基于Pairwise排序学习的因子分解推荐算法
2016-07-19周俊宇戴月明吴定会
周俊宇 戴月明 吴定会
(江南大学物联网工程学院 江苏 无锡 214122)
基于Pairwise排序学习的因子分解推荐算法
周俊宇戴月明吴定会
(江南大学物联网工程学院江苏 无锡 214122)
摘要针对基于内存的协同过滤推荐算法存在推荐列表排序效果不佳的问题,提出基于Pairwise排序学习的因子分解推荐算法(简称Pairwise-SVD推荐算法)。新算法将因子分解的预测结果作为排序学习算法的输入,把排序问题转化成分类问题使用排序学习理论进行排序产生推荐列表。实验结果表明相比基于内存的协同过滤推荐算法,Pairwise-SVD推荐算法的排序效果更佳。其在指标Kendall-tau上提高了近一倍,在指标MRR上提高了近30%,且在指标MAP上也有小幅提高。
关键词Pairwise因子分解协同过滤分类排序学习
0引言
随着大数据时代的到来,信息过载问题成为人们日益关注解决的难题。用户迫切希望可以从海量数据当中发现对于自己有用的信息,针对这一需求研究人员提出了推荐系统这一研究课题。
推荐系统主要以推荐列表的形式给用户推送信息也称为Top-N推荐。基于内存的协同过滤推荐算法主要有基于用户的协同过滤推荐算法和基于物品的协同过滤推荐算法。这类算法的特点是通过相似度计算来给用户推送其可能感兴趣的物品信息。不过这类算法也有排序效果不佳的不足,主要是其没有考虑推荐物品与用户的相关度。为提高推荐算法的预测精度,学术界对评分预测问题展开了大量的研究。其中典型的算法是以因子分解算法为代表的一系列改进算法。下面将介绍推荐系统领域的一些研究情况。
YueShi等[1]人提出了一种将排序学习融入矩阵分解的协同过滤推荐算法。其排序学习算法的类型是列表级排序,通过优化列表级排序的损失函数来进行算法的性能优化。不过这种算法虽然效果很好,但是它只从损失函数的角度进行优化所以这种算法的实用性不是很强。
SeanM.McNee等[2]人提出了新的观点,即仅仅通过改良预测精度是不足以说明推荐效果的好坏。虽然基于评分预测的改进大大提高了评价指标的结果。但在实际的推荐系统中效果却不明显,因为用户在实际情况下并不会真的喜欢预测精度高的物品。
YueShi等[3]人提出了CLiMF协同过滤推荐算法,该算法优化的主要目标是MRR。该指标反映了用户最关心的物品在推荐列表中的排序位置,它是信息检索领域中的重要指标。CLiMF算法在原来的协同推荐算法的基础之上考虑了排序性能的优化问题,其在MRR指标上的表现较好。
ShuziNiu等[4]人提出了一种新的Top-N推荐算法,并将其命名为FocusedRank算法。该算法有效地降低了原有Top-N算法的时间复杂度,从O(n)降低为O(nlogn)。并且针对新的算法提出了新的评价准则k-NDCG和k-ERR。
虽然排序学习理论在信息检索领域已经有了大量的研究成果,但是将排序学习理论用于推荐系统的研究却少之又少。本文在前人工作的基础之上展开,提出将Pairwise排序学习理论加入到因子分解推荐算法当中,并采用Rank-SVM方法具体实现Pairwise排序。最后通过在三种不同类型的排序指标上进行对比实验来验证本文提出的算法的性能优势。
