一种基于深度神经网络的话者确认方法
2016-07-19吴明辉胡群威
吴明辉 胡群威 李 辉
(中国科学技术大学电子科学与技术系 安徽 合肥 230027)
一种基于深度神经网络的话者确认方法
吴明辉胡群威李辉
(中国科学技术大学电子科学与技术系安徽 合肥 230027)
摘要主要研究基于深度神经网络的话者确认方法。在训练阶段,以语音倒谱特征参数作为输入,说话人标签作为输出有监督的训练DNN;在话者注册阶段,从已训练的DNN最后一个隐藏层抽取与说话人相关的特征矢量,称为d-vector,作为话者模型;在测试阶段,从测试语音中抽取其d-vector与注册的话者模型相比较然后做出判决。实验结果表明,基于DNN的话者确认方法是可行的,并且在噪声环境及低的错误拒绝率的条件下,基于DNN的话者确认系统性能比i-vector基线系统性能更优。最后,将两个系统进行融合,融合后的系统相对于i-vector基线系统在干净语音和噪声语音条件下等误识率(EER)分别下降了13%和27%。
关键词话者确认深度神经网络深度学习
0引言
随着语音相关技术的发展和成熟,在日常生活中语音的应用越来越广泛,而语音作为证据在安全方面的应用也日益重要,使得对话者确认技术SV(SpeakerVerification)的需求越来越迫切。话者确认的任务是通过测试给定语音波形信号中包含的说话人个性信息,从而对其声明的身份进行判决。根据是否限定说话的内容,话者确认分为与文本有关和与文本无关两种类型。与文本有关的话者确认要求测试语音的内容要与注册语音的内容相同,所以只能用于某些特殊的领域;而与文本无关的话者确认不要求测试语音和注册语音的内容相同,所以应用范围更广,在本文中主要研究与文本无关的话者确认方法。
一般的话者确认系统可以分为以下三个阶段:
(1) 训练阶段:通过大量的语音数据训练得到通用的背景模型。背景模型的类型有很多种,目前应用较广的主要是基于高斯混合模型GMM(GaussianMixtureModel)的通用背景模型UBM[1],还有基于联合因子分析JFA(JointFactorAnalysis)的通用模型[2-4]。
(2) 注册阶段:根据目标说话人的语音数据,结合通用背景模型,获得与目标说话人相关的话者模型,一般要求目标说话人的语音数据和通用背景模型的训练语音数据不重叠。
(3) 测试阶段:将测试语音经过话者模型和通用背景模型输出评分,然后与设定的阈值比较,做出判决。
在上述三个阶段采用不同的方法,已经产生了很多不同的话者确认系统。目前,主流的话者确认系统是采用i-vector和PLDA结合的方法[5],在这个系统中,主要是利用JFA作为特征提取器,从语音倒谱特征中提取一个与说话人相关的低维向量i-vector,然后通过PLDA进行后续的处理,输出评分。
