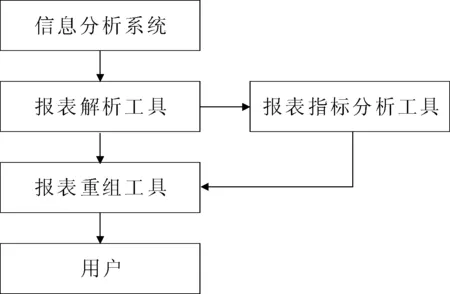
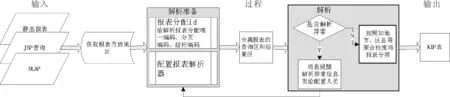
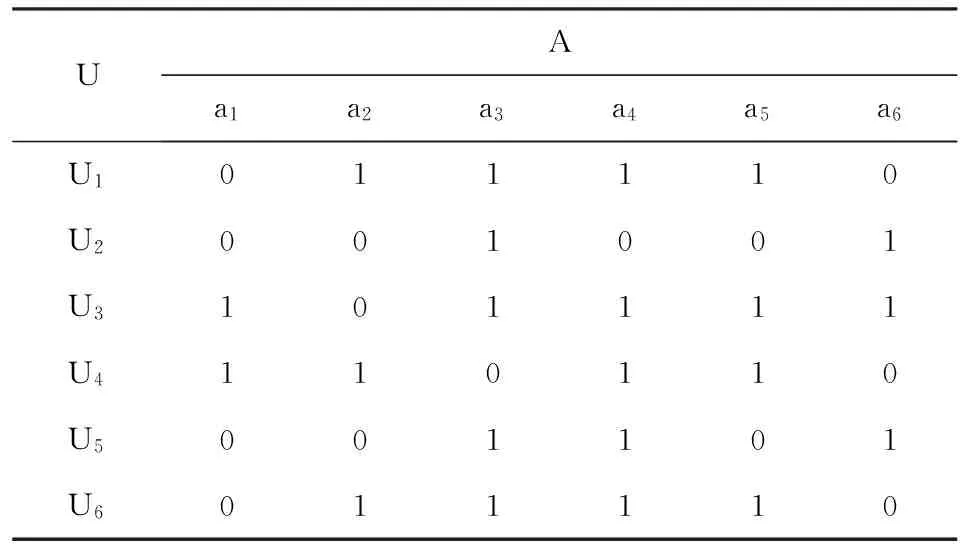
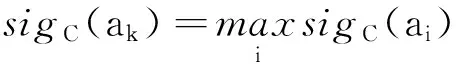基于粗糙集的报表重组方法
2016-07-06王文庆
王文庆, 王 耀
(1.西安邮电大学 自动化学院, 陕西 西安 710121;2.西安邮电大学 通信与信息工程学院, 陕西 西安 710121)
基于粗糙集的报表重组方法
王文庆1, 王耀2
(1.西安邮电大学 自动化学院, 陕西 西安 710121;2.西安邮电大学 通信与信息工程学院, 陕西 西安 710121)
摘要:针对企业信息系统报表数据处理问题,提出基于粗糙集的报表解析重组方法。该方法运用报表解析工具对报表进行解析,引入“信息量”概念,并利用粗糙集属性约简方法,实现对报表指标体系的筛选评价,确定出重要指标。最后,再利用报表重组工具,对信息系统中的指标进行重新组装。实例验证结果表明,该方法可实现多报表之间不同指标的自由组合,生成新的报表,提高了报表开发的效率。
关键词:报表解析;报表重组;粗糙集;信息量
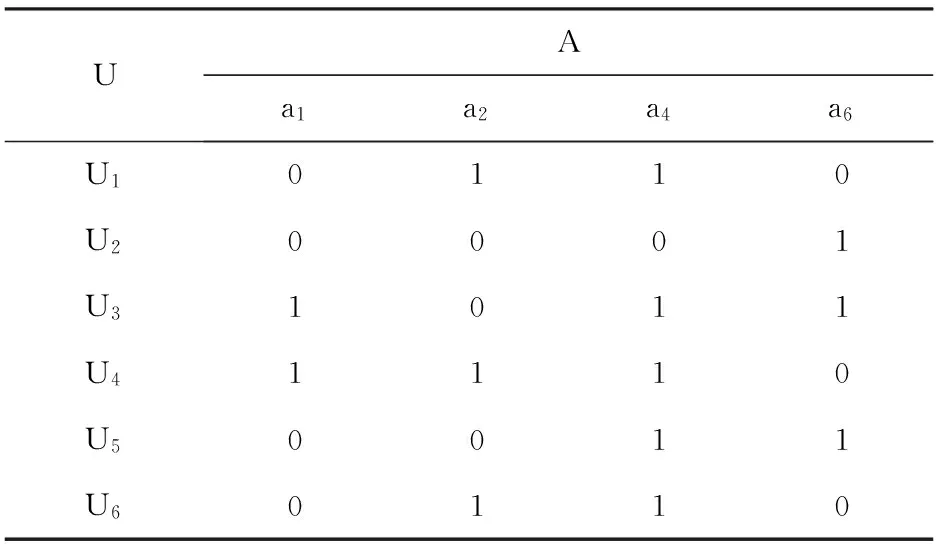
经营报表分析是企业掌握自身经营状况,并辅助经营决策的基本措施和主要途径,是企业经营管理的重要组成部分[1-2]。各企业经营报表的灵活度,是衡量每个企业综合运营能力的重要指标,也是反映企业信息化程度的重要指标[3]。目前,现有的技术方案是由业务部门初步提出需求,开发人员与业务部门确认需求,再将设计报表样式交给业务部门确认,最终由开发人员根据确认后的详细需求开发出报表[4]。
根据实际应用中的情况,现有的报表设计流程存在以下问题。
(1)传统报表开发流程适用于需求变动较小的报表需求。由于企业业务的扩充,部分报表需求再开发过程中可能会发生新的需求修改,这就意味着需要开发人员重新与业务人员确认报表开发需求。
(2)大多数企业的报表主要以静态报表为主,不同报表中的指标不能交互,存在相同的关键绩效指标(KeyPerformanceIndicators,KPI),使得报表利用率较低。如何在现有报表中提炼出应用者需要的报表体系,在当前技术方案是不能实现的。
(3)新业务的高速发展,原有的部分业务随着业务演进逐步淘汰,部分信息分析报表只能整体作废,但这些报表中的部分指标仍有意义,不能将其中有用的部分提取出来,供后续新增的报表使用,从而造成了资源的浪费。
(4)目前的技术方案也不能实现对重要指标的筛选并进行监控。文献[1-3]主要是通过各类型组件实现用户自定义数据项和报表界面的功能,将报表的格式和数据分离,实现报表格式的自定义从而提高报表的灵活性,而不是针对报表之间数据的互通性,复用性,数据项还是从数据库中获取。
本文拟提出一种基于粗糙集属性约简的报表解析重组方法,将报表进行解析,利用粗糙集[5]和“信息量”概念[6]进行报表指标约简并确定指标权重,最后对报表进行重组。
1粗糙集理论与信息量
粗糙集理论是处理模糊和不确定知识的数学工具。根据观测数据删除冗余信息,分析知识的粗糙度、属性间的依赖性与重要性,生成分类或决策规则等[5]。
1.1信息系统
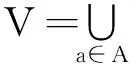
每个属性子集P⊆A决定一个二元不可分关系IND(P),信息系统S=(U,A,V,f)也可称为知识表达系统U/IND(A)。
设集合元素x,y∈U,如果(x,y)∈IND(P),则称x和y是等价的。等价关系IND(P)构成了U的等价划分,表示为
IND(P)={X1,X2,…,Xn},
