基于词法分析和XML技术的多媒体试题批量导入研究
2016-07-19符云清
俞 婷 符云清
(重庆大学软件学院 重庆 401331)
基于词法分析和XML技术的多媒体试题批量导入研究
俞婷符云清
(重庆大学软件学院重庆 401331)
摘要试题导入是当前在线教育面临的一个难点问题。传统的在线试题导入效率较低而且出错率较高。目前一些基于词法、语法分析的试题导入研究侧重于纯文本试题的导入。通过对联通内训平台试题库的分析发现包含图片、视频的多媒体试题出现较为频繁。为了解决这一问题,提出一种基于词法分析和XML技术的多媒体试题批量导入方法。该方法首先对试卷进行预处理得到标准的试卷模型,然后通过试题解析得到HTML格式的试卷并根据HTML的标签信息分解出题目与答案,最后将“题目-答案”以XML格式存入数据库中并完成试题导入。该方法成功运用到联通内训平台,高效地解决了多媒体试题导入的问题。相比于现有的试题导入方法,该试题导入方法支持的试题类型更多,导入效率和准确率也有所提高。
关键词试题导入词法分析JACOB
0引言
随着在线教育的进一步发展,试题库中的题目越来越多。自动化的试题导入能够大大减小试题导入人员的工作负担,同时提高试题准确率。李静梅[1]利用Microsoft公司提供的VBA技术来处理word文档中试题的导入问题。这种处理方式效率较高,处理过程也相对简单,但是在试题文档的类型上存在着明显的局限性。王甲[2]利用词法、语法分析技术逐个字符读入试题,然后对这些字符进行归类和封装,最后通过构建语法树来验证和还原试题。这种方法在一定程度上解决了试题导入过程中数据的安全性、试题文档类型等问题,但是这类方法没有很好地考虑到多媒体试题的导入问题。
当前许多题库系统仅包含纯文本格式的试题,在题干或试题选项部分都不能支持复杂的公式、特殊符号以及图片、音视频等多媒体内容,从而限制了题库系统的应用和推广;且大多试题库系统仅支持人工录入,其不仅效率低下,还容易在输入过程中出错。在这种背景下,若能将这些试卷以多媒体试题形式批量导入到题库系统中,则将大大提高题库系统建设的效率,实现题库资源在更大范围内的共享和重用,从而为各类教育培育的教学评价奠定坚实基础。
本文在王甲等人工作的基础上研究了传统的分词技术[3]、词法分析技术[4],提出了基于词法分析[5]和XML技术[6]的多媒试题批量导入方法。首先通过词法分析为试题打上唯一标识并得到试题的题干及选项部分,然后以XML形式存储到数据库中,同时提供对多媒体试题的支持。作者在中国联通重庆分公司员工内训平台中题库及考试模块中对提出的方法予以了具体实现,并验证了该方法的可行性和高效性。
1相关研究
1.1词法分析
词是中文中最小的能够独立活动的有意义的语言成分,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记。因此,中文词语分析[7]是信息处理的基础和关键。其中分词的方法又是多种多样的,包括基于字符串匹配的分词方法[8]、基于统计的分词方法[9]、基于语法规则的分词方法等。在目前试题导入的研究中,词法分析被应用到试卷的预处理中。一些研究者利用词法分析技术把试卷以词为单位进行分解[2,10],然后导入试题库。本文综合考虑试卷导入的实际情况和词法分析特点,将传统的词扩大到‘试题’,以试题为单位进行分‘词’。
1.2基于单词流的试题导入
