支持技术创新的专利检索与分析
2016-07-18刘斌冯岭王飞彭智勇
刘斌,冯岭,王飞,彭智勇
支持技术创新的专利检索与分析
刘斌1,2,冯岭1,王飞1,彭智勇1,2
(1. 武汉大学计算机学院,湖北武汉 430072;2. 武汉大学软件工程国家重点实验室,湖北武汉 430072)
介绍了目前专利检索和分析的主要研究工作,包括专利的可检索性、技术现状检索和相关性检索方法等,以及专利地图分析、新颖度分析和PatentDom专利分析框架等分析方法。最后基于深度学习的思想,讨论了新一代的支持技术创新的专利检索方法、专利论文检索方法以及专利趋势分析方法。
专利;专利检索;专利分析;深度学习
1 引言
近年来,科学技术日新月异,经济全球化趋势增强,产业结构调整步伐加快,国际竞争日趋激烈[1~3]。知识或智力资源(包括专著、专利、商标、科技论文、技术报告以及科学实验数据等)的占有、配置、生产和运用已成为经济发展的重要依托,技术知识的重要性日益凸现。以知识为基础的产业在国内经济所占的比重不断提高,知识产权已成为国家之间、企业之间竞争的焦点。
专利是最典型的知识产权,也是数量最大的、增长速度最快的技术信息来源。美国专利申请始于1790年,中国则开始于1985年。表1反映了美国和中国的专利申请量的增长速度[1~3]。

表1 专利发展趋势
截至2014年底中国有效发明专利拥有量共计66.3万件,全世界范围内的专利数量已经达到7 300万件。根据世界知识产权组织的统计,专利文献中包含了世界上95%的研发成果。如果能有效地利用专利信息,不仅可以缩短60%的研发时间,还能节省40%的研发经费[4, 5]。
专利蕴含着巨大的价值,吸引许多研究者的注意。2002年开始,日本国立情报学研究所在其举办的NTCIR会议设立专门的专利检索专题讨论会,并发布了若干专利测试数据集(如表2所示),其中,NTCIR-3数据集包含跨语言检索任务。NTCIR-4,5,6数据集包含技术现状检索,专利分类等任务[6~8]。
CLEF(cross language evaluation forum)是面向欧洲语言的信息检索开放评测平台,从2009年开始设立专门针对专利检索的主题研讨会CLEF-IP,同时提供大约130万个英文专利,供研究者下载测试。
此外,一些重要的国际会议如CIKM、SIGIR等都设置了相应的专利Workshop,供研究人员进行交流。
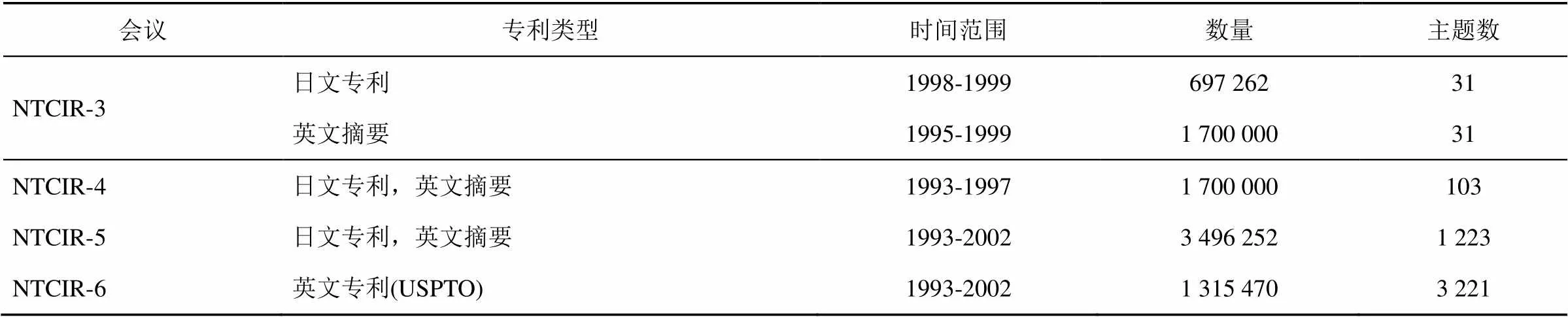
表2 NTCIR数据集
专利研究目前可以分为3类:1) 专利检索;2)对专利文本进行各种深入分析;3) 与专利相关的其他研究,如推荐合作者[9]、专利续费等[10]。
2 专利检索相关评价标准与检索方法
2.1 专利检索评价标准
专利检索作为信息检索的一个分支,可以采用准确率和召回率对算法进行比较。但是准确率和召回率互相影响,理想情况下两者都要高[11]。一般情况下准确率高时,召回率就低;而召回率高时,准确率就低。专利检索侧重于召回率,为了更好地反映算法的全局性能,Magdy等[12]经过分析,设计专利检索评价值(PRES, patent retrieval evaluation score)。

其中,r是第个相关专利文档的排名,是专利文献集合中相关专利的数目,max是用户最大检索的专利数。算法的值越高,则召回率越高,且相关的文档排名越靠前。
专利检索按照检索目的可分为:可专利性检索(patentability search)也叫新颖性检索(novelty search)、专利技术现状检索(prior art search)、相关性检索等。专利的检索和一般的科技文献检索相比,有其特殊性,主要体现在以下4个方面。
1) 撰写方式的特殊性。论文撰写时,作者一般采用大家熟悉的描述方式,这样可以让读者更容易理解作者所要表达的含义。但是专利撰写时,申请人为了扩大自己所申请专利的保护范围和提高专利授权的可能性,往往使用一些模糊的术语和表达,甚至创造新的术语。
2) 对于专利检索,召回率比查准率更重要,因为如果漏检一条重要的专利,会给企业带来重大的损失。
3) 专利数据格式复杂。专利包含了分类号、权利声明等丰富信息。其中,专利分类号用来对专利文献进行分类,充分利用专利分类号等其他信息,可以使检索结果更准确。
4) 检索条件长度不同。对于专利申请人和专利审查员,他们更希望提供全文检索的功能,因此专利检索文本包含几百个关键字。而目前现有的一些检索比如即席检索(ad hoc search)、Web检索和文献检索的检索文本长度相对比较短,例如Google搜索的最佳长度为155个英文字符。
2.2 可专利性检索
因为专利检索的文本长度很大,所以缩短检索文本是一个简单可行的方法[13~18]。最常用的方法就是对专利文本各个词的频率(TF, term frequency)进行统计,选择Top-高频词来代替原有查询进行检索。信息检索已有研究结果表明采用高频词来进行检索并不能得到很好的检索效果,因此提出了IDF(inverse document frequency)指数,并利用TF-IDF来计算每一个词的权重。然而,专利撰写者往往为了规避已有的技术,会创造一些新词,它们的TF-IDF值很高[11]。所以采用TF-IDF方法仅能检索到少量的相关专利。Hideo等[13]针对跨库检索提出了一种词过滤的技术,每个词被赋予一个过滤权重TDV(term distillation value)。
