian;fuzzy matching
