基于OpenCL的尺度不变特征变换算法的并行设计与实现
2016-07-19许川佩王光
许川佩 王光

摘要:针对尺度不变特征变换(SIFT)算法实时性差的问题,提出了利用开放式计算语言(OpenCL)并行优化的SIFT算法。首先,通过对原算法各步骤进行组合拆分、重构特征点在内存中的数据索引等方式对原算法进行并行化重构,使得算法的中间计算结果能够完全在显存中完成交互;然后,采用复用全局内存对象、共享局部内存、优化内存读取等策略对原算法各步骤进行并行设计,提高数据读取效率,降低传输延时;最后,利用OpenCL语言在图形处理单元(GPU)上实现了SIFT算法的细粒度并行加速,并在中央处理器(CPU)上完成了移植。与原SIFT算法配准效果相近时,并行化的算法在GPU和CPU平台上特征提取速度分别提升了10.51~19.33和2.34~4.74倍。实验结果表明,利用OpenCL并行加速的SIFT算法能够有效提高图像配准的实时性,并能克服统一计算设备架构(CUDA)因移植困难而不能充分利用异构系统中多种计算核心的缺点。
关键词:
尺度不变特征变换算法;开放式计算语言;复用内存对象;细粒度并行;异构系统
中图分类号: TP391.4 文献标志码:A
0引言
以尺度不变特征变换(Scale Invariant Feature Transform, SIFT)算法[1]为代表的基于特征的图像匹配方法近几年发展迅速,该算法对光照、角度或尺度变化的图像都有较好的匹配精度和适应性,但实时性差。为了提高实时性,在此基础上又衍生出了主成分分析(Principal Component Analysis, PCA)SIFT[2]、快速鲁棒特征(Speed Up Robust Feature, SURF)检测[3]等改进算法。这些改进的算法尽管在速度方面有所提升,但实时性仍然不能满足实际应用要求且在抗尺度和抗旋转方面性能都有不同程度的下降,因此仍无法取代经典的SIFT算法[4]。
近年来随着图形处理器(Graphics Processing Unit, GPU)计算能力的不断提升,利用GPU天然硬件并行的特性来加速非图形通用大规模运算逐渐受到人们的青睐,目前较为成熟并得到广泛应用的GPU并行编程模型为英伟达(NVIDIA)公司开发的统一计算设备架构(Compute Unified Device Architecture, CUDA)模型。文献[5-7]利用CUDA实现了SIFT算法关键步骤的GPU并行加速,取得了一定的加速效果。文献[8-9]在移动GPU平台上利用开放式计算语言(Open Computing Language, OpenCL)实现了SIFT算法的并行加速,相对于移动中央处理器(Central Processing Unit, CPU)取得了4.6~7.8倍的加速效果。另外,完成同样的计算,GPU比CPU的功耗低87%,即利用OpenCL实现的GPU并行运算相对于传统的CPU具有更高的性能功耗比,但以上方法大多采用步骤分离的优化,没能充分利用GPU全局内存以及算法各步骤的中间计算结果,加速效果受显存带宽的制约。