近年来,深度神经网络DNN以其强大的特征表示能力,成功应用于语音识别领域[6]。本文提出在话者确认系统中利用DNN作为特征提取器,通过构建语音倒谱特征到说话人的一个映射,从而建立通用背景模型。在注册阶段,通过注册语音训练DNN,然后抽取DNN最后一个隐藏层的输出,将其定义为d-vector;在测试阶段,与基于i-vector的话者确认系统相同,根据目标说话人的d-vector和测试语音的d-vector之间的距离做出判决,接受或拒绝。
为了验证本文方法的有效性,参考了美国国家标准技术署BIST(NationalInstituteofStandardandTechnology)评测[7]的部分要求,采用等误识率EER(EqualErrorRate)和DET(DetectionErrorTrade-off)曲线作为评价标准,对NIST语料库进行测试,实验表明本文构建的系统取得了较好的性能。
1相关背景介绍
基于i-vector和PLDA的话者确认系统是目前与文本无关话者确认系统中的主流系统。i-vector可以看作是语音倒谱特征在全局差异空间(TotalVariabilitySpace)的一个低维表示,其中包含了大部分的说话人个性信息和少量其他信息。对于一个给定的语音信号,定义均值超矢量如下:
M=m+Tω
(1)
其中m是一个与说话人无关的均值超矢量,通常采用UBM的均值超矢量代替,T是一个低秩矩阵,称为全局差异矩阵TVM(TotalVariabilityMatrix),ω是一个服从标准正态分布的向量,称为i-vector。在获得i-vector以后,再进行PLDA操作,这个和JFA的原理相同,都是进一步将语音中包含的说话人个性信息和通道信息区分开,从而获得更好的识别效果[8,9]。
在过去的研究中,已经尝试过将神经网络用于话者确认系统中,因为神经网络具有很好的非线性分类能力,所以能够对语音信号中包含的说话人个性信息进行鉴别。其中自联想神经网络AANN(AutoAssociativeNeuralNetwork)[10]采用目标说话人AANN网络输出和背景模型UBM-AANN输出之间的误差进行网络重构,被用于话者确认系统中;带有bottleneck层的多层感知机MLP(Multi-layerperceptions)也曾被用于话者确认系统中[11]。最近,已经有研究将深度神经网络用于话者确认系统中,如基于卷积神经网络和玻尔兹曼机的话者确认系统[12,13]。
2基于DNN的话者确认系统
本文提出基于DNN的话者确认系统模型如图1所示。DNN用于提取语音倒谱特征MFCC中与说话人相关的特征参数,这个方法与文献[12]类似,但主要的不同是本文采用有监督的训练方法,并且用DNN代替卷积神经网络。
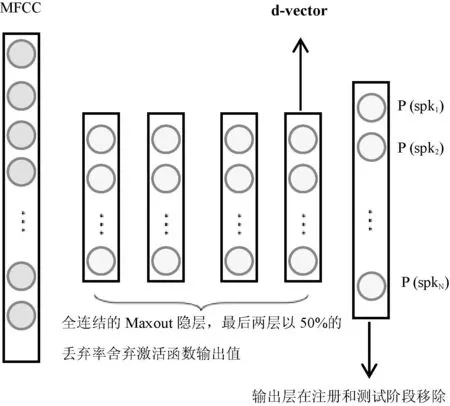
图1 基于DNN的话者确认系统背景模型
2.1DNN作为特征提取器
本文所提出方法的核心思想就是将DNN用作特征提取器,在i-vector基线系统中采用DNN代替JFA作为背景模型,从语音倒谱特征中提取一个与说话人相关的特征向量[14]。