1理论基础
这节主要阐述构成本文算法的理论基础。主要从两个方面进行介绍,分别是Bias-SVD算法、排序学习理论等内容。
1.1Bias-SVD算法
本文提出的Pairwise-SVD推荐算法借鉴了Bias-SVD推荐算法的思想。所以先简要地阐述一下Bias-SVD算法的思想。
为了预测用户物品评分矩阵当中的空缺项需要把评分矩阵进行分解,分解后的矩阵表示成如下的形式:
(1)
这里矩阵R代表的是用户物品评分矩阵,P和Q是分解后的两个降维矩阵,P矩阵代表的是用户的特征,Q矩阵代表的是物品的特征。这里可以通过在训练集的观察值上利用最小化均方根误差来学习P矩阵和Q矩阵[5]。通过这种方法可以把上述矩阵表示成如下的形式:
(2)
为了进一步提高预测精度,Bias-SVD算法在上面的矩阵分解的基础之上加入了三个偏置项,把上面的公式改变成了如下的形式:
(3)
其中,μ表示训练数据集当中评分的平均情况。因为不同的数据集评分分布情况有很大的不同。比如说有的数据集评分普遍偏高,而有的数据集评分普遍偏低。所以数据集的评分均值对预测有很大的干扰影响,这里为平衡该影响而引入评分均值这一项。
bu表示用户的评分偏置项。由于不同用户打分的尺度不相同,会造成对于同一物品相似用户的打分产生巨大的偏差。例如有的用户比较苛刻打分普遍偏低,而有的用户尺度宽松打分普遍较高。通过加入这一偏置项就可均衡这种情况提高预测精度。
bi表示物品偏置项。该项表示物品的受欢迎程度,因为有的物品比较热门所以评分一般都很高,而有的物品比较冷门打分普遍偏低。通过引入这一项可以惩罚热门物品,并平衡冷门物品。
为了学习公式中的各个参数,使用最小二乘法来定义损失函数。得出Bias-SVD算法的损失函数如下所示:

(4)
在确定了损失函数之后可以通过随机梯度下降法学习损失函数中的各参数。下面列出随机梯度下降学习的策略:
bu←bu+γ·(eui-λ·bu)bi←bi+γ·(eui-λ·bi)pu←pu+γ·(eui·qi-λ·pu)qi←qi+γ·(eui·pu-λ·qi)
(5)
通过上面的学习策略就可以求得各个参数的结果。
1.2排序学习理论
所谓排序学习理论即将信息检索领域中的排序问题转化成机器学习问题,以此期望获得更好的排序结果。一般的排序学习问题可用如图1的流程来进行说明。
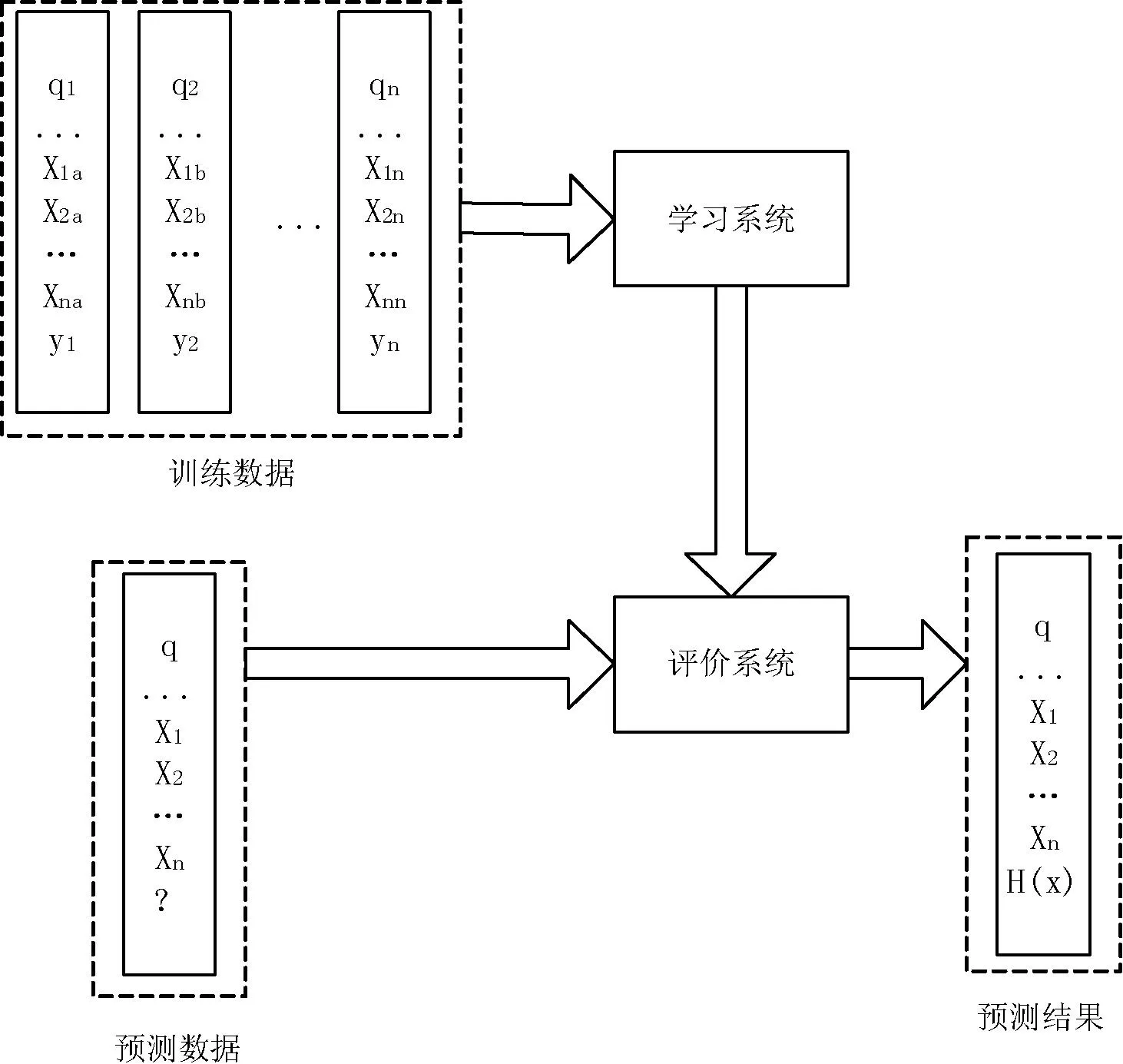
图1 排序学习算法流程图
从图1可以看出排序学习是一种有监督学习,所以它需要训练集来构造模型。举例来说,在信息检索的过程当中一个训练集包含有n个查询(在图中用q1到qn表示)。相应的与查询相关的文档可以用x1到xm来表示。这里的m表示对于某一个查询返回的文档个数。图中的模型的获得可以通过一个具体的学习算法取得(比如组合特征方法)。通过这一学习算法可以使模型尽可能准确地预测出训练集的标签。在进行测试的时候只需要运用训练好的模型就可以产生推荐列表。
根据输入数据的格式不同,通常情况下排序学习算法主要分为三大类。有基于点的排序算法(Pointwise),基于对的排序算法(Pairwise),基于列表的排序算法(Listwise)[6]。
本文所采用的排序方法属于基于对的排序方法,故下面将主要阐述基于对的排序方法的主要思想和实现手段。