另外利用CUDA实现的算法只适用于NVIDIA显卡,移植困难,而目前的计算机系统大多是“CPU+协处理器”的异构系统[10],这使得CUDA无法充分利用异构系统中不同类型的计算核心。具有跨平台特性的开放式并行编程语言OpenCL的出现为解决此问题提供了契机,利用OpenCL设计的并行算法能够在CPU+(GPU、数字信号处理器(Digital Signal Processor, DSP)、现场可编程门阵列(FieldProgrammable Gate Array, FPGA)等异构系统间移植[11-12],该特性使得经OpenCL优化的算法能够摆脱对硬件平台的依赖。自2010年OpenCL1.1发布以来,对OpenCL技术的应用研究逐渐兴起。陈钢等[13]对OpenCL内存操作作了深入的分析;Yan等[14]利用OpenCL实现了SURF算法的并行加速。OpenCL编程相比CUDA更为复杂[15],在软件开发方面也面临更多的挑战和困难,目前在PC平台上还没有利用OpenCL并行优化的SIFT算法出现。
针对以上问题,本文对SIFT算法步骤及数据索引方式进行重构,提高其并行度,然后通过优化内存读取、合理利用OpenCL内存层次等策略对该算法进一步优化,在NVIDIA GPU平台上实现了SIFT特征的快速提取。为研究OpenCL的可移植性,将优化的GPU版本移植到Intel双核CPU平台上,实验表明优化后的算法在两种计算平台上的实时性都有一定提升。
1SIFT特征提取算法流程
SIFT算法最早由Lowe[1]在1999年提出并于2004年完善,由于其良好的匹配特性,目前已得到广泛研究与应用。SIFT特征点提取实质是在不同尺度空间上查找关键点(特征点),算法基本步骤如下。
1)尺度空间构建。
2)高斯差分金字塔空间构建。
3)DOG空间极值点检测。
DOG空间极值点检测就是将DOG图像中每个像素与它同尺度的8邻域点及上下相邻尺度对应的9×2个邻域点进行比较,若为极值点则作为候选特征点,记录其位置和对应的尺度。为获得更精确的特征点位置,在候选特征点处进行泰勒展开,得到式(4):
D(x)=D+DTxx+12xT2Dx2x(4)
其中:关键点偏移量为x此处的偏移量x,与后面的x的命名重复,不太规范,因一篇论文中,一个变量仅能代表一个含义,若包括两个含义,则指代不清晰,是否可以用另一个变量对此进行说明?
回复:这两个变量x是使用字体来区分的,一个是粗斜体表示向量,一个是细斜体,表示普通变量。是可以区分的。
这个公式是经典文献[1]中此算法的原作者提出的公式,也是用这种方式表述的。为保持统一,所以我觉得可以不用修改。=(x,y,σ)T;(x,y,σ)在该极值点处的值为D;令D(x)x=0,可通过式(5)求得极值:
=-2D-1x2Dx(5)
在Lowe[1]的文章中当在任意方向上的偏移量大于0.5时,认为该点与其他关键点很相似,将其剔除;否则保留该点为候选特征点,并计算该点对应的尺度。