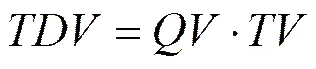
其中,表示词在查询条件中的重要性,表示词在目标语料库中的重要性。假设为词在查询条件中出现的概率,为查询词在目标集合中出现的概率。对于一个词,概率可以利用标题()和摘要(a)中词的频率进行计算,计算方法如式(3)所示。
或(3)
其中,n是专利标题中包含该词的专利数量,n代表专利摘要中包含该词的专利数量,N代表集合中的专利总数量。
概率利用目标集合()和整个专利文档的词()的分布进行计算,计算方法如下
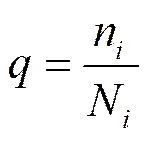
其中,n是目标集合中包含该词的文章数,N是目标集合总的文章数,n是专利中包含该词的专利数量,N代表NTCIR-3中专利数量。
对于一个检索词,论文依据不同的规则设计了9种计算的方法,以及5种计算的方法。采用NTCIR-3的数据作为测试集,该算法效果排名第1(如表3所示),表明该方法可以有效地进行跨库检索。表3中2的含义是一个词的值等于该词的频率。0含义是1,即的值仅依赖于。,和是预先定义好的常量,P@10为前10个专利准确率。

表3 NTCIR-3数据集测试结果
审查员(或者发明人)通过输入待审核专利的权利声明(claim),算法自动抽取相关的关键词进行检索,返回相应的文档,进而判断权利范围要求的合法性。从表3中可以看出,算法的平均准确率()小于0.3,在排名前10的专利准确率不超过0.4。这是因为专利中存在大量语义含混不清的词,导致词过滤技术方法面临较大的挑战。
2.3 技术现状检索
技术现状检索就是给定一个技术背景(如一篇专利),找出与其相关的专利。技术现状检索可以帮助公司掌握最新相关领域的发展现状,辅助公司确定新的开发领域,合理分配宝贵的资源。检索条件的抽取是技术现状检索成功的关键,由于专利检索更注重召回率,采用查询扩展是比较有效的方法,所以寻找有效的扩展词就成为研究的重点。
2.3.1 第三方知识库的扩展方法
专利现状查询面临2个挑战:1)由于输入为一组关键词,而各个关键词可能属于不同的主题,因此无法表达一个准确的查询需求。2)查询中常常存在歧义词,如“苹果”可能表示苹果公司,也可能表示水果。信息检索已有研究表明,借助于维基百科这样的公共知识库可以提高检索的准确率和召回率。IPC分类是国际通用的专利分类方法,它描述该类专利的特点、功能,因此可以把IPC分类描述看成是一种知识库,借助于IPC可以用来进行语义消歧,提高专利检索的准确率和召回率。例如,当“苹果”出现在电子分类的IPC下时,它通常指的是苹果公司,当出现在农业和林业等分类下时,苹果可以看成是水果[19, 20]。
Mahdab[17]利用IPC描述作为扩展词典,提出了一种基于位置近邻的查询扩展方法,并对检索结果进行重排序,从而提高检索的准确率和召回率,算法步骤如下。
1) 对于被检索的专利,使用第一条权利声明代替整个专利作为查询条件。
2) 提取IPC文本中专利特征的相关性描述,去除专利领域的停用词,建立候选扩展词表。
3) 对专利库中的每一条专利,计算扩展词和查询词的相关度,选择Top-个相关度最高的词作为查询扩展词。扩展词和查询条件相关度计算方法如下

其中,(|t)是查询词t在查询条件中出现的概率;是查询词在专利文档中的位置。(|t)可以采用最常见的词频统计的方法计算。(|)用来计算专利文档中第个位置是扩展词与第个位置是查询词的相关性概率。它的计算可以采用位置核函数来进行计算,如高斯距离核函数、拉普拉斯距离核函数等。该公式的含义是查询词在查询条件中出现的概率越大,扩展候选词离查询词在文中位置越近,它们的关系就越紧密,则该权重越大。
4) 利用查询扩展词进行查询,并对查询结果利用式(6)重新计算专利相关度。
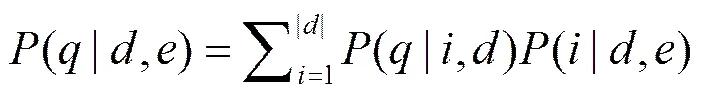
其中,代表专利文档中词的总数,(|,)表示第个词是扩展词的概率。如果第个词是扩展词,那么它的概率是扩展词所有出现位置总数的倒数,否则概率为零。
以CLEF2010作为实验数据,该方法效果如表4所示,和其他方法相比,检索的准确率有了较大的提高(8%)。主要原因是专利申请人在撰写专利时都要参考和使用IPC的描述信息,因此利用IPC作为扩展词可以最大限度地把扩展词的歧义降到最低;此外,计算相关度时将词的分布和位置结合起来。

表4 IPC扩展检索对比
2.3.2 基于主题的检索
专利作为一种文档,必然包含一定的主题。判断2个文档相似性的常规方法是通过统计2个文档中共同出现的单词数,这种方法没有考虑到文字背后的语义关联,可能存在2个文档共同出现的单词很少,但2个文档是相似的情况。LDA模型可以提高检索的准确性,因此在信息检索和自然语言处理中得到了广泛的应用。
Krestel等[23]将LDA模型应用到专利推荐,提出了基于潜在主题的专利推荐方法。根据专利的特点,将专利分成5个部分:题目(title)、摘要(abstract)、权利声明(claims)、概要(summary)和具体实施(details),利用DMR(dirichlet multinomial regression)对专利和查询条件进行计算,选择相似度高的专利进行推荐,具体方法如下。
