基于Hadoop二阶段并行模糊c-Means聚类算法
2016-07-19胡吉朝黄红艳
胡吉朝 黄红艳
(石家庄经济学院信息工程学院 河北 石家庄 050031)
基于Hadoop二阶段并行模糊c-Means聚类算法
胡吉朝黄红艳
(石家庄经济学院信息工程学院河北 石家庄 050031)
摘要针对Mapreduce机制下算法通信时间占用比过高,实际应用价值受限的情况,提出基于Hadoop二阶段并行c-Means聚类算法用来解决超大数据的分类问题。首先,改进Mapreduce机制下的MPI通信管理方法,采用成员管理协议方式实现成员管理与Mapreduce降低操作的同步化;其次,实行典型个体组降低操作代替全局个体降低操作,并定义二阶段缓冲算法;最后,通过第一阶段的缓冲进一步降低第二阶段Mapreduce操作的数据量,尽可能降低大数据带来的对算法负面影响。在此基础上,利用人造大数据测试集和KDD CUP 99入侵测试集进行仿真,实验结果表明,该算法既能保证聚类精度要求又可有效加快算法运行效率。
关键词二阶段模糊c-Means大数据聚类并行入侵检测
0引言
如何从海量数据中排除干扰提取到有用数据,是一项有意义的工作[1],而算法的运行效率是影响算法实际应用效果的关键因素[2,3]。聚类算法作为一种典型的数据挖掘算法,对大数据并行聚类算法的研究较多。文献[4]设计并实现了Hadoop云计算平台下基于Mapreduce模型的并行K-Means聚类算法;文献[5]利用常值系数加权实现混合K-center和K-median加速并行聚类算法,并利用采样来简化样本,思路不错但单纯的随机样本无法确保选中的数据充分代表整体数据,精度不理想;文献[6]研究了协同聚类机制,并基于Hadoop平台实现了大型分布数据的协同聚类;文献[7]结合遗传算法固有的并行特点,基于Hadoop平台设计了并行遗传K-Means聚类算法;文献[8]的设计思想是以提高K-Means算法性能为目的,提高并行后K-Means算法聚类效果和性能。并行化K-Means算法已有诸多研究成果,相比而言c-Means算法并行化研究较少。
Hadoop平台下的Mapreduce模型并行化算法加快了运行效率,但数据量过大时,Mapreduce模型采用的MPI通信模型存在较高的通信消耗。某种程度上抵消了并行所带了的算法效率提升,对此提出一种成员管理协议来改进MPI通信模型,并利用个体贡献值确定进行reduce操作的典型个体,以此改善文献[5]随机采样的不具有代表性的弱点。本文的设计思想主要是通过上述方式并结合同步化管理协议实现c-Means算法的并行化设计,提出基于Hadoop二阶段并行模糊c-Means聚类算法PGR-PFCM(Protocolgroup-reduceparallelfuzzyc-Meansclustingalgorithm)。
1改进Mapreduce模型
1.1模型介绍
Mapreduce模型是目前比较成熟的大数据分布式计算模型,同时也是大数据并行聚类算法实现的主要执行框架。Mapreduce名称来源于该框架的两个主要操作:map和reduce操作。map操作类似一种映射操作,是针对数据集所有成员的一种操作,map操作后返回结果列表。reduce操作针对map操作反馈的结果执行并行化的算法。Mapreduce模型如图1所示。
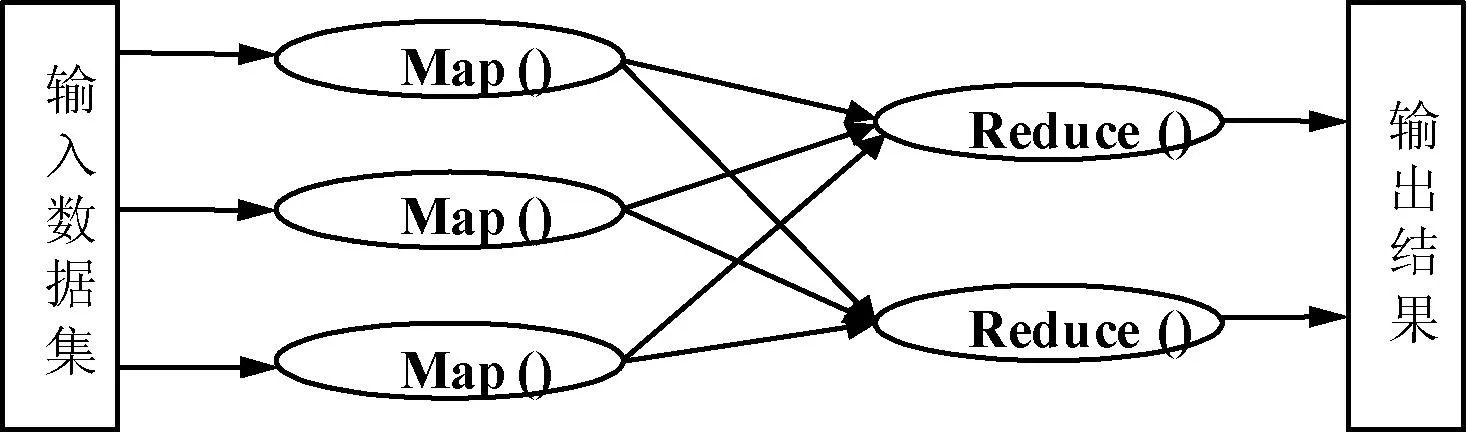
图1 Mapreduce模型
在Mapreduce模型中问题进程被分解为相互独立可以并列运行的子进程,便于充分发挥计算机集群的计算性能。map和reduce操作框架的构建主要是根据数据中的key-value进行设计和操作:
Map:(k1,v1)→[(k2,v2)]
