云存储中小文件元数据管理研究与优化
2016-07-22林媛
林媛
摘要:为了提高系统的可扩展性及整体查询速度,云存储中通常将元数据与数据进行分开管理。在小文件存储系统中,集群规模的增大会导致存储元数据的主节点性能瓶颈。该文针对此问题,在小文件合成大文件技术的基础上,应用基于Vandermonde矩阵的RS算法改进了其冗余机制,减少了系统存储的元数据。引入group概念,对主节点应用元数据形成集群进行管理,并借鉴树型数据结构,设计了基于group的树型元数据结构,同时采用主、从节点共同存储元数据的方式,分散单一主节点存储元数据的压力。
结论表明,该文提出的方案有效地提高了云存储主从架构主节点及系统整体的性能。
关键词:云存储;元数据结构;元数据存储策略;树型数据结构
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2016)16-0118-04
Abstract: To improve system scalability and the overall query speed , cloud storage is typically metadata and data are managed separately. In a small file storage system , increasing the cluster size can cause performance bottlenecks master node storing metadata. Aiming at this problem , on the basis of small files into a large file technology, application -based RS algorithm Vandermonde matrix to improve its redundancy mechanisms to reduce the metadata stored in the system . The introduction of group concept , the main application metadata form a cluster node management, and draw a tree data structure, a group of tree -based metadata structures , while using the main way from the common node storing metadata, decentralized single master node pressure storage of metadata.