1) 对于一个给定的专利,利用TF-IDF从专利集合中选取Top-个内容相关的专利,生成初始候选集。
2) 对于Top-个专利,分析专利引用部分,如果该专利引用了其他专利,将这些被引专利加入到候选集合中。
3) 对候选集中的每一个专利,按照下面的方法计算值。
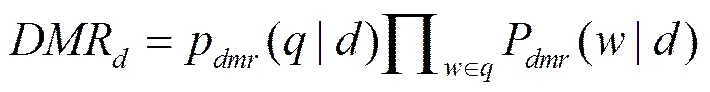
(8)
(9)
式(9)中是专利包含的主题数,取值为专利总数的开方()。N是每一个部分词的总数,N是专利包含的总词数。和是词和主题的后验概率估计,可以通过Gipps抽样的方法进行计算。
该方法随机选择了2012年12月3日发布的100个专利,对每一个专利选择500个相似度最大的专利,加上被引专利得到一个包含27 500个专利的集合。表5是将该方法和BM25、语言模型(LM)进行比较的结果。
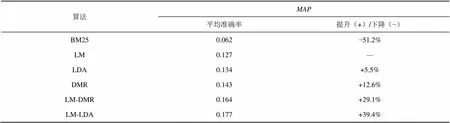
表5 基于LDA的专利检索对比
LM主要考虑词的分布,LM-DMR和LM-LDA方法是用DMR、LDA对语言模型进行扩展。以LM为基准,可以发现利用主题可以提高平均准确率,将语言模型和主题模型进一步结合使检索结果更精确,这也符合一般的规律。
2.3.3 基于引用关系的查询扩展方法
专利申请书还包含了丰富的引用信息。Mahdabi[24]对专利文档进行实验观察,发现2个专利之间的相关性不仅与两者的文本相似度相关,而且很大程度上与两者之间的引用关系相关,进而提出基于时间感知的加权PageRank算法AQE-TPR,具体步骤如下。
1) 查询专利集合,得到Top-个文本相似度高的专利作为根集合,然后找出所有引用该Top-个专利以及Top-所引用的专利,根据引用关系构建专利引用网络。
2) 对其中每一个节点按照式(10)计算其初始概率。是专利授权时间,是时间间隔因子,专利授权越早和查询条件相关的可能性越低。
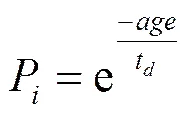
如果专利引用专利,那么和之间就存在一条边,边的权值对应于专利和之间的关联程度。AQE-TPR综合考虑专利和的IPC分类、内容相似度,发布时间间隔、共同发明人、共同的专利权人。当组合权重大于0.5时,a=1,反之a=0。这样就构成一个专利引用网络cit,利用PageRank算法计算每一个专利的值。
3) 计算每一个词的权重,方法如下
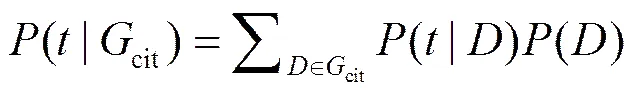
其中,()对应于专利的PageRank值,()是该词在专利中出现的概率。如果一个专利的PageRank值越大,那么该专利处于核心地位,如果一个词在很多专利中出现,那么该词非常重要。
4) 综合考虑查询条件orig和专利引用网络,利用式(12)计算扩展词的概率,选择Top-个概率最高的词作为扩展词,是预先定义的常数。
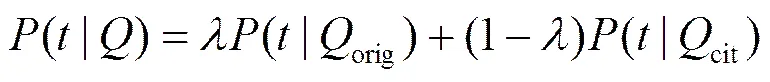
以CLEF-IP2011的数据为实验对象,比较结果如表6所示。可以发现AQE-TPR方法好于Nijm和Hyder算法,Nijm和Hyder算法在CLEF-IP 2011比赛中排名第一和第二。本方法的贡献就是通过PageRank算法综合考虑专利各个部分的信息,从而提高检索的准确率和召回率。

表6 基于引用的专利检索对比
此外还有一些方法利用查询扩展提高专利检索的召回率[25,26]。Bashi[27,28]利用词语位置计算语料库和查询条件的相关性,并选择最相关的若干文档,利用伪相关反馈进行查询扩展。Bhatia[26]将专利文献分割成大小相同的片段(snippet),并将查询条件分割成较小的句子。将查询条件和专利文献进行比较,选择相似度最大的片段,并以此返回相应的专利文献,该方法能提高查询的响应时间。较早的方法有Hironori[25]提出的利用聚类进行查询扩展,该方法将专利聚类成一个层次结构,在不同的层次上进行查询扩展以提高召回率。
2.4 相关性检索
专利相关性是指该专利和哪些专利相关。英文专利包含专利之间的引用关系。和论文的引用关系不同,专利对其他专利的引用意味着本专利的权利声明受到限制,即本专利的价值会变得更低,所以专利发明人在引用其他专利时会显得非常“小气”,这对已有的专利是非常不公的[29,30]。
Sooyoung等[29]提出了基于价值驱动的专利引用推荐方法CV-PCR。CV-PCR将专利D表示为一个五元组<T,C,V,a,R>,其中,T代表专利的文本内容,C代表专利的IPC代码,V是专利发明人,a是专利所有权人,并以此构建专利异构信息网络,如图1所示,网络中边的含义如表7所示。

表7 网络拓扑含义
对于一个给定的专利D,CV-PCR分为3步推荐相关的引用。
1) 采用常规的专利检索方法检索出若干个相关的专利,并计算专利相关度。
2) 以专利异构信息网络为基础,根据式(13)计算专利的特征值。特征包括:专利之间是否有引用关系、专利的相似度、专利主分类号、专利次分类号、专利发明人、专利权人、专利内容。
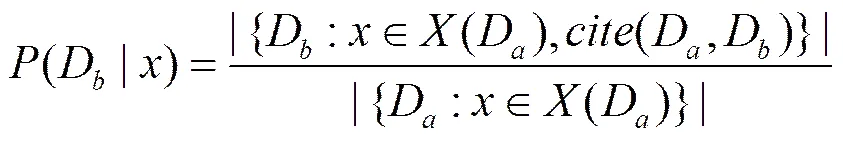
其中,分母的含义是对于专利D以及它的特征,有多少专利具备特征;分子的含义是这些专利中同时引用专利D的数量。
给定一个查询专利D,对网络中每一个专利计算所有特征值的平均值,方法如下。
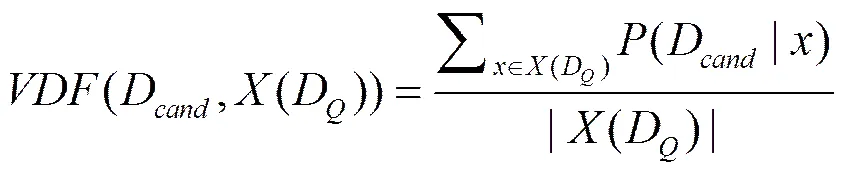
