蚁群算法在网络学习中的应用
2016-07-22王瑞
王瑞
摘要:网络学习是通过计算机网络进行自主学习和协作学习的一种学习活动。与传统学习活动相比,网络学习具有共享丰富的网络化学习资源、以个体的自主学习和协作学习为主要形式、无时空限制等三个特征。网络学习一方面需要网络技术的支持,另一方面需要学习者掌握使用技术进行学习的知识和技能。技术支持不仅仅意味着给学习者提供一台计算机或者帮助他们与因特网相连;更在于它使得学习者与一个充满学习资源的知识世界相联系,为学习者提供了一个使其思想得以拓展的机遇。网络学习代表着一种新的学习方式。而蚁群算法作为一种智能算法,将其应用在网络学习这一领域,也会提高我们网络学习的效率,本文将会对这一内容展开探究。
关键词:网络学习;学习对象;蚁群算法
中图分类号:TP18 文献标识码:A 文章编号:1009-3044(2016)16-0195-04
1 网络学习的相关概念、背景
网络学习改变了传统的学习方式,一方面,互联网将全世界的各种信息资源联结起来,成为一个海量的资源库;另一方面,优秀教师或专家可以从不同的角度提供相同知识的学习素材和教学指导,任何人可以在任何地点进行网络访问,形成多对多的教学。在这种情况下,学习者对学习时间和学习内容就有了充分的选择余地,自主学习成为必然。传统的学习在时间上是有限制的,在空间上是狭小的,而网络学习使知识的传递不受时空限制,学习者可以依据个人情况来安排学习的时间和地点,可以在任何时间、任何地点向任何人学习,打破了学习的时空界线。网络学习的这种学习资源的丰富性、学习方式的个性化、学习时空的非局限性,大大增加了个体学习的自由度和效率。
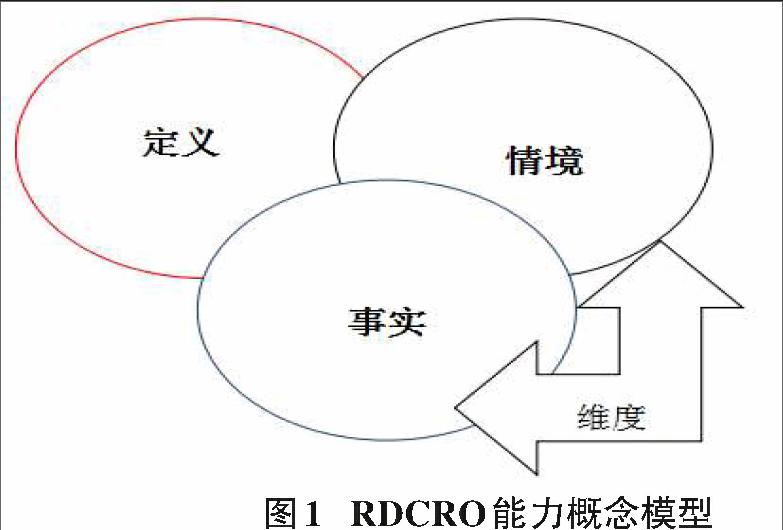
图1表示的是RDCEO能力概念模型,RDCEO的优点我们这里不做过多陈述了。
2 学习对象排序
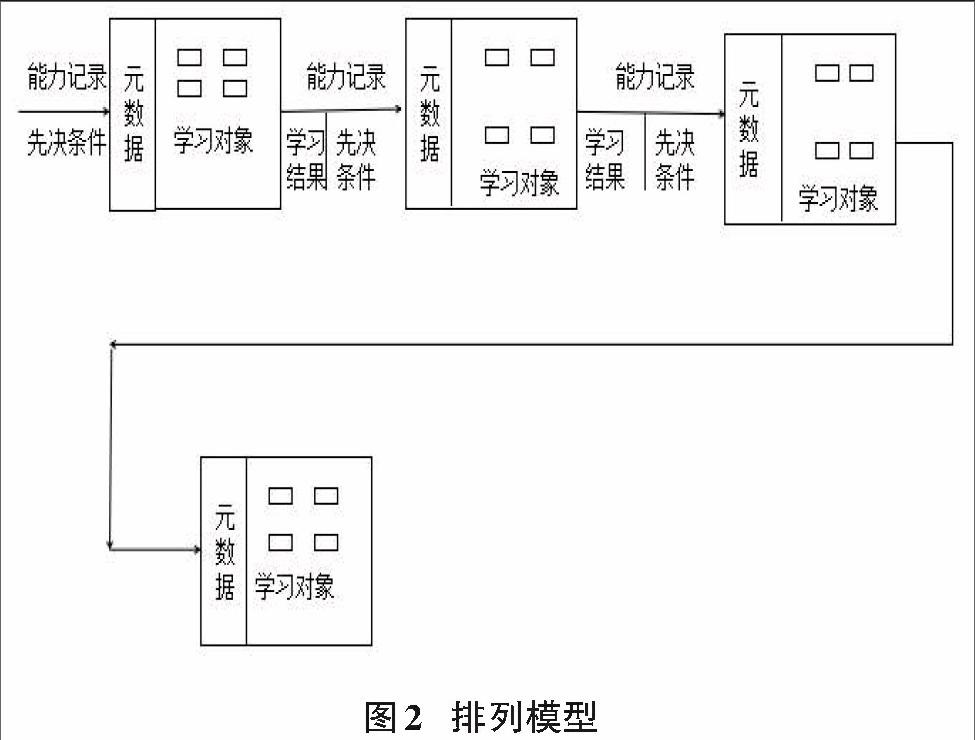
据RDCEO能力模型,能力记录与学习单元预先定义的先决条件和学习结果[1]相关联,元数据是与学习者相关的一些数据,并与学习对象关联。我们使用这种方法来模拟学习对象排序。通过构建的能力模型,我们可以构建一个包含 “能力”、“元数据”和“学习对象”的组件序列。寻到适合不同学习群体的学习路径的问题,可以公式为一个约束满足问题,解空间由所有可能的序列构成。我们设定n为状态总数,好的学习路径的可能序列就可以被表示为满足所有已建立的约束条件的n个学习对象。在序列中学习单元的排序代表了定义状态之间的过渡转换的操作,包含组件的学习对象自动排序由图2所示。