对于i≠j,i,j=1,2,…,n,有
Xi≠∅,Xi≠Xj,

1.2属性约简
定义2[8]设信息系统中属性a∈A,如果
IND(A-{a})=IND(A),
则称属性a在A中是不必要的(多余的);否则,称a在A中是必要的。
不必要的属性在信息系统中是多余的,如果将它从系统中去掉,不会改变该系统的分类能力。但是,若从系统中去掉必要的属性,则一定会改变该系统的分类能力。
定义3[9]信息系统中属性集A中所有必要的属性组成的集合称为属性集A的核,记作Core(A)。
定义4[10]设属性子集P⊆A。如果
IND(P)=IND(A),
且P是独立的,则称P是A的一个约简。
1.3知识的信息量及重要性度量
将信息量概念引入信息系统。
定义5[6]设信息系统中,属性子集P⊆A,且
U/IND(P)={X1,X2,…,Xn},
则定义属性子集P的信息量为
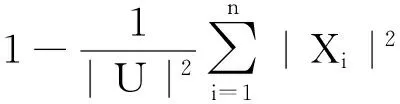
其中|Xi|表示集合Xi的基数,|Xi|/U表示等价类Xi在U中的概率。
定理1[11]设属性子集P⊆A。若
U/IND(A)⊂U/IND(P),
则I(P) 定理2[11]设属性子集P⊆A,则 IND(P)=IND(A) 当且仅当I(P)=I(A)。 定义6[6]属性a∈A在A中的重要性定义为 sigA-{a}(a)=I(A)-I(A-{a})。 当且仅当sigA-{a}(a)>0时,属性a∈A在A中是必要的。属性集A的核 Core(A)={a∈A: sigA-{a}(a)>0} 。 定义7[12]若C⊆A,任意属性a∈A-C(集合A和C的差)关于属性子集C的重要性定义为 sigC(a)=sigC∪{a}-{a}(a)= I(C∪{a})-I(C)。 属性a∈A-C关于属性集C的重要性由C中添加a后所引起的信息量的变化大小来度量。sigC(a)的值越大,说明属性a∈A-C关于属性集C就越重要。 2报表解析重组流程 运用报表解析重组方法构建报表解析、报表指标分析和报表重组3个工具,对信息系统中的报表进行解析,指标分析并重新组装,从而生成新的报表。图1为报表重组的流程。 图1 报表生成流程 由图1可见,从信息系统现有报表中获取数据,通过报表解析工具将报表数据解析出来,生成到后台数据库物理表里,提供给报表指标分析工具及报表重组工具,然后将信息推送给用户。开发相应的报表重组前台界面,用户可以根据需求对指标进行选择,生成所需报表,报表生成之后进行报表发布,或对某些指标进行监控。 指标解析重组流程如图2所示。用户从前台界面发送报表解析信息,同时将报表刷新完成消息发送给报表解析工具,然后报表解析工具从信息分析系统中获取满足条件的报表物理数据,将报表内容解析后生成到数据库物理表里,同时生成报表解析完成消息,并将完成消息和数据提供给报表指标分析工具和报表重组工具,然后用户根据需求获取KPI,进行新报表的发布和实现KPI的监控。 图2 指标解析重组流程 3基于粗糙集的报表重组方法 3.1构建报表解析工具 报表解析工具是报表组装系统中的重要组件,包括输入、处理过程和输出。报表解析原理如图3所示,输入端从信息系统获取报表数据,根据报表类型(静态报表,JSP报表,OLAP报表)得到报表存放的地址解析后,将解析出的各指标数据输入到后台记录KPI数据的数据库物理表里,完成解析。获取报表各指标数据后,报表指标分析和重组时就可以实现表表之间的互通,根据需求获取数据。 图3 报表解析原理 报表解析的主要过程如下。 步骤1报表解析配置。为了方便解析配置,整个报表解析有专门的前台界面支撑,在前台界面上可对报表、报表的时间区间和地市等解析信息进行相应的选择。 步骤2构建报表解析后的表名称。解析后的报表对应唯一的后台数据表,数据表中每个指标对应唯一的编码。