PCA和SPA的近红外光谱识别白菜种子品种研究
2016-07-12杜焱喆章海亮
罗 微,杜焱喆,章海亮
华东交通大学,江西 南昌 330013
PCA和SPA的近红外光谱识别白菜种子品种研究
罗 微,杜焱喆*,章海亮
华东交通大学,江西 南昌 330013
为了实现对不同品种白菜种子的快速无损鉴别,应用近红外光谱技术获取白菜种子的光谱反射率,首先采用变量标准化校正和多元散射校正对原始光谱进行预处理;其次,采用主成分分析法(PCA)对光谱数据进行聚类分析,从定性分析的角度得到三种不同白菜种子的特征差异,并采用连续投影算法(SPA)选取特征波长;最后,分别基于全波段光谱、PCA分析得到的前3个主成分变量以及SPA算法选取的特征波长,建立了最小二乘支持向量机(LS-SVM)和偏最小二乘判别(PLS-DA)模型进行白菜种子不同品种的鉴别。从主成分PC1、PC2得分图中可以看出,主成分1和2对不同种类白菜种子具有很好的聚类作用。基于特征波长建立的PLS-DA和LS-SVM模型的判别结果优于基于主成分变量建立的模型,其中基于特征波长建立的LS-SVM模型识别效果最优,建模集和预测集的品种识别率均达到100%。结果表明,通过SPA算法选取的6个特征波长变量能够很好的反映光谱信息,提出的SPA算法结合LS-SVM预测模型能获得满意的分类结果,为白菜种子品种的识别提供了一种新方法。
近红外光谱;主成分分析;连续投影算法;偏最小二乘鉴别;最小二乘支持向量机
引 言
我国国土面积大,不同地区适合种植不同品种的白菜,因此市场上白菜种子品种多,质量也良莠不齐,目前主要依靠人工鉴别品种,但难以确保正确分辨,故需要研究一种简单、实用、可靠的鉴别方法能够替代人工识别白菜种子。近红外光谱检测技术作为一种无损、快速、低成本和绿色无污染的检测及分析方法,可以对物质的品种、成分、质量等进行定性和定量分析,近些年在农产品质量检测中得到了广泛应用。如水蜜桃[1]、红酒[2]、苹果[3]、西瓜[4]、咖啡豆[5]、茶叶[6]、稻谷[7-8]、玉米[9]等,但应用近红外光谱技术检测白菜种子品种的研究相对较少。本文首先对采集的原始光谱数据进行预处理;其次采用主成分分析法(PCA)对光谱数据进行聚类分析,从定性分析的角度得到三种不同白菜种子的特征差异,并用连续投影算法(SPA)挑选特征波长;最后分别以全波段光谱变量、PCA分析得到的前三个主成分变量及SPA算法选取的特征波长变量作为建模输入,结合偏最小二乘鉴别(PLS-DA)和最小二乘支持向量机(LS-SVM)模型进行白菜种子不同品种的鉴别。
1 实验部分
1.1 仪器
试验使用美国ASD公司的近红外光谱仪,其波长范围为325~1 075 nm,光谱采集探头视场角为20°,扫描次数为30次,采样间隔为1 nm,光源为14.5 V卤素灯,光源入射角度为45°。光谱数据分析软件为Unscramble V9.7和Matlab 2012。
1.2 样本采集及样本统计
试验所用白菜种子均来自江西某种子交易市场,包括鑫丰70、青麻叶和山东五号3个白菜种子品种。用同样的标准从每个品种中挑选出30个样品,共计90个样本。全部样本按照2∶1的比例随机分成两个集合,即建模集与预测集。其中建模集有60个样本(每个类别各20个),预测集有30个样本(每个类别各10个)。待设备稳定工作且经过校准后,将样本置于光谱仪采集视角范围内,测定白菜种子的透射光谱,表1为样本统计结果。