(1)
Reduce:(k2,[v2])→[(k3,v3)]
(2)
系统运行时管理主机会根据输入数据断点情况实时调度参与并行计算的计算机数量,同时通过管理主机也可以实时处理计算机故障问题。因此允许程序员在没有操作经验和硬件操作经验的前提下较容易地使用大型分布式数据资源。
1.2典型个体操作方案


图2 数据降低策略
文献[10]提出这种基于组的典型个体降低策略可以通过定义在组上的MPI通信函数实现信息的交流。但是因为操作过程标识符列表会随着迭代的进行不断变化,即进行组降低的对象组合不断改变,每次迭代都需要更改过程标识符列表。这样通过MPI通信函数方式会增加过多的通信开销。因为随着迭代的增加重心能够更好地接近聚类的中心,所以首先考虑只有一个重心并且只有一个过程子集的聚类模式。同时为了解决MPI通信函数时间占用比过高的问题,对传统MPI通信模型设计了同步化的组成员管理协议来取代,并且这种基于组降低的操作可以并行相互独立的在过程子集中同步进行,适合于并行算法的嵌入。
1.3同步化管理协议
典型个体动态分组成员管理协议(protocolgroup-reduce)通过将动态组成员管理的控制信息封装在操作信息中。将pID列表进行广播,并且随着每个组降低操作进行同步修改,无需增加算法的额外通信开销。protocolgroup-reduce操作步骤如下:
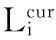
Step4步骤s时进程i,j进行信息交换,包含远程和本地pID列表的合并,合并公式为Li,s + 1=Li,s⊕Lj,s。
Step5若进程pi贡献值gi低于阈值Tmin则将该进程从pID列表中剔除。贡献值[10]:
(3)
其中,Li为进程pi到重心的欧氏距离。
Step6外部的进程pm可通过异步发送贡献值到本地组与组长接触,包括pm对下一降低操作的贡献度,以及添加该外部进程pm的ID到本地组mID中。如果组长接受进程pm则发送pID列表给进程pm。
Step7输出结果mID。
2PGR-PFCM聚类算法
2.1模糊c-Means算法
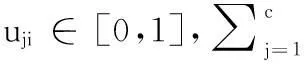

(4)
满足:
(5)
式(4)中‖·‖代表内积范数。模糊c-Means算法利用下面两式对vj及uji值进行迭代从而实现最小化目标函数J的目的:
(6)
(7)
程序1PFCM算法伪代码
1: %模糊c-Means算法(PFCM)伪代码
2:FunctionP=PFCM();
3:randomisemy_uOld[j][i]foreachx[i]
4:do{
5:maxErr=0;
6:forj=1toc
7:myUsum[j]=0;
8:resetvectorsmy_v[j]to0;
9:resetmy_u[j][i]to0;
10:endfor;
11:fori=myid*(n/P)+1to(myid+1)*(n/P)
12:forj=1toc
13:updatemyUsum[j];
14:updatevectorsmy_v[j];
15:endfor;
16:endfor;
17:forj=1toc
18:Allreduce(myUsum[j],Usum[j],SUM);
19:Allreduce(my_v[j],v[j],SUM);
20:v[j] =v[j]/Usum[j];
21:endfor;
22:fori=myid*(n/P)+1to(myid+1)*(n/P)
23:forj=1toc
24:updatemy_u[j][i];
25:maxErr=max{|my_u[j][i]-my_uOld[j][i]|};
26:my_uOld[j][i] =my_u[j][i];