基于这样的思想,首先在语音倒谱特征上构建有监督的DNN系统,用于区分训练集中不同说话人的语音信号。这个背景神经网络的输入采用扩展的40帧语音MFCC参数,就是将原始的语音MFCC特征参数进行左右扩展;另外对训练集中的N个说话人采用一个N维向量进行编号。其中对应说话人维度的值为1,其他维度的值都为0,这些编号称为说话人的身份标签,DNN系统的输出对应为这些标签,图1为DNN的拓扑结构图。
当训练完DNN以后,使用其最后一个隐藏层输出作为对说话人信息的一种表示,也就是说,先获得语音的MFCC参数。然后将这些特征参数输入到DNN中,用前向传播算法求出最后一个隐藏层的输出,即为对说话人的一个新的表示,称这个输出为d-vector。选用DNN的最后一个隐藏层作为输出而不是选用softmax分类器作为输出的原因有两个:首先,这样做可以减小神经网络的规模,通过舍弃DNN的输出层,可以在增加训练数据集时,而不用增加网络的规模;其次,通过后面的实验发现这样提取的特征用于话者确认的性能更好。
2.2注册和测试
当给定说话人s的一个语料集Xs={Os1,Os2,…,Osn},其中每一条语音可以表示为多帧的特征向量Osi={o1,o2,…,om}。注册过程描述如下:首先,使用说话人s的每一条语音Osi中的特征向量oj和他的身份标签去有监督的训练DNN,将DNN最后一个隐藏层输出称为与Osi有关的d-vector;然后,将所有的这些d-vector进行平均处理得到最后的d-vector,称为与说话人s相关的d-vector。
在测试过程中,首先抽取测试语音的d-vector,然后计算测试语音d-vector和注册语音的d-vector之间的余弦距离,将这个值与事前设定的阈值作比较进行判决。
2.3DNN的训练过程
本文采用带有dropout策略的最大输出(Maxout)DNN[15,16]作为背景模型。在训练样本集较小时,dropout策略可以很好的预防DNN过拟合[16],dropout策略就是在训练的过程中随机丢弃一些隐藏层节点的输出。MaxoutDNN是对dropout策略一种很好的实现,MaxoutDNN不同于标准的MLP,其将每一层输出分为不重叠的两组,每一组通过最大化输出的策略选择单个激活函数的值作为输出。在本文中,训练一个带有4个隐藏层的DNN,每个隐藏层包含512个节点。前两层不使用dropout策略,后两层以50%的概率丢弃激活函数输出进行DNN的训练,如图1所示。使用sigmoid函数作为每一个非线性神经元的激活函数,学习率为0.001。DNN的输入采用堆叠的40帧的语音MFCC参数,即向左扩展20帧,向右扩展20帧组成的超帧参数,目标向量的维度为800,与训练集中话者的人数相同。最终的DNN大约有2MB左右的参数,这和最小的i-vector基线系统类似。
3实验与分析
3.1实验数据库