约束满足问题是一个三元组(X,D,C),其中X = {x1、x2、x3、x4、x5、x6、x7}表示有限集合变量;D表示将每个变量映射到相应域的一个函数D(X) ,?×表示对每对符合 0 ≤i 当所有来自以定义的约束满足问题的解是给定的元组的排列时,这样的约束满足问题被称作排列约束满足问题。它由四元组(X,D,C,P)表示,其中(X,D,C)是约束满足问题,P=(v0。。。vn-1)是|X| = n值中的一个元组。需要注意的是,排列约束满足问题的解S必须是(X,D,C)的解,且是P的完全排列。我们所研究的学习对象排序问题能够建模为一个排列约束满足问题。例如,我们将名称为1,2,3,4,5,6,7的学习对象的排列约束满足问题的解集设定为 S = {1,2,3,4,5,6,7},这样,就表示为: 此外,当一个粒子返回一个合适的值0,可以找到一个序列,满足所有的约束,因此算法的过程是完成的。适当函数也表现很好,如果约束集C为置换CSP定义准确。现在,我们是一个包含7个学习对象的序列只有一个可行的解决方案,约束集定义为C={ xi+1-xi>0:xiX,i∈1,2,3,4,5,6,}。更准确的定义是C={ xi-xj>0:xiX,xj{x1。。。。。。xi}}。如果我们考虑序列{ 2,3,4,6,7,5,1 },如果使用了第一个定义,那么标准的惩罚函数将返回1;返回值将是6,如果我们使用了第二个定义。要指出的是,第二个定义是更准确的。因为它返回将序列置换成一个适当的解决方案更好的一个数量交换的代表性。此外,第一个定义的缺点是,不同的序列在其距离到解决方案返回相同的合适值。例如,序列{2,3,4,5,6,7,1}, {1,3,4,5,6,7,2},{1,2,4,5,6,7,3}和{1,2,3,5,6,7,4}将会返回合适值1。但是,第二个定义用于解决约束问题。如教师,内容供应商和管理员的用户定义必要的数量的限制,因此,该系统将计算实际的约束,以保证算法的收敛。 3.2 蚁群算法的参数 值得一提的是,蚁群算法的一个重要优点是与其他遗传算法相比,它采用相对小数量的参数。在本文中,样本数量规模被设置为20只蚂蚁。由于完全知情的蚂蚁,没有必要考虑邻域的大小。 此外,模型给出了用户群体进行仿真测试:每个虚拟学习对象主体(即蚂蚁),给予一个浮点值来代表——0和1之间。这个值通常分布在学生人数平均数0.5以上以及标准偏差为1/3。每一个联系都有一个难度值,也在0和1之间。当一只蚂蚁到达给定的节点时,如果它的级别允许它验证节点,它就成功,否则,它就失败了。并且同时释放相应的信息素。该算法的一般标准是在与虚拟机构的电子学习门户相对应的虚拟图上执行的。节点和相应的权重之间的弧已被机构教学团队进行分配。样本案例被设定在现实情况下的20个节点、1000个弧线,并构成一个有意义的结构与实际规模。 该框架的基本蚁群算法如下;在每一次迭代中,利用给定的信息素模型,蚂蚁有概率得到考虑到CSP问题的解决方案。然后,一个本地搜索程序被应用到所构造的解决方案。最后,在下一次迭代开始之前,一些解决方案会被用于执行信息素更新。下面是关于这个这个框架的更多细节的解释。
