基于改进的分布式K-Means特征聚类的海量场景图像检索
2016-07-19崔红艳曹建芳
崔红艳 曹建芳
(忻州师范学院计算机科学与技术系 山西 忻州 034000)
基于改进的分布式K-Means特征聚类的海量场景图像检索
崔红艳曹建芳*
(忻州师范学院计算机科学与技术系山西 忻州 034000)
摘要针对传统的图像检索方法在处理海量数据时面临的问题,提出一种基于改进的分布式K-Means特征聚类的海量场景图像检索方法。对分布式K-Means算法进行改进,优化了初始聚类中心的选择和迭代过程,并将其应用与场景图像的特征聚类中;充分利用Hadoop分布式平台的海量存储能力和强大并行计算能力, 提出了海量场景图像的存储和检索方案,设计了场景图像特征提取、特征聚类以及图像检索三个阶段分布式并行处理的Map和Reduce任务。多组实验表明,提出的方法数据伸缩率曲线平缓,取得了优良的加速比,效率大于0.6,检索的平均准确率达到了88%左右,适合海量场景图像数据的检索。
关键词Hadoop分布式平台MapReduce分布式K-Means算法特征聚类场景图像检索
0引言
多媒体技术及网络技术的快速发展,已导致图像数据的迅速增长,面对海量的图像数据,如何快速、准确地检索到用户需要的图像,已成为人们关注的热点问题。传统的基于单节点架构的图像检索方法,在同时访问用户数量较少时,基本可以满足用户对访问时间的要求,但随着图像数量的迅速增长,图像特征库会变得很大,在线同时访问用户数量也会随之增多,导致图像的检索速度会因此而急速下降;另外,图像的特征相似度计算属于复杂运算,使用传统的检索方法会耗费大量的计算资源,运算速度也很慢。这些都会导致大量用户同时检索时,系统运行效率迅速下降,甚至无法承受,难以及时对用户作出响应[1]。因此,传统的图像检索方法已无法完成对海量图像数据的处理,难以满足人们对图像检索性能的要求。对海量图像的检索面临巨大的挑战,探索新的图像检索方法已成为数字图像理解领域的研究热点。
云计算技术的发展为海量图像数据的处理提供了新的思路,云计算技术的发展过程一直与大规模数据的处理关系密切,因此利用云计算平台进行分布式并行处理是实现海量图像高效检索的一种有效解决方案。Hadoop是一个能够对大规模数据进行分布式并行处理的软件框架,自问世以来因其优秀的大规模数据处理能力、良好的可扩展性、高可靠性以及低成本等优点得到了广泛的应用[2]。本文以最常见的场景图像为例,在分析传统的图像检索方法的基础上,研究了Hadoop平台中的MapReduce并行编程框架,提出了基于MapReduce的海量场景图像检索方案和改进的分布式K-Means特征聚类算法,设计了场景图像并行特征聚类的Map任务和Reduce任务,实现了海量场景图像的高效检索。为验证本文提出的检索方法的性能,实验从检索准确率、数据伸缩率、加速比与效率等多个方面验证了检索方案的强大并行计算能力。
1相关工作