表1 样本的建模集和预测集统计
1.3 光谱预处理
为了挖掘光谱数据中的有效信息,提高信噪比,更好的利用光谱数据进行建模分析,需要采取适当的光谱预处理方法来去除光谱信号中存在的高频随机噪声、谱线平移、光散射等干扰的影响。常见的预处理方法有: 中值滤波平滑法(moving average smoothing)、变量标准化校正(SNV)、多元散射校正(MSC)、一阶(1st Der)和二阶导数(2nd Der)等。我们分别采用中值滤波平滑法、SNV、MSC等三种预处理方法进行试验。
1.4 建模方法与模型评价
1.4.1 偏最小二乘判别
偏最小二乘PLS算法是通过建立光谱数据与品种分类值之间的多元统计回归模型,进行分析。除了线性回归分析,PLS在建模过程中集合了包括主成分分析、典型相关分析等方法的功能特点,因此在分析结果中,不仅可以建立更优化的回归模型,还可以同时进行主成分分析以简化数据结构,观察变量间的相互关系等研究内容,提供更多的建模信息。PLS方法将光谱数据与变量进行多元线性回归,而偏最小二乘判别(PLS-DA)方法是基于PLS回归的一种判别分析方法,基于预测的分类值,选择相应的阈值进行归类[10]。具体判别标准为: 计算验证集的分类值(Yp),①当|Yp-样品预设值|≥0.1,判定样本不属于该类;②当|Yp-样品预设值|<0.1,判定样本属于该类。
1.4.2 最小二乘支持向量机
LS-SVM是经典支持向量机(SVM)的一种改进算法,具有很强的非线性处理能力,避免了复杂的计算,同时也是一种快速的多元建模方法,被广泛应用于非线性时间序列的预测中[11]。LS-SVM将求解复杂的二次优化问题转化为求解线性方程组来获得支持向量,克服了在少量的训练样本中训练时间长、训练结果存在随机性等不足。LS-SVM首先通过一非线性映射函数将样本的输入变量映射到高维特征空间。然后构造优化函数,将优化问题转换为等式约束条件。可以利用拉格朗日乘子对最优化问题进行求解,对各个变量求偏微分。LS-SVM的算法描述如下:
设训练集样本为D={(xk,yk)|k=1,2,…,N},xk∈Rn,yk∈{-1,1},其中x为输入向量为,y为目标值。
在权w空间中可以转化为求解如下函数
(4)
约束条件为yk=wTφ(x)+b+ek,k=1,…,N,其中权向量w∈Rn,φ(x)为Rn→Rnh的核空间映射函数,b是偏差量,误差变量ek∈R,γ是可调超参数。
通过拉格朗日乘子对此最优化问题进行求解,可得
L(w,b,e,α)=J(w,e)-

(5)
其中αk(k=1,2,…,N)是拉格朗日乘子。根据优化条件
(6)
可得
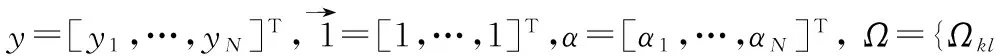
核函数Ωkl=φ(xk)Tφ(xl)=K(xk,xl),k,l=1,…,N是满足Mercer条件的对称函数。
采用RBF(radialbasisfunction)核函数可得
K(x,xk)=exp(-‖x-xk‖2/σ2)
(8)
最后得到LS-SVM拟合模型
1.4.3 模型评价
采用决定系数、建模集交互验证的均方根误差、预测集样本预测的均方根误差和识别正确率等指标评价模型的预测效果。识别正确率和决定系数越大,均方根误差越小,模型的性能就越好。
2 结果与讨论
2.1 白菜种子样本的光谱特征曲线
图1为不同品种白菜种子的近红外光谱曲线,其中以波长为横坐标,范围是325~1 075 nm,光谱漫反射率为纵坐标。如图1所示,不同品种白菜种子的光谱曲线具有相似的变化趋势,难以从光谱特征中区分不同样本之间曲线的差异,因此需要采取化学计量学的建模方法,建立光谱与不同品种白菜种子之间的定性模型。由于光谱曲线在首尾波段处含有较多噪声,取400~1 000 nm波长范围共计601个变量为研究对象。
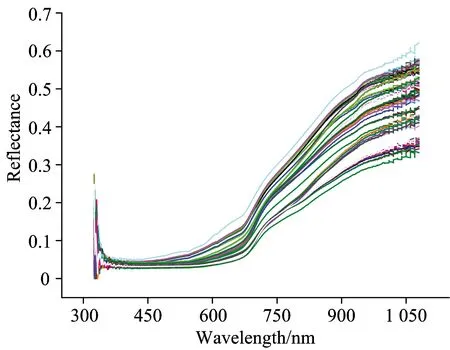
图1 不同品种白菜种子的近红外原始光谱

