大数据背景下智能手机APP组合推荐研究
2016-06-29吕晓玲
程 豪,吕晓玲,钟 琰,范 超,赵 昱
(1.中国人民大学 应用统计科学研究中心,北京 100872;2.美国哥伦比亚大学 梅尔曼公共卫生学院,纽约 10032;3.中国人民大学 a.统计咨询研究中心,b.统计学院,c.数据挖掘中心,北京 100872;4.国家统计局国际统计信息中心,北京 100826;5.QuestMobile&人大统计移动互联网大数据研究院,北京 100015)
大数据背景下智能手机APP组合推荐研究
程豪1,2,3a,3b,3c,吕晓玲1,3b,3c,5,钟琰3b,3c,范超3b,4,赵昱5
(1.中国人民大学 应用统计科学研究中心,北京 100872;2.美国哥伦比亚大学 梅尔曼公共卫生学院,纽约 10032;3.中国人民大学 a.统计咨询研究中心,b.统计学院,c.数据挖掘中心,北京 100872;4.国家统计局国际统计信息中心,北京 100826;5.QuestMobile&人大统计移动互联网大数据研究院,北京 100015)
摘要:面对当下智能手机APP种类繁多、层出不穷的局面,数据提取方案的提出和常见APP组合规律的深度挖掘已成为大数据时代的研究热点。在重新界定不同APP类别间关系度量方式的前提下,推出一套完整的关系型数据提取方案。借助社会网络可视化工具初步发现了不同APP类别间的关系程度及分布,而concor模型为APP组合的多层次划分和推荐提供了可靠的方法学依据。研究发现APP的多层次组合划分实现,对现实生活中经常同时使用的APP类别组的挖掘、划分结果具有较好的解释性和现实意义,为智能手机生产者提供了APP研发方向,并能推进智能生产和生活的发展进程。
关键词:智能手机;APP应用程序;组合多层次划分;推荐研究
一、引 言
作为大数据时代的研究热点,智能手机海量数据的深度挖掘往往关注于用户行为信息研究方面[1],比如Pablo根据行为理解提炼出用户行为模式[2];Leskovec等人在考虑时间因素下讨论了社交关系[3];David等人根据地理信息完成服务推荐研究等[4]。尽管智能手机APP具有与人们的生活联系紧密、信息资源丰富、不涉及用户私密行为信息等特点,但APP应用程序的相关研究仍较为空缺。
综观大数据网络关系研究方法,社会网络分析方法的相关研究成果为解决APP组合推荐问题提供了借鉴和参考。彭小川等人应用社群图和矩阵法概括了BBS群体的基本特征,并对群体中成员地位的形成、意见领袖的特点和群体内部人际交往的特征进行了探讨[5];S. Parthasarathy, Y. Ruan和V. Satuluri引入了社会网络分析理论而非传统的聚类方法,通过研究节点及节点间的连接情况,分析同一社区内的网络结构关系,并进一步研究了社区内成员的亲属关系。同时,Smriti Bhagat, Graham Cormode和S. Muthukrishnan探讨了结点分类(node classification)问题[6]79-146。
HTML5是HTML规范的当前最新版本,同时也是一系列Web相关技术的总称,其中最重要的3项技术就是HTML5核心规范、CSS3(Cascading Style Sheet,层叠样式表的最新版本)和JavaScript(脚本语言的一种,用于增强网页的动态效果)。
面对不同种类APP应用程序的不断涌现,利用网络信息定义一种全新的关系测度方式(权重),提出一套清晰合理的智能手机监测数据及APP关系型数据的提取方案,实现APP组合规律的深度挖掘,并对业界提供一些实用的合理化建议,已成为一项鲜有人尝试却颇具价值的研究课题。
综上所述,对于工程造价信息化建设工作的落实,其在当前确实表现出了较强的发展作用价值,相对于传统工程造价管理模式具备多方面优势,这也就需要加大推广力度,详细分析探究现阶段存在的各个方面问题,然后采取有效措施予以解决。
二、关系型数据提取方案
(一)数据简介
1.选择优良苗种,加州鲈鱼苗的质量会直接关系到自身的抗病能力,选择健康优质的种苗,可以提高育苗成活率和提高鱼仔活力和健康指数,从而为后期的成鱼养殖提供可靠的保障,使加州鲈养殖效益提高。
本文数据来自QuestMobile智能设备混合数据池,为智能手机监测数据。该数据横跨2015年2月1日到5月17日共106天,涉及13余万安卓系统用户。数据总量高达1.8T,包括用户地理位置信息(个人ID、记录时间、地点等)、手机型号信息(品牌、型号、分辨率、尺寸等)、手机APP使用信息(个人ID、使用APP名、APP包名、使用起止时间、使用时长、上下行流量等)三部分。所有数据以日为单位,依据用户即时行为生成,所有内容记录在4张表中,用户行为信息较为混杂。仅以个人ID作为唯一标识,且在时间上并不具备一一对应性。易知,该数据具备数据量巨大(Volume)、增长速度快(Velocity)、内容多样化(Variety)、价值密度低(Value)的4V特征。手机APP使用信息数据(记录在Sessiong表中)包含个人ID、使用APP名、APP包名、使用起止时间、使用时长、上下行流量等APP使用的详细记录,其中APP类型涵盖网络购物、本地生活、网络视频、汽车服务、新闻资讯、通信聊天、系统工具、主题美化、网络金融、数字阅读、网络音乐、教育培训、丽人母婴、实用工具、图像服务、网络社交、旅游出行、健康医疗、效率办公、游戏等方面的20类上万种APP。
