一种基于加权LDA模型的文本聚类方法
2016-07-05张春杰张志远
李 国,张春杰,张志远
(中国民航大学a.计算机科学与技术学院;b.中国民航信息技术科研基地,天津 300300)
一种基于加权LDA模型的文本聚类方法
李国a,b,张春杰a,b,张志远a,b
(中国民航大学a.计算机科学与技术学院;b.中国民航信息技术科研基地,天津300300)
摘要:针对传统聚类算法在处理大规模和高维文本聚类时存在的不足和局限性,提出了新的以LDA(latent dirichlet allocation)模型为基础的聚类方法。通过LDA主题模型挖掘得到文本之中的潜在主题分布以及不同主题内的词语分布,分别计算文本在“文本-主题”特征空间和“主题-词语”特征空间的相似度,然后对两者线性加权,获得最终的文本相似度。利用经典的K-Means算法,在中英文语料库上进行的实验表明,与单纯地利用VSM结合K-Means相比,具有较好的聚类效果。
关键词:LDA;向量空间模型;数据挖掘;文本聚类;K-Means
伴随着互联网近年来飞快的发展,图书期刊、企业和个人信息、政府报告、多媒体资源和社会新闻等数据的规模都在快速膨胀,而以上这些内容的基本呈现方式,大都是非结构化的文本。由于这些文本信息发布的类别和渠道非常庞杂,人们想要在其中快速准确地获取有效的信息变得十分困难,在花费了大量的时间和精力后往往也只是事倍功半。如何从这些海量文本中准确高效地获取人们真正想要得到的有用信息已成为目前迫切需要解决的问题。作为一种无监督机器学习方法,文本聚类算法已在文本自动整理、数字图书馆服务和检索结果的组织等方面获得了比较广泛的应用。因为事先不用对这些文本进行类别的手工标记,也无需训练过程,所以在文本的处理方面具有较高的简便灵活性,也日趋受到研究人员越来越多的关注。
在传统的文本聚类中,应用最广泛的文本模型当属向量空间模型(vector space model,VSM)。该模型是由Salton等[1]于1969年提出来的,其采用文本中的词作为特征项,将文本集构造成一个高维、稀疏的文本-词语矩阵。但是VSM模型将词语仅当成一个标量,忽视了其在文本中的内在含义,无法辨别同义和多义词。但在计算文本相似度时,同义词和多义词具有相当重要的作用。另外,由于文本和词语数量通常都特别巨大,直接采用VSM模型产生的矩阵不仅维度高且极度稀疏,计算效率较低,因此在聚类之前通常需要对文本-词语矩阵进行降维操作[2]。目前高维矩阵的降维有多种方法,如概念索引(concept indexing,CI)、基于矩阵奇异值分解理论的隐含语义分析(latent semantic analysis,LSA)[3],以及多元统计分析理论中的主成分分析(principal component analysis,PCA)等[4]。特征提取也是一种有效的降维方式,常用方法包括信息增益(information gain,IG)、卡方(chi-square,CS)、术语强度(term strength,TS)及互信息(mutual information,MI)等[5]。上面所介绍的算法都是基于大规模语料的,在统计学基础之上得到对文本类别具有较大作用的特征项,但是在特征选择过程中都没有考虑非结构化文本数据中的潜在主题信息,没有从词语的语义角度对文本所要选择的特征进行分析,因此在聚类效果上依然不是特别好。