实验数据来自美国国家标准技术署NIST(NationalInstituteofStandardandTechnology)举办的全球说话人评测比赛中的语音数据[7]。NIST语料库覆盖了多种传输信道情况和话筒类型。以NIST10语料库为例,其根据语料数据的不同,分成5种训练条件和4种测试条件,将不同的训练条件和测试条件组合即可作为不同的测试任务。其中一个组合作为核心任务,所有评测的参赛者都必须要完成核心任务,由于NIST语料库数据量庞大,本实验从NIST10语料库中选择1000个说话人语料作为测试子集。其中800个说话人语音用作背景模型的训练,200个说话人语音用作注册和测试,每个说话人包含30条语音,每条语音的长度大约为3min(VAD后大约2min)。从800个说话人中每人选出10条用作背景模型的训练,注册和测试时,每个说话人的前20条语音用作注册,剩下的用作确认测试。从其他199个人中每人选出10条作为冒认测试,一共进行400 000次测试。
3.2基线系统
在本文中,主要目的是保持模型在较小的规模下仍能够完成比较好的效果。基线系统采用基于i-vector的话者确认系统,GMM-UBM采用13维的MFCC参数及其一阶差分和二阶差分进行训练。使用EER作为评判标准,测试采用不同混合度的UBM和不同的i-vector维度以及不同LDA之后的维度对系统性能的影响,从而评估i-vector系统在什么样的模型大小下性能最好。其中TVM采用PCA进行初始化,迭代10次,UBM采用6次迭代。
如表1所示,基于i-vector的话者确认系统随着系统规模的下降,性能也会有所下降,同样可以看出,在进行了t-norm[17]规整后的性能会明显优于不进行规整的原始输出评分。其中最小的i-vector系统包含2M左右的参数,和本文的系统规模类似。
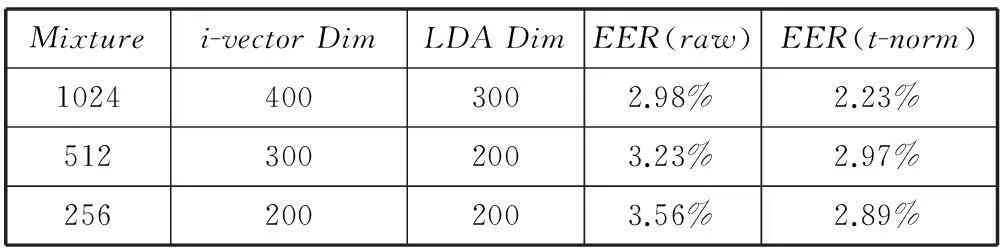
表1 不同参数配置下i-vector系统的性能对比
3.3基于DNN的话者确认系统
如图2所示,是基于i-vector的基线系统和基于d-vector的话者确认系统的性能比较。通过观察DET曲线发现在d-vector系统中,未经规整的原始输出评分要比经过t-norm规整后的评分效果好。而i-vector系统中依然是t-norm之后的评分优于未经规整的评分,这可能是因为经过d-vector系统输出的评分并不是服从正太分布而是服从重尾分布。因此在以后的工作中需要对d-vector系统输出评分采用新的评分规整策略。在接下来的实验中,基于d-vector的实验都采用原始的评分作为输出。
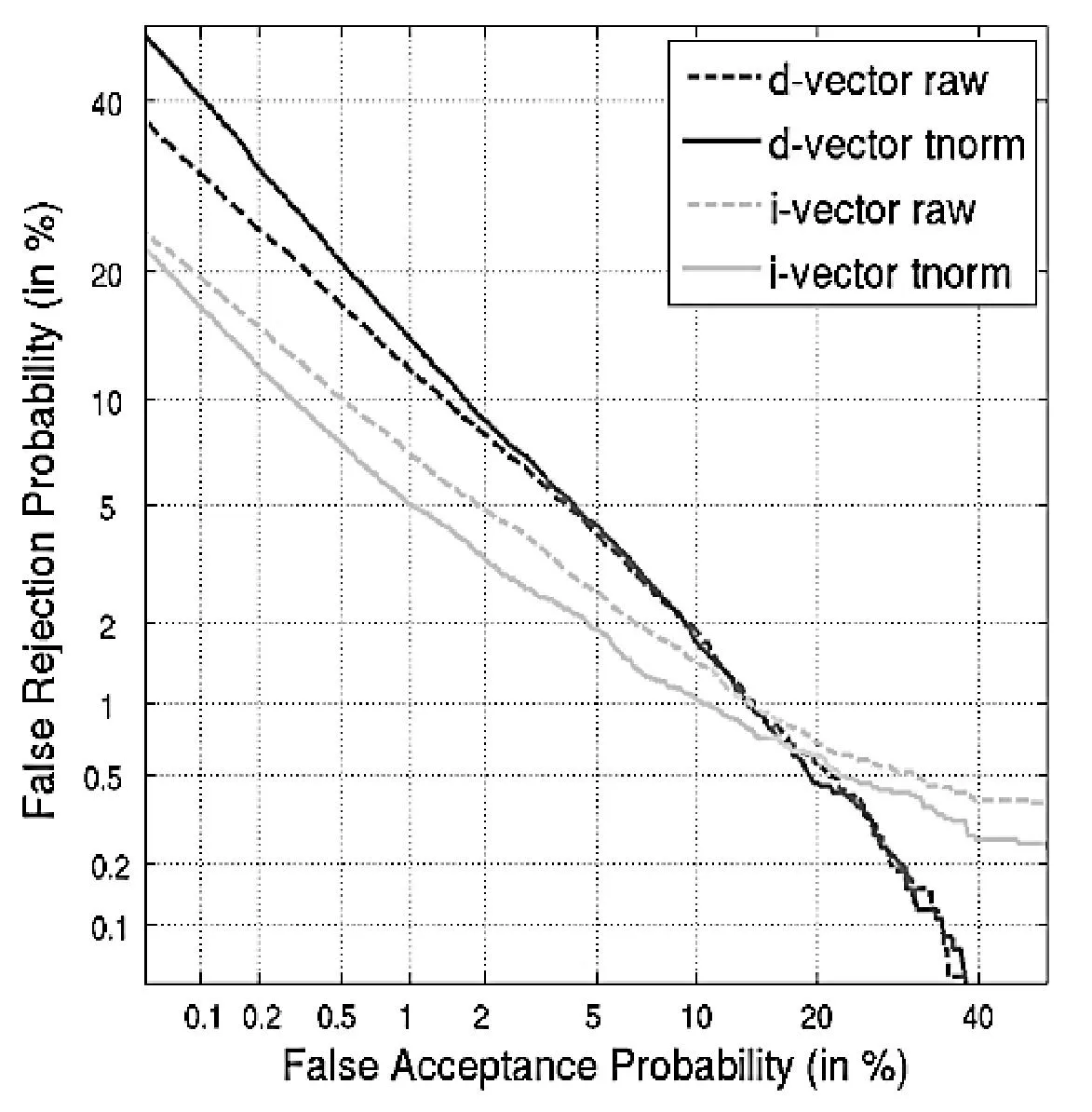
图2 比较t-norm评分规整对两个系统的影响
从DET曲线中可以看出经过t-norm规整后的i-vector系统的EER为2.84%,而未经规整的d-vector系统EER为4.55%。所以基于i-vector的系统性能要优于d-vector系统,然而在低的错误拒绝率时,如图2右下角所示,基于d-vector系统的性能优于i-vector系统。