4)特征点主方向计算。
5)SIFT特征矢量生成。
将特征点邻域内图像坐标根据步骤4)计算出的特征点主方向进行旋转,使得特征向量具有旋转不变性,旋转后以特征点为中心划分成4×4个子区域,在每个子区域内计算8方向的梯度方向直方图,即可构成4×4×8共128维SIFT特征矢量。
2SIFT算法的并行化重构
OpenCL标准将内核可用的内存分为私有内存、局部内存和全局内存/常量内存等类型[16],所以在利用OpenCL优化算法时,充分挖掘GPU内存的存储层次,合理分配工作组大小是提高并行运算效率的关键[17]。为提高算法并行度方便数据划分、降低内存带宽要求,本文对SIFT算法作了以下重构。
1)步骤合并。将构造尺度空间、创建高斯金字塔及极值点检测三步骤统一设计,目的是充分利用OpenCL的global memory和local memory的访问机制,使得这3个步骤的中间计算结果最大限度地在显存中完成交互,减少内存与显存间的数据交换次数,隐藏带宽延时。
2)步骤拆分。将极值点定位分为极值点坐标检测和极值点精确定位两步:第1步只返回极值点坐标,目的是辅助主机端完成内存分配;第2步完成极值点精确定位。
3)重构数据索引。本文全面摒弃基于队列的特征点索引方式,而是采用线性存储的方式管理特征点集,这对OpenCL内核的工作项划分、提高数据读取效率以及降低内存访问冲突都非常有效。
4)任务细粒度并行。经过数据索引重构,在OpenCL的内核运行时,可方便地部署大规模的工作组和工作项,实现计算任务的细粒度划分。经过以上设计后不仅能提高数据访问速度,而且能够避免潜在的内存访问冲突。
3SIFT算法的OpenCL实现
图1为并行设计的SIFT特征提取流程。整个设计充分利用全局内存以降低数据传输延时。主机端首先分配相应内存对象,然后依次入列高斯模糊、DOG金字塔和极值点检测3个OpenCL内核,完成后即可生成尺度空间和DOG金字塔,从全局优化考虑,将这两部的结果驻留在全局内存中,只返回经压缩的极值点坐标。接着按序运行极值点精确定位、特征点方向计算和特征向量生成3个步骤,计算完成后即完成特征提取全过程。整个流程仅有返回极值点坐标和返回特征点结果两次读回操作,其余的中间结果全部在显存中完成交互,提高数据利用率,降低显存带宽要求。
3.1高斯模糊+DOG+极值点检测内核设计
深入发掘算法的并行潜力,充分利用OpenCL的内存层次、合理配置工作项数量和工作组大小是性能提升的关键,也是内核设计的难点。
3.1.1高斯滤波内核设计及工作项分配
为降低计算量,将二维高斯变换分解为沿水平和垂直方向的一维变换,分解后可减少(N2-2×N)×W×H次乘法运算(N为高斯核大小,W、H为图像的宽和高)。由于每个像素相互独立,所以在NDRange函数入列高斯滤波内核时将工作项大小设置为W×H-N,即每个工作项完成一个像素的卷积。另外,进行卷积时相邻像素(图2黑实线框内数据)要重复读取图2灰色部分的数据,为提高读取效率,本文通过配置工作组,实现原始数据在局部内存中共享。图2为水平高斯核宽度为7、工作组大小设置为8时的数据分配,图2表示每8个工作组读取14个数据,完成8个点(图2黑虚线框内数据)的卷积运算。