近年来,一些学者开始研究利用LDA进行降维并将其应用于文本聚类中。郑诚等[6]使用LDA中的主题分布作为特征项,由于选取的特征项过少,在计算文本相似度时必然会丢失大量有效信息,对文本的区分力度也明显不够。王振振等[7]使用不同主题内词语的分布作为特征项,由于未考虑文本-主题之间的关系,对文本的区分度也存在一定影响。针对上述方法存在的缺陷,本文的特征选择是基于LDA主题模型,利用建模之后的“主题-词语”分布和“文本-主题”分布作为特征选择的结果,发掘出文本之中潜在的主题信息,将文本用主题表示,将文本中的词语映射到主题之中,分别计算文本在“文本-主题”特征空间和“主题-词语”特征空间的相似度,然后对其进行线性加权,得到最终的相似度结果。使用该方法,在文本聚类时能有效降低文本表示的维度,同时又能解决同义和多义词的问题。在中英文语料上进行的聚类实验表明,较其他聚类算法,本文所提算法的聚类结果更好。
1 研究与方法
1.1LDA概率主题模型
主题是一个较抽象的概念,表达了文本中的一种潜在主旨,一般采用词语相应于主题的条件概率分布描述。词语与主题关系越密切,条件概率就越大,相反的话就越小。概率主题模型通过统计文本中词的概率分布,确定每个词语在相应主题的概率,最终将文档表示成不同概率的主题集合。
作为概率主题模型的前身,潜在语义分析(LSA)提出了语义维度,打破了以VSM为主导的单纯以词频作为文本表示的模式,实现了文本在低维空间上的隐含语义表示。其通过奇异值分解(singular value decomposition,SVD)构造一个新的隐形语义空间。它把非结构化的文本量化为将词语作为向量空间维度中的一个点,假设在此空间之中的文本都包含特定的语义,且并非无规律分布。自然语言的文本是由一个个词语构成的,这些词语又是在相应的文本当中去理解它们的真实含义,因此这里体现了一种“词语-文本”的双重关系。但LSA在处理同义词问题上效果仍然不是很理想,且由于SVD的计算时间较长,算法效率方面往往无法保证。另外,在最终的结果矩阵中存在结果在很多维度上是负数,对此并无相应的物理解释。20世纪90年代后期,Hofmann等[8]在LSA的基础上提出了概率潜在语义分析(probabilistic latent semantic analysis,PLSA)算法,与LSA有着类似的思想,在PLSA模型中同样也加入了一个隐含的变量层,但其是以概率的形式来说明LSA的问题,大致思想是把文本和词语同等对待,将语料库中的每一篇文本和词语映射成一个维度不高的语义空间中的一个点。经过这一处理,既可以解决矩阵维度过高的难题,又可以将文本中词语和词语间的内在联系构建出来,而且在该语义空间上几何距离越接近的词语,它们的语义也就越接近,它在一定程度上可以缓解文本模型中“一词多义”的问题。但PLSA最大的缺点就是其在文本层缺少了数学中的概率模型,使得算法过程中的参数数量会随着文本数量的增多而增加,很容易出现过度拟合的问题。Blei等[9]通过引入狄利克雷先验分布扩展了PLSA模型,克服了PLSA在文本表示时的种种不足,即LDA概率主题模型。
在LDA概率主题模型中,首先需介绍“文本集”、“文本”和“词语”的概念,以此表示文本类的数据,其定义如下:
1)词语数据集中的基本单位,可以由数据集中的词表序列{1,2,…,V}选取,用w表示,并且w∈{1,2,…,V}。
2)文本由N个词语所构成的组合,用w表示,其表达式是w =(w1,w2,…,wn),这里wn指的是文本之中的第n个词语。
3)文本集由M篇文本所构成的文本语料库,这里用D表示,其表达式是D =(w1,w2,…,wm),其中wm指的是文本集之中的第m篇文本。
LDA的主要思想是把文本集中的每一篇文本表示成主题这一变量的分布,对于每一个潜在主题,则利用词语的概率分布来表示。这里,Blei有着如下的假设:①狄利克雷分布的维数和文本集之中主题的数量一致,这个K是固定和已知的;②文本中主题与词语上的概率用参数矩阵β来表示,这其中每个元素代表的是主题zi于词语wj上的概率(在文中,变量的下标表示的是这个变量在文本集之中的序号,变量的上标代表的是这个变量的取值范围或值,如这里的zi代表的是主题z的值是i),而且这个参数也是固定的。
依据上面的假设,可以得到文本主题的分布参数θ、文本d中主题z和Nd个词语w在已给定参数α和β的情况下的联合分布概率为

对式(1)在θ上求积分并且在主题z上求和,可得到边缘概率分布如下

利用式(2)可求得文本集之中所有文本的边缘分布概率,进而求得文本集D的概率分布为
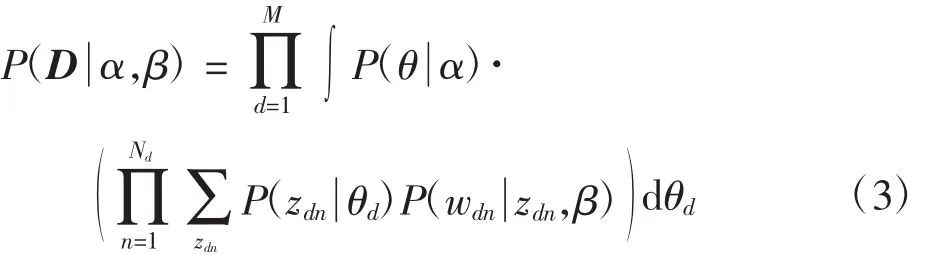
图1是LDA的概率图模型,从中可知LDA是一个三层模型:参数α和β都是文本集层的参数,只有等所有文本集都生成完成后才会更新一次;变量θ指的是文本层的变量,当每一篇文本生成结束之后就会更新;而变量z和w都是词语层的变量,每个词语的生成就表示它们要更新一次。
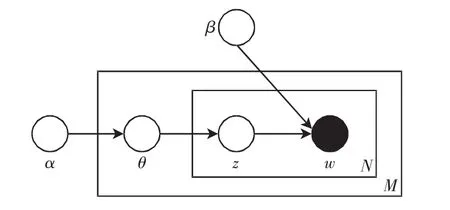
图1 LDA概率图模型Fig.1 Probability graph model of LDA
因为上式含有多个隐变量,直接通过推导求出会十分困难,因此需要得到其近似解。本文选用更好的Gibbs抽样来求解参数,下面详细介绍Gibbs抽样算法。
1.2Gibbs抽样
按照Blei在LDA模型中的假设,Dirichlet分布的参数α和主题分布的参数β在文本的生成过程中是固定值,所以针对某一个文本d而言,其隐含变量后验概率分布为
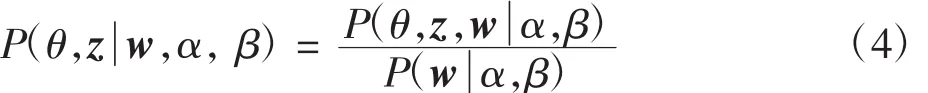
在此,按照贝叶斯理论可得到

这里P(z)只与参数θ相关,而P(w z)只与参数φ相关,所以在参数θ和φ上分别积分,得到
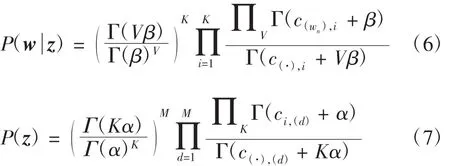
其中:c(·),i表示文本中的所有词语属于主题i的数量;表示所有文本集中词语wn属于主题i的数量;c(·),(d)表示当前d中全部主题出现的数量;ci,(d)表示当前d中主题i出现的次数。然而式(4)中的P(α,β)仍然不能求得,它与文本集中全部词语的主题分布情况相关。
故可把文本集中的全部词语视作离散的变量空间,这其中每个变量的状态可从主题集合中选取,进而构建了马尔可夫链,再依据P(θ,φw,α,β)对所有的变量采样,在马尔可夫链稳定后,对其中的所有变量状态进行统计,可根据最终的统计量来估计目标概率的分布。
在更新链的状态时,可以采用Gibbs抽样方法[10],这里需计算P(z-n, w)。针对文本d中的第n个位置上的词语,其条件概率分布为