近年来,研究者们对分布式K-Means聚类算法进行了一些研究,目前研究应用较多的平台是Hadoop分布式平台,它利用MapReduce并行编程计算模型实现大规模数据的存储和计算。对分布式K-Means聚类算法的改进大多是借鉴于传统的非分布式K-Means算法,而对于传统的K-Means算法的改进主要集中在初始聚类中心的确定和距离函数的确定两个方面。NehaA等人[3]利用所有的数据对象到特定中心的计算,选取中间的数据对象作为数据中心,避免了随机选取初始聚类中心的不确定性,减少了循环迭代的次数。张军伟等人[4]和韩最蛟[5]根据聚类数据间的距离和密度,选择距离较大或密度较小的数据作为聚类中心。出了对K-Means算法的聚类过程做一些改进之外,针对Hadoop分布式平台,赵卫中[6]等人提出了一种基于云平台的并行K-Means聚类算法,利用MapReduce并行编程模型的Combine函数进行本地的合并,加快了算法的迭代速度。金伟健[7]等人通过在计算模型中增加通信模块,减少重复的通信流量,从而提高了数据的传输速率。尽管这些算法都可以对大规模数据进行处理,但其聚类的质量并不是很高,也没有很好地考虑算法执行过程中的计算量的问题。
在海量图像处理方面,WileyK[8]等人通过将图像转换成序列化的二进制文件,利用Hadoop实现了对天文图像的分析处理,但因其无法对图像进行随机读写,所以应用受到了一定的限制。AlmeerMH[1]等人利用Hadoop的HDFS实现了对大规模遥感图像的分析和存储。朱义明[9]通过自定义图像接口读写整张图像,提出了基于Hadoop平台的图像分类方法, 但该方法未考虑小文件低效率的问题,从而导致一定的资源浪费,因此仅适合对遥感图像的处理。SweeneyC[10]提出了一种新的方法,通过将图像数据信息转化为Float数组的方式将其存储在一个文件中,并附有索引文件,从而有效解决了小文件低效率问题并支持通过索引文件随机读取,但这种方法不能存储图像的原始完整信息,而且图像与数组互相转换的编码与解码方法较为复杂,目前仅支持RGB颜色空间和jpg、png、ppm格式的图像,应用范围受到一定的限制。
综上所述,目前几乎没有一种适合大规模场景图像的高效的特征聚类和检索方法。因此,本文在上述研究的基础上,以传统的K-Means算法和海量场景图像为研究对象,在MapReduce冰箱编程模型框架下,研究场景图像的特征聚类优化方法,分析如何能准确、快速、高效的从海量场景图像库中检索到用户需要的图像数据,实现“以人为本”的高效场景图像检索。
2系统整体架构
针对传统的单节点架构和场景图像迅速增长引发的瓶颈问题,本文提出了Hadoop分布式平台下的场景图像检索方案,系统整体架构如图1所示。
系统整体架构分为三层:
(1) 表现层:用户通过Internet获取服务,提交示例图像或接收检索结果。
(2) 业务逻辑层:Web服务器根据用户的检索请求执行相应的业务处理。