一些试题导入方法将试题分解为一组词,然后将一个个词导入系统,出题时对这些词进行重新组装。王甲[2]通过词法分析将试题文本打断为孤立的单词,进而将各个单词进行归类和封装,然后使用预定义的语法树对封装后的单词对象进行匹配和验证。同时,单词表对整个过程涉及到的临时数据进行存储和必要支持。潘旭[10]把试卷内容作为源代码来处理,提出了一种基于ANTLR的试题导入方法。潘旭通过对词法、语法的分析生成试卷模型并完成试题导入工作。
这类试题导入方法需要对试题进行打乱处理,然后重新组装。一个试题库中需要导入的试题可能数量极大,如果都要进行试题打乱和重新组装需要耗费大量时间。此外,王甲在文中也提到试题打乱组装的过程中可能会造成元素重复、元素缺失等错误。
1.3基于纯文本文档的试题导入
在一些课程平台系统中需要导入以TXT格式或者PDF格式的培训试题[11]。导入文本文件时首先是需要选择存储试题的文档,培训试题的类别,培训内容所属的章节,输入培训试题的数量。这样,通过后台一系列的操作,培训问题就会被导入到数据库中,避免了繁琐的手动打字的问题。在进行试题导入的过程中,首先要进行培训试题格式的预处理,比如TXT格式的文件,因为是纯文本文件,所以只需要使用输入/输出流读取文本内容。比如DOC格式的文本,需要导入专门分析用户DOC文档的POI包。通过调用POI包的方法,则可以更容易地分析其文档中的内容,将题目解析过后存入数据库中。李静梅[1]在文中采用了Microsoft提供的文档解析包来处理word文档。在此类导入方法中,虽然实现方便,但对试卷文档类型要求比较苛刻,且不支持含有图片、符号等的多媒体试题导入。
2多媒体试题导入模型的建立
以上提及了多种试题导入的方法。在试题导入的过程中,基于单词流的试题导入方法效率不高。特别是在出题过程中,试题重组将会花费较大的时间,而且重组过程中会带来元素重复、元素缺失等问题。基于纯文本文档的试题导入在方法实现上和导入效率上有所提高,但是并不能很好地支持含有多媒体类型的试题导入。试题导入的主要目的是将各种类型的试题快速存入数据库中,在出题时能够快速地从题库中提取出所需要的试题。如果将试题全部逐字逐句进行词法分析,不但效率非常低下,而且词语与词语之间将会出现非常大的歧义。同时,在实际的应用中,我们不需要对每一道试题中的每一个词都进行单独的分析,我们关注的是一道试题。
本文在分析了基于单词流和基于纯文本文档的试题导入方法的优缺点之后,提出了一种基于词法分析和XML技术的多媒体试题导入模型。该模型的构建主要分为三步(详见图1所示)。

图1 试题导入模型
该方法首先构建试卷模型,对试卷解析,将其转化成HTML格式文档,然后再以XML形式存储到数据库中。通过将试卷文档解析成HTML,不仅避免了分词所带来的极大的歧义问题,也提高了试题导入的效率,试题存储不再以词为单位,而是以题为单位。下面对试卷导入模型进行详细的分析。
2.1试卷模型构建
在进行试题导入前,需要对试题做一个统一的规定,以减小在导入过程中的出错率。一份试卷包含多种类型的试题、试题数量以及试题答案。为了更好地描述,文中用E表示试卷,Q表示试题,N表示试题数量,A表示试题答案。那么一份试卷可以用式(1)进行简单表示。
E=Q∪N∪A
(1)
试卷中试题类型多样,文中用Qi来分别表示单选题、多选题、判断题、简答题、填空题,其中i为1、2、3、4、5。对五类题型进行分析可以发现一定的规律。Q1、Q2由题干和选项两部分组成,而Q3、Q4、Q5则只有题干一个部分。故在试题标注和导入时需要特别注意Q1、Q2的完整性。
同样的,一份试卷中总的试题数量N是试卷中各个类型试题总量之和,我们定义了如下试题总量公式。
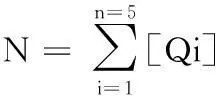
(2)