Conclusions show that the proposed scheme effectively improves the cloud storage from the main structure master and overall system performance.
Key words: cloud storage; metadata structure; metadata storage strategy; tree data structur
1 概述
云存储由于其便捷性,数据存储空间大且收费合理被广大用户所欢迎。因此,广大互联网行业纷纷推出自己的云存储产品。并且为了更加提高其体验性,研发者不遗余力的优化其技术。
当前云存储中主要有两种架构方式:主从架构及对等架构,主从架构即系统中有一个主节点,文件所有元数据存储于主节点中,剩余的为数据节点集群,主要用于存储文件数据[1]。对等架构是无主从之分,所有节点地位平等[1],但有一个元数据逻辑层,即系统元数据单层存储。主从架构由于其易扩展性及系统稳定性更高而更广泛地应用于云存储中。但主从架构有一个明显的缺点,就是当系统存储的是小文件,且小文件数量过多时,存储元数据的主节点会成为整个系统的性能瓶颈[2]。并且在云存储中,一般是采取多副本的形式进行数据备份,对于云存储来说,是很消耗资源的,且主节点存储的元数据还包括副本的元数据,当面对海量小文件,对主节点来说,压力还是很大的。目前对于主节点性能的解决方式,大多是多用几台机器存储,但这样的做法会减少查询效率,且浪费资源[2]
2 云存储小文件系统元数据相关技术研究
典型的集中式架构的分布式存储系统有Google的GFS[2],淘宝的TFS[2],Facebook的Haystack[2]。
在集中式架构中,元数据分为应用元数据及文件系统元数据。应用元数据全部存放于主节点中,用于定位文件在分布式集群中的机器、磁盘位置。文件系统存在于每个磁盘当中,文件系统的元数据存放于相应磁盘中,以inode形式存在。存储在主节点的应用元数据为文件与集群的映射关系,应用元数据包括文件key到集群机器的映射关系,及到磁盘的映射关系等,也包括每一个文件key对应的三个副本到集群的映射关系。
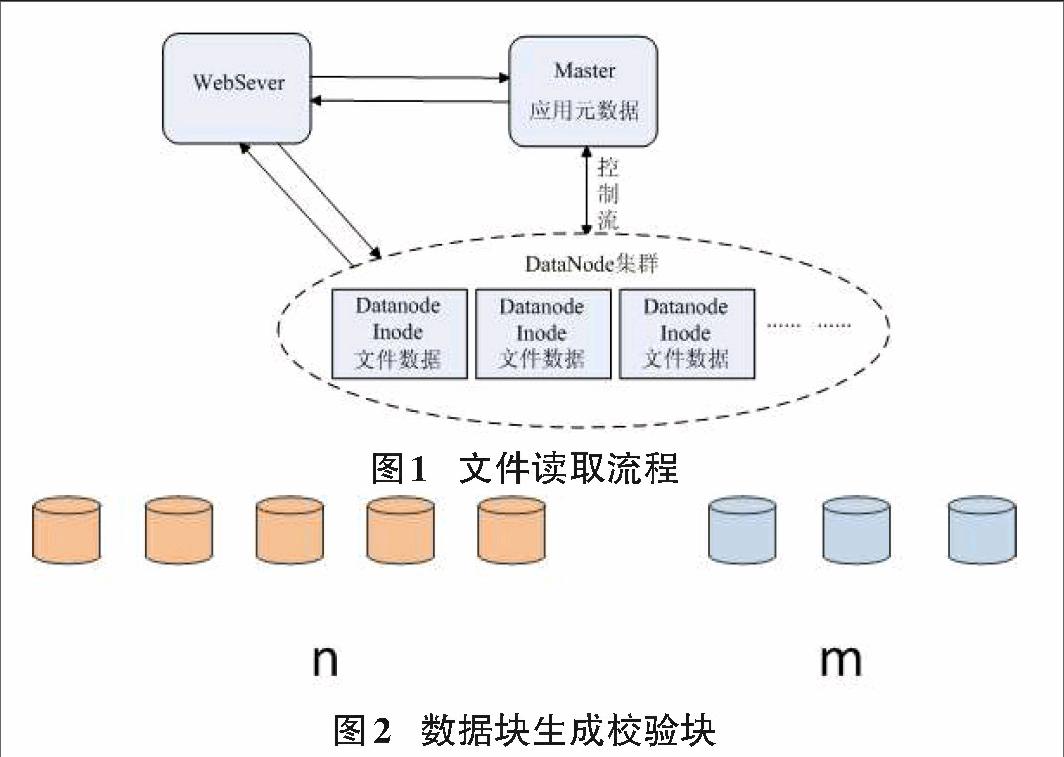
文件的读取如图1所示,WebSever首先向主节点请求文件的应用元数据,查询出文件在集群的位置,然后向数据节点查询文件的具体位置信息,取得数据。
每个小文件存储为一个文件会导致元数据太多难以被全部缓存,且过多的i/o操作会限制系统的吞吐量,为了减少小文件在文件系统的元数据i/o操作,主要是减少其系统存储的查询小文件所需的元数据,目前针对小文件元数据减少的方法是将多个小文件存储在单个大文件中,控制文件个数,维护大型文件,则文件系统只需维护其合成的大文件的元数据,大大减少了系统存储的查询所需元数据。