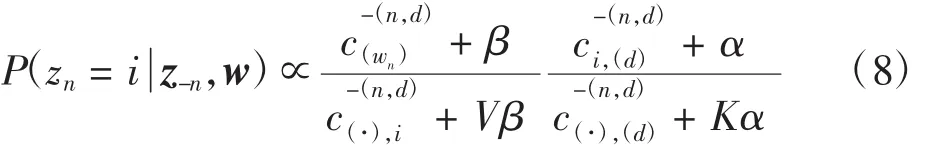
其中:i表示主题的编号,i∈{1,2,…,K};统计量c的下标表示此统计量之中样本的条件,上标指的是此统计量之中样本的范围;(·)代表在对应维度上的元素全集;-(x)表示在对应维度上取x的补集,所以这里的表示除了第d篇文本之中第n个位置的词语所属于的主题之外,文本集中剩余词语被赋予主题i的数量,其余统计量的定义与此类似。这里,式(8)的前半部分表示的是词语wn从属于主题i的概率,后半部分表示的是文本d中主题i的概率。这两部分分别对应于本文所论述的“主题-词语”分布和“文本-主题”分布。
详细采样过程如下:
2)按照均匀分布,在[0,1]之中随机选取一个值P 且0<P≤1;
3)按照P在P(i)上属于的变量值当做新的主题。
而Gibbs采样的更新步骤如下:
1)初始化马尔可夫链的初始状态zi,其取值范围是{1,2,…,K};
2)按照式(8)的概率分布更新所有zi;
3)多次迭代后,当马氏链稳定之后,这时的目标分布达到收敛,此刻zi的取值就是最终分布的随机变量的样本。
利用这时的zi估算LDA中的参数,其表达式为
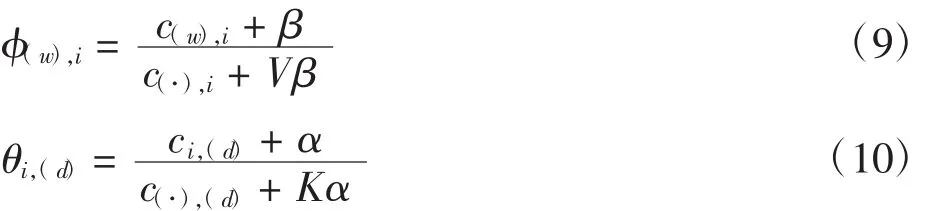
通过这些参数,可以预测新文本中词语w在已有w和z的前提下对应的主题z和它的后验分布。
1.3加权LDA的文本建模
1.3.1语料选择
为验证算法的有效性,本文分别在中文和英文语料集合上对算法进行了试验。其中,英文语料使用的是20-News-Group语料库,特别选取了其中的10个类:comp.graphics,comp.sys.ibm.pc.hardware,motorcycles,rec.sport.baseball,rec.sport.hockey,sci.electronics,sci. med,sci.space,soc.religion,talk.politics.guns。每个子类分别取500篇文档,共5 000篇。中文语料使用的是复旦大学中文语料库,选取了其中的10个子类:Agriculture,History,Space,Sports,Politics,Environment,Economy,Computer,Education,Law。每个子类选取了100篇文本,一共1 000篇。
1.3.2LDA主题数的选择
主题数目K的确定对于LDA模型的准确率至关重要。通过LDA的建模过程可知,多项分布θ和φ的狄利克雷先验分布的参数分别对应于α和β,通过其自然共轭的性质,P(w,z)的值可以通过对θ和φ积分计算得到。P(w,z)= P(w|z)P(z),并且φ和θ单独出现于第一项和第二项,对φ积分获得第一项值为[11]


其中,M为Gibbs抽样算法迭代次数。
1.3.3文本相似度计算