在工作组内共享局部内存通常能提高计算性能,但并不绝对[18]。为找到工作组的最佳大小,本文测试了不同工作组大小时,宽度为11的高斯核对分辨率为1280×960的图片进行水平卷积的耗时,测试结果如图3所示。随着工作组的增大,耗时逐渐减少,当工作组大于128后,耗时基本不再改变,又因为局部内存的限制,工作组不宜太大,于是本文将工作组大小配置为128。如此设计需考虑同一工作组中工作项的同步化问题,本文采用OpenCL提供的barrier(CLK_LOCAL_MEM_FENCE)障碍函数来实现,垂直滤波与此类似,不再赘述。
3.1.2DOG金字塔构建
此步骤的内核有两种设计方法:1)一次入列内核,只将高斯金字塔相邻两层相减,得到一层DOG图像;2)一次入列内核,将高斯金字塔整组图像传入内核,计算完成后即可得到一组DOG图像。
经实验发现,第2种方法数据利用率高,耗时较短。又因为高斯金字塔每组层数固定,所以第2种设计的参数也固定,于是本文采用第2种设计方法,数据划分如图4所示。为进一步提高运算效率,对数据的运算都以float4型向量进行,共配置(W×H+3)/4个工作项,即每个工作项完成一组高斯金字塔对应位置(图4单个虚线框内数据)的float4型向量相减。
3.1.3极值点检测及内核精确定位
入列极值点精确定位内核前,主机端需预先分配内存,而事先并不知道需要为多少个特征点分配内存,所以本文将极值点检测和精确定位作为两个内核先后入列,为减少数据传输,极值点检测内核只返回压缩的极值点坐标数组。
极值点检测内核计算完成后,根据返回的极值点坐标在CPU端统计极值点位置和个数N,然后为N个特征点分配内存,如图5所示(实际分配1.5×N个,Lowe[1]文中指出实际的特征点数会是极值点数N的1.15倍左右)。图5中每个虚线框用来保存一个特征点的完整信息。最后入列极值点精确定位内核,每个极值点配置一个工作项,计算出的精确坐标按工作项索引存入图5对应的位置。
3.2计算梯度方向直方图
至此,已经得到每个特征点的坐标、尺度,并按线性存储在图5所示的全局内存中。
因为每个特征点在内存中按线性排列,相互独立,所以为每个特征点配置一个工作组来计算梯度方向直方图,工作组分配如图6(a)所示。将工作组内工作项设置为2维,为确定工作组最佳大小,本文尝试了{1,RAD}、{2,RAD}、{4,RAD}、{8,RAD}四种方式,经测试{2,RAD}效果最好(其中RAD为特征点的邻域宽度)。当RAD=5时,每个工作组分配10个工作项,工作组中的数据分配如图6(b)所示,图6(b)中标有相同数字的像素被同一工作项处理。为实现数据共享,在工作组local_memory中构建方向直方图,这时必须使用OpenCL提供的atomic_add原子累加操作才能保证多个工作项同时累加直方图同一位置时不会出错。直方图生成后统计出大于直方图极值80%的点的个数和角度,作为独立的候选特征点,将结果填入图5中对应的位置。