表2 不同预处理方法的PLS建模预测结果
2.2 PCA聚类分析
主成分分析(PCA)方法是一种经典的降维方法,它可以用较少的变量去解析原始变量中的大部分信息,且所含信息互不重复,从而把多个变量转化为少数几个综合指标即主成分。通过PCA分析可以将复杂因素归结为几个主成分,并对未知样品进行归类。应用matlab软件,用PCA对原始光谱进行聚类分析,表3为前三个主成分对光谱变量的累计解析百分比即累计可信度。从表3可以看出,仅主成分PC1的可信度就为97%,前两个主成分PC1和PC2的累计可信度已达98%,说明采用前两个主成分PC1和PC2就能较好的解析原始光谱的主要信息。

表3 前三个主成分的累计可信度
选取通过PCA分析得到的前两个主成分对90个白菜种子样本进行归类。图2为PC1和PC2的得分图,其中横坐标为每个样本的PC1得分值,纵坐标为PC2得分值。从图2中可以明显看出,样本被分成三类。品种为山东五号的30个白菜种子样本均分布在Y轴的右方即第一、四象限且聚合度较好;品种为青麻叶的30个白菜种子样本分布也较为集中,主要分布在第二、四象限;相比前两个品种,品种为鑫丰70的白菜种子样本聚合度最优,集中分布在第三象限内,除了有1个样本在第二象限,而另外两个品种都平均分布在两个象限内。以上结果表明,主成分PC1和PC2对三种白菜种子有较好的聚类作用,从定性分析的角度得到三种不同白菜种子的特征差异。

图2 90个白菜样本的PC1和PC2得分图

图3 基于前5个PC变量的PLS建模RMSE分布图
选取的波段从400~1 000 nm共有601个波长点,若采用全光谱波段建模,信息量大、变量太多,且有些样品的光谱信息很弱,与样品的性质没有明显的相关性,对品种的鉴别贡献小。因而在PCA分析基础上,选择对白菜种子有较好聚类作用的少数变量作为输入建立品种预测模型。图3是采用PCA分析后取前5个主成分变量进行PLS建模得到的RMSE分布图,横坐标表示前5个主成分变量,纵坐标表示选择不同的主成分变量个数时RMSE的变化值。从图中可以看出取前3个主成分变量建模时,误差已经达到最小,随着变量个数的增加,误差并未增大。取基于PCA分析得到的前3个主成分变量作为后续预测模型的输入。
2.3 连续投影算法
连续投影算法(SPA)作为一种重要的特征波长变量提取方法,能够有效剔除变量之间的共线性,最大程度避免信息的重复,使得变量之间的信息冗余度最低[12]。该算法可以把最重要的少数几个波长点选出来概括大多数样品的光谱信息,因而能够降低模型的复杂度并减少计算量,提高模型的速度和效率。应用matlab软件运行相关程序,运行结果如图所示。图4表示RMSE值随变量数增加的变化,实心圆点表示挑选出的波长数。可以看出当选取3个波长点时,均方根误差值有一个快速下降的过程,选取6个波长点建模时,均方根误差达到最小的稳定值,之后随着变量数的增加,误差也未增大。挑选的6个特征波长点在整个光谱波长范围内的分布如图5所示,这6个波长点均匀地分布在可见和近红外光谱范围内,说明对于样本的分类不能仅仅考虑某个范围的波长。采用SPA提取到的6个特征波长分别为925, 668, 577, 885, 992和888 nm。