同样也实验了采用不同的参数配置去训练DNN,发现不使用dropout策略,EER会上升3%左右。通过增加隐藏层的数量到1024,对于整个系统的性能没有提高,但当减少隐藏层的节点数目到256时,系统的EER上升到了8%。
3.4注册数据的影响
在d-vector系统中,在注册阶段没有统计说话人语料数目对整个系统性能的影响,在这个实验主要研究每个说话人选用不同数目的语料对基于i-vector的基线系统和基于d-vector的话者确认系统的影响。在注册阶段每个说话人分别选用4、8、12、20条语音进行比较。
通过分析表2中各个情况下的EER,在两个系统的性能都是随着注册语音数目的增加而提高,并且趋势相同。

表2 不同的注册语音数目对系统的影响
3.5噪声鲁棒性
在实际的应用中往往训练阶段和实际测试阶段环境不匹配,在这个实验中,主要测试在噪声环境下,两个系统性能的比较。背景模型都是在干净语音下训练得到,但是在注册语音和测试语音中都加入了10dB的白噪声,两个系统的DET曲线如图3所示。从图可以看出,在噪声情况下,两个系统的性能都有所下降。但是基于d-vector的系统的性能在噪声情况下性能下降的幅度较小,并且在低的错误拒绝率的条件下基于d-vector的话者确认系统的性能要优于基于i-vector的基线系统的性能。
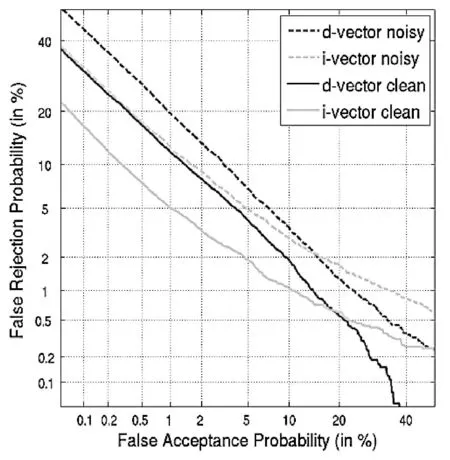
图3 比较采用干净语音和带噪声的语音对两个系统的影响
3.6系统融合
通过上面与i-vector基线系统的比较发现,本文提出的基于d-vector的话者确认系统是可行的,尤其适合于噪声环境和在要求低的错误拒绝率的条件下。然后我们将这两种系统进行融合,称为i/d-vector系统。一般融合的策略有很多种,本文只是简单地将两个系统的输出评分进行平均,如图4和图5中fusion所示,并且在两个系统中都采用t-norm进行规整。通过分析图4和图5可知,融合后的系统i/d-vector在干净语音及带噪声条件下都优于单个系统的性能,就EER来说,i/d-vector系统相对于i-vector系统在干净环境下和噪声环境下分别下降了13%和27%。

图4 在干净语音下比较融合后的系统(fusion)与单个系统的性能
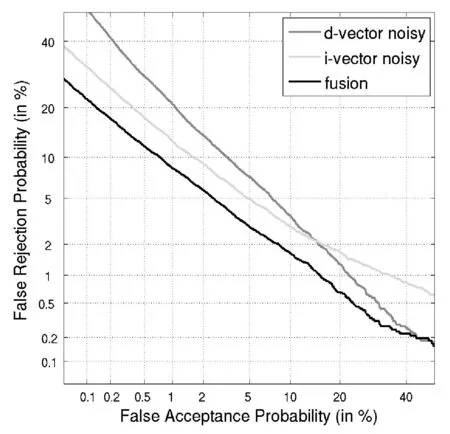
图5 在噪声语音下比较融合后的系统(fusion)与单个系统的性能
4结语
本文提出了一种新的基于DNN的话者确认方法,通过采用语音信号的倒谱特征参数训练DNN来区分说话人,被训练的DNN用于抽取语音信号中与说话人相关的特征参数。最后将这些特征参数取平均,得到d-vector,然后用于话者确认系统。通过实验表明基于d-vector的话者确认系统的性能与i-vector基线系统相当,在融合了两种系统之后发现,融合后的系统优于其任何一个单独的系统。并且在噪声环境下,基于d-vector话者确认系统比i-vector基线系统的鲁棒性更好;在低的错误拒绝率的条件下基于d-vector的话者确认系统优于i-vector基线系统。