(3) 数据处理层:是整个系统的核心部分,主要进行海量场景图像的存储和管理,负责场景图像的特征提取、匹配、输出结果等。用户将检索示例图像或检索关键字通过Internet提交给Hadoop分布式系统,经过MapReduce计算模型进行特征提取(如果是示例图像),然后进行特征匹配:如果是示例图像检索,就将示例图像特征与HDFS中存储的场景图像特征库匹配;如果是关键字检索,就将检索关键字与场景图像库的标注信息匹配;最后输出检索结果。
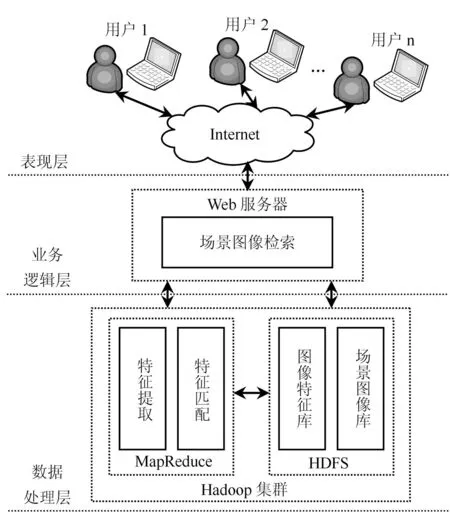
图1 海量场景图像检索系统架构
2.1MapReduce并行编程模型
MapReduce是Hadoop分布式处理的核心技术之一,它为大数据的处理提供了一种面向底层的分布式并行处理计算模式,为开发者提供了一套完整的编程接口和执行环境。MapReduce采用标准的函数式编程计算模式,核心是可以将被称为高次函数的函数作为参数进行传递,通过多个高次函数的串接,将数据的计算过程转换成为函数的执行过程。
MapReduce将数据的计算过程分为Map和Reduce两个阶段,分别对应两个函数:mapper和reducer。在Map阶段,原始数据经分段处理后作为输入给mapper,经过过滤和转换,将产生的中间结果作为Reduce阶段reducer的输入,最后经过聚合处理得到最终结果。
Map阶段,MapReduce将用户的输入数据分割为固定大小的片段(Split),然后将每个Split分解成一批键值对
Reduce阶段,Reduce把从不同的mapper函数接收过来的数据整合排序,然后调用对应的reducer函数,将
其过程表示为:
Map:(k1,v1)→list(k2,v2)
Reduce:(k2,list(v2))→list(k3,v3)
2.2HDFS体系结构设计
HDFS也是Hadoop的核心子项目之一,采用主从(Master/Slave)模式体系结构,将大规模的数据存储在多台相关联的计算机上,既可增加存储容量,又能实现自动容错,能够自动检测和快速恢复硬件故障,在超大规模数据集上方便的进行流式数据访问。
当图像数据规模很大时,如果将其全部存储在HDFS中,那么读取图像会产生很大的时间开销,HBase是一个在HDFS之上的面向列的分布式数据库,可以进行实时读写,因此本文将场景图像的存储路径和特征存储于HBase分布式数据库中。结构如表1所示。

表1 海量场景图像的存储表设计
将场景图像的ID作为HBase表的主键,取图像和提取的图像特征、标注信息作为HBase表的两个列族。由于HBase对表执行的是按行原子操作,因此将一张场景图像的所有信息全部放在一行存放,以便于读写。
3改进的分布式K-Means特征聚类算法
3.1场景图像特征提取
由于SURF算法能在保持尺度、旋转、照明变化等无关特性的同时,使得计算过程效率更高,因此,本文采用SURF算法提取场景图像的特征。过程如下:
(1) 计算场景图像每个像素点X=(x,y)在尺度σ下的Hessian矩阵:
(1)
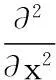
该矩阵是由二阶导数构成的矩阵,用不同尺度σ下的近似高斯核计算求得,因此,Hessian值实际上是一个包含三个变量的函数:H(x,y,σ)。
(2) 计算在空间域和尺度域上同时达到局部极大值时的相应位置和尺度。
对于每个特征点,求其在半径为6σ的圆内的Haar小波在x和y方向的响应dx和dy,对覆盖在60°范围内的响应求和,旋转窗口得到最长向量的方向即为主要方向。
(3) 对得到的64维特征向量做归一化处理。
该过程在Hadoop分布式处理平台下的MapReduce计算过程如下:
Map任务:
输入:
输出:
mapper函数对每张场景图像利用SURF算法特征向量,并统计特证数,便于归一化处理。
Reduce任务:
reducer函数将mapper函数输出的每个键值对作为自己的输入,并再将其传递到输出部分。
3.2特征聚类
K-Means聚类算法是一个重复迭代算法,在分布式环境下,每次迭代都会耗费大量的时间和通信量,而且用于图像的特征聚类时,图像的属性维数较高,数量较多,因此传统的分布式K-Means算法的时间复杂度很大。本文改进了传统的分布式K-Means算法,首先使用Canopy算法选择初始聚类中心,然后在聚类中心点生成的过程中使用Combine函数进行了本地的合并,这样既优化了初始聚类中心,又优化了算法的迭代过程,大大降低了分布式K-Means算法的时间复杂度。
(1) Canopy算法和K-Means算法
Canopy算法[11]的主要思想是将聚类分成两个阶段:首先,使用一个简单、快捷的距离计算方法将数据分成被称为“canopy”的可重叠的子集;然后,使用一个精准而严密的距离计算方法计算出现在第一阶段中的属于同一个“canopy”的所有数据向量的距离。该算法由于只计算重叠部分的数据向量而有效地减少了计算量。
K-Means算法[11]是一种经典的基于距离的聚类算法,它采用距离作为相似性的评价指标,即两个对象的距离越近,相似性就越大。其基本思想为:首先随机选取k个点作为初始聚类中心,然后计算各样本到中心点的距离,将样本归类到离其最近的簇中,接着对调整后的新类计算新的簇中心,若相邻两次的簇中心没有变化,则样本调整结束,聚类准则函数E收敛。

(2)
其中,Mi为类Ci中数据对象的均值,p是类Ci中的空间点。
分布式K-Means算法[11]的基本思想是:首先随机选择一个站点作为主站点,然后主站点利用K-Means算法将其划分为k个簇,接着主站点将各个簇的中心点广播给其余的k-1个子站点,最后各子站点计算本站点的数据对象与中心站点各个簇中心点的距离,并将每个样本点归入离其最近的中心点,将不属于自己的样本对象传送给与该样本对象所属的簇类对应的站点。反复迭代,直到判别函数E收敛为止。
(2) 改进的分布式K-Means特征聚类算法描述