3) 对这些专利采用基于监督排序学习算法(RankSVM)进行重新排序。
CV-PCR和BL1方法和BL2方法进行了对比[19,31]。其中,BL1方法是基于排序学习的相关专利检索,BL2方法是科技论文引文推荐方法,比较结果如表8所示。通过比较可以发现该方法在推荐相关专利方面具有优势。主要原因是该方法不仅考虑了专利的内容,而且考虑了专利的其他有用信息。这进一步说明了专利检索有其特殊性,不能简单地照搬传统的信息检索方法。

表8 专利相关性检索对比
3 专利内容扩展分析方法
专利分析是对专利说明书或者专利公报中大量专利信息进行分析、加工、组合,并利用统计学的技巧和方法使这些信息转化为具有总揽全局及预测功能的竞争情报,从而为企业技术、产品及服务研发提供决策参考。常见的专利分析有:专利地图、专利价值计算、专利新颖性分析等。
3.1 专利地图
专利地图(patent map)是采用统计分析方法加以缜密及精细剖析整理制成的各种可分析解读的图表信息,具有类似地图指向功能。专利技术功效地图通常将专利分解成技术手段和技术效果2个维度,制作成矩阵或图表,横轴代表一项技术,而纵轴代表技术效果[32, 33]。
图2是对手机领域从2002年~2007年专利申请进行划分得到的专利技术功效矩阵,从中可看出,每一年手机功效的发展趋势,例如,2002年多媒体技术、智能化技术和时尚外观设计催生了手机中的照相功能。图2中包含3个技术空白区。如技术空白区2表明手机产业中外观设计发明不多,还有很大的发展空间;空白区3表明多媒体、智能化和数据连接技术在手机GPS导航中运用还不多[34, 35]。
其实,从最近几年手机的发展趋势可以看出,外观设计已经成为手机一个很重要的卖点,且目前的手机都具备GPS导航功能,导航中各种语音提示,以及近乎真实三维地图、实时路况信息以及周边相关的娱乐、餐饮、住宿等信息都已经有效地集成到导航中。所以好的专利地图可以帮助用户快速了解领域技术现状、发现技术真空,对指导专利研发有着重要作用。目前专利地图的制作仍然采用半人工半自动化的过程。例如对于专利技术/功效矩阵图,因为技术和功效通常很难区分,所以提取一篇专利中技术与功效往往是一件非常难的事情。此外,专利的数量过于庞大,且所属的领域具有很大的差异[26]。
3.2 新颖性分析
专利新颖性并没有一个公认的定义。一般可以这样理解专利的新颖性,新颖性是指发明不属于现有技术,也没有任何单位或者个人就同样的发明向专利局提出过申请,并记载在申请日以后(含申请日)公布的专利申请文件或者公告中。
Hasan等[36]提出了一个利用词新颖度计算专利新颖度的方法,并设计一个专利排序系统COA (claim originality analysis ),针对专利的价值(包括专利的新颖性和重要程度),对专利进行排序。
COA方法基于专利的总体贡献度对专利进行排序。总体贡献度是该专利所有关键短语的贡献度之和,总体贡献度越大,代表该专利所具有的价值越大,具体步骤如下。
1) 提取专利文本的关键词,COA采用自然语言处理方法中的元语法(-gram)从专利文本中提取所有短语。在关键短语识别部分,作者构建了背景词典,将出现频率大于的短语放入背景词典。通常,这些短语出现频率较高,但对专利的价值贡献较小,所以将这部分短语过滤掉。经过以上2个部分,剩下的短语被识别为关键短语。同时,COA引入了时间窗口的概念,仅考虑最近年内新出现的短语,进一步减少了关键短语的数量。
2) 计算关键短语贡献度。在COA中,关键短语的贡献度基于2个方面:关键短语的频度和短语出现的时间长度。贡献度值的大小与关键短语出现的频度成正比,与短语出现的时间长度成反比。
3) 计算专利的价值。COA设计了2种专利价值计算方法:①对每条专利的所有关键词的贡献度进行线性累加,得到该条专利的总体贡献度;②将关键短语的数量作为专利的价值。
该方法以IBM申请的专利为实验数据进行效果评估。首先采用领域专家对每一个申请的专利人工分为3类:1核心(excellent),2重要(good)和3一般(not-so-good)。作者然后采用COA方法对专利进行打分,并和人工分类的结果进行比较,比较结果如表9所示。从表中可以看出属于类1专利的COA值远远大于属于类3专利的值。

表9 COA对专利打分结果
反过来,当一个专利的COA值确定后,可以对专利进行分类。基于COA值,作者设计了一个线性分类器,分类结果如表10所示。

表10 专利分类结果
一般来说,一个专利如果被越多的专利引用,则该专利越有价值。通过实验发现,COA方法比直接利用引用关系评估专利价值准确率高。
3.3 PatentDom分析框架
PatentDom是一个基于网络的专利分析框架[37,38],基于该框架设计了3个应用:PatentLine、PatentTrace和PatentLink。PatentDom引入多视图专利图(multi- view patent graph)概念,=(,w,s,s,E,w)。其中,对应于每一个专利,每个节点都有一个权值,为该专利被引用次数的倒数,所以权值越小代表该专利越重要。图中包含2种类型的边。如果2个专利的相似度超过一定的权值,那么它们之间就存在一条无向边,相似度对应于该边的权值。如果专利之间存在引用关系或者2个专利发布的时间小于预先设定的时间间隔,那么2个节点之间存在一个有向边,每个有向边的权重为1。由于该网络包含2种类型的边,因此称为多视图专利图。
