基于分布式计算的遥感图像水体识别研究
2016-07-19田生伟
杨 柳 田生伟
(新疆大学软件学院 新疆 乌鲁木齐 830046)
基于分布式计算的遥感图像水体识别研究
杨柳田生伟
(新疆大学软件学院新疆 乌鲁木齐 830046)
摘要为了提高遥感数据的处理速度,解决遥感信息提取中的数据密集与计算密集问题,将并行计算的思想引入到遥感图像的处理与信息提取中,构建基于Landsat ETM +影像的分布式遥感图像水体提取模型。以渭干河流域为研究区,利用单波段阈值法、多波段谱间关系法、水体指数法等方法进行水体信息自动提取的实验。实验结果表明,该模型具有较高的识别精度,能够快速识别水体,并具有稳定的可扩展性和伸缩性。
关键词大数据遥感水体识别并行计算
0引言
遥感信息提取的主要对象是陆地表层系统中各类自然和人文要素,水体是其中主要的自然要素之一,具体表现为湖泊、河流、湿地等形态[1]。快速、准确地从卫星遥感影像上获取水体信息,已成为水资源调查及监测湿地保护、洪水灾害评估等领域的重要技术手段[2]。随着遥感技术的不断发展,水体大数据呈几何级数倍增,而传统的遥感图像处理软件数据处理能力有限,使得遥感图像的处理速度成为遥感技术在不同领域应用和发展的瓶颈。
为了解决信息提取中的数据密集与计算密集问题,满足对实时性要求较高的应用对速率的要求,并行计算受到国内外学者的普遍关注[3-5]。2004年,Google提出MapReduce[7,8]分布式计算模型。MapReduce模型隐藏了并行计算、数据分配、任务调度及负载均衡等复杂细节,可以实现自动伸缩的大规模并行计算。由于MapReduce编程模式简单,具有高性能和高容错而得到广泛的应用。
本文探讨将分布式并行计算思想应用于遥感图像的水体信息提取中,构建基于MapReduce的遥感图像水体识别模型。选取渭干河-库车河三角洲区域Landsat8影像,利用水体指数模型、单波段阈值法、波谱间关系模型等进行水体信息自动提取的实验,水体识别效率得到了一定的提高。
1MapReduce
1.1MapReduce编程模型
MapReduce是一个处理超大数据集的分布式并行编程模型,它把整个任务拆分成多个子任务,并将这些任务分发给一个主节点(NameNode)。主节点将子任务进行分组并分发给自己管理的各个从节点(DataNode)共同完成。然后,通过整合各个节点的中间结果而得到最终结果。
在分布式计算中,MapReduce框架负责处理并行编程中分布式存储、工作调度以及网络通信等复杂问题,它把处理过程高度抽象为两个函数:Map和Reduce。Map负责把任务分解成多个子任务,Reduce负责把多个子任务处理的结果汇总起来。
1.2MapReduce处理过程
MapReduce处理数据分为两个阶段:Map阶段和Reduce阶段。Map阶段开始前,要对输入数据进行“分片”(即将超大输入数据划分成大小相等的“数据块”)。每个Map任务接收一个数据“分片”,然后产生一个
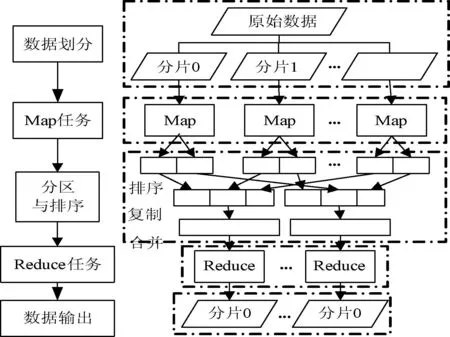
图1 MapReduce模型执行流程
2基于分布式计算的水体识别
2.1数据划分及组织形式
在海量遥感数据并行计算中,数据块的划分方式和数据分块的大小直接影响着并行计算的效率[9]。本研究采用矩形块方式切分每幅影像,以默认数据分块大小(64MB)为单位,对研究区影像进行切分。选取开源的Hadoop为实验平台,基于HDFS(HadoopDistributedFileSystem)和HBase(HadoopDatabase)的特点,将遥感影像文件存放到HDFS中。而其他元数据信息存入HBase中,并采取为同一数据块建立多个副本以提高数据块的可靠性与可用性(如图2所示为B0、B1等数据块存储在HDFS中的示例)。

图2 HDFS下遥感数据块读取流程
2.2基于MapReduce模型的的水体识别
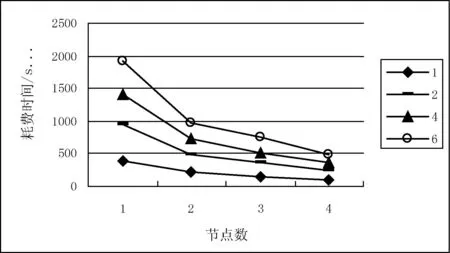
常用的遥感影像水体信息提取方法主要是依据水体和其他地物在各个波段上光谱特征的差异(如图3所示)。利用单个波段或多个波段构造一定的水体提取模型,将水体和其他地物区分开来。本文主要选取单波段阈值法、谱间关系法和水体指数法对水体信息进行提取。

图3 典型地类波谱特征曲线
(1) 单波段阈值法
利用某种地物与背景地物在某一波段上的反射率(或像元灰度值)的差异,确定某一数值为区分该地物和背景地物的方法,称为单波段阈值法[10]。本文选取TM5短波红外波段数据,通过选择一定的阈值T,小于该阈值的为水体,水体提取模型如下所示:
TM5 (1) (2) 谱间关系法 谱间关系法是多波段方法的一种,通过分析地物与水体的光谱特征属性,在LandsatTM影像上,水体对不同波长的光谱反射率随着波长的增加而减小,同时光谱反射率变化范围有限。早期研究表明,通过比较TM2与TM3的光谱值和以及TM4与TM5的光谱值和,可以有效增加水体与地物的光谱差异。而这一谱间关系特点是水体特有的,可以有效的区分水体信息[11]。 (3) 水体指数法 水体指数法是水体识别应用最广泛的方法,它通过选取与水体提取紧密相关的多个波段,构建水体指数数学模型,增强水体与背景地物之间的反差,实现水体信息的提取。本研究选取较为经典的归一化植被指数(NDVI)、归一化差分水体指数(NDWI)[12]和改进归一化差异水体指数(MNDWI)[13]进行水体信息提取,其公式分别为: (2) (3) (4) 其中,NIR代表近红外波段,即b4波段;Red代表红光波段,即b3波段;Green代表绿光波段,即b2波段;MIR代表短波红外波段,即b5或b7波段。 针对LandsatETM+遥感数据,利用上述方法对研究区水体进行识别。Map函数处理划分后的遥感数据块并对水体信息进行提取,输出<影像名,地址>键值对。Reduce函数把所有key值(影像名)相同的键值对的value(影像地址)相加,输出<影像名,影像水体识别结果地址>键值对。 3实验结果与分析 3.1研究区及数据源 渭干河流域位于新疆阿克苏以东225公里的沙雅县境内,经纬度40°55′~41°20′N,82°30′~83°30′E。渭干河是塔里木河的支流之一,发源于天山北坡,由木扎尔特河、克孜尔河等六条支流汇合而成。研究选取2013年6月的渭干河Landsat8卫星遥感影像作为实验数据,并对影像进行包括辐射定标以及大气校正的预处理。 3.2实验环境 实验采用Hadoop的完全分布式模式进行,集群包括4台主机,其中1台作为主节点(NameNode),其余3台作为数据节点(DataNode)。在每台主机上安装LinuxUbuntu12.04、Java环境、JDK1.6和Hadoop0.20,搭建基于Hadoop的并行水体识别集群系统。计算机的硬件配置详细信息如表1所示。 表1 计算节点配置信息 3.3实验结果与分析 3.3.1实验一正确性测试与分析 使用基于MapReduce的水体识别模型对渭干河-库车河三角洲地区进行水体信息提取,部分水体提取结果如图4所示。实验的验证样本为试验区域的高分辨率遥感影像,利用ENVI5.1软件对其进行监督分类得到真实参考源。 图4 水体提取结果 为了确定水体信息提取的精度和可靠性,使用错提率、kappa系数和总体精度等评价指标对5种分类结果进行评价(如表2所示)。 表2 不同水体提取方法精度比较 表2中,不同水体提取方法的精度由大到小顺序依次为:MNDWI>NDWI>NDVI>谱间关系法>单波段阈值法。归一化差异水体指数(MNDWI)能消除地形差异的影响,增强水体与建筑物的反差,因此识别率最高。而单波段阈值法只利用了水体在某一个波段上的特征,而忽略了水体在其他波段上的特征。此外,利用单波段阈值法不能很好地区分山区阴影与水体,影响了整体的识别精度。基于MapReduce的水体识别模型,5种水体指数提取精度都在90%以上,这表明了本文提出的模型具有较高的识别精度。 3.3.2实验二可扩展性和伸缩性测试与分析 为了验证模型的可扩展性和伸缩性,通过控制计算节点个数和数据量进行以下实验。选取渭干河流域2013年的6幅Landsat8影像,分别选取1幅、2幅、4幅、6幅影像进行水体提取实验。实验数据集D1={1,2,4,6} (单位: 幅),影像详细信息如表3所示。 表3 实验数据详细信息 由实验一可知,使用归一化差异水体指数(MNDWI)对遥感图像进行水体提取的精度最高。因此,选用归一化水体指数进行水体识别并对比识别耗费时间。图5为计算节点不同的情况下,分别对1幅、2幅、3幅、4幅遥感图像进行水体识别所耗费的时间。 图5 不同数据量下水体识别耗费时间对比 此处引入加速比作为一个评价指标。加速比是同一个任务在单节点上运行时间与在多个相同节点构成的并行系统上运行时间的比率,用来衡量并行系统或程序并行化的性能和效果。加速比的计算公式如下: (5) 式中,Sp是加速比,T1是单节点下的运行时间,Tp是在有p个节点构成的并行系统中下运行时间。图6为不同数据量下并行加速比与计算节点的关系。 图6 计算节点数与加速比对应关系 从图5、图6我们可以看出:(1) 当数据量一定时,随着计算节点的线性增加,水体识别的时间线性降低。随着计算节点的增加,水体提取的加速比呈一定比例增加。当计算节点个数为2时,平均加速比为1.918;计算节点个数为3时,平均加速比为2.654;计算节点个数为4时,平均加速比为3.936。由此验证了基于分布式计算的水体识别模型具有稳定的可扩展性,可以满足不同规模的大型计算问题。(2) 随着数据量的线性增长,水体识别时间基本呈线性增长。这就验证了提出模型的可伸缩性,可以适应大规模数据量的遥感影像水体识别。 4结语 通过引入分布式并行计算的思想,结合水体识别理论与技术方法,提出基于分布式计算的水体识别模型,以渭干河-库车河三角洲地区为例进行实验分析。实验结果表明,基于分布式计算的水体识别模型具有较高的识别精度,能够快速识别水体信息,并具有稳定的可扩展性和伸缩性。下一步的研究工作主要是进一步完善基于分布式计算的水体识别模型,考虑水利设施(包括大坝、水库、水电站)等信息的提取策略。 参考文献 [1]LuoJC,ShengYW,ShenZF,etal.Waterinformationautomaticextractionbasedonmulti-resolutionremotesensingimageusingstepiterativemethod[J].JournalofRemoteSensing,2010,41(6):144-151. [2]DingF.Studyoninformationextractionofwaterbodywithanewwaterindex(NWI)[J].ScienceofSurveyingandMapping,2009,34(4):155-157. [3] 徐斌,杨秀春,陶伟国,等.