图4 RMSE值随SPA选择变量数增加的变化图

图5 SPA选择的6个特征波长分布图
2.4 基于PCA和SPA建立品种预测模型
基于PCA聚类分析得到的PC1,PC2,PC3和SPA算法选取的6个特征波长作为输入变量,依次采用PLS-DA和LS-SVM算法建立不同预测模型,其分类结果见表4。表4中,对比相同输入变量的建模结果,可以看出LS-SVM模型的预测结果要明显优于PLS-DA模型。其中,采用LS-SVM模型分别对预处理后的全波段光谱、前3个主成分变量及6个特征波长变量建模的建模集和预测集的分类正确率均高达100%。而PLS-DA模型对预处理后的全波段光谱建模,预测集的分类正确率为93.3%;基于SPA提取的特征变量建立的PLS-DA模型,其预测集的分类正确率为90%;基于PCA分析获取的前三个主成分特征变量建立的PLS-DA模型预测效果最差,预测集的分类正确率仅为66.7%。主要原因在于LS-SVM模型是一种非线性建模方法,一般来说,相对于PLS这样的线性模型,采用非线性模型建模更为复杂,模型建立过程中考虑到了非线性影响因素,如白菜种子水分、颜色深浅和颗粒大小等,从而提高了模型的预测效果。此外,采用PLS-DA模型用于品种鉴别时,阈值设为0.1,若增大阈值,则PLS-DA的建模集和预测集的正确率会提高,将该模型应用于白菜种子品种鉴别也具有一定的可行性。