编码由虚拟报表编码、分页编码和指标编码共同组成。虚拟报表编码由系统自动生成,分页编码及指标编码由解析程序自动识别生成。为了使表的各指标操作方便,对报表中指标作一个映射,分别对应一个中文名称。最后将解析出来的数据存放在报表对应的数据表里。 步骤3报表界面分析。每个报表的界面都是由查询区和结果区组成,查询区为不同的查询条件,结果区由指标名称、指标维度、数据结果3部分组成。步骤2对结果区进行了指标唯一性确定,后台数据存放还需要对查询区的条件进行解析,解析到后台对应数据库表指标中,使结果具有通用性。 步骤4日常解析记录及异常解析记录。记录解析步骤日志方便后期查看;当解析出现异常时,维护人员能够根据报表异常解析情况,做到快速的响应。 报表解析完成之后,进行报表指标评价约简。结合粗糙集理论,融入信息论中“信息量”的概念,对报表指标进行约简,减少报表重组时的指标数量,筛选出重要的指标,同时根据权重对各指标进行排序。 3.2构建指标分析工具 3.2.1指标约简 为了减少信息系统中报表指标的数量,需要去掉信息分析报表中冗余信息。报表中的指标集对应着粗糙集信息系统中的属性集,信息系统属性集约简的过程就是指标集约简的过程。 基于粗糙集理论,计算指标集A的核,选择指标重要性大的指标依次加入到核中,直到约简后的指标集信息量与原指标集A的信息量相同为止。 算法描述如下。 输入信息系统S=(U,A,V,f),其中U为论域,A为指标集。 输出该信息系统的最小约简C。 步骤1计算指标信息系统的信息量I(A)。 步骤2令Core(A)=∅。对于所有ai∈A,计算其在信息系统中的重要性sigA-{ai}(ai),若sigA-{ai}(ai)≠0,则Core(A)=Core(A)∪{ai}。然后计算I(Core(A)),若I(Core(A))=I(A),则Core(A)为A的最小近似约简,算法结束。否则,执行步骤3。 3.2.2基于属性重要性设置权重 利用指标自身的信息量来计算权重,评价指标自身的信息,保持指标权重计算的客观性。 指标体系经过指标约简后,得到约简后的指标集C={r1,r2,…,rm},ri为指标集约简后的第i个指标(i=1,2,…,m)。由定义4可知,C是独立的,C中的属性也是独立的。根据知识的信息量的概念,指标权重确定的算法步骤如下。 输入指标约简后的信息系统 S=(U,C,V,f)。 输出指标集C中各指标的权重wi。 步骤1由等价关系C对论域U的划分为 U/IND(C)={X1,X2,…,Xn}; 计算约简后指标集C的信息量I(C)。 步骤2计算所有属性ri(i=1,2,…,m)的重要性 sigC-{ri}(ri)=I(C)-I(C-{ri})。 步骤3归一化ri的属性重要性,得出每个指标的权重为 3.3构建报表重组分析工具 对报表进行指标分析后,根据具体情况进行报表重组。该重组工具将需求指标进行固化,通过对指标数据进行组装拼接,形成新的报表。报表重组在前台界面操作,如图4所示,该重组工具核心是报表查询区、监控配置区和报表自定义区。 图4 报表重组原理 为了对报表各指标进行查询,提供了报表查询区;根据指标评价结果,对重要指标进行监控、预警,提供了监控配置区;为了能够对报表进行自定义重组,提供了报表自定义区,可以根据需求对指标进行选择,生成新报表,实现报表的重组。在重组的过程中也可以对指标进行简单的计算,使用报表重组展现工具将报表发布。 4应用实例分析 以某通信运营商收入报表为例,对该报表进行解析,指标约简,重组,验证本文方法的有效性。对前台报表查询区和结果区进行解析,根据具体报表、报表分页、报表指标和维度等进行解析。通过粗糙集和信息论中“信息量”的结合对报表进行指标约简、指标重要性评价,减少指标数量和筛选出重要指标。 