27:endfor;
28:endfor;
29:Allreduce(maxErr,Err,MAX);
30:}while(Err>=epsilon)
2.2PGR-PFCM聚类算法描述
使用一种类似于组合器(Combiner)的节点类型,在算法迭代过程中Mapper操作和reduce操作串联执行,PGR-PFCM算法步骤如下:
Step1输入参数。中间缓冲聚类数量Kt,聚类数量K,数据段长度L。
Step2Mapper操作。执行map(inValue,inKey,outValue,outKey)操作:
(a) 在inValue中加载聚类数据,执行map操作。
(b) 在outValue数据中执行PFCM(Kt)映射聚类操作。
(c) 按照聚类结果重新格式化outValue值。
(d) 输出(outValue,outKey)。
Step3Reducer操作。执行同步化管理协议protocolgroup-reduce操作 (inValue,inKey,outValue,outKey)操作。
(a) 在inValue中加载Mapper操作的聚类中间结果,并执行protocolgroup-reduce操作。
(b) 在protocolgroup-reduce操作的聚类中间结果上执行PFCM(K)聚类操作。
(c) 输出最终的聚类结果。
上述步骤中,参数Kt的取值直接决定了PGR-PFCM算法的运行速度和聚类质量。PGR-PFCM算法的第一个阶段通过定义一个中间缓冲聚类数量Kt起到压缩数据数量的作用。参数Kt的大小决定了PGR-PFCM算法第二阶段输入数据的大小,进而影响算法的运行速度和精度,Kt越大速度越慢精度越高,Kt越小速度越快精度越高。
3仿真结果与分析
硬件条件:基于Hadoop框架对算法进行仿真实验,实验硬件条件:节点数:16(由16台计算机组成),每台计算机配置:Intel-Core2.0GHz,2GBRAM。
3.1算法加速度和运行时间
下面我们通过实验方法研究PGR-PFCM算法的并行特性。对于给定的数据尺寸m×n,采用IBM数据生成器生成7组合成数据集[9],表1给出了这些人造测试数据集的具体信息。

表1 数据集信息
首先对比不同数据集大小、不同尺寸、以及不同节点数的算法加速比及每次迭代所需时间。从表1可以看出测试数据集的大小从64MB至2048MB不等,小数据集形如d2其数据集大小为64MB。这样的数据集可以加载到单一机器中进行处理时间消耗并不是很大,但是超大数据集如d30和d31,采用一台机器进行数据处理则处理能力无法满足要求。实验采用算法加速度和每次迭代时间为主要指标,仿真结果如图3所示。


图3 实验结果对比
图3(a)反映的是算法每步迭代所需要的时间,显然该时间随着数据量及节点数的变化而变化,数据量越大处理速度越慢,节点数越多计算速度越快,但是并非呈线性关系,而是随着节点的增加速度提升的效果越来越差,最后趋于平衡。图3(b)反映的是加速度与节点数的关系,图中显示的是随着节点数的增加,加速度增大,算法的运行时间缩短。图3(c)反映的是加速度与数据集的关系,图中看出节点数较小时算法的加速度随数据维数的增加变化幅度不大,而节点数较多时,加速度随数据集大小的变化趋势逐渐明显,从侧面说明本文所提算法在多节点大数据集上运行的优势。
3.2KDD CUP 99应用测试
在对上述提出的并行聚类算法进行评价时,这里借用入侵检测的KDDCUP99数据库[11,12]作为仿真对象。通过对该数据库入侵数据的聚类检测结果,来对比算法性能。KDDCUP99数据库主要含有4种典型的网络入侵数据:DOS、Probe、U2R和U2L。上述四种类型网络入侵数据信息如表2所示。

表2 测试数据选取数量