初始化信息素值:在算法开始时,信息素值都被初始化为一个常量值xi,并且它是大于0的。
解决方案:蚁群算法的基本成分是对解决方案有一个概率性的启发尝试。此外,一个建设性的启发式安排解决方案——对解集合中的学习对象成分的序列。我们解决档案建设都是从空的部分解决方案=()开始的。此外,每一个步骤的当前解决方案都是从集合R()?C\{}里面添加可行解组来的。这是为了保证在每个步骤当中能够确保约束满足。让成为R()的一个解成分。的选择概率是相对于,的,表示信息素值,v是一个函数——对基于当前步骤的信息(也成为启发式信息)的每个有效解的成分进行分配。特别是,参数的值和,>0,>0。参数决定了信息素值和启发式信息的相对重要性。此外,启发式信息是可选的,但获得一个高算法性能它是必要的。在蚁群算法中选择下一个解决方案组件的概率我们称之为转移概率[3]。
工作算法:
初始化;
1)在系统中设置所有的初始参数:变量,状态,函数,输入,输出,输入轨迹,输出轨迹,然后设置初始信息素值。
2)将每只蚂蚁以空记忆的状态单独放置在初始状态。
While终止条件不满足时进行如下操作:
(1)构建蚂蚁方案:每个蚂蚁以应用连续函数的概率移动从一个状态到另一个状态来构建一个路径,这取决于:移动的吸引力和移动的轨迹水平。
(2)应用局部搜索。
(3)最佳路径检查:如果有改进,那么进行更新。
(4)更新路径:1、每条路径上的信息素以固定比例蒸发。2、对每一只蚂蚁进行蚂蚁循环的信息素更新。3、用一定数量的精英蚂蚁进行蚂蚁循环来增援最佳路径。
在信息素路径上创建一个新的种群样本:这个操作是基于适应度函数的情况下,以一定概率从样本中选择。
4 数值模拟
在这一节中,我们提供了一个电子学习过程模型和仿真结果来说明在之前的部分中所获得的算法的有效性。
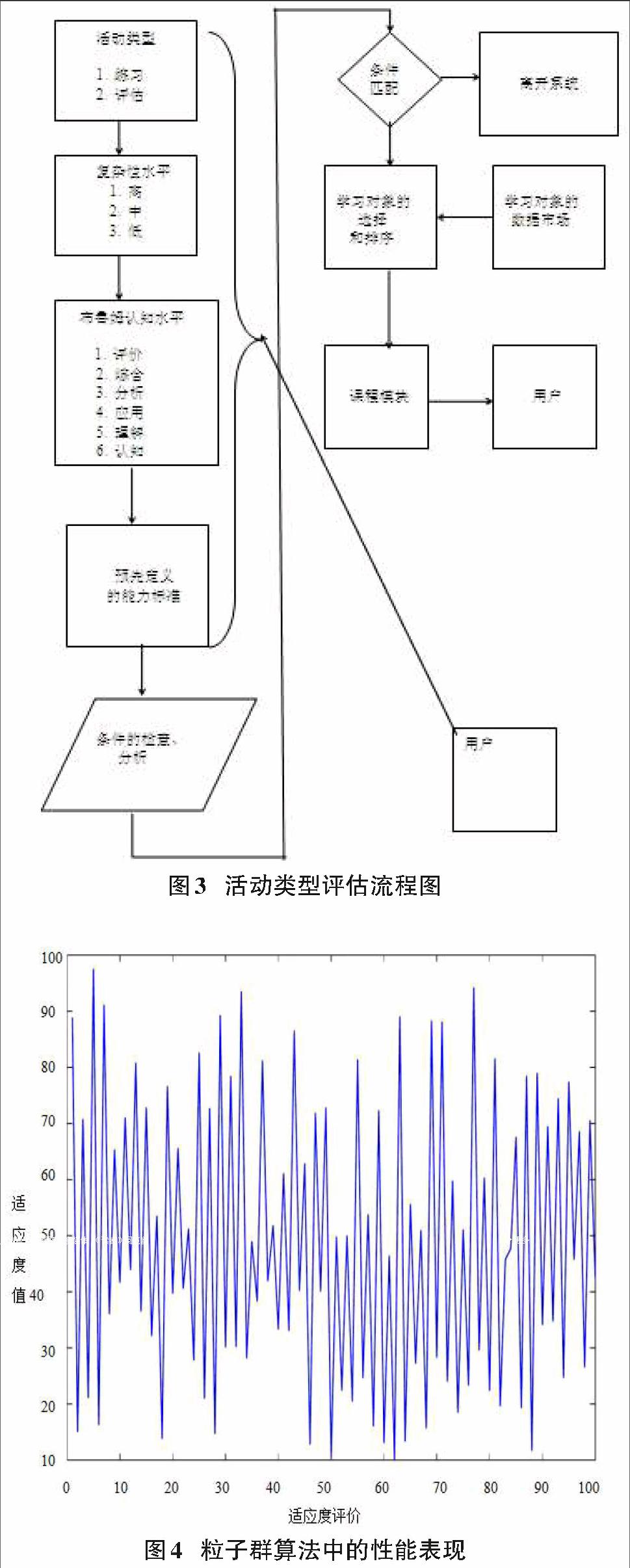
网络学习的过程的模型是这样的:学习者/用户输入关于他们要求的数据。输入被收集的活动类型,复杂度和布鲁姆认知水平。输入被收集之后,使用预先定义的标准对学习者的能力水平进行检查。如果标准匹配,学习对象的选择和排序在第B条得到解释。整体的电子学习过程模型,如图3所示。
我们考虑这样的一个用户或者是学生,进入研究生阶段在工商管理硕士——系统管理专业学习,并且完成了第一年的课程和需要发表的核心论文,将这些放在一个固定的序列中。然后,第二年的时候,用户将登录到网络学习门户,并且在他/她想要的完成的课程里选择活动类型、复杂程度和布鲁姆认知水平。Matlab中的GUI工具箱是用来开发正在建立中的上述简单步骤的选项的。如果用户像图3那样选择了活动类型的评估,复杂度的媒介和在布鲁姆认知水平的应用同时随着先决条件或者在应用程序级别上进行课程所需或限制,可供选择的课程列表就会在屏幕上显示。