3.3特征向量生成
计算出特征点主方向后,即可入列特征向量生成内核,因数据重构后各特征点在内存中线性存储且可独立计算,所以为每个特征点分配一个工作组。又因每个特征点邻域被划分为4×4个子区域,所以为每个工作组配置16个工作项分别计算每个子区域的8个方向,数据划分如图7。图7中每个箭头的长度表示每个方向的梯度累计值,箭头越长代表值越大。所有工作组计算完毕后,整个SIFT特征提取算法执行完毕,提取出的特征点全部存储在图5所示的线性内存中。
利用以上方法对两幅图片进行特征提取后,即可利用欧氏距离准则完成两幅图片特征点的粗匹配,然后用随机抽样一致(RANdom Sample Consensus, RANSAC)算法对粗匹配对进行提纯,计算得到两幅图片之间的变换矩阵,完成两幅图片的匹配。
4优化后的算法在CPU上的移植
为进一步验证OpenCL的可移植性并比较OpenCL在不同平台上的加速性能,本文将优化后的OpenCL_GPU_SIFT算法移植为能在CPU上运行的OpenCL_CPU_SIFT版本。尽管OpenCL具有跨平台特性,但由于硬件资源的差异,仍需注意以下两点:
1)本文采用的Intel core i5 3210m CPU不支持OpenCL 32位原子操作,所以在3.2节的内核设计中无法使用atomic_add原子累加操作,只能将3.2节的工作组大小配置为1,此时每个工作组中只有一个工作项,因而不能实现局部内存共享。
2)工作组中工作项的数量上限一般受限于两点:一是设备所能提供的资源数,二是内核所需的资源数,这里的资源主要指的是局部内存。针对3.2节的内核,GT635m GPU的局部内存为47KB(K表示×1024),工作组上限为512,而Intel 3210m CPU的局部内存只有32KB(K表示×1024),工作组上限为352,所以工作组大小一定要根据硬件平台来设置,这点尤为重要。针对以上两点修改后得到的OpenCL_CPU_SIFT版本即可运行于Intel 3210m CPU中,可见OpenCL具有较好的可移植性。
5实验结果及分析
5.1实验平台
本实验的实验平台CPU为Intel Core i5 3210m,双核心四线程,2.5GHz;GPU采用NVIDA GeForce GT 635m,核心频率660MHz,96个流处理器单元,128位总线宽度;开发环境为Vs2013,OpenCV版本2.4.9,OpenCL版本1.1。
5.2实验方法
本文实验的代码是在Rob Hess维护的SIFT算法(http://robwhess.github.io/opensift/,本文称之为CPU_SIFT)的基础上修改而来。实验分别测试并行化的OpenCL_CPU_SIFT和OpenCL_GPU_SIFT这两个版本用时,并与未优化的CPU_SIFT版本用时作比较分别计算两个版本的加速比。实验选取a,b两组图片。a组有a1~a5共5幅图片,b组有b1~b4 4对共8幅图片。