根据报表数据对报表进行离散化,1表示数据达标,0表示未达标。构建报表指标评价表如表1所示,a1为本地通话费,a2为增值业务收入,a3为WLAN收入,a4为短信收入,a5为彩信收入,a6为流量收入,则指标集 A={ a1, a2, a3, a4, a5, a6}, 论域 U={U1, U2, U3, U4, U5, U6}。 4.1评价指标集约简 指标约简算法步骤如下。 步骤1根据指标信息系统,等价关系为 U/IND(A)={{U1,U6},U2,U3,U4,U5}, 计算得I(A)=30/36。 步骤2计算指标a1的重要性,得 sigA-{a1}(a1)=I(A)-I(A-{a1})=0。 同理可得a2,a3,a5和a6的重要性都为0,而 sigA-{a4}(a4)=2/36, 因此 Core(A)={a4}。 计算得 I(Core(A))=12/36 步骤3令 C=Core(A)={a4}, A-C={a1,a2,a3,a5,a6}。 指标集A-C中各指标的重要性分别为 sigC(a1)=I(C∪{a1})-I(C)=18/36, sigC(a2)=sigC(a6)=16/36, sigC(a3)=sigC(a5)=10/36。 重要性最高的是a1,将其加入C,得 C={a1,a4}。 因为 I(C)=20/36 故重复此过程,直至得到最小约简指标集 C={a1,a2,a4,a6}, 此时有I(C)=I(A)。 通信运营商的重要指标为a1,a2,a4和a6。指标个数减少了33%,减少了报表重组指标数量。约简后的指标如表2所示。 表2 约简后的指标评价表 4.2指标权重计算 步骤1最小约简指标集的等价关系为 U/IND(C)={{U1,U6},U2,U3,U4,U5}, 最小约简指标集信息量I(C)=30/36。 步骤2各指标重要性分别为 sigC-{a1}(a1)=sigC-{a2}(a2)= sigC-{a4}(a4)=2/36, sigC-{a6}(a6)=6/36。 步骤3归一化处理指标重要性,得 wa1=wa2=wa4=0.166 7,wa6=0.500 0。 可见,报表进行解析之后,使用粗糙集综合评价方法可以有效的约简评价指标,减少指标的数量,确定指标的重要性。指标约简评价之后,将指标约简评价信息发送给报表重组工具,可在报表查询区对各指标进行查询,根据需求及指标的权重结果对指标进行选择及监控,生成新的报表。 5结语 将报表进行解析,通过粗糙集理论分析,引入“信息量”的概念到粗糙集信息系统中,对报表指标集进行了指标约简和权重设置,减少了报表重组的指标数量。实例验证结果表明,基于粗糙集报表重组的方法克服了信息系统报表数据处理问题,为企业提供有效的报表重组方法,提高了报表的利用率。 参考文献 [1]李广,王建林,赵利强,等.基于Silverlight的柔性生产报表系统的设计[J/OL]. 计算机工程与设计,2013,34(7):2595-2598[2015-07-15].http://mall.cnki.net/magazine/article/SJSJ201307064.htm.DOI:10.3969/j.issn.1000-7024.2013.07.063. [2]巫乔顺, 彭海波, 李杰. 一种自定义动态报表系统的设计与应用[J/OL].机械设计与制造工程, 2013(1):80-82[2015-07-15].http://mall.cnki.net/magazine/article/JXZZ201301025.htm.DOI:10.3969/j.issn.2095-509X.2013.01.022. [3]马燕, 王文发, 许淳,等. 基于Web的生产统计报表的设计与实现[J/OL].