3个应用的核心是从图中选择个最重要的专利。PatentDom将此问题归结为图论中最小支配集问题,利用贪心算法,选择起决定性作用的个专利。
PatentLine主要分析核心专利随时间变化的关系。该框架将问题归结为最小代价的Steiner树,利用生成树建立核心专利之间的联系。
PatentTrace用来分析一个给定的专利和最重要的个专利之间的关系,即分析该专利最大可能和那个重要的专利之间存在关联。PatentTrace采用式(15)计算节点的权值。
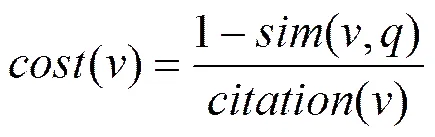
该计算方法综合了专利之间文本的相似度和引用关系。
PatentLink则利用中心子图(center-piece)分析2个专利之间潜在的联系。
通过典型案例研究表明,这3种分析方法的结果是有效的,能够分析出专利技术发展的脉络。
由于3种分析方法都依赖于核心专利的选择,表11是PatentDom方法、COA[28]方法、PageRank方法以及CorePatent方法检索结果的对比。通过对比可以看出,PatentDom在目前已有的方法中对专利价值的计算是比较好的。

表11 核心专利检索结果对比
4 基于深度学习的专利检索与分析
面对海量的专利数据,即使是技术很全面的专利工作者也往往力不从心。由于专利撰写的特点使专利检索的召回率和准确率有待进一步的提高[39]。目前,专利检索与分析主要针对专业人员,一般人很难利用,因此需要专利检索与分析更加准确和智能化,下面本文从专利检索、专利论文检索以及专利趋势分析3个方面举例说明深度学习在专利检索与分析中的应用[40,41]。
4.1 专利检索
图3是一个基于深度学习的专利检索方法,对于一个待检索的专利,从专利库中检索类似的专利1,2,…,C。该方法分为2步。
1) 特征提取,将专利语料库映射到一个维的空间。对于一个给定的专利,利用卷积神经网络(CovNN,convolutional neural network)将专利文本通过多层卷积,提取其维语义特征[41]。
一篇专利包含标题、摘要、正文(实施)和权利声明等几个部分。如果一个专利包含图表,则还有相应的关于图表的说明。专利每一部分所表达的内容不同,以及申请人在每一部分的撰写方式不同,因此本文认为每一部分存在不同的特征。所以在卷积神经网络的第一层,本文设置了4个卷积核1(),2(),3(),4(),对每一个部分进行初始特征提取。
由于专利每一部分的长度不一样,摘要部分言简意赅,实施部分详细明了,权利声明部分则居于两者之间,因此需要设计每一个卷积函数的步长,每一次卷积操作可以看成是对步长内的文本信息进行特征提取。通过第一层卷积神经网络,本文完成专利文本的原始输入,并提取了初步特征。但这些特征还比较局部,为了进一步提取全局特征并降低输入的维度,需要通过多层卷积神经网络对第一层卷积神经网络的输出进行再次卷积。在每一层卷积网络中,本文同样需要设计多个卷积核,这样可以从不同的角度提取专利文本的特征,当提取多重特征后,需要设计合适的池化(max-pooling)方法对特征进行融合。最终对于给定的专利P,本文得到它的维向量,设为V。
卷积神经网络的参数训练过程可以采用梯度下降的过程进行逐层训练。这里再引入一个相似度函数使提取的特征是有效的。由于提取的是专利的语义特征,本文采用传统余弦相似度对2个专利进行相似度计算。如果专利P和P相似,P和P不相似,那么(V,V)>>(V,V)。如果不等式不成立,那么卷积网络提取的特征是有偏差的,这样本文利用相似度作为目标函数去优化卷积神经网络的卷积核。
2) 利用排序学习的方法,对检索到的专利进行排序。这里排序学习考虑的因素有专利的语义相似度、专利发布的时间、专利的法律状态、专利之间的引用关系等。专利的语义相似度采用余弦相似度进行计算。假设专利P和P的发布时间分别是(P)和(P),那么专利之间相对价值采用式(16)计算。其含义是优先推荐最近的专利。
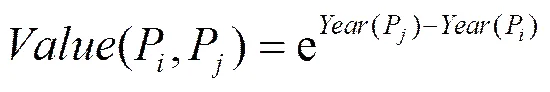
专利之间存在引用关系,这样就可以构造专利引用网络,根据专利在网络中的相对关系,采用网络的度量指标(如距离、跳数)计算专利在技术上的关联程度。这样就可以构造一个排序学习算法向用户推荐最相似的专利。
4.2 专利论文检索
4.1节主要研究在专利文档集合中检索相似的专利,同样论文也是一个很重要的技术文献集合,论文中包含了大量的技术。
对于一个专利,检索与之相关的论文可以帮助专利审查员决定该专利是否新颖,同样对于一个公司可以帮助公司研发人员掌握更全面的相关领域的技术现状。因此对于一个专利检索相似的论文也是一个值得研究的问题。图4是一个基于深度学习的专利论文检索框架。
Step1 特征提取。同样采用卷积神经网络对论文和专利分别提取其相应的特征。由于论文和专利分属不同的科技文献种类,因此需要设计不同的卷积函数对其进行特征提取。
Step2 空间变换。由于论文和专利属于不同类的科技文献,因此可以认为提取的特征属于不同的空间,为了计算其相似程度需要对它进行空间变换。假设V和V分别为专利P和论文A所对应的维向量(假设为列向量)。本文定义存在一个×维的矩阵,使V=MV。它的含义是,如果P和A是相似的,那么在向量空间存在某种形式的矩阵变换使向量变换成。