基于对的排序方法不关心单个文档的顺序,其主要关注的是文档对的分类问题。也就是说基于对的排序方法把排序问题转化为二元分类问题。如果每一个文档对都能正确的分类那么也就可以得出正确的排列顺序。所以基于对的排序方法的主要目标是尽可能快地缩小分类的误差。
基于对的排序方法实现有很多的方法,比如神经网络、感知器、boosting、Rank-SVM方法等。由于本文的排序学习方法通过Rank-SVM实现所以下面主要讲解Rank-SVM方法的主要思路。
1.3Rank-SVM方法
Rank-SVM方法采用支持向量机模型解决分类问题。Rank-SVM方法在训练数据集上构造数据样本对S={(xi,xj),zi},其中xi与xj表示针对某一个查询返回的文档。如果(xi,xj)是正样本对则zi的值表示为+1,如果(xi,xj)是负样本对则zi的值表示为-1。Rank-SVM方法的数学表达如下所示[7]:

(6)
从上面的数学公式可以看出Rank-SVM方法与一般的SVM方法非常接近。但所不同的是两种方法的约束条件有一定的差别。SVM方法的约束条件是基于单个的样本点构造的,而Rank-SVM方法的约束条件基于样本对构造。并且Rank-SVM方法的损失函数定义为样本对上的Hinge损失。举例来说,有一个查询q,如果其标签当中的文档xu比xv相关。并且如果两条支持向量的最大间隔大于1,还满足条件wTxu>wTxv的条件,则其损失函数为0,否则为Hinge损失的0到1的上界。
图2、图3用通俗的方法说明Rank-SVM方法的基本思想。

图2 针对某一个用户的查询 图3 基于成对排序的Rank-SVM分类
图2中的椭圆形表示一个用户的查询,这里我们选取一个用户的查询做成对排序(在推荐系统里这可以看作是针对一个用户的推荐列表)。
图3表示将一个用户的查询信息转化成成对信息后用Rank-SVM分类的结果。这里有两个类别+1和-1。其中+1代表正相关,-1代表负相关。举例来说(X3-X1)表示这个数据分类为-1也就是负相关,也就是说用户不希望X3文档排列在X1文档的前面。所以文档对(X1-X3)分类为+1就是正相关。
2Pairwise-SVD算法
2.1算法描述
本文提出的算法在Bias-SVD算法的基础之上进行改进,把只能处理单个数据的Bias-SVD算法改造成可以处理成对数据的Pairwise-SVD算法。

这样接下来就可以把Bias-SVD算法的评分预测公式进行如下的改造:
(7)
这里简要解释一下上面的数学公式的含义。公式的左半部分表示的是一个偏序关系,即对于用户u我们把物品i排列在物品j的前面这样的一个偏序关系[8]。等式的右边是改造的打分函数,即针对这样的偏序关系依照等式右边的方法进行打分。在等式的右边添加sigmoid函数是为了做归一化处理,使最终的打分函数的取值落在-1到1之间。
下面阐述一下Pairwise-SVD算法的具体执行步骤:
(1) 我们要把数据集中的数据进行Pairwise化处理,因为只有这样才能进行后续的工作。
(2) 将Pairwise化后的数据集进行分割,分割为训练集合测试集。
(3) 在训练集上利用随机梯度下降算法训练Pairwise-SVD算法的模型。