计算机技术与发展, 2012,22(2):213-216[2015-07-15].http://mall.cnki.net/magazine/article/WJFZ201202057.htm.DOI:10.3969/j.issn.1673-629X.2012.02.056. [4]贾旸. 统计报表应用需求分析[J/OL].中国金融脑,2010:29-32[2015-07-18].http://mall.cnki.net/magazine/article/ZGJN201001009.htm.DOI:10.3969/j.issn.1001-0734.2010.01.007. [5]PAWLAKZ.Roughsettheoryanditsapplicationstodataanalysis[J].CyberneticsandSystems:AnInternationalJournal,1998,29(1):661-688.DOI:10.1080/019697298125470. [6]梁吉业, 曲开社, 徐宗本. 信息系统的属性约简[J/OL]. 系统工程理论与实践, 2001, 21(12):76-80[2015-07-22].http://mall.cnki.net/magazine/article/XTLL200112013.htm.DOI:10.3321/j.issn:1000-6788.2001.12.014. [7]张文修,吴伟志,粱吉业,等.粗糙集理论与方法[M/OL].北京:科学出版社,2001:1-39[2015-07-20].http://download.csdn.net/detail/monkeyxxxx/3610810. [8]PAWLAKZ.Roughsetstheoreticalaspectsofreasoningaboutdata[M/OL].Boston:KluwerAcademicPublishers,1991[2015-07-20].http://download.csdn.net/detail/myyd1zhi/4695183. [9]SHENJB,LVYJ,TAODX.AnApproximateAttributeReductionofRoughSetandItsAlgorithm[C/OL]//IntelligentComputationTechnologyandAutomation, 2009.ICICTA’09.SecondInternationalConferenceon.Changsha:IEEE, 2009:591-594[2015-07-23].http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=5287751.DOI:10.1109/ICICTA.2009.377. [10]MAM,DENGT.Theattributereductionoftheinformationsystembasedonnewroughset[C/OL]//IntelligentControlandInformationProcessing(ICICIP), 2011 2ndInternationalConferenceon.Harbin:IEEE, 2011:301 - 304[2015-07-23].http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=6008253.DOI:10.1109/ICICIP.2011.6008253. [11] 李鸿.一种基于绝对信息量的知识约简算法[J/OL].