本文将Canopy算法与K-Means算法结合,利用Canopy算法优化K-Means算法的初始聚类中心,其算法描述如下。
算法分为两大部分:初始聚类中心的优化和聚类迭代过程的优化。
利用Canopy算法对初始聚类中心的优化过程为:
输入:场景图像数据集List(形如
输出:k个初始聚类中心(形如
① 数据预处理。将场景图像数据集合List按照图像的image_id排序,并设置初始距离阈值T1和T2(使用交叉验证获得),且T1>T2。
②mapper函数随机选取一个场景图像样本向量作为一个canopy中心向量,然后遍历场景图像数据集合List,若场景图像数据与canopy中心向量之间的距离小于T1,则将该图像数据归入此canopy;若距离小于T2,则将该图像数据从原始数据集中去除,直到List为空;最后输出所有的canopy中心向量。
③reducer函数处理mapper函数的输出,整合Map阶段产生的canopy中心向量,生成新的canopy中心向量,即初始聚类中心。
这样就得到了k个初始聚类中心。
利用K-Means算法进行特征聚类的迭代优化过程为:
输入:场景图像数据集List(形如
输出:k个聚类中心(形如
①mapper函数接收Canopy算法reducer函数的输出,计算各场景图像数据对象到其所属的各canopy中最近的簇中心的距离,输出场景图像数据及所属的簇,形如
②combine函数接收mapper函数的输出,在本地进行同一簇对象的合并,即对各簇中场景图像数据对象的对应维求和,统计数据对象的个数,得到形如
③reducer函数接收combine函数的输出,统计各簇的所有场景图像数据对象的对应维之和、场景图像数据对象的总个数,得到新的簇中心值作为稳定的K-Means簇中心,形如
④ 根据产生的稳定的簇中心,进行聚类划分:mapper函数接收待聚类场景图像数据作为输入,并加载稳定的K-Means簇中心,计算各场景图像数据对象与k个簇中心之间的距离,得到该数据对象最终所属的簇;reducer函数接收mapper函数的输出,进行数据收集,得到最终的聚类结果。
对于场景图像特征相似度的计算,本文采用欧几里得距离公式进行计算。
(3)
4海量场景图像检索的实现
检索流程如图2所示。

图2 海量场景图像检索流程
基于改进的分布式K-Means特征聚类的海量场景图像检索,根据场景图像的SURF特征描述图像,结合场景图像的标注信息特征,实现图像检索。主要是以下几个步骤:
(1) 场景图像库以及标注信息存储于HDFS的HBase分布式数据库中,用于特征提取、聚类以及获取检索结果。
(2) 对库中的场景图像使用SURF算法进行分布式并行特征提取,并使用本文提出的改进的分布式K-Means算法进行特征聚类,将聚类后的图像数据及特征信息存储于HDFS中。
(3) 在图像检索阶段,Map任务接收用户输入的检索要求,并读取图像特征信息库,判断检索要求,提取示例图像特征,计算待检索图像特征与图像库中各聚类中心的相似度,并将计算的结果作为中间结果输出。