表4 PLS-DA和LS-SVM模型分类预测结果
表4中,对比不同输入变量的建模结果,可以看出参与建模的输入变量个数越多,预测效果越好。比如采用预处理后的全波段光谱数据,共601个波长点作为输入变量建模时,预测集的正确率最高,Raw-PLS-DA为93.3%,Raw-LS-SVM为100%。采用SPA算法选取的6个特征波长作为输入变量建模时,预测集的正确率也均达到90%,SPA-PLS-DA为90%,SPA-PLS-DA为100%。采用PCA分析得到的前三个PC值作为输入变量时,预测集的正确率最低,PCA-PLS-DA为66.7%,PCA-LS-SVM为100%。采用全波段光谱建模时,变量多,包含信息量大,结果更为准确。但建模时运算更为复杂,效率低,包含的冗余信息也较多。而采用PCA分析法得到的变量个数较少,不能充分代表原始光谱的全部信息,但效率最高。采用SPA算法挑选出的有效波长能充分代表原始光谱的有效信息,预测效果较好,可以作为波长提取的一种有效手段,提高模型运算速度。结果表明,采用SPA算法选取有效特征波长并结合LS-SVM模型对白菜种子品种进行分类是可行的,并且获得了满意的准确度。
3 结 论
采用近红外光谱技术实现白菜种子的品种识别,分别利用变量标准化校正(SNV)和多元散射校正(MSC)对光谱数据进行预处理,能很好消除光散射以及样品光谱中基线漂移的影响。采用PCA分析法对光谱数据进行聚类分析,从定性分析的角度得到3种不同白菜种子的特征差异,从主成分PC1和PC2得分图中可以看出,主成分1和2对不同种类白菜种子具有很好的聚类作用,提取基于PCA分析得到的前3个主成分变量。采用SPA算法对预处理后的光谱提取出6个特征波长,分别基于全波段光谱变量、PCA分析得到的前3个主成分变量以及SPA算法选取的特征波长变量,建立PLS-DA和LS-SVM预测模型。结果显示,基于特征波长建立的PLS-DA和LS-SVM模型的判别结果优于基于主成分变量建立的模型,其中基于特征波长建立的LS-SVM模型识别效果最优,建模集和预测集的品种识别率均达到100%。相比PCA分析法,通过SPA选取的6个特征波长变量更能够反映光谱信息。试验结果表明,应用近红外光谱技术可以快速而又准确的鉴别白菜种子品种。本文提出的SPA算法结合LS-SVM预测模型能获得满意的分类结果,为白菜种子品种的识别提供了有效的方法和依据。
[1] Monti L L, Bustamante C A, Osorio S, et al. Food Chemistry, 2016, 190: 879.
[2] Heras-Roger J, Díaz-Romero C, Darias-Martín J. Food Chemistry, 2016, 196: 1224.
[3] Jakobek L, Barron A R. Journal of Food Composition and Analysis, 2016, 45: 9.
[4] ZHANG Chu,LIU Fei,KONG Wen-wen, et al(张 初,刘 飞,孔汶汶, 等). Transactions of the Chinese Society of Agricultural Engineering(农业工程学报), 2013,(20): 270.
[5] BAO Yi-dan,CHEN Na,HE Yong, et al(鲍一丹,陈 纳,何 勇, 等). Optics and Precision Engineering(光学精密工程), 2015, (2): 349.
[6] Cai J, Wang Y, Xi X, et al. International Journal of Biological Macromolecules, 2015, 78: 439.
[7] LIU Wei,LIU Chang-hong,ZHENG Lei(刘 伟,刘长虹,郑 磊). Transactions of the Chinese Society of Agricultural Engineering(农业工程学报), 2014,(10): 145.
[8] Miskelly D M, Wrigley C W. Identification of Varieties of Food Grains: Elsevier, 2016.
[9] YANG Hang,ZHANG Li-fu,TONG Qing-xi(杨 杭,张立福,童庆禧). Infrared and Laser Engineering(红外与激光工程), 2013,(9): 2437.
[10] Mazivila S J, de Santana F B, Mitsutake H, et al. Fuel, 2015, 142: 222.
[11] Cheng J, Sun D. LWT-Food Science and Technology, 2015, 63(2): 892.
[12] FANG Xiao-rong,ZHANG Hai-liang,HUANG Ling-xia, et al(方孝荣,章海亮,黄凌霞, 等). Spectroscopy and Spectral Analysis(光谱学与光谱分析), 2015,35(5): 1248.
(Received Feb. 3, 2016; accepted Jun. 12, 2016)
*Corresponding author
Discrimination of Varieties of Cabbage with Near Infrared Spectra Based on Principal Component Analysis and Successive Projections Algorithm
LUO Wei,DU Yan-zhe*,ZHANG Hai-liang
East China Jiaotong University, Nanchang 330013, China
The varieties of cabbage seeds directly affect the yield and quality of cabbage, in order to rapidly and nondestructively identify the varieties of cabbage seeds, near infrared spectra technique were applied in this study and reflectance spectrum of the cabbage seeds was obtained. Firstly, to excavate the effective information in the spectral data and improve signal to noise ratio, the raw spectra was pre-processed with the method of standard normal variate (SNV) and multiplicative scatter correction (MSC). Secondly, principal component analysis (PCA) was used to analyze the clustering of cabbage samples, then the characteristic differentia of three cabbage varieties was obtained through qualitative analysis. Six Effective wavelengths were selected by successive projections algorithm (SPA). Finally, the full spectra variable, the first three principal components (PCs) using PCA and selected effective wavelengths using SPA were respectively set as inputs of the partial least squares discriminant analysis (PLS-DA) and least-squares support vector machine (LS-SVM) models for the classification of cabbage seeds. As can be seen from the two dimensional plot drawn with the scores of PC1 and PC2 (the first two principle components), PC1 and PC2 had a good clustering effect for different kinds of cabbage seeds. LS-SVM models performed better than PLS-DA models, the correct rates of discrimination were 100% achieved with LS-SVM models. PLS-DA and LS-SVM models built based on the selected wavelengths performed better than the models built based on the first three principal components, moreover, the SPA-LS-SVM model obtained the best results among all models, with 100% discrimination accuracy for both the calibration set and the prediction set. The overall results show that SPA can extract wavelengths, and the LS-SVM model combined with SPA can obtain optimal classification results. So the present paper could offer an alternate approach for the rapid discrimination of cabbage seeds variety.
Near infrared spectral;Principal component analysis (PCA);Successive projections algorithm (SPA);Partial least squares discriminant analysis (PLS-DA);Least-squares support vector machine (LS-SVM)
2016-02-03,
2016-06-12
国家自然科学基金项目(61565005)资助
罗 微,女,1988年生,华东交通大学助教 e-mail: 15270030556@163.com *通讯联系人 e-mail: dyz@ecjtu.edu.cn
TP731
A
10.3964/j.issn.1000-0593(2016)11-3536-06