本文使用目标函数优化的方法计算矩阵,目标函数如式(17),其中,是给定的测试数据集中数据的个数。
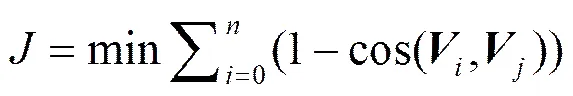
目标函数中采用余弦函数,这是因为如果2个向量在线性空间越相似,其余弦值越大,1−cos(,)越小。对目标函数采用梯度下降的算法对其进行优化,从而得到转换矩阵。
Step3 利用排序学习的方法,对检索到的专利进行推荐。这里排序学习考虑的因素有论文的语义相似度、论文发布的时间、论文的质量以及论文之间的引用关系等因素。
4.3 结合论文的专利趋势分析
专利趋势分析就是分析某个领域现有专利技术发展的现状。正如前面提到科技论文也是一个非常重要的技术来源,在分析专利发展趋势时必须考虑科技论文。
在前面已经设计了卷积神经网络提取专利和论文的特征,并构建了专利和论文之间进行特征转换的矩阵,这样就可以将论文和专利映射到同一个语义空间。
Step1 利用现有的聚类算法,将专利和科技论文进行聚类。
Step2 对于每一类,利用深度学习提取专利和论文中的技术短语(算法1)。
Step3 对每一类技术短语建立Logistic模型,确定其参数,并预测专利的发展趋势。
此外,专利和论文是从不同的方面反映了技术发展的历程。有的领域论文在先,研究人员开展大量的基础研究或者理论研究,到达一定实用阶段时可以去申请大量的专利。有的领域可能是专利在前面,再有大量的研究,如PageRank算法。类似产品的生命周期,本文将技术的生命周期分为4个阶段:导入期、成长期、成熟期和衰退期。
在每一类中,分别对论文和专利建立其相应的Logistic模型,并分析所处的阶段,建立每一个阶段论文和专利之间的时间对应关系,这样更好地帮助企业去预测技术的发展。
算法1 ExtractTechnicalTerm//提取技术短语
1) 使用公开的语料库建立初始的字向量,向量维度为100,迭代100次。
2) 抽取德温特专利数据库中人工标注的技术短语作为训练数据。
3) 使用左右各4个字做为上下文,9×100个神经元为输入层,隐藏层为100,输出层为4,神经网络结构为[900→100→4],进行次迭代,建立深度神经网络DNN-TM[40,41]。
4) 用DNN-TM神经网络抽取专利和论文中的技术短语。
这一节研究了专利检索、结合论文的专利检索方法,均采用了卷积神经网络提取专利和论文的特征,避免了文本稀疏带来的“维数灾难”。方法的核心就是确定卷积神经网络的结构:卷积核的个数及其参数、卷积网络的层数。其次,本文设计了空间转换矩阵,利用目标函数优化的方法实现了论文和专利之间的语义转换。
在专利趋势分析中,本文提出利用深度神经网络提取技术短语词汇,利用生命周期模型,建立论文和专利生命周期之间的对应关系,帮助用户更好地预测技术发展的趋势。
5 结束语
国家和企业越来越重视知识产权的保护,研究人员提出专利的技术现状检索和相关性检索等专利检索方法,设计专利新颖度分析和专利地图分析等专利分析方法,使企业用户可以快速地了解领域的研究现状,把握技术趋势变化,做出合理的企业决策。
在专利检索方面,学者们已经取得了丰硕的成果,提出基于主题的检索、基于引用的检索、基于词库的扩展检索等多种检索方法,但是准确率和召回率仍然有待提高。在专利分析方面,尽管已经取得了一定的成果,但对专利数据的分析仍然较浅[39]。如专利中包含的引用关系很少被考虑到,而进行专利搜索与分析的研究时,如果能够结合引用关系,会使检索和分析结果更加准确。此外,专利文献不仅包括中文,还有英文、日文专利等,并且科技论文中同样包含大量的技术,因此本文必须设计新的智能化专利搜索与分析算法,使之能够适应跨语言、跨语料库的专利检索和分析,这样才能够真正发挥它们的巨大作用。
[1] State Intellectual Property Office of PRC. 2014 key IP5 statistical data[EB/OL].http://www.sipo.gov.cn/tjxx/wjndbg/201507/P020150707534432342721.pdf.
[2] State Intellectual Property Office of PRC. 2013 key IP5 statistical data[EB/OL].http://www.sipo.gov.cn/tjxx/wjndbg/201509/P020150901583608432123.pdf.
[3] State Intellectual Property Office of PRC. 2012 key IP5 statistical data[EB/OL]. http://www.sipo.gov.cn/tjxx/2012tjbgen.pdf.
[4] CHEN C. Searching for intellectual turning points: progressive knowledge domain visualization[J]. PNAS, 2004, 1011(Suppll): 5303-5310.
[5] ERDI P, MAKOVI M, SOMOGYVARI Z, et al. Prediction of Emerging technologies based on analysis of the US patent citation network[J]. Scientometrics, 2013, 95(1): 225-242.