小文件合成大文件的方法减少了文件系统元数据数量,但是,由于每个小文件维护三个副本,文件系统同样需要维护对应三个副本的元数据,其并不利于内存的利用。且主节点维护的文件应用元数据数量为源文件元数据x,加上副本元数据数量3x,即4x,副本元数据量占源文件元数据量的三倍,当数据量大时,很容易造成主节点性能瓶颈。
3 云存储小文件系统元数据管理方式优化方案
针对集中式架构主节点性能瓶颈问题,本文应用基于Vandermonde矩阵的RS算法减少主节点应用元数据,然后引入group概念,对主节点应用元数据应用group进行管理,使其形成基于group的树型结构,改变了主节点应用元数据的数据结构,然后采用主节点与数据节点相结合的方式,改变其存储策略,从这三个角度,减少主节点的元数据数据量及信息量。
3.1云存储分布式小文件系统元数据数量方案改进设计
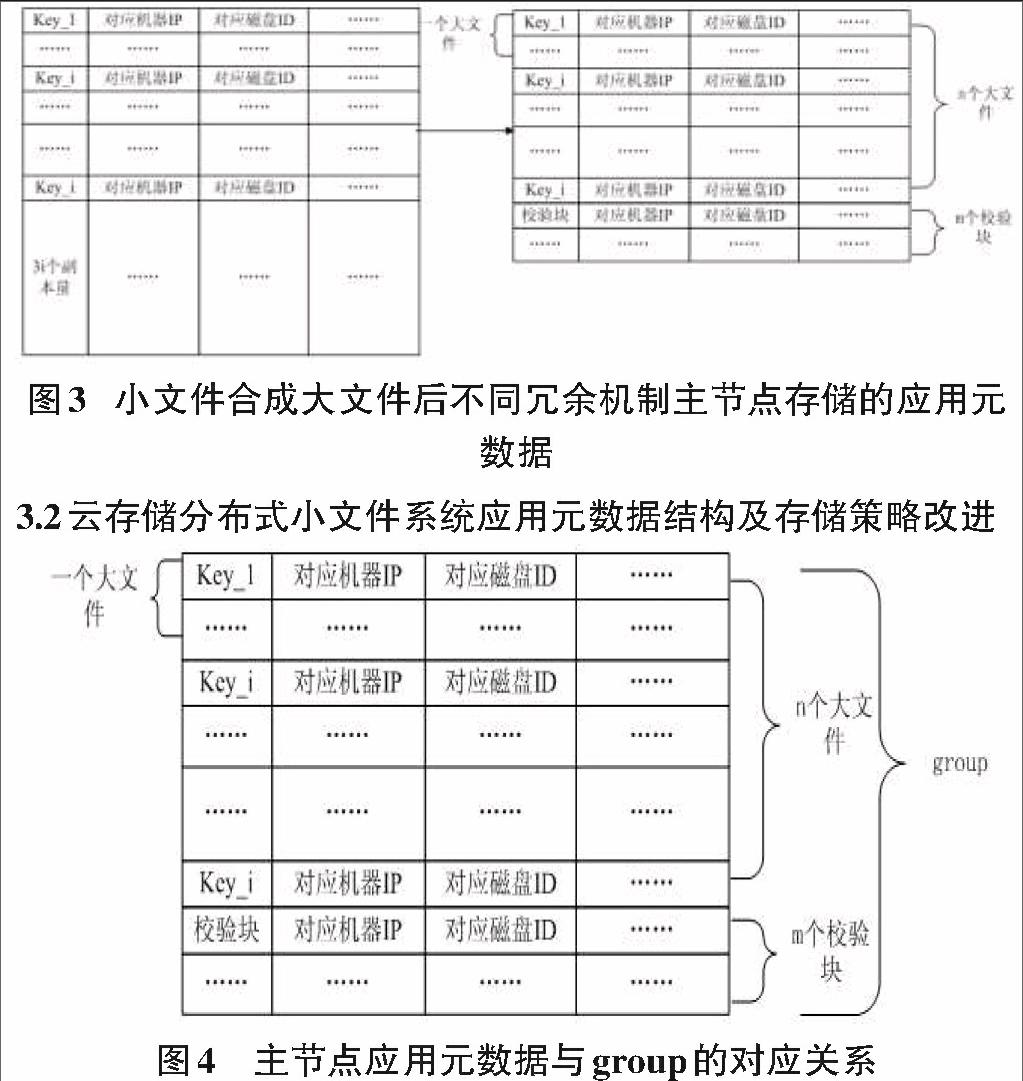
通过前面分析知,小文件合成大文件方式减少了文件系统所需的查询数据的元数据量,但是其3个副本的冗余方式也导致主节点存储的应用元数据量过多。即数据节点文件的冗余方式影响着系统所需存储的元数据数量。
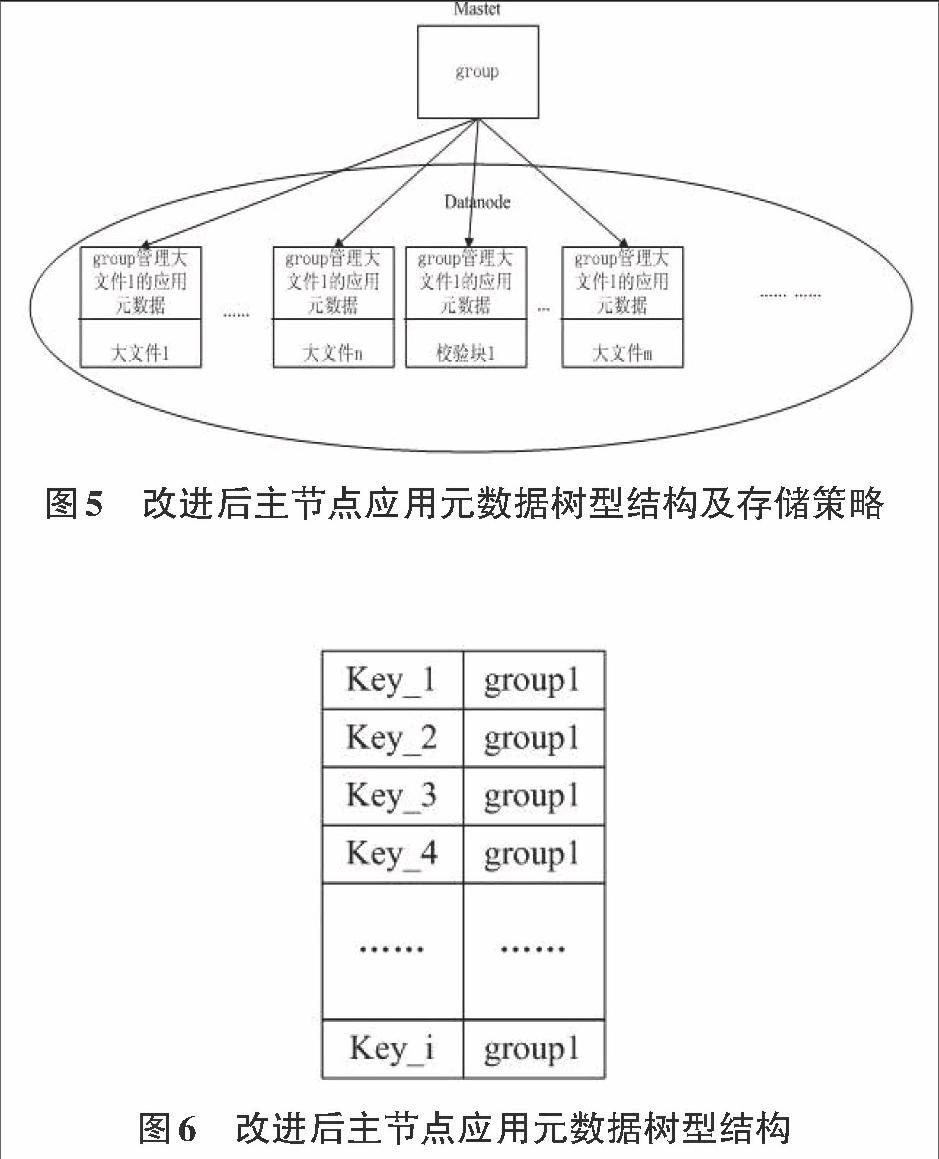
基于Vandermonde矩阵的RS算法是起源于通信领域的前向编码方式[2],由于其能够在接收方做到自动检测错误,并且能够运用传输方传输过来的恢复策略进行数据自动恢复,使其能够运用到数据存储领域,即对要存储的文件产生一定的编码算法,产生出一定的校验块,当有数据丢失时,运用一定的机制进行恢复。如图2所示,基于Vandermonde矩阵的RS算法利用n块数据块,生成m块校验块,且m 如有n个源文件,应用一个文件三个副本的方式,主节点需要存储4n个应用元数据,应用基于Vandermonde矩阵的RS算法对源文件进行冗余,生成m个校验块, 且m 这样做的好处是明显的,校验块生成的数量往往比源数据块的数量少,存储开销小于源文件三个副本的存储开销,由此,应用元数据的存储开销也变少,且文件数据能够达到高可靠性。 因此,本文将一定数量的小文件合成的大文件作为一个数据块,用n个数据块(n个大文件)生成其冗余的m个校验块,由此减少主节点存储的副本应用元数据数量。主节点存储的应用元数据化简为图3.6右,图左边为小文件合成大文件后主节点应用元数据的存储,但是因为文件的冗余方式是3副本形式,则其i个文件(n个大文件)有3i个副本,应用元数据也为3i个,图右边i个文件(n个大文件)有m个校验块,但m的数量远远小于3i个副本量的元数据。 3.2云存储分布式小文件系统应用元数据结构及存储策略改进 造成主节点性能瓶颈的原因主要是存储的元数据数量及元数据信息量,上一节运用基于Vandermonde矩阵的RS算法对小文件合成的大文件进行冗余,减少了应用元数据,为了进一步减少主节点存储的应用元数据数量及信息量,本文引入group概念,如图4所示,对i个小文件(n个大文件)及其所形成的m个校验块形成一个group,即这i个小文件的应用元数据及m个校验块的应用元数据形成一个group,然后将应用元数据信息交由group管理,使文件名与group形成映射关系。 