常用到的入侵检测评价指标主要是检测率和错检率[13]。所谓检测率是指聚类算法在入侵数据库中正确归类识别的入侵数据个数与数据库中入侵数据总数的比值;错检率是指正常数据被错误归类的数量与正常数据总量的比值。检测率和错检率如下所示[14]:

(8)

(9)
对于表2选取的KDDCUP99测试集,选取K-meansⅡ、FPCM[15]及PGR-PFCM三种算法进行仿真对比,所有实验运行30次求平均值。仿真结果如表3所示。
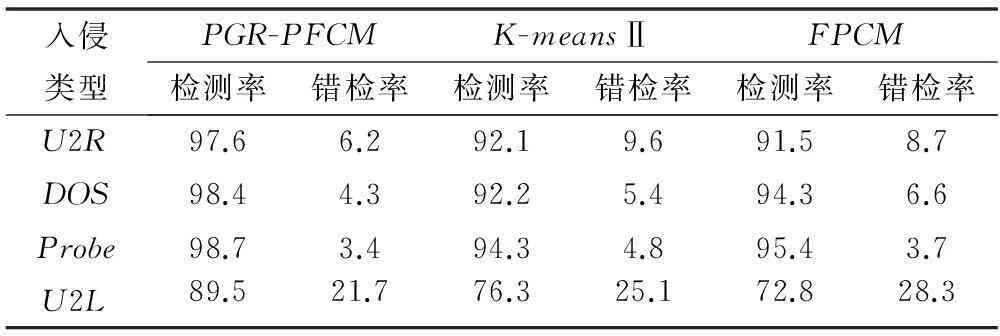
表3 分类结果对比(%)
表3分类结果对比分别给出K-meansⅡ、FPCM及PGR-PFCM三种算法,在KDDCUP99测试集上的聚类识别检测率和错检率对比结果。由此可看出,在该测试数据库的四种数据类别聚类识别中,PGR-PFCM算法在检测率和错检率两项评价指标上均要优于K-meansⅡ和FPCM算法。而K-meansⅡ和FPCM两种算法相比,K-meansⅡ算法在U2R和U2L两种数据上的聚类识别成功率要比FPCM算法高,而FPCM算法在U2L和DOS两种数据上的聚类识别成功率要比K-meansⅡ算法高。综合指标评价上,K-meansⅡ和FPCM两种算法性能近似。因此,单纯从聚类识别算法角度,PGR-PFCM算法是可行的,聚类性能要好于K-meansⅡ和FPCM算法。
为进一步验证PGR-PFCM算法在KDDCUP99测试集上的普适性,选取ISVMID[16]和GANNID[17]两种算法进行对比。实验对象仍然基于KDDCUP99标准测试数据库,相关参数如表2所示,仿真结果如图4、图5所示。

图4 三种算法的检测率对比
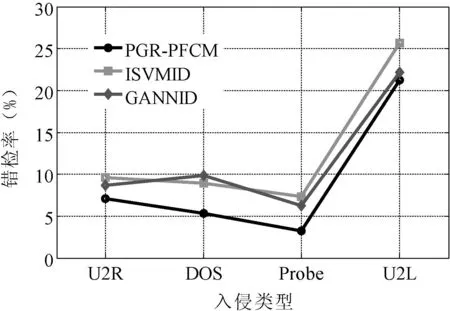
图5 三种算法的错测率对比
图4分别给出PGR-PFCM、ISVMID和GANNID三种算法在KDDCUP99测试集上的入侵数据检测率对比情况。可以看出,PGR-PFCM算法在KDDCUP99测试集四种类型数据上的检测准确率要比ISVMID和GANNID两种算法要高。而ISVMID和GANNID两种算法相比,在DOS和U2R两种入侵类型中,ISVMID要优于GANNID算法,而在U2L和Probe两种入侵类型中,GANNID要优于ISVMID算法。图5给出PGR-PFCM、ISVMID和GANNID三种算法错检率对比结果。可以看出,PGR-PFCM算法在DOS、Probe、U2R和U2L四种数据上的错检率要低于ISVMID和GANNID算法,其中在U2R、Probe和U2L三种入侵数据中,ISVMID算法错检率高于GANNID算法。通过对比分析可知,PGR-PFCM算法对入侵数据检测是高效的。
4结语
本文建立了基于Hadoop二阶段并行模糊c-Means聚类算法用来处理大数据聚类,并采用基于协议的组典型个体降低策略来改善Mapreduce的MPI通信模型的算法时间复杂度,以提高算法的整体运行效率。通过有选择的组降低算法能够有效排除不良数据项的干扰,因而PGR-PFCM算法具有更高的运行效率和聚类成功率。在并行率和加速比方面,PGR-PFCM算法在大规模数据集上的并行率和加速比都优于小型数据集上的表现,说明了PGR-PFCM算法能够实时根据数据量的大小对自身进行调整。最后通过在KDDCUP99入侵数据测试集上的对比仿真结果,表明PGR-PFCM算法同样适用处理实际环境下的大数据聚类问题。
参考文献
[1]DaiL,ChenT,XuHK.ResearchontestingTechniqueofbigdata[J].ApplicationResearchofComputers,2014,31(6):1606-1611.