其中[Qi]为一份试卷中第i类题型对应的试题数目。N能够反应出一份试卷的容量,在系统出题时可以用来评定一份卷子的难度系数。
在确定了一份试卷的组成内容和题量后一份试卷的总体结构构件完成。本文提出的试卷导入方法以试题为单位,故在试卷模型构建过程中需对每一道试题进行标注。
定义标注的试题格式为:
$Qi-Q-n$
(3)
其中Qi为题目类型,Q表示题目,n(n≤[Qi])表示题目序号。例如$Q1-Q-30$表示第30道单选题。判断题和简答题的标注规定与单选题和多选题类似。如果文档中含有答案,则将答案和前面的题目相对应起来,在试卷解析和分解完成后以结构化形式存入到数据库中。定义答案的标注格式为:
$Qi-A-n$
(4)
比如$Q1-A-30$表示的是题目序号为30的单项选择题答案。
2.2试卷解析
用户选择不同类型的试卷文档并导入系统后,系统需要对这些文档进行解析。以word文档为例,图2为联通五级认证试卷中的部分试题,试题由单选题、多选题、判断题和简答题四部分构成。

图2 联通等级认证试题(加入标注前)
在试卷解析步骤中最为重要的是试题题型和试题数量的解析。因为在试题导入的过程中要保证试题答案的导入,而试题类型和试题数量是保证试题和答案对应的关键。为了更好地区分试题题型、提取试题数量。本文在试卷解析的过程中对每道试题进行标注。例如,在选择题题型前面的标注:“$Q[1-5]{1}-Q-[ ]+$”。其中Q表示题型,n表示该类题型数量。图3为加入标注后的试卷(详见2.1试卷模型构建)。

图3 联通等级认证试卷(加入标注后)
在试卷类型前面加入标注可以认为是在原始word文档中加入相应的html标签,这是后面word文档解析成HTML文档的前提。
为了更好地将试题以题为单位存入数据库中,以数据流形式读取word文档可能效率不是很高,这里将word文档解析成HTML文档。这是因为HTML文档结构化信息鲜明,方便了试题的提取。在将试卷解析成HTML文档的过程中,主要使用的是JACOB(JAVA-COMBridege)组件[12]。用户通过JACOB来调用本地COM自动化组件。图4就是JACOB调用本地COM自动化组件的详细机制[13]。为了提高下一阶段中试卷分解的效率,解析生成的HTML文档会先缓存到系统服务器中,在试题导入数据库后删除。
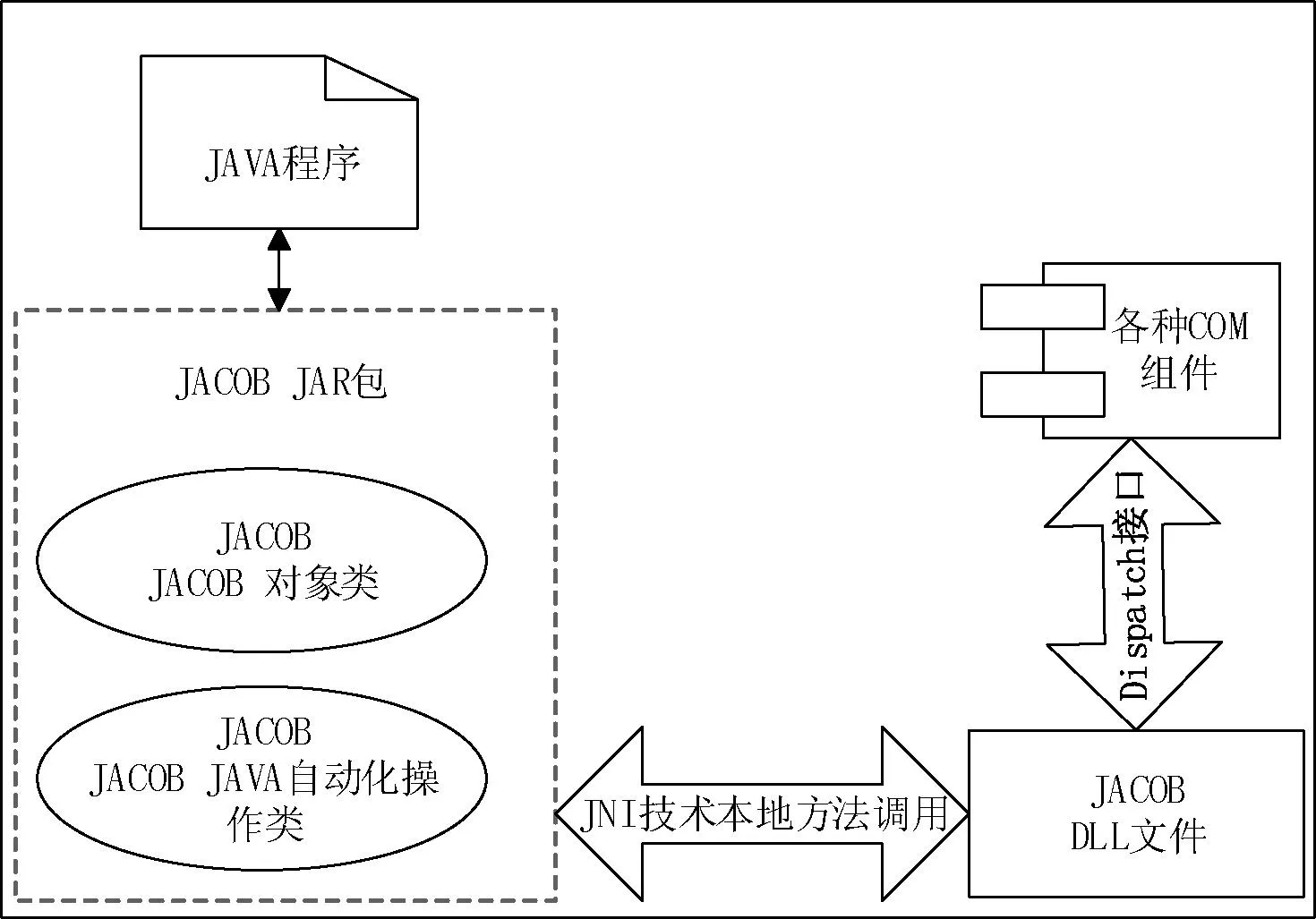
图4 JACOB调用COM工作原理图
在进行试题解析的过程中,除了处理纯文本试题,还需要处理包括图片、特殊公式、符号、音频、视频等多媒体试题。例如,在解析含有图片的试题过程中,试卷解析器将试卷中的文本试题转换成HTML格式,同时将图片上传至资源服务器,最后将图片在资源服务器中的地址写入到原来的图片的位置。若试题中含有一些特殊的符号和公式,试卷解析器将这些符号和公式转换为特定的编码格式,最后将原来的符号和公式替换为特定的编码格式。
如下为试卷解析部分的伪码:
BEGIN(算法开始)
IMPORT:试卷
EXPORT:HTML文档
IFType=Text则TEXT→HTML
IFType=Multimedia则Multimedia→MediaService,ChangeSRC
……
HTML→ScratchFile
END(算法结束)
2.3试卷分解
在解析成HTML后,试卷以HTML形式表示。若将试卷以HTML格式存入数据库,则在出题时不能重新组题。为了解决这一问题,对试卷解析完成后的HTML格式的试卷以试题为单位进行分解,得到题目和答案。试卷分解的主要依据是试卷解析阶段中的标签信息。试卷分解完成后的试题及对应答案被整合封装成XML格式,最后存入数据库。