(4)Reduce任务接收Map任务的输出,将相似度按从大到小的顺序排序,将相似度最大的聚类中心的场景图像作为最终检索结果输出。
5实验及结果分析
5.1实验环境和测试数据
本文实验环境搭建的Hadoop集群由局域网内5台计算机构成,其中1台计算机为Master节点,其余4台计算机为Slave节点,各节点计算机采用4G双核处理器,500GB硬盘空间的基本配置,操作系统采用Ubuntu。
本文的实验测试数据来自Internet上的SUNDatabase场景图像数据库,该数据库目前包含131 067张场景图像,908个场景类别。由于实验条件的限制,我们从中选取20 000张场景图像作为实验测试数据集。
5.2系统性能测试与分析
(1) 存储性能测试与分析
在做存储性能实验测试时,根据Hadoop集群不同节点个数的情况,我们对存储不同的场景图像集规模所需消耗的时间进行了实验对比,场景图像集的规模分别设置为:500、1000、3000、6000、10 000、15 000、20 000张;在1个、2个、3个和4个节点时分别做了存储耗时性能的测试。实验结果如图3所示。
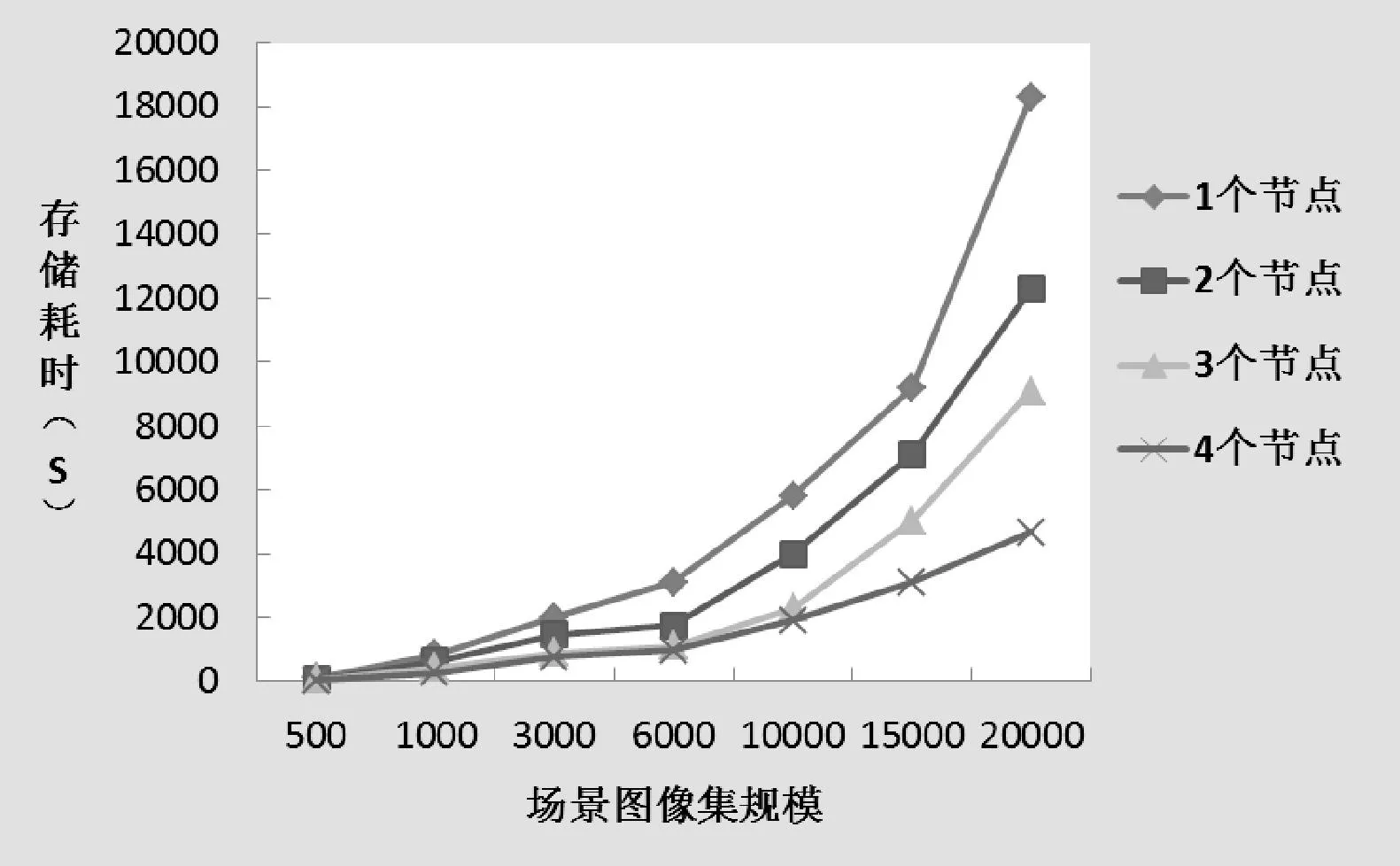
图3 海量场景图像存储耗时对比
可以看出,在场景图像的规模小于1000张时,节点数量的增长对场景图像存储耗时性能的影响并不明显,当场景图像的规模大于1000时,分布式并行存储的优势逐渐明显。在相同的图像规模下,存储耗时随着节点的数量增加而下降;随着图像规模的增大,存储耗时也在不断增加,然而,单节点集群增加最快,而4个节点集群的增长速度最为缓慢,即在图像规模不太大时,不适合采用多节点集群分布式存储,而当图像规模变大时,采用分布式存储的效率是很高的。
(2) 检索性能测试与分析
为验证检索的效果,本文从检索准确率、加速比与效率、数据伸缩率等三个方面进行了实验对比。
① 检索准确率
本文首先使用传统的查准率、召回率以及F1值来衡量系统的检索效果。表2是在不同的场景图像规模下,结合人工辅助的统计,得到的检索效率。
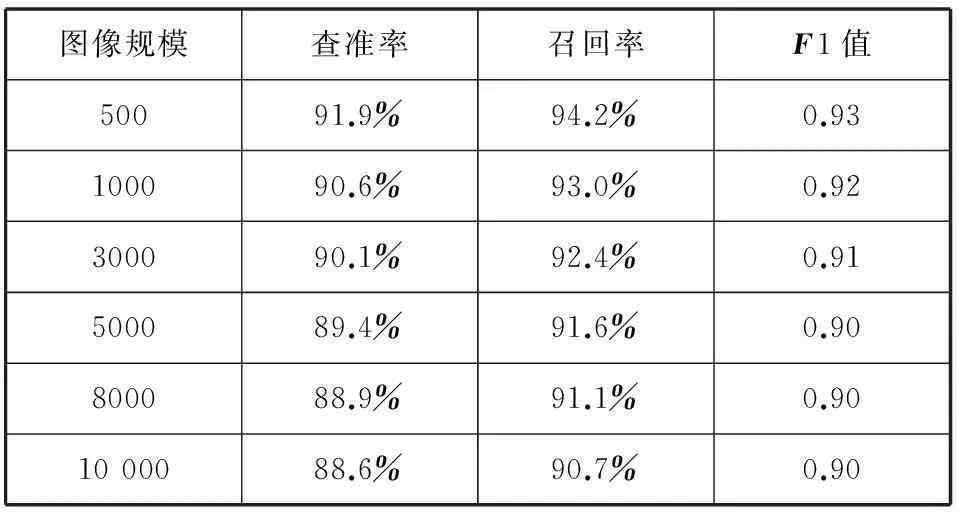
表2 检索平均准确率比较
从表2可以看出,系统检索的查准率、召回率和F1值都较高,检索效果较好;另外,还可以看到,随着场景图像规模的不断增大,虽然系统的查准率和召回率在降低,但下降的幅度很小,这充分说明,采用分布式并行处理方式非常适合大规模数据的处理。
② 数据伸缩率
数据伸缩率[2]是衡量设计的方案处理不同数据规模的能力的一个指标,是指处理扩大后的数据集所需的时间与处理原始数据集所需时间的比值。实验以节点数为4进行,从1 000张场景图像的数据规模起,逐渐将图像规模增加到10 000,测试结果如图4所示。
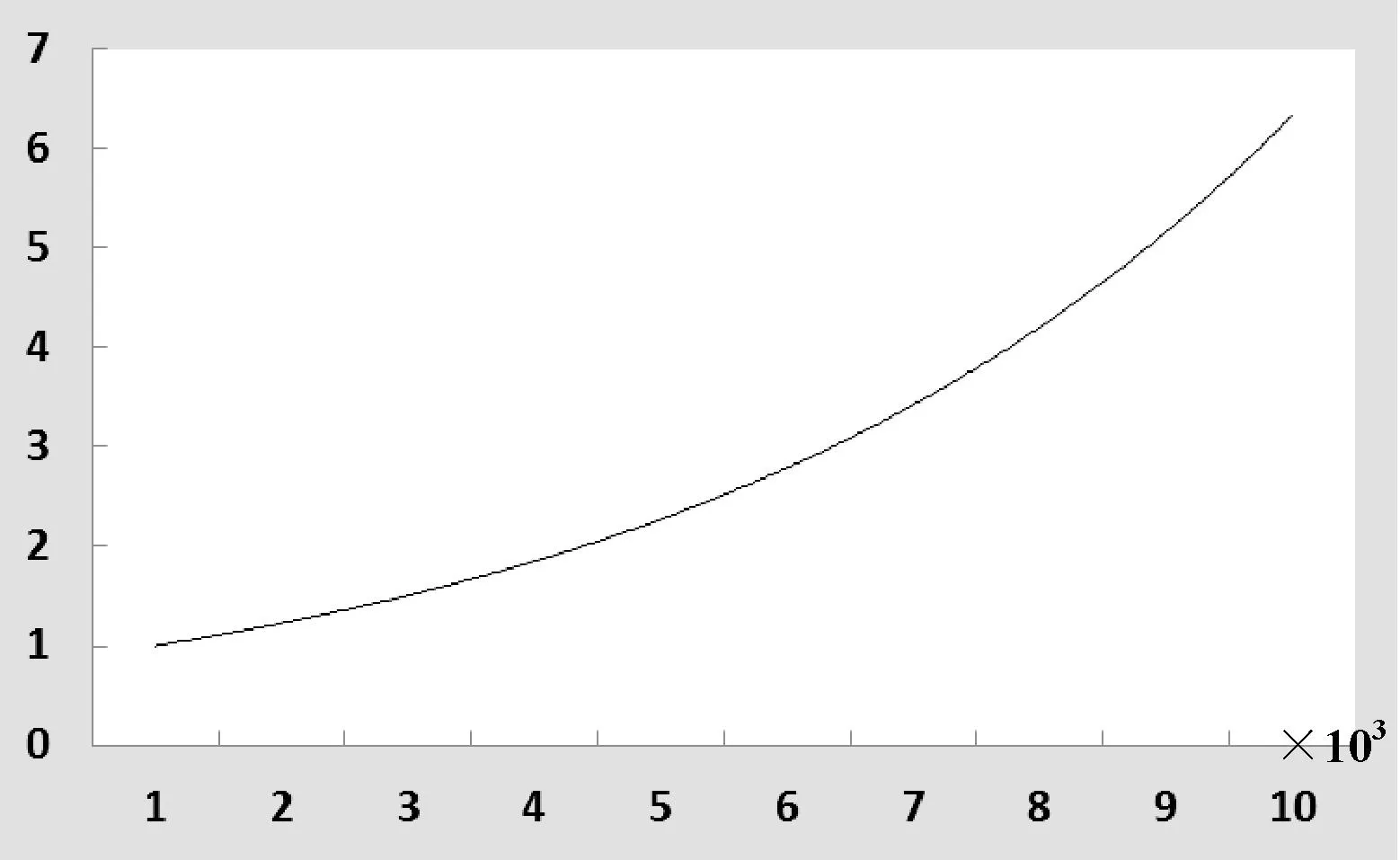
图4 系统数据伸缩率测试