为使实验结果更具有参考性,其中a1选取Rob Hess采用的behavior图,分辨率为320×300;a2选取国际通用的Lena图,分辨率为512×512;a3此处是否描述有误?即a2~a5,共4幅图像,而后面的描述中却有3幅,所以请作相应调整。~a5为利用CCD摄像头获取的3幅纹理从简单到复杂的测试图片,分辨率分别为960×720、1280×960、2560×1440。另外为了测试优化后的算法对不同图片的适应性,b组图片选取4对有角度、光照和尺度变化的图片,分辨率统一为1280×960。
5.3实验结果
在与原CPU_SIFT算法匹配效果一致的情况下,各图片的耗时如表2所示,利用OpenCL优化后的CPU版本和GPU版本的加速比最大分别为4倍和19倍左右,如图8所示。这表明OpenCL不仅具有优秀的并行计算能力,而且具有较好的跨平台特性,这也是OpenCL相对于CUDA的一大优势。
通过对比表1和表2可知,本文在PC平台实现的SIFT算法的加速比比文献[9]中实现的加速比更高,特别是当图像分辨率较大时,本文实现的加速比会进一步增大。这主要是因为两点:1)数据量越大,越能充分发挥GPU并行运算的能力,越能隐藏数据传输延时;2)由于移动处理器架构的限制,文献[9]只针对SIFT特征点检测部分进行了优化,而本文则是对整个SIFT算法流程进行统一优化,充分利用了GPU的全局内存,数据读取效率更高。另外,通过对比进一步证明了OpenCL对移动平台和PC平台都具有广泛的适用性,再次说明OpenCL具有较好的可移植性和跨平台性。
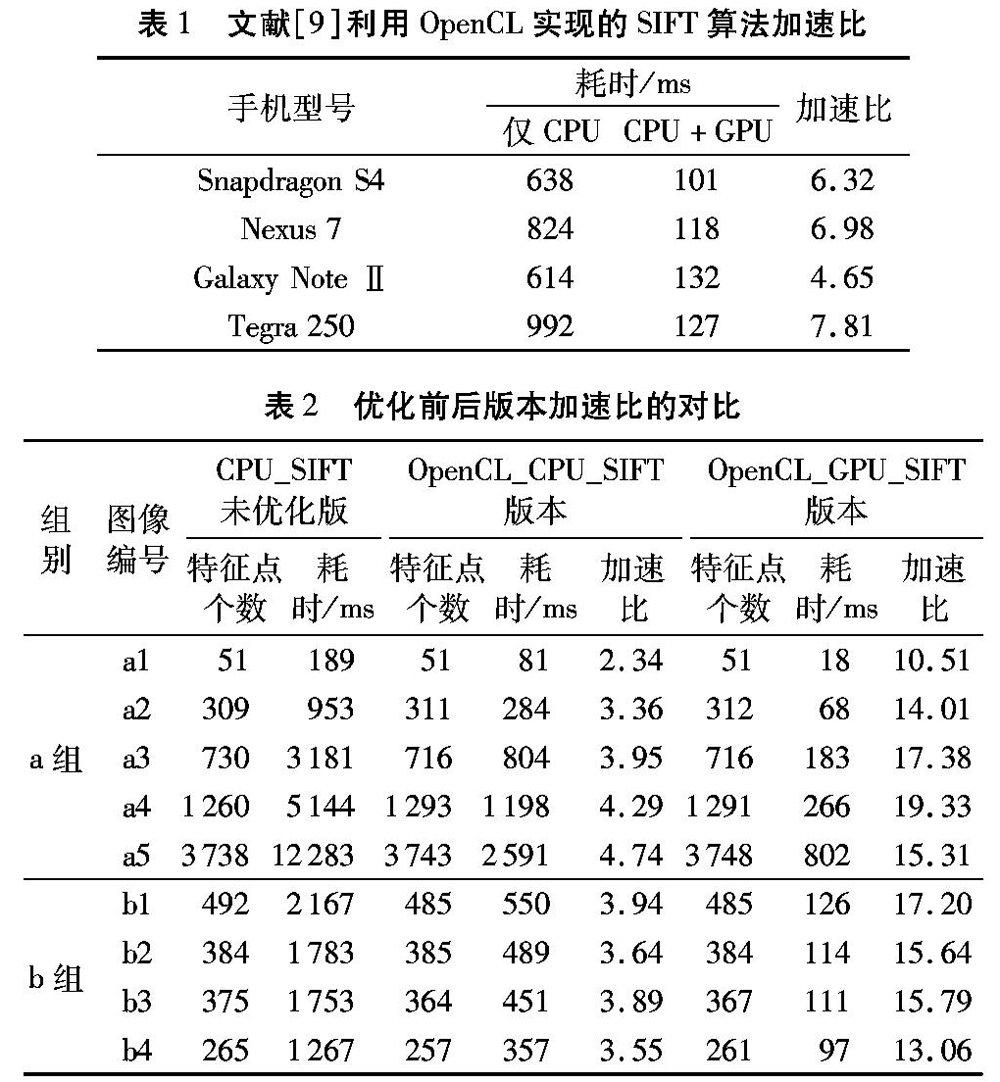
图9为本文算法对a组图像的特征提取结果。由图9可知,优化的算法对图像处理领域常用的Lena图和behavior图都能有效地提取特征点,a3~a5三张图片的纹理由简单到复杂,优化后的算法均能有效提取特征点。在b组图片中,b1的两幅图片有角度变化,b2有光照变化,b3既有角度又有光照变化,b4的角度、光照和尺度均有变化,匹配结果如图10所示。综合图9和图10的实验结果可知,优化后的算法对不同分辨率、不同纹理复杂度的图像都能提取稳定的特征点,对具有角度、光照和尺度变化的图像都能正确匹配,这表明并行化后的算法对各种图片都有较好的适应性。
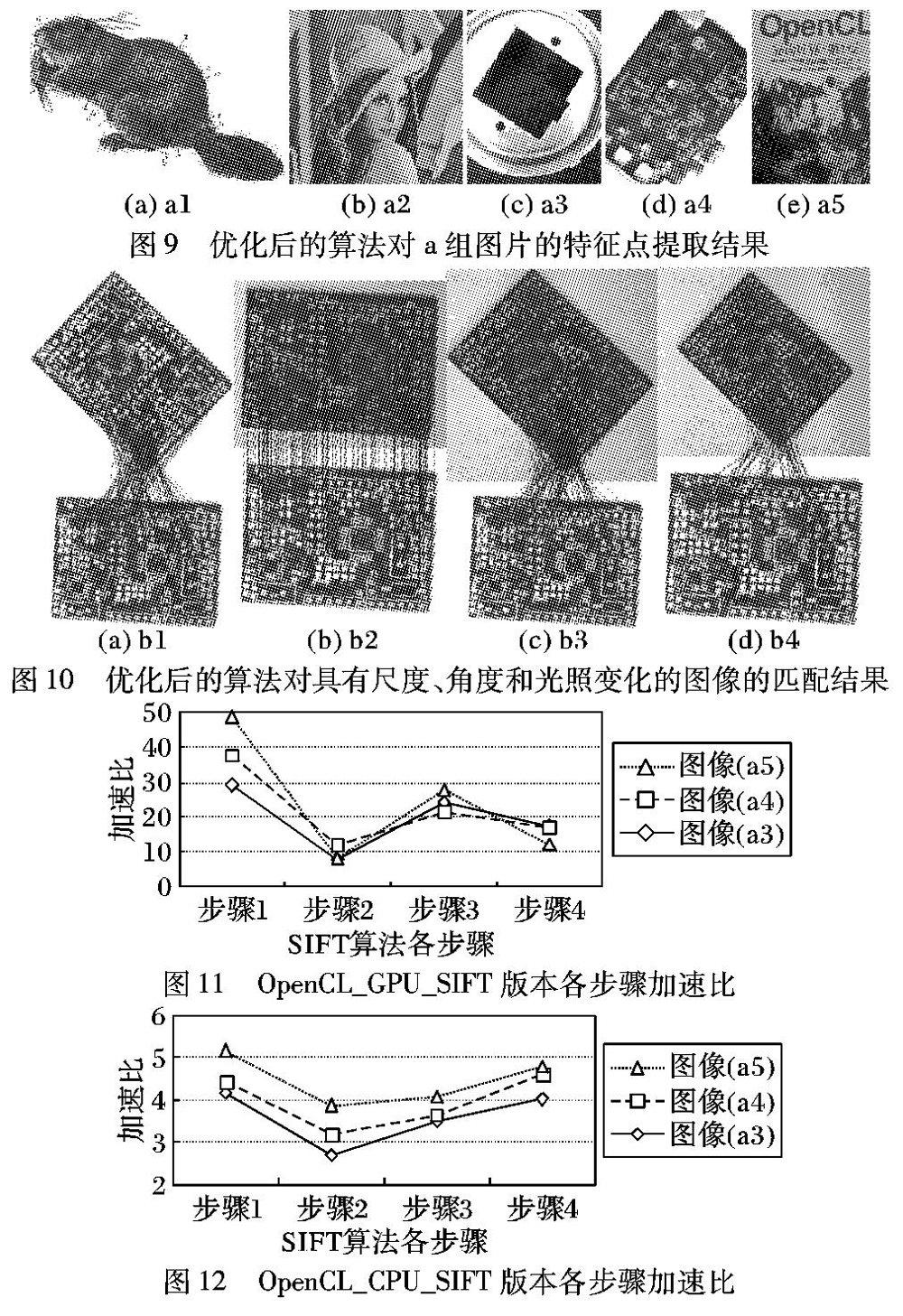
为进一步分析不同平台不同数据规模对OpenCL加速性能的影响,针对a3、a4和a5三幅不同分辨率的图像,本文分别统计了优化后的GPU和CPU版本各步骤的加速比,结果如图11和图12。图11和图12中步骤1为高斯模糊+高斯差分金字塔生成,步骤2为极值点定位,步骤3为计算方向直方图,步骤4为特征矢量生成。对比图11和图12可知,无论是GPU还是CPU平台,优化后,高斯模糊+高斯差分金字塔生成步骤加速比都最大,GPU版本甚至达到了50倍,这是因为该步骤中各工作项数据独立无分支,并行度高。