计算机工程与应用,2004,14(28):52-53[2015-07-23].http://mall.cnki.net/magazine/article/JSGG200428015.htm.DOI:10.3321/j.issn:1002-8331,2004.28.016. [12] 鲍新中,张建斌,刘澄. 基于粗糙集条件信息熵的权重确定方法[J/OL]. 中国管理科学, 2009(3):131-135[2015-07-25].http://mall.cnki.net/magazine/article/ZGGK200903018.htm.DOI:10.3321/j.issn.1003-207x.2009.03.018. [责任编辑:祝剑] Reportreconstructingmethodbasedonroughset WANGWenqing1,WANGYao2 (1.SchoolofAutomation,Xi’anUniversityofPostsandTelecommunications,Xi’an710121,China;2.SchoolofCommunicationandInformationEngineering,Xi’anUniversityofpostsandTelecommunications,Xi’an710121,China) Abstract:A new method for parsing and restructuring report based on rough set is proposed to deal with the issues in data processing of the report in information system. The report is parsed by the report-parsed tools. A concept of “information quantity” is introduced to determine the important indexes, and finish the screening evaluation of report index system by rough set attribute reduction method. Then the report-restructured tools are used again to restructure the indexes in the information system. Example verification results show that, the proposed method can achieve ree combination of different indexes among the multiple reports, generate new reports and improve the efficiency of report development. Keywords:report-parsed, report-restructured, rough set, information quantity doi:10.13682/j.issn.2095-6533.2016.02.021 收稿日期:2015-11-05 基金项目:陕西省科技厅工业攻关计划项目(2014K05-29);陕西省教育厅科学研究计划资助项目(14JF028) 作者简介:王文庆(1964-),男,博士,教授,从事复杂系统分析与控制、智能信息处理研究。E-mail: wwq@xupt.edu.cn 王耀(1990-),女,硕士,研究方向为通信信号处理及应用。E-mail:15929480371@163.com 中图分类号:TP319 文献标识码:A 文章编号:2095-6533(2016)02-0105-06