[2] 王珊,王会举,覃雄派.架构大数据:挑战、现状与展望[J].计算机学报,2011,34(10):1741-1752.
[3]MeglerVM,MaierD.Whenbigdataleadstolostdata[C]//Procofthe5thInternationalConferenceonInformationandKnowledgeManagement.NewYork:ACMPress,2012:1-8.
[4] 赵卫中,马慧芳,傅燕翔.基于云计算平台Hadoop的并行K-means聚类算法设计研究[J].计算机科学,2011,38(10):166-169.
[5]EneA,ImS,MoseleyB.FastclusteringusingMapRe-duce[C]//Procofthe17thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining,California,USA:ACMPress,2011:681-689.
[6]PapadimitriouS,SunJ.DisCo:DistributedCo-clusteringwithMap-Reduce:ACaseStudyTowardsPetabyte-ScaleEnd-to-EndMining[C]//Procofthe8thIEEEInterna-tionalConferenceonDataMining.Pisa,Italy:IEEEPress,2008:512-521.
[7] 陆秋,程小辉.基于Mapreduce的决策树算法并行化[J].计算机应用,2012,32(9):2463-2465.
[8]BahmaniB,MoseleyB,VattaniA.Scalablek-means++[J].ProceedingsoftheVLDBEndowment,2012,5(7):622-633.
[9]MiaoYQ,ZhangJX,FengH.AFastAlgorithmforClusteringwithMapreduce[J].AdvancesinNeuralNet-works,2013,17(11):532-538.
[10]DavidP,GiuseppeDF.EfficientGroupCommunicationforLarge-ScaleParallelClustering[J].IntelligentDistributedComputing,2013,446:155-164.
[11]MengYX,LiWJ.Towardsadaptivecharacterfrequency-basedexclusivesignaturematchingschemeanditsapplicationsindistributedintrusiondetection[J].ComputerNetworks,2013,57(17):3630-3640.
[12]HassanzadehA,XuZY,RaduS.PRIDE:PracticalIntrusionDetectioninResourceConstrainedWirelessMeshNetworks[J].InformationandCommunicationsSecurity,2013,23(3):213-228.
[13]ShakshukiEM,SheltamiTR.EAACK—ASecureIntrusion-DetectionSystemforMANETs[J].IEEETransactionsonIndustrialElectronics,2013,60(3):1089-1098.
[14]ChiragM,DhirenP,BhaveshB.Asurveyofintrusiondetectiontechniquesincloud[J].JournalofNetworkandComputerApplications,2013,36(1):42-57.
[15]TerenceK,KateS,SebastianL.ParallelFuzzyc-MeansClusteringforLargeDataSets[C]//8thInternationalEuro-ParConferencePaderborn,Germany:Springer,2002:27-30.
[16] 谭爱平,陈浩,吴伯桥.基于SVM的网络入侵检测集成学习算法[J].计算机科学,2014,41(2):196-200.
[17] 陈鸿星.基于遗传优化神经网络的网络入侵特征检测[J].计算机工程与应用,2014,50(14):78-81.
HADOOP-BASED TWO-STAGE PARALLEL FUZZY C-MEANS CLUSTERING ALGORITHM
Hu JichaoHuang Hongyan
(School of Information Engineering,Shijiazhuang University of Economics,Shijiazhuang 050031,Hebei,China)
AbstractAiming at the problem of too high occupancy of communication time and limited applying value of the algorithm under the mechanism of Mapreduce, we put forward a Hadoop-based two-stage parallel c-Means clustering algorithm to deal with the problem of extra-large data classification. First, we improved the MPI communication management method in Mapreduce mechanism, and used membership management protocol mode to realise the synchronisation of members management and Mapreduce reducing operation. Secondly, we implemented typical individuals group reducing operation instead of global individual reducing operation, and defined the two-stage buffer algorithm. Finally, through the buffer in first stage we further reduced the data amount of Mapreduce operation in second stage, and reduced the negative impact brought about by big data on the algorithm as much as possible. Based on this, we carried out the simulation by using artificial big data test set and KDD CUP 99 invasion test data.Experimental result showed that the algorithm could both guarantee the clustering precision requirement and speed up effectively the operation efficiency of algorithm.
KeywordsTwo-stageFuzzy c-MeansBig dataClusteringParallelIntrusion detection
收稿日期:2014-11-10。河北省科技厅科技攻关项目(132101 30)。胡吉朝,讲师,主研领域:数据挖掘,智能计算。黄红艳,讲师。
中图分类号TP312
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.067