而极值点定位步骤有大量的选择判断语句,并行度较差,闫钧华等[19]将此步骤放在CPU端执行,本文将此步骤一并优化,速度有一定提升但不够理想,这是因为在并行编程中无论CPU还是GPU都受分支语句的影响,GPU尤其如此。另外,与图11不同,图12中的三条曲线无交叉,随着图片分辨率的增大各步骤的加速比都逐步增大,说明数据规模越大越能发挥并行运算的优势。另外OpenCL_CPU_SIFT版本的特征向量生成步骤比计算方向直方图步骤的加速效果更好,这是因为前者通过工作组共享局部内存能充分利用CPU的L1 cache,从而提升运算性能。
6结语
本文对SIFT算法进行合并、拆分和数据重构等并行化设计,改善提高了算法的并行度,并通过合理设置工作组和工作项大小,充分利用内存层次等方法对算法进一步优化。利用OpenCL并行编程语言的跨平台特性,本文分别在NVIDIA GPU和Intel CPU平台上对该算法进行并行优化,分别取得了10.51~19.33和2.34~4.74倍的加速,并利用OpenCL的可移植性解决了CUDA对硬件平台的依赖问题。本文的研究内容及结果可应用于提升遥感图像拼接、医学影像配准和流水线工件定位等领域的图像匹配速度。
目前本文的优化方法在同一时刻只将OpenCL内核入列到CPU或者GPU中,即同一时刻只能充分利用CPU或GPU的计算能力,接下来本文将进一步研究异构系统中不同平台间的并行性,将可并行运行的内核同时入列到CPU和GPU中运行,进而扩展到多核多CPU和多GPU的复杂异构系统中,进一步提高算法的运行速度。
参考文献:
[1]
LOWE D G.Distinctive image features from scaleinvariant keypoints [J]. International Journal of Computer Vision, 2004, 60(2): 91-110.
[2]
KE Y, SUKTHANKAR R. PCASIFT: a more distinctive representation for local image descriptors [C]// CVPR 2004: Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2004: II506-II513.
[3]
BAY H, TUYTELAARS T, VAN GOOL L. SURF: speeded up robust features [C]// ECCV 2006: Proceedings of the 9th European Conference on Computer Vision, Part Ⅰ. Berlin: Springer, 2006: 404-417.
[4]
LUO J, GWUN O. A comparison of SIFT, PCASIFT and SURF [J]. Journal of Business Education, 2009, 3(4): 143-152.