(4) 判断模型训练是否终止不终止则返回步骤(3)。
(5) 如果训练终止,在测试集上面测试训练好的模型的效果。
(6) 如果训练好的模型的效果达标,用该模型产生的信息作为Rank-SVM方法的输入。
(7) 训练Rank-SVM模型。
(8) 判断Rank-SVM模型训练是否终止如不终止返回步骤(7)。
(9) 利用Rank-SVM方法进行排序产生推荐列表。
(10) 评估推荐效果的好坏情况。
2.2Pairwise-SVD算法程序流程图
下面我们通过一个流程图详细讲述Pairwise-SVD算法在计算机当中执行的每一个步骤。如图4所示。

图4 算法程序流程图
3实验验证
3.1实验用数据集
本文实验所采用的数据集是GroupLens研究小组的MovieLens100KB数据集。该数据集包含943个用户对于1682部电影的评分数据。并且每名用户至少评价20部以上的电影。
3.2评价指标
本文主要采用三种基于排序的评价指标评价推荐效果的好坏。它们分别是Kendall-tau,MRR和MAP。
其中Kendall-tau评价指标用于比较用户喜欢的物品列表与推荐给用户的物品列表的关系。Kendall-tau指标越高说明推荐的物品与用户喜欢的物品越相关。
(8)
指标MRR表示在列表中越早出现的物品其权重越高。指标MRR的高低说明了越早出现用户喜欢的物品的概率大小。MRR越高说明推荐列表的前几项就是用户感兴趣的物品(因为习惯上用户只关注列表的前几项内容)。
(9)
指标MAP称为平均准确度,衡量用户喜欢的物品在列表中出现的频度。同样的越早出现在列表中的物品其权重越高。
(10)
3.3对比实验
在这里设计三组对比实验分别展示三种算法在这三个评价指标上的优劣程度。
需要说明的是与本文算法进行对比的算法是基于用户的协同过滤推荐算法(UserCF)和基于物品的协同过滤推荐算法(ItemCF)。
3.3.1第一组对比实验
在第一组对比实验中我们比较三种算法在指标MRR上的优劣程度。这里我们随机给不同的用户推荐不同数量的物品以此来比较三种算法的情况(用5作为物品列表增加的迭代步长)。
实验的结果通过图5的柱状分析统计图来进行展示。
通过上面的柱状分析图可以得出这样的结论。Pairwise-SVD算法在指标MRR上其效果要好于基于物品的协同过滤算法和基于用户的协同过滤算法。其中在推荐列表长度为10的时候效果最明显(性能提高约30%左右),而这个长度往往是一般推荐系统所选取的给用户推荐的物品数量。
3.3.2第二组对比实验
在这组实验中我们关注三种算法在指标Kendall-tau上的性能情况。同上一组实验一样我们随机选取几个用户进行推荐,设定不同长度的推荐列表(长度从5到12)。比较在不同长度的列表下Kendall-tau值的大小。实验的结果如图6的折线统计图所示。
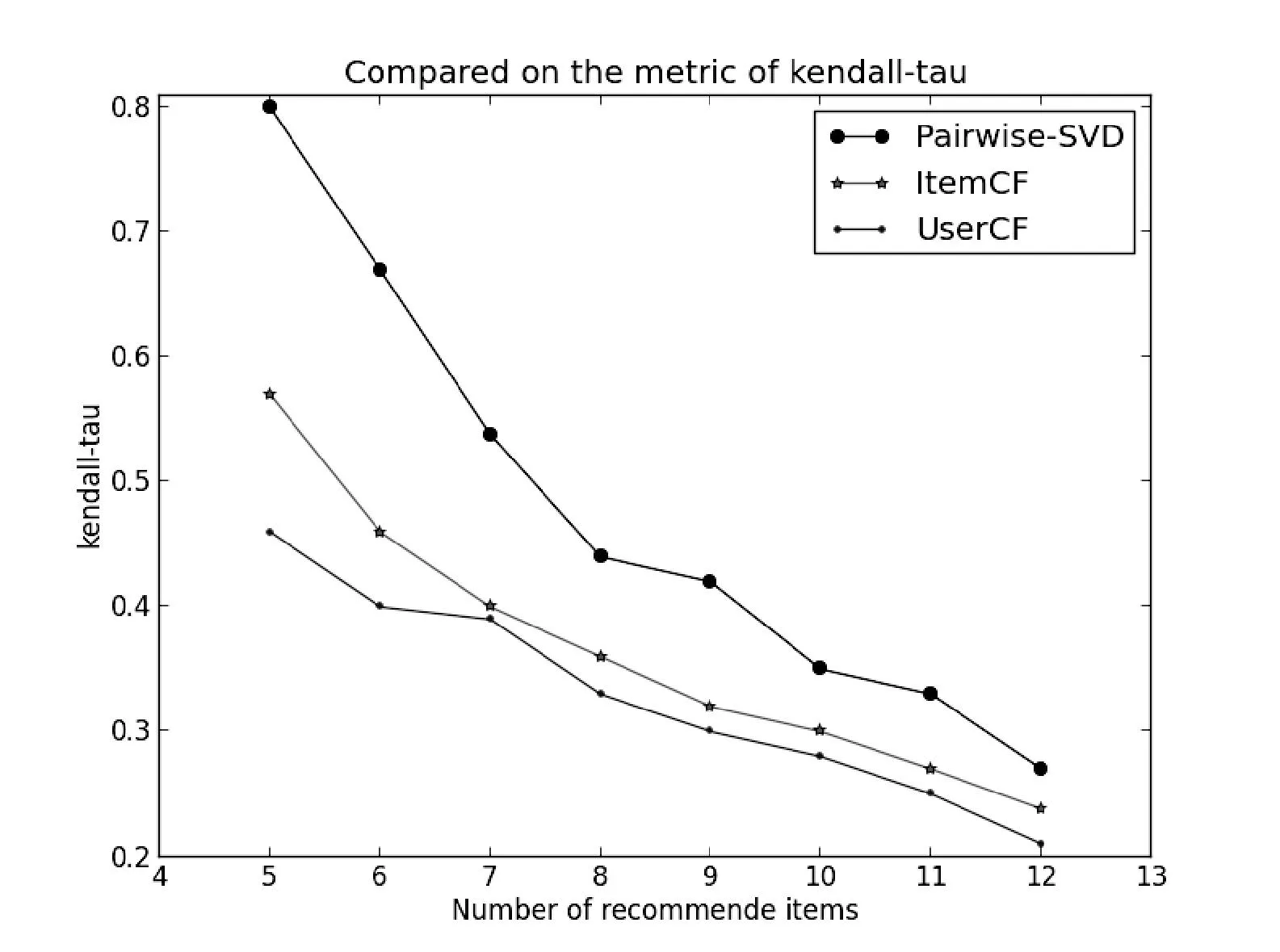
图6 三种算法在Kendall-tau上的比较
通过上面的折线图可以看出Pairwise-SVD算法在指标Kendall-tau上要明显好于另外的两种算法。这说明由Pairwise-SVD算法产生的推荐列表其用户的兴趣与物品之间的相关度更高。
3.3.3第三组对比实验