[6] FUJII A, ISHIKAWA T. NTCIR-3 patent retrieval experiments at ULIS[C]//NII Test Collection for IR Systems-3. c2002: 1-6.
[7] FUJII A, ISHIKAWA T, KANDO N. Test collections for ptent-to-ptent rtrieval and ptent map generation in NTCIR-4 workshop[C]//The 4th International Conference on Language Resources and Evaluation. c2004: 1643-1646.
[8] FUJII A, ISHIKAWA T, KANDO N. Overview of the patent retrieval task at the NTCIR-6 workshop[C]//NII Test Collection for IR Systems-6. Tokyo, Japan, c2007: 359-365.
[9] WU S, SUN J, TANG J. Patent partner recommendation in enterprise social networks[C]//WSDM, Rome, Italy, c2013: 43-52.
[10] JIN X, SPANGLER S, CHEN Y, et al. Patent maintenance recommendation with patent information network model[C]//ICDM. Vancouver, Canada, c2011: 280-289.
[11] MANNING C, RAGAVAN P, SCHUTZE H. An introduction to information retrieval[M]. London: Cambridge University Press, 2009.
[12] MAGDY W, JONES G. PRES: a score metric for evaluating recall-oriented information retrieval applications[C]//SIGIR. Geneva, Switzerland, c2010: 611-618.
[13] HIDEO I, HIROKO M, YASUSHI O. Term distillation in patent retrieval[C]//The ACL-2003 Workshop on Patent Corpus. c2003: 41-45.
[14] VERBERNE S,HONDT E D. Prior art retrieval using the claims section as a bag of words[C]//The Cross-language Evaluation Forum Conference on Multilingual Information Access Evaluation: Text Retrieval Experiments. c2009: 497-501.
[15] VARMA M, VARMA V. Applying key phrase extraction to aid invalidity search[C]//International Conference on Artificial Intelligence and Law. Pittsburgh, PA, c2011: 249-255.
[16] KONISHI K. Query terms extraction from patent document for invalidity search[C]//NTCIR-5 Workshop Meeting. Tokyo, Japan, c2005.
[17] MAHDABI P, ANDERSSON L, Keikha M, et al. Automatic refinement of patent queries using concept importance predictors[C]// SIGIR. Portland, USA, c2012: 505-514.
[18] TAKAKI T, FUJII A, ISHIKAWA T. Associative document retrieval by query subtopic analysis and its application to invalidity patent search[C]//CIKM. Washington, USA, c2004: 399-405.
[19] ADAMS S. Comparing the IPC and the US classification systems for the patent searcher[J]. World Patent Information, 2001, 23(1): 15-23.