[5]
张杰,柴志雷,喻津.基于GPU的图像特征并行计算方法[J].计算机科学,2015,42(10):297-324.(ZHANG J, CHAI Z L, YU J. Parallel computation method of image features based on GPU [J]. Computer Science, 2015, 42(10): 297-324.)
[6]
肖汉,郭运宏,周清雷.面向CPU+GPU异构计算的SIFT特征匹配并行算法[J].同济大学学报:自然科学版,2013,41(11):1732-1737.(XIAO H, GUO Y H, ZHOU Q L. Parallel algorithm of CPU and GPUoriented heterogeneous computation in SIFT feature matching [J]. Journal of Tongji University (Natural Science), 2013, 41(11): 1732-1737.)
[7]
LU M. Fast implementation of scale invariant feature transform based on CUDA [J]. Applied Mathematics & Information Sciences, 2013, 7(2): 717-722.
[8]
WANG G, RISTER B, CAVALLARO J R. Workload analysis and efficient OpenCLbased implementation of SIFT algorithm on a smartphone [C]// GlobalSIP 2013: Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing. Piscataway, NJ: IEEE, 2013: 759-762.
[9]
RISTER B, WANG G, WU M, et al. A fast and efficient SIFT detector using the mobile GPU [C]// ICASSP 2013: Proceedings of 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway, NJ: IEEE, 2013: 2674-2678.
[10]
董小社,刘超,王恩东,等.面向GPU异构并行系统的多任务流编程模型[J].计算机学报,2014,37(7):1638-1646.(DONG X S, LIU C, WANG E D, et al. A multi taskstream programing model for GPU based on heterogeneous parallel system [J]. Chinese Journal of Computers, 2014, 37(7): 1638-1646.)
[11]
PENNYCOOK S J, HAMMOND S D, WRIGHT S A, et al. An investigation of the performance portability of OpenCL [J]. Journal of Parallel & Distributed Computing, 2013, 73(11): 1439-1450.
[12]
TIAN L, MENG C, ZHOU F. A twolevel task scheduler on multiple DSP system for OpenCL [J]. Advances in Mechanical Engineering, 2014: Article ID 754835.
[13]
陈刚,吴百锋.面向OpenCL模型的GPU性能优化[J].计算机辅助设计与图形学学报,2011,23(4):571-581.(CHEN G, WU B F. GPU performance optimization targeting OpenCL model [J]. Journal of ComputerAided Design & Computer Graphics, 2011, 23(4): 571-581.)
[14]
YAN W, SHI X, YAN X, et al. Computing OpenSURF on OpenCL and general purpose GPU [J]. International Journal of Advanced Robotic Systems, 2013, 10(4): 301-319.
[15]
SANCHEZ L M, FERNANDEZ J, SOTOMAYOR R, et al. A comparative study and evaluation of parallel programming models for sharedmemory parallel architectures [J]. New Generation Computing, 2013, 31(3): 139-161.
[16]
JANG B, CHOI M, KIM K K. Algorithmic GPGPU memory optimization [C]// ISOCC 2013: Proceedings of the 2013 International SoC Design Conference. Piscataway, NJ: IEEE, 2013: 154-157.
[17]
肖汉,马歌,周清雷.面向OpenCL架构的Harris角点检测算法[J].计算机科学,2014,41(7):306-309.(XIAO H, MA G, ZHOU Q L. Harris corner detection algorithm on OpenCL architecture [J]. Computer Science, 2014, 41(7): 306-309.)
[18]
FANG J, SIPS H, VARBANESCU A L. Aristotle: a performance impact indicator for the OpenCL kernels using local memory [J]. Scientific Programming, 2014, 22(3): 239-257.
[19]
闫钧华,杭谊青,许俊峰,等.基于CUDA的高分辨率数字视频图像配准快速实现[J].仪器仪表学报,2014,35(2):380-386.(YAN J H, HANG Y Q, XU J F, et al. Quick realization of CUDAbased registration of highresolution digital video images [J]. Chinese Journal of Scientific Instrument, 2014, 35(2): 380-386.)