在这一组实验当中比较三种算法在指标MAP上的结果。并通过表1来展示,其中N代表推荐给用户的物品数量。
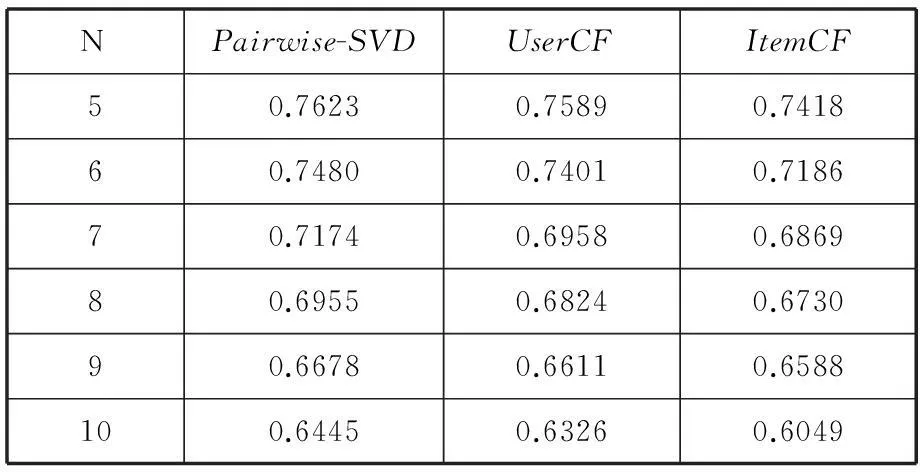
表1 三种算法在MAP上的比较
通过上面表格中的数据,可以得出这样的结论。即Pairwise-SVD算法在MAP指标上相比另外的两种算法也有一定的优势。说明Pairwise-SVD算法所推荐的物品准确度与覆盖效果更好。
4结语
本文在前人工作的基础之上提出了基于Pairwise排序学习的因子分解推荐算法。把原本只适用于预测精度的因子分解推荐算法改造成为适合产生推荐列表的推荐算法。并通过实验将该算法与基于内存的协同过滤推荐推荐算法进行对比。在三个评价指标上都取得了比较好的效果。此外加入了Rank-SVM方法把排序问题转化为机器学习问题使得列表排序更加智能化。本文的工作也为其他的机器学习算法融入推荐算法当中做了很好的铺垫。
在未来的工作中我们将把其他的分类算法比如神经网络算法等内容用于进行排序学习,并在多维特征的情况下进行测试来验证其效果。未来将进一步深化排序学习与推荐系统领域的交叉研究。
参考文献
[1]YueShi,MarthaLarson,AlanHanjalic.List-wiseLearningtoRankwithMatrixFactorizationforCollaborativeFiltering[C]//Recys’10.Barcelona,Spain:ACM,2010.
[2]SeanMMcNee,JohnRiedl,JosephAKonstan.BeingAccurateisNotEnough:HowAccuracyMetricshavehurtRecommendersystem[C]//Montreal.Quebec,Canada:ACM,2006.
[3]YueShi,AlexandrosKaratzoglou,LinasBaltrunas.CLiMF:LearningtoMaximizeReciprocalRankwithCollaborativeLess-is-MoreFiltering[C]//Dublin,Ireland:Recsys’12,2012.
[4]ShuziNiu,JiafengGuo,YanyanLan,etal.Top-kLearningtoRank:Labeling,RankingandEvaluation[C]//Portland,Oregon,USA:SIGIR’12,2012.
[5] 项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[6] 林原,林鸿飞,苏绥.一种应用奇异值分解的Rankboost排序学习方法[C]//中国山东烟台,第十届全国计算语言学学术会议,2009.
[7] 丁伟民.排序学习中的RankingSVM算法研究 [J].科技视界,2013(30):84-138.
[8]ChenT,ZhangW,LuQ.SVDFeature:AToolkitforFeature-basedCollabrativeFiltering[C]//Toappearinthe30thInternationalConferenceonMachineLearningResearch,2012:3585-3588.