LDA主题模型是在统计学基础上,通过文档集的潜在信息,将文档映射到基于隐含主题的特征空间上,并且将主题映射到词语的特征空间上。VSM模型首先是基于词频统计的理论,利用文本中词语的TFIDF值在向量维度上对2篇文本进行相似度计算。TFIDF思想中的IDF理论从本质上来讲是一种有效的在文本表层知识方面抑制噪声的加权处理方法,虽然在相似度计算上可以取得不错的效果,但同时由于只是在词表层方面对文本进行探究,必然会丢失掉大量文本的深层语义信息。另一方面,利用LDA主题模型挖掘得到文本内部的潜在主题知识,在一定程度上弥补了前者在相似度计算方面的不足,但由于文本映射到主题空间的维度相对较低,导致在计算时文本信息的完整性很难保证,进而对于文本类别的区分能力显得不够。所以,本文把以上二者进行有机结合,在文本词语和潜在主题两个不同层次计算文本之间的相似度。由于考虑了各自模型的优势,弥补两者的不足之处,进而保证了最终文本聚类的质量。
在主题-词语这个特征空间上,对每一个主题选择前N(本文实验取N=100)个特征词,计算每一个特征词在整个文档集中的TF-IDF权重,再结合文档-主题这个特征空间,利用线性加权求和的方法,将其进行结合,从而有效地提高计算文本相似度的质量。
文档di在主题-词特征空间上的向量可表示为di_LDA1=(w1,w2,…,wn),其中n为从所有K个主题中所选择的词汇数量。则文本di、dj基于主题-词特征空间的余弦相似度为
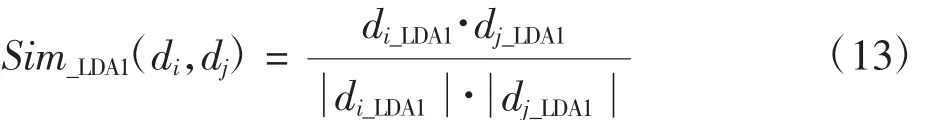
文档di在文本-主题特征空间上的向量可表示为di_LDA2=(z1,z2,…,zK),其中K表示主题的个数。则文本之间基于文本-主题特征空间的余弦相似度为Sim_LDA2(di,dj)。本文将这两种相似度进行线性融合,计算公式为

其中λ∈(0,1)为线性参数,表示主题-词模型和文档-主题模型按一定比例的加权求和。
2 结果与分析
本文选用经典的K-means聚类算法,用F值来作为最终实验好坏的评价指标。F度量值是将实验的准确率和召回率联合起来对实验结果进行评估的综合性指标。其中,准确率P(i,j)和召回率R(i,j)可分别定义为

其中:nij是聚类j中隶属于类别i的文本数目;ni是类别i的文本数目。对应的F度量值定义为

全局聚类的F度量值定义为
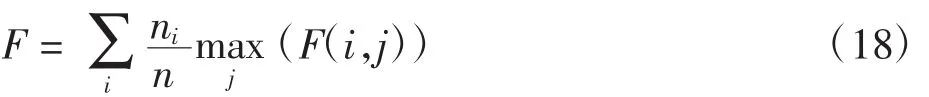
2.1实验步骤
在对文本进行LDA建模前,先要对语料库中的文本进行相应的处理,这里包括去停用词以及对于中文语料的分词,进而将文本表示为词向量的形式。由于LDA主题模型使用的是词袋模型,因此在对中文语料进行分词操作之后,中英文语料的建模过程是基本相同的。在建模过程中,使用Gibbs抽样算法得到实验过程中需要的参数,具体设置为α= K/50、β=0.01,Gibbs抽样次数为2 000。实验中的λ值依次从0.01取到0.99,经过多次实验,当λ为0.85时聚类质量最高。通过实验研究了主题数目K对Gibbs抽样算法的影响。当K取不同值时分别运行Gibbs抽样算法,观察-logP(w|K)值的变化。在英文语料上的实验结果如图2所示。
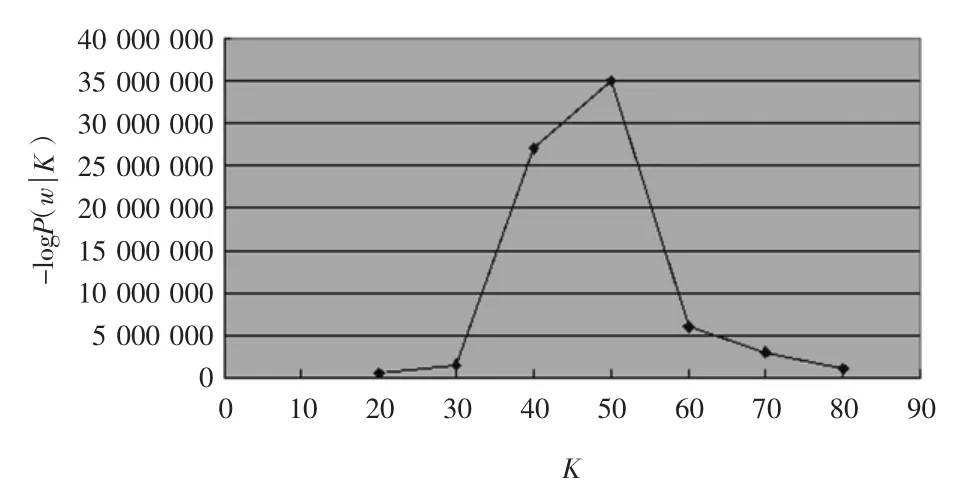
图2 英文语料-logP(w|K)与K的关系图Fig.2 Relationship of topic number K and -logP(w|K)
由图2可以看出,对于20-News-Group英文语料,K值取50的时候,-logP(w|K)的值最大,证明这时文本集中对于信息的有效程度拟合达到最优。同理,经过实验得知复旦大学中文语料当主题数K取80的时候-logP(w|K)的值最大。因此后续实验英文语料和中文语料主题数K的值分别取50和80。