可以看到,在场景图像的规模小于5000时,数据伸缩率曲线较为平缓,这说明在图像数量较少时,系统并不能充分发挥各数据节点的计算能力,而当图像规模大于5000时,数据伸缩率的增长趋势较快,曲线上升较为陡峭,这进一步的说明数据规模愈大,愈能发挥各数据节点的计算能力。同时,可以看出,图像规模从5000张扩大到10 000张时大约需要3.8倍的时间,而从1000张扩大到10 000张时只用了大约5.8倍的时间,系统取得了较好的数据伸缩率。
③ 加速比与效率
加速比[2,13]是指同一任务在单个计算节点的运行时间与多个计算节点的运行时间之比,效率是加速比与计算节点数量之比,二者是用来衡量检索方案整体性能的指标。图5是场景图像规模分别为5000、10 000、15 000时系统加速比与效率的实验对比结果。

图5 系统性能对比
在理想状态下,系统加速比应随着节点个数增加而线性增长,效率始终保持不变。但实际上由于任务的控制受到通信开销、负载平衡等因素的影响,加速比不会线性增长,系统效率并不会达到1。GollerA[12,14]等人认为只要效率达到0.5,即可认为系统获得了很好的性能。从图5可以看出,通过对三组规模不同的场景图像的测试,加速比随着节点个数的增加而增加,效率都在0.5以上,这充分说明系统获得了很好的性能。另外,随着场景图像规模的增大,节点个数愈多,加速比与效率的性能就愈好,这同时也说明在分布式并行处理情况下,数据规模愈大,愈能充分发挥各数据节点的计算能力。
从整体上看,无论是存储性能还是检索性能,本文提出的基于改进的分布式K-Means特征聚类的海量场景图像检索方法都达到了很好的效果。
6结语
本文对基于改进的分布式K-Means特征聚类的海量场景图像检索方法进行了深入探讨和研究,研究了如何对分布式K-Means算法改进,并将其应用于场景图像检索的特征聚类中,在Hadoop分布式处理平台上实现了海量场景图像的检索。实验结果表明,设计的检索方案能均衡系统负载,充分利用分布式系统的资源,提高检索速度;面对海量的场景图像数据,Hadoop分布式系统的检索效率相对于单节点架构的系统有很大提高,充分体现了分布式并行处理架构的强大计算能力。
随着大数据时代的到来以及云计算、多媒体技术的快速发展,对于大规模多媒体数据的分析和处理逐渐成为新的研究热点。本文下一步的研究内容主要包括:(1) 扩展Hadoop分布式平台的节点数,调节系统的相关参数,进一步提高分布式系统的工作效率;(2) 优化特征提取和聚类算法,提高检索的准确率;(3) 优化分布式处理Map任务和Reduce任务的设计,从而实现更快、更精确的检索。
参考文献
[1]AlmeerMH.CloudHadoopmapreduceforremotesensingimageanalysis[J].JournalofEmergingTrendsinComputingandInformationSciences,2012,3(4):637-644.