中国草地产草量遥感监测田[J].生态学报,2007,27(2):405-413. [4] 李昌凌,李文军.基于NDV1的锡盟苏尼特旗地表植被生物量的趋势分析和空间格局[J].干旱区资源与环境,2010,24(3):147-152. [5] 陈国良,孙广中,徐云,等.并行计算的一体化研究现状与发展趋势[J].科学通报,2009,54(8):1043-1049. [6] 苏光大.图像并行处理技术[M].北京:清华大学出版社,2002. [7]DeanJ,GhemawatS.MapReduece:Simpledataprocessingonlargeclusters[J].CommunicationsoftheACM,2005,51(1):107-113. [8]LammelR.Google’sMapreduceProgrammingModel-Revisited[M].Redmom,USA:DataProgrammabilityTeamMicrosoftCrop,2007. [9] 付天新,刘正军,闫浩文.基于MapReduce模型的生物量遥感并行反演方法研究[J].干旱区资源与环境,2013,27(1):2-3. [10] 陈华芳,王金亮,陈忠,等.山地高原地区TM影像水体信息提取方法比较-以香格里拉县部分地区为例[J].遥感技术与应用,2009,19(6):479-484. [11] 周成虎,骆剑承,杨晓梅,等.遥感影像地学理解与分析[M].北京:科学出版社,2001. [12]McFeetersSK.TheUseofNormalizedDifferenceWaterIndex(NDWI)intheDelineationofOpenWaterFeatures[J].InternationalJournalofRemoteSensing,1996,17(7):1425-1432. [13] 徐涵秋.利用改进的归一化差异水体指数(MNDWI)提取水体信息的研究[J].遥感学报,2005,9(5):589-595. ON IDENTIFYING WATER BODY IN REMOTE SENSING IMAGES BASEDONDISTRIBUTEDCOMPUTING Yang LiuTian Shengwei (School of Software,Xinjiang University,Urumqi 830046,Xinjiang,China) AbstractIn order to improve the speed of remote sensing data processing and solve data-intensive and computing-intensive problems in remote sensing information extraction, we introduced the parallel computing idea to remote sensing image processing and information extraction, and built a Landsat ETM+images-based water body extraction model for distributed remote sensing image. We took Weigan River basin as the study region, used several methods such as single-band threshold, relationship between multiband spectra and water index, etc. to conduct experiments of automatic water body extraction. Experimental results demonstrated that the model has higher identification accuracy, it can identify water body information quickly, and has stable scalability and stretchability as well. KeywordsBig dataRemote sensingWater body identificationParallel computing 收稿日期:2014-11-26。国家自然科学基金项目(61363083,4126 1090);新疆研究生科研创新项目(XJGRI2014033)。杨柳,硕士生,主研领域:云计算,大数据。田生伟,教授。 中图分类号TP391TP751 文献标识码A DOI:10.3969/j.issn.1000-386x.2016.06.034