2.2实验结果及分析
当确定最优主题数后就利用LDA模型对文本进行聚类。实验结果如图3和图4所示。
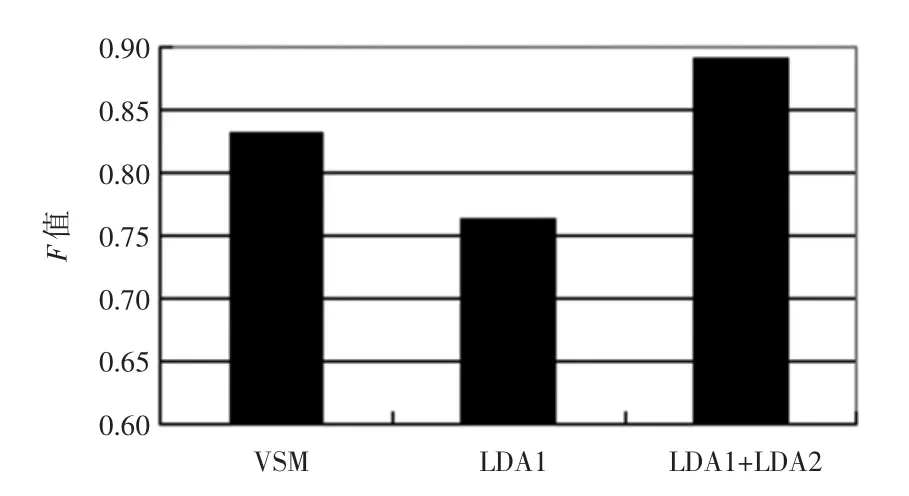
图3 20-News-Group英文语料基于平均F值的比较结果Fig.3 20-News-Group English corpora comparison based on average value F
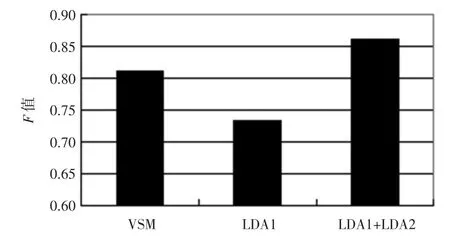
图4 复旦大学中文语料基于平均F值的比较结果Fig.4 Fudan University Chinese corpora comparison based on average value F
图中的VSM指将文本集中所有不同词语作为特征时的文本聚类结果;LDA1指仅利用文本-主题这一特征空间作为特征项时的聚类结果;LDA1+LDA2指将文本-主题和主题-词语这2个特征空间联合起来作为特征项时进行的文本聚类的结果。
从图中可以看出,单独使用文本-主题特征空间进行聚类效果很差,这是因为K比较小,选取的特征值数量不够。而将文本-主题和主题-词这两个特征空间联合起来作为进行聚类却可以明显地提高F值,比单独使用VSM结合K-means提高了近5%,获得了较好的聚类效果。
3 结语
通过将LDA主题模型与传统的文本聚类方法有效结合,在原来单纯的以词频为基础的空间向量模型中加入了文本的深层次语义知识,利用本文方法具有以下优点:
1)可以明显地提高文本相似度的计算准确性。
2)本文通过LDA对文本进行建模,使文本映射到“文本-主题”和“主题-词语”这2个特征空间中,一方面增强了向量表示文本的语义含义,另一方面大大缩小了文本表示的向量维度。
3)由于在文本聚类时加入了文本的潜在主题,使聚类效果有了明显的提高。
4)中英文语料库的对比聚类实验证明,本文算法结果要好于单纯使用VSM模型的聚类结果。
参考文献:
[1]唐果.基于语义领域向量空间模型的文本相似度计算[D].昆明:云南大学,2013.
[2]孙昌年,郑诚,夏青松.基于LDA的中文文本相似度计算[J].计算机技术与发展,2013(1):217-220.
[3]DEERWESTER S,DUMAIS STA. Indexing by latent semantic analysis [J].Journalofthe Societyfor Information Science,1990,41(6):391-407.
[4]高茂庭,王正欧.几种文本特征降维方法的比较分析[J].计算机工程与应用,2011,42(30):157-159.
[5]王刚,邱玉辉,蒲国林.一个基于语义元的相似度计算方法研究[J].计算机应用研究,2008(11):3253-3255.
[6]郑诚,李鸿.基于主题模型的K-均值文本聚类[J].计算机与现代化,2013(8):78-80,84.
[7]王振振,何明,杜永萍,等.基于LDA主题模型的文本相似度计算[J].计算机科学,2013,40(12):229-232.
[8]HOFMANN T. Unsupervised learning by probabilistic latent semantic analysis[J].Machine Learning,2001,42(1):177-196.