为了实现逻辑上增大RAM-to-disk比率[3],逻辑上扩充存储应用元数据的内存空间,本文采取主节点与数据节点共同存储应用元数据,由此可扩展应用元数据的存储空间。且为了实现既使主节点管控整个系统的应用元数据,又减少其存储元数据数量及信息量,分散其一部分信息到数据节点,本文引入树型索引的概念,将应用元数据形成以group为根的树型元数据结构,使主节点只存储文件名与group的映射关系,并不再存储校验块的应用元数据信息(校验块应用元数据信息交由group管理),而数据节点存储大文件数据块的地方存储自己相应的group管理的元数据信息。 形成的应用元数据结构及存储方式如图5所示,主节点存放文件与group的映射关系,即以group的树型元数据结构的根节点,主节点在应用元数据管控中只管理最重要的,而将group管理的应用元数据的具体信息分发到各个文件块对应的节点中,即每个文件块存储自己对应的应用元数据,并加载到内存。由此减轻了主节点的压力。 4 实验与分析 4.1实验设计 本文针对改进后的元数据管理方式,形成分布式小文件系统SFS,对SFS设计测试内容如下: 1)由于上传操作是当数据上传后,未做任何处理之前,主节点收到数据后就会给客户端返回OK,因此,采用单线程在外网的情况下上传1万、3万、5万文件,并与NFS文件系统作对比,分析SFS的上传性能。 2)下载操作,为了分析SFS优化过的元数据管理,对系统采取多线程下载,在不同多线程下载的情况下,与传统云存储的下载情况进行对比,分析本本文改进的元数据管理方式是否对系统性能发生了提高。下载操作分为顺序下载及随机下载操作。 测试环境:集群共配置19台机器,一台测试客户端,1台名字节点(Namenode),用于存储一级元数据,1台名字节点的备机,16台数据节点(Datanode),用于存储数据及相应的元数据。机器采用Intel(R) Xeon(R) CPU E5620 × 2的CPU,12G内存,操作系统centos 6.5 。 4.2文件系统上传测试 上传测试中,本文选用分布式文件系统HDFS进行对比测试,测试数据选取如表5.3,通过对SFS的整体性能测试及HDFS的性能测试进行对比,来分析SFS改进的元数据管理方式的性能。 从表2看出,随着小文件数量的逐渐增加,SFS上传文件的吞吐量随着文件数量的增加而增大,并且当小文件数量达到14万个时,系统吞吐量依然在增加,说明系统工作良好。HDFS一开始的时候吞吐量比SFS的吞吐量大,但是随着小文件数量的增加,系统吞吐量增长缓慢,这是由于HDFS主要是处理大文件所引起的,小文件会导致过多的I/O消耗。图5.2清晰的表现了两者的对比。