如下为试卷分解部分的伪码:
BEGIN(算法开始)
IMPORT:HTML文档
EXPORT:题目-答案
IFcurrentType=SingleAnswer、Multipleanswer,则(SingleAnswer||Multipleanswer) →Tmain&&Toption&&SetType
IFcurrentType=ShortAnswer、TrueorFalse则(ShortAnswer||TrueorFalse) →Key&&SetType
IFcurrentType=Multimedia则GetPath&&SetType
……
Questions→Database
END(算法结束)
3实验与结果
在以往的试题导入研究中较少考虑到多媒体试题,一般观念认为多媒体试题导入将会消耗巨额的时间。为了更好地比较包含多媒体试题的试卷和纯文本试卷导入效率。本文首先验证了基于题的试题导入效率与试题类型的关系。取100份word文档的联通模拟试卷,将每一份完整试卷拆分成单选题、多选题、判断题、简答题四个部分分别导入数据库,并统计各类题型导入消耗的时间(每类题型总数量相同)。结果表明试题导入的效率并不依赖于试题类型。然后分别取出100份包含多媒体试题和不包含多媒体试题的完整试卷,统计两类试卷导入的准确率和时间。实验结果如图5所示。

图5 多媒体试卷与纯文本试卷导入效率、准确率对比图
上述实验结果表明基于词法分析和XML技术的试题导入方法在处理多媒体试题时所消耗的时间与处理纯文本试题所消耗的时间差距不大。
为了更好地分析和对比,本文实现了基于单词流、基于纯文本的试题导入方法,同时还记录了人工试题导入的时间和出错率。实验数据为100份word文档的联通模拟试卷(不包含多媒体试题)。其中每份试卷共含有40个题目:10个单选题,10个多选题,5个判断题,10个填空题,5个简答题。实验结果如图6、图7所示。

图6 耗费时间对比图

图7 出错率对比图
通过图6可以发现本文提出的多媒体试题导入方法相比于手工的试题导入和基于单词流的试题导入方法在处理相同数量的试题时具有较大的优势,两者消耗的时间都比较少。通过对比四种试题导入方法的出错率(见图7所示),基于纯文本试题导入和本文提出的基于词法分析和XML技术的试题导入方法出错率明显低于基于手工的试题导入和基于单词流的试题导入方法。虽然基于纯文本的试题导入方法在时间消耗和出错率上与本文提出的方法持平,但是本文提出的多媒体试题导入方法在试题的类型上却有着较大的优势。
此外,本文提出的基于词法分析和XML技术的多媒体试题批量导入方法在中国联通重庆分公司员工内训平台中予以了具体实现,从实际中验证了该方法的可行性和高效性。
4结语
本文阐述了基于词法分析和XML技术的多媒体试题批量导入方法,并通过该方法完成文本格式及其他媒体格式的试题导入工作。在试卷模型的构建过程中,采用题为单位的试卷导入思想,规避了以词为单位的试题导入带来的低效率问题,符合实际的试题导入应用要求。试卷解析和分解阶段通过对试题的标注并结合JACOB技术将文本文档解析成HTML文档,组装试题-答案存入数据库。该试题方法目前成功应用到联通内部培训平台,实现了高效导入试题、高效重组试题的目标,得到了联通上下员工的认可。同时,通过与当前的存在的试题导入方法对比也可以发现本文提出的多媒体试题导入方法在批量处理和效率上有一定的优势。
参考文献
[1] 李静梅,冉祥金,姚成浪,等.基于PB与VBA的试题导入方法研究[J].应用科技,2006,33(4):51-53.