[20] MAHDABI P, GERANI S, HUANG J X, et al. Leveraging conceptual lexicon: query disambiguation using proximity information for patent retrieval[C]//SIGIR. Dublin, Ireland, c2013: 113-122.
[21] GANGULY D, LEVELING L, MAGDY W, et al. Patent query reduction based on pseudo-relevant documents[C]//CIKM. Glasgow, Scotland, UK, c2011: 1953-1956.
[22] MAGDY W, JONES G. A study on query expansion methods for patent retrieval[C]//PAIR. c2011: 19-24.
[23] KRESTEL R, SMYTH P. Recommending patents based on latent topics[C]//Recommender Systems. c2013: 395-398.
[24] MAHDABI P, CRESTANI F. Query-driven mining of citation networks for patent citation retrieval and recommendation[C]//CIKM. Shanghai, China, c2014: 1659-1668.
[25] HIRONORI D, YOHEI S, et al. A patent retrieval method using a hierarchy of clusters at TUT[C]//NTCIR-5 Workshop Meeting. Tokyo, Japan, c2005.
[26] BHATIA S, HE B, HE Q, et al. A scalable approach for performing proximal search for verbose patent search queries[C]//CIKM. Maui, HI, USA, c2012: 2603-2606.
[27] BASHIR S, AUBER A. Analyzing document retrievability in patent retrieval settings[C]//DEXA. c2009: 753-760.
[28] BASHIR S, AUBER A. Improving retrievability of patents in prior-art search[C]//ECIR. Dublin, Ireland, c2010: 457-450.
[29] SOOYOUNG O, ZHEN L, LEE W C, et al. CV-PCR: a context-guided value-driven framework for patent citation recommendation[C]// CIKM. San Francisco, CA, USA, c2013: 2291-2296.
[30] HUANG W, KATARIA S, CARAGEA C, et al. Recommending citations: translating papers into references[C]//CIKM. Maui, HI, USA, c2012: 1910-1914.
[31] XUE X,CROFT W. Automatic query generation for patent search[C]//CIKM. Hong Kong, China, c2009: 2037-2040.
[32] JUN S H, PARK S, SIK J D. Technology forecasting using matrix map and patent clustering[J]//Industrial Management & Data Systems. 2012, 112(5): 786-806.
[33] CHEN X, PENG Z, ZENG C. A co-training based method for chinese patent semantic annotation[C]//CIKM. Maui, HI, USA, c2012: 2379- 2382.
[34] LIU D, PENG Z, LIU B. Technology effect phrase extraction in Chinese patent abstracts[C]//APWeb. Changsha, China, c2014: 141-152.
[35] DRAZIC M, KUKOLJ D, VITAS M, et al. Technology matching of the patent documents using clustering algorithms[C]//The 14th IEEE International Symposium on Computational Intelligence and Informatics. c2013: 405-408.
[36] HASAN M A, SPANGLER S, GRIFFIN T, et al. COA: finding novel patents through text analysis[C]//SIGKDD. Paris, France, c2009: 1175-1184.
[37] ZHANG L H, LI L, LI T, et al. PatentLine: analyzing technology evolution on multi-view patent graphs[C]//SIGIR. Boston, Massachusetts, USA, c2014: 1095-1098.
[38] ZHANG L H, LI L, LI T, et al. PatentDom: analyzing patent relationships on multi-view patent graphs[C]//CIKM. Shanghai, China, c2014: 1369-1378.
[39] TADURI S,YU H,LAU G, et al. Developing a comprehensive patent related information retrieval tool[J]. Journal of Theoretical and Applied Electronic Commerce Research. 2001, 6(2): 1-16.
[40] BNEGIO, Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research. c2009: 1137-1155.
[41] WANG M X, LU Z D, LI H, et al. GenCNN: a convolutional architecture for word sequence prediction[C]//ACL. c2015.
Patent search and analysis supporting technology innovation
LIU Bin1,2, FENG Ling1, WANG Fei1, PENG Zhi-yong1,2
(1. School of Computer, Wuhan University, Wuhan 430072, China; 2. State Key Laboratory of Software Engineering, Wuhan Uvinersity, Wuhan 430072, China)
The main research work of patent search and analysis were summarizes. The patent search includes patentability search,prior art search,and query expansion. And the patent analysis includes patent map, novelty analysis, and a new analysis framework named PatentDom. Finally, based on the idea of deep learning, three new methods of patent search and analysis are put forward.
patent, patent search, patent analysis, deep learning
TP391.1
A
10.11959/j.issn.1000-436x.2016055
2015-10-10;
2016-01-20
彭智勇,peng@whu.edu.cn
国家自然科学基金资助项目(No. 61232002);湖北省科技支撑计划基金资助项目(No. 2015BAA127);武汉创新团队计划基金资助项目(No. 2014070504020237)
The National Natural Science Foundation of China( No. 61232002), The Science and Technology Support Program of Hubei Province (No. 2015BAA127), The Wuhan Innovation Team Project (No. 2014070504020237)
刘斌(1975-),男,江苏泰兴人,博士,武汉大学讲师,主要研究方向为复杂数据管理、数据挖掘等。
冯岭(1986-),男,河南郑州人,武汉大学博士生,主要研究方向为专利分析与挖掘等。
王飞(1989-),男,江苏连云港人,武汉大学博士生,主要研究方向为专利检索、分析和挖掘。
彭智勇(1963-),男,湖北武汉人,武汉大学教授、博士生导师,主要研究方向为复杂数据、可信数据和Web数据管理。