[2] 朱为盛,王鹏.基于Hadoop云计算平台的大规模图像检索方案[J].计算机应用,2014,34(3):695-699.
[3]NehaA,KiriiA.Amid-pointbasedk-meanclusteringalgorithmforDatamining[J].InternationalJournalonComputerScienceandEngineering,2012,4(6):1174-1180.
[4] 张军伟,王念滨,黄少滨,等.二分K均值聚类算法优化及并行化研究[J].计算机工程,2011,37(11):23-25.
[5] 韩最蛟.基于数据密集性的自适应K均值初始化方法[J].计算机应用与软件,2014,31(2):182-187.
[6] 赵卫中,马慧芳,傅燕翔,等.基于云计算平台Hadoop的并行K-Means聚类算法设计研究[J].计算机科学,2011,38(10):166-168.
[7] 金伟健,王春枝.适于进化算法的迭代式MapReduce框架[J].计算机应用,2013,33(12):3591-3595.
[8]WileyK,ConnollyA,KrughoffS,etal.AstronomicalimageprocessingwithHadoop[C]//Proceedingsofthe20thConferenceonAstronomicalDataAnalysisSoftwareandSystems.SanFrancisco:AstronomicalSocietyofthePacific,2011:93-96.
[9] 朱义明.基于Hadoop平台的图像分类[J].西南科技大学学报,2011,26(2):70-73.
[10]SweeneyC,LiuL,AriettaS,etal.HIPI:aHadoopimageprocessinginterfaceforimage-basedmapreducetasks[D].Charlattesville:UniversityofVirginia,2011.
[11] 樊哲.Mahout算法解析与案例实战[M].北京:机械工业出版社,2014.
[12]GollerA,GlendinningI,BachmannD,etal.Parallelanddistributedprocessing[M].DigitalImageAnalysis.Berlin:Springer-Verlag,2001:135-153.
[13] 王贤伟,戴青云,姜文超,等.基于MapReduce的外观设计专利图像检索方法[J].小型微型计算机系统,2012,33(3):626-632.
[14] 颜宏文,陈鹏.基于云模型的电网统计数据质量评估方法研究[J].计算机应用与软件,2014,31(12):100-103.
MASSIVE SCENE IMAGE RETRIEVAL BASED ON IMPROVED DISTRIBUTEDK-MEANSFEATURECLUSTERING
Cui HongyanCao Jianfang*
(Department of Computer Science and Technology,Xinzhou Teachers University,Xinzhou 034000,Shanxi,China)
AbstractConcerning that traditional image retrieval methods are confronted with the problems when processing massive data, we put forward a retrieval method for massive scene images, which is based on improved k-means feature clustering. We improved the distributed K-means algorithm, optimised the selection of initial cluster centres and the iteration procedure, and applied it to feature clustering of scene images. We made full use of the massive storage capacity and the powerful parallel computing ability of Hadoop distributed platform, proposed the storage and retrieval scheme on massive scene image, and designed the Map and Reduce tasks of three-phase distributed parallel processing on scene image with feature extraction, feature clustering and image retrieval. Sets of experiments demonstrated that the proposed method has gentle curve of data expansion rate, achieves good speedup ratio, the efficiency is greater than 0.6, and the average accuracy rate of retrieval reaches about 88%. The proposed scheme is suitable for large-scale scene image data retrieval.
KeywordsHadoop distributed platformMapReduceDistributed k-means algorithmFeature clusteringScene image retrieval
收稿日期:2015-01-19。国家自然科学基金项目(61202163);山西省高校大学生创新创业训练项目(2014383);山西省自然科学基金项目(2013011017-2);忻州师范学院重点学科专项课题(XK201308)。崔红艳,本科生,主研领域:数字图像理解。曹建芳,副教授。
中图分类号TP391
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.047