[2] 王甲,康慕宁.基于词法、语法分析的试题导入系统的研究[J].微型机与应用,2010,29(4):65-67,70.
[3] 叶继平,张桂珠.中文分词词典结构的研究与改进[J].计算机工程与应用,2012,48(23):139-142.
[4] 刘群,张华平,俞鸿魁,等.基于层叠隐马模型的汉语词法分析[J].计算机研究与发展,2004,41(8):1421-1429.
[5] 黄小斌,余悦蒙.一种词法分析与字标注分词结合的方法[J].电脑知识与技术,2012,8(8):1814-1817.
[6]WangX.XMLintheapplicationofnetworktestsystem[C]//ElectricalandControlEngineering:Yichang,2011:937-940.
[7] 吴栋,滕育平.中文信息检索引擎中的分词与检索技术[J].计算机应用,2004,24(7):128-131.
[8]LiuL,WangC,BaiL,etal.Studyofontologytechnologyinfieldwordsegmentationsystemofdigitallibrary[C]//Shanghai,China:ComputerSupportedCooperativeWorkinDesign,2010:223-227.
[9]LiuH,WangZ.Post-processingmethodofunknownwordsegmentationbasedonstatisticofwordfrequency[C]//InformationScienceandEngineering,2010:1386-1389.
[10] 潘旭,康慕宁.基于ANTLR的试卷识别和导入系统的研究[J].电子设计工程,2011,19(7):45-49.
[11]LiY,ZhuL,WangX.Designandimplementationofanonlineself-trainingsystemfortheComputerSystemPlatformcourse[C]//Harbin:AdvancedComputationalIntelligence(ICACI),2012:194-197.
[12] 车晓波,闰旭琴,刘晓建.基于JACOB的WORD文档操作技术[J].科技创新导报,2013(4):29-30.
[13] 李瑞,李永刚.JAVA中基于JACOB的COM组件调用研究[J].微计算机信息,2007,23(15):168-170.
STUDY ON BATCH MULTIMEDIA QUESTIONS IMPORTING BASED ONLEXICALANALYSISANDXMLTECHNOLOGY
Yu TingFu Yunqing
(College of Software Engineering,Chongqing University,Chongqing 401331,China)
AbstractQuestion importing is a nodus facing by current online education. Traditional online question importing is characterised by low efficiency and high error ratio. At present, some researches on question importing based on lexical and syntax analysis focus on the plain text-oriented questions importing. However, through analysing the item bank of China Unicom internal training platform, it is found that the multimedia questions including pictures and videos appear frequently. In order to address this problem, in the paper we put forward a batch importing method for multimedia questions, it is based on lexical analysis and XML technology. First, the method pre-treatments the paper to get a standard test paper model. Secondly, by questions analysing it gets a test paper in HTML format and disassembles the questions and answers according to HTML tag information. Finally, it stores the “questions-answers” to database in XML format and completes the question importing. This method has been successfully applied to China Unicom internal training platform, which efficiently solves the problem of multimedia questions importing. Compared with existing questions importing methods, this one supports more question types and has higher importing efficiency and accuracy.
KeywordsQuestions importingLexical analysisJACOB
收稿日期:2014-12-31。俞婷,硕士,主研领域:E-Learning,计算机网络。符云清,教授。
中图分类号TP393
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.033