从图7中看出,在小文件数量逐渐增多的情况下,SFS的吞吐量持续增加,而HDFS的吞吐量变化不大,这是由于HDFS里面可以存储大文件及小文件,系统对于文件的处理是进行分块处理,当小文件数量增加,会导致HDFS的I/O消耗增加,所以系统性能吞吐量增加并不明显,说明SFS对于小文件系统性能良好,改进的元数据管理方式提高了系统性能,适合于小文件系统存储。
4.3文件系统下载性能测试
本节主要测试实现的主从架构中存储元数据主服务器的性能,为了对比改进的元数据管理方式是否对分布式小文件系统元数据主服务器性能及整体性能提高,本节采取将元数据全部放置在主节点与改进的元数据管理方式进行对比,由于系统整体配置一样,环境一样,只是元数据管理方式不一样,因此,对系统整体性能测试也即表现了元数据管理方式的性能。
在所述测试环境及测试目标的情况下,对SFS及传统云存储进行顺序下载测试,采取50个线程进行下载,测试数据分为5组,最小从10000个文件开始,然后线性递增,由于本文针对的是云存储小文件系统,因此提出的文件大小不超过64K,具体选取的测试数据描述如表3:
从图8看出,SFS设计的元数据管理方案对比传统云存储元数据管理方案使系统整体的下载时间降低了。由于SFS只将分布式文件的一部分元数据存储于主从架构的主节点,即将基于group的树型元数据的group信息存储于主元数据服务器节点,剩余的精简过的元数据分布于响应数据节点的内存中,查询一个数据的方式是先在主节点查询其位置信息,再到数据节点查询数据,本文设计的数据节点的元数据是分布于查询数据对应的节点内存中,并没有多余的通信开销,且元数据主服务器节点由于只存储文件对应的group信息,存储压力小,性能必会得到提高,而传统的云存储是将分布式文件系统所有元数据都存储于主节点,且主节点元数据一般存储于数据库中,所有元数据存储于主节点会导致执行查询多个表的操作,且主节点的压力是比较大的,性能也会受到一定的影响。就是说,就算系统高负载情况下,SFS的响应时间会比传统的快,一样能够提供更好的服务。
5 结论
本文分析了云存储小文件系统元数据管理存在的问题,该问题导致了小文件系统主从架构主节点性能瓶颈,即系统元数据结构、元数据放置策略及系统存储的查询所需的元数据数量问题, 针对此问题,改进了主从架构小文件系统元数据管理方式,利用基于Vandermonde矩阵的RS算法改变冗余方式减少其元数据数量,引入group概念,对元数据形成集群管理,设计了基于group的树型元数据结构,并在此基础上采取主从节点相结合共同存储元数据的方式分散主节点压力。本文改进的元数据管理方式提高了主节点及系统性能,但之后主节点单点故障问题还需进一步研究。
参考文献:
[1] 赵黎斌. 面向云存储的分布式文件系统关键技术研究[D]. 西安: 西安电子科技大学, 2011.
[2] Reed-Solomon Codes[J/OL]. School of computer Science.