接下来的工作主要包括修改现在的余弦评分策略,以及采用新的规整方法对评分进行规整。进一步去探索新的融合策略,如在i-vector和d-vector空间使用PLDA模型等。最终,希望能够提出一种有效的鲁棒性更好的话者确认系统。
参考文献
[1]ReynoldsDA,QuatieriTF,DunnRB.SpeakerverificationusingadaptedGaussianmixturemodels[J].Digitalsignalprocessing,2000,10(1):19-41.
[2]KennyP,BoulianneG,OuelletP,etal.Jointfactoranalysisversuseigenchannelsinspeakerrecognition[J].Audio,Speech,andLanguageProcessing,IEEETransactionson,2007,15(4):1435-1447.
[3]KennyP,BoulianneG,OuelletP,etal.SpeakerandsessionvariabilityinGMM-basedspeakerverification[J].Audio,Speech,andLanguageProcessing,IEEETransactionson,2007,15(4):1448-1460.
[4]KennyP,OuelletP,DehakN,etal.Astudyofinterspeakervariabilityinspeakerverification[J].Audio,Speech,andLanguageProcessing,IEEETransactionson,2008,16(5):980-988.
[5]DehakN,KennyP,DehakR,etal.Front-endfactoranalysisforspeakerverification[J].Audio,Speech,andLanguageProcessing,IEEETransactionson,2011,19(4):788-798.
[6]HintonG,DengL,YuD,etal.Deepneuralnetworksforacousticmodelinginspeechrecognition:Thesharedviewsoffourresearchgroups[J].SignalProcessingMagazine,IEEE,2012,29(6):82-97.
[7]MartinAF,GreenbergCS.TheNIST2010speakerrecognitionevaluation[C]//Interspeech2010,11thAnnualConferenceoftheInternationalSpeechCommunicationAssociation,Makuhari,Chiba,Japan,2010:2726-2729.