根据先决条件下的被清零的课程数量,用户将被授权访问那些会让他们毕业的课程。如果约束是不满足的,用户将被提示按照布鲁姆认知水平中的较低层次去选择。在这个过程中,系统采用图2中的排序模型,并根据约束检验以及这些课程上的权重分配来对课程清单进行排序,这将给出一个如图4的输出。为了在仿真中得到验证,网络学习中的MBA课程中的学习对象排序问题将会到考虑到。尤其是,对学习对象自动排序的解决方案是在使用借助Matlab的算法得到的。更确切地说,为了说明本文提出的算法的有效性并且验证它,新的学习对象被提出并且会有仿真结果生成。在本文提出的算法中,在适应度函数中的起着重要的作用,并且所获得的解决方案取决于它们的参数选择。
我们进行了如下的参数仿真:
(1)工商管理硕士课程在前两个学期主要有7个课程。
(2)这些课程是按照固定的顺序排列的。
(3)然后,将会8个选修课程,在这两个学期间,当学生完成全部的基本课程的之后,可以选择全部所有的选修课程。
(4)学生标准在他们进入第三个学期之前必须要得到检查。
(5)为了选择选修领域,他们的基本水平将会受到测试检查。举个例子,选择系统专业的学生,在他们毕业之前的学习中,必须要有电子论文。
(6)同样的,附加约束也可以在不同的场景中进行设置。
我们从数值模拟的实验可以看出,该蚁群算法在解决网络学习这一问题中是有价值的,得到的结果是相对较优的。
5 小结
根据约束集,对网络学习中学习对象的自动排序进行了研究。众所周知的,运用到新的信息素更新写略的蚁群算法,被用于获取网络学习中的学习对象的自动排序,这使得该策略不同于现有文献中的其他状况。利用模型和测试来保证互操作性。此外,蚁群算法提供了一个优化的解决方案,并且相比于粒子群算法和遗传算法显示出了更好的结果。
参考文献:
[1] de-Marcos L, Barchinoj R, Martinez J,et al.New method for domain independent curriculum sequencing: A case study in a web engineering
[2] de-Marcos L, Barchinoj R, Martinez J,et al. New method for domain independent curriculum sequencing: A case study in a web engineering master program[J].Int. J. Eng. Educ.,2009(25):632-645.
[3] Dorigo M, Blum C. Ant colony optimization theory: A survey[J]. Theor. Comput. Sci. 2005, 344:243-278.