FACTORISATION RECOMMENDATION ALGORITHM BASED ONPAIRWISERANKINGLEARNING
Zhou JunyuDai YuemingWu Dinghui
(School of Internet of Things,Jiangnan University,Wuxi 214122,Jiangsu,China)
AbstractMemory-based collaborative filtering recommendation algorithm has the problem of poor recommendation list ranking effect, in light of this, we presented a new kind of factorisation recommendation algorithm which is based on Pairwise ranking learning, namely the Pairwise-SVD recommendation algorithm. The new algorithm uses the predictive result of factorisation as the input of ranking learning algorithm, in this way, it converts the ranking problem into a classification problem and then uses the ranking learning theory to rank and generates a recommendation list. Experimental results showed that, compared with the memory-based collaborative filtering recommendation algorithm, the Pairwise-SVD recommendation algorithm had better ranking effect. What’s more, it almost doubled the index of Kendall-tau, and improved about 30% in index of MRR, and reached a small improvement in the index of MAP as well.
KeywordsPairwiseFactorisationCollaborative filteringClassificationRanking learning
收稿日期:2015-01-18。国家高技术研究发展计划项目(2013AA 040405)。周俊宇,硕士生,主研领域:数据挖掘与推荐系统。戴月明,副教授。吴定会,副教授。
中图分类号TP3
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.061