[8]KennyP.BayesianSpeakerVerificationwithHeavy-TailedPriors[C]//Proc.OdysseySpeakerandLanguageRecognitionWorkshop,Brno,CzechRepublic,2010:14.
[9]LarcherA,LeeKA,MaB,etal.Phonetically-constrainedPLDAmodelingfortext-dependentspeakerverificationwithmultipleshortutterances[C]//Acoustics,SpeechandSignalProcessing(ICASSP),2013IEEEInternationalConferenceon.IEEE,2013:7673-7677.
[10]YegnanarayanaB,KishoreSP.AANN:analternativetoGMMforpatternrecognition[J].NeuralNetworks,2002,15(3):459-469.
[11]HeckLP,KonigY,SönmezMK,etal.Robustnesstotelephonehandsetdistortioninspeakerrecognitionbydiscriminativefeaturedesign[J].SpeechCommunication,2000,31(2):181-192.
[12]LeeH,PhamP,LargmanY,etal.Unsupervisedfeaturelearningforaudioclassificationusingconvolutionaldeepbeliefnetworks[C]//Advancesinneuralinformationprocessingsystems,2009:1096-1104.
[13]StafylakisT,KennyP,SenoussaouiM,etal.PreliminaryinvestigationofBoltzmannmachineclassifiersforspeakerrecognition[C]//ProceedingsOdysseySpeakerandLanguageRecognitionWorkshop,2012.
[14]VarianiE,LeiX,McDermottE,etal.Deepneuralnetworksforsmallfootprinttext-dependentspeakerverification[C]//Acoustics,SpeechandSignalProcessing(ICASSP),2014IEEEInternationalConferenceon.IEEE,2014:4052-4056.
[15]CaiM,ShiY,LiuJ.Deepmaxoutneuralnetworksforspeechrecognition[C]//AutomaticSpeechRecognitionandUnderstanding(ASRU),2013IEEEWorkshopon.IEEE,2013:291-296.
[16]DahlGE,SainathTN,HintonGE.ImprovingdeepneuralnetworksforLVCSRusingrectifiedlinearunitsanddropout[C]//Acoustics,SpeechandSignalProcessing(ICASSP),2013IEEEInternationalConferenceon.IEEE,2013:8609-8613.
[17]AuckenthalerR,CareyM,LloydThomasH.Scorenormalizationfortext-independentspeakerverificationsystems[J].DigitalSignalProcessing,2000,10(1):42-54.
A SPEAKER VERIFICATION METHOD BASED ON DEEP NEURAL NETWORK
Wu MinghuiHu QunweiLi Hui
(Department of Electronic Science and Technology,University of Science and Technology of China,Hefei 230027,Anhui,China)
AbstractIn this paper we mainly investigate the method of using deep neural network (DNN) for speaker verification. At the stage of training, the DNN is trained under supervision using the feature parameter of speech cepstrum as input and the label of speaker as output. At the stage of speaker registration, an eigenvector correlated to the speaker, namely d-vector, is extracted from the last hidden layer of the trained DNN and is used as the model of speaker. At test stage, from testing speech a d-vector is extracted to compare it with the model of the registered speaker and then to make the verification decision. Experimental results show that the DNN-based speaker verification method is feasible. Moreover, under the condition of noisy environment and low error-rejection rate, the DNN-based speaker verification system outperforms the i-vector base line system in performance. Finally, we integrate these two systems, relative to the i-vector base line system, the integrated system reduces the equal error rate (EER) by 13% and 27% for clean speech and noisy speck conditions respectively.
KeywordsSpeaker verificationDeep neural network (DNN)Deep learning
收稿日期:2014-12-14。吴明辉,硕士,主研领域:人工智能与模式识别,语音信号处理。胡群威,硕士。李辉,副教授。
中图分类号TP3
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.039