[9]BLEI D,NG A,JORDAN M. Latent dirichlet allocation[J].Journal of Machine Learning Research,2003(3):993-1022.
[10]GRIFFITHS T L,STEYVERS M. Finding scientific topics[J]. PNAS,2004,101(1):1137-1145.
[11]石晶,胡明,石鑫,等.基于LDA模型的文本分割[J].计算机学报,2008,31(10):1865-1873.
(责任编辑:杨媛媛)
Text clustering method based on weighted LDA model
LI Guoa,b,ZHANG Chunjiea,b,ZHANG Zhiyuana,b
(a. College of Computer Science and Technology;b. Airport Engineering Research Base,CAUC,Tianjin 300300,China)
Abstract:In order to overcome the shortcomings and limitations of traditional clutering algorithms in dealing with largescale and high dimension text clustering,a text clustering method is presented based on weighted LDA(latent dirichlet allocation)model. Two distributions are obtained by LDA: the topic distribution and the word distribution of different topics hidden in the text,which are then combined as the text feature to obtain the final text similarity. Using the classic K-Means algorithm in both English and Chinese corpus,the experimental results show that compared with the pure VSM combined with K-Means,this algorithm has better clustering effect.
Key words:LDA;vector space model;data mining;text clustering;K-Means
中图分类号:TP18
文献标志码:A
文章编号:1674-5590(2016)02-0046-06
收稿日期:2015-04-01;修回日期:2015-04-23基金项目:国家自然科学基金项目(61201414,61301245,U1233113)
作者简介:李国(1966—),男,河南新乡人,教授,博士,研究方向为智能信息处理.