(二)方案设计
STEP3:经多次迭代,得到一个元素只有1和-1的矩阵,记为Cn。
在提取APP关系型数据之前,本文以Python为工具[7],选择用户使用时间作为反映APP偏好或受欢迎程度的依据,提出一种界定不同APP类别间关系的度量方式,即APP社会网络中的权重。用矩阵W=(wij)20×20表示20类APP关系型数据,即为测度APP间关系的权重矩阵。显然,M为对称阵,行和列均表示APP类别(20类APP出现的顺序见数据简介)。其中第i行、第i列表示在106天内所有用户在第i类APP上花费的总人次天数;第i行、第j列表示第i类APP与第j类APP被一个用户在一天当中同时使用的总人次天数。APP关系型数据的提取流程如下:
STEP1:由于数据中APP种类繁多,数量过万,很多APP仅有极少数人使用。因此,本文利用额外的信息对APP进行打标签处理,挑选出5 000个相对热门的APP,将其分为数据简介中所示的20类为代表。
学生审题能力在“趣味四部曲”中悄然提升,相信其他方面的学习如果能紧紧抓住“趣味性”这一主线,一定可以让学生在轻松、愉悦的氛围之中主动学习并掌握。
STEP2: 对每天每个用户的APP使用时间,依照APP使用分拣表进行分类汇总,得到每一天存在记录的用户使用每种类别的APP的使用时间。
STEP3:统计每一天内每类APP的使用人数以及同时使用每两类APP的人数。
STEP4:将106天的每类APP及每两类APP使用人数加总,并用矩阵形式存储,得到106天的使用人数矩阵。
STEP5:对矩阵中各元素取自然对数,作为最终由20类APP构成的关系型数据。
三、APP多层次划分的方法选择
因此,需要对“派系”进行推广,通过设定节点间的最大距离n,产生n-派系。n-派系存在一定应用层面的局限性。第一,当n等于2时,可以直接解释有共同中间节点的关系;但当n大于2时,尽管节点间相对较弱的关系可能对网络的总体结构非常重要,但具体意义还不是很清晰。第二,n-派系的直径有可能大于n。虽然n-派系要求各个节点间通过长度不超过n的路径连接在一起,但并不能保证这些路径仍然保留在子结构之中。第三,一个n-派系可能包含n-派系外的点,即可能是一个不关联图。因此,n-派系往往不是一个具有较高凝聚性的凝聚子群。
APP组合的形成过程实际上是APP多层次划分的过程,即以所有APP为网络节点,根据节点间关系信息,将整个网络中的所有节点进行重排,划分为多个子结构,再对子结构进行凝聚,形成规模较大的子结构集合。这种“先划分再凝聚”思想的实现,需要以社会网络分析理论为基础,借助“凝聚子群分析”和“网络与角色的对等性思想”来完成[8]148-265[9]5-25。早期的社会网络学者在霍桑工厂和杨基城报告中曾涉及到“派系”的思想,在无向关系网络中派系(至少包含三个点的最大完备子图)中的任何两点都必须彼此邻接,不能间接相连,且不能被其他派系所包含。作为凝聚子群分析中最早提出的概念,派系分析具有如下四个相互关联的局限性:第一,由于去掉派系中的任何一个关系,都无法称为派系,因此定义过于严格导致网络结构的划分常常不够稳定;第二,派系的规模会受到点度数的限制,即如果网络中任一个节点至多与其他节点存在k个关系,那么不可能包含超过k个节点的派系;第三,现实中出现的派系常常规模太小,并且重叠很多,对于大规模或稀疏型网络,派系的概念就失去意义;第四,派系内节点没有任何分化,即同一个派系中的节点在图论的意义上都是等同的。此外,派系建立在节点间邻接基础上,忽视通过间接关系建立的小结构。
晏殊长期以来得不到公正、合理的评价,受到严重的“污名化”,与大量真相被严重遮蔽或者错误释读有关之外,传统的君子小人、非白即黑以及党争思维方式,也具有相当大的负面影响。
STEP4:重排Cn,得到矩阵分区,即“块”。
网络密度、点与图的中心度等量化指标有助于研究者结合知识图谱深度解读正念疗法领域研究议题的总体概况及内部构建。网络密度映射网络成员间的联系强弱度,密度值越大,网络成员间关系越密切[16]。网络密度越接近1说明网络联系越密切。图3共现网络密度为0.8658,标准差为1.6837,密度程度较强。由图3得知正念、正念训练、心理健康处于核心位置,与其联系的关键词众多,同时位于网络图中心的关键词同周围关键词连线较多且粗,网络边缘关键词间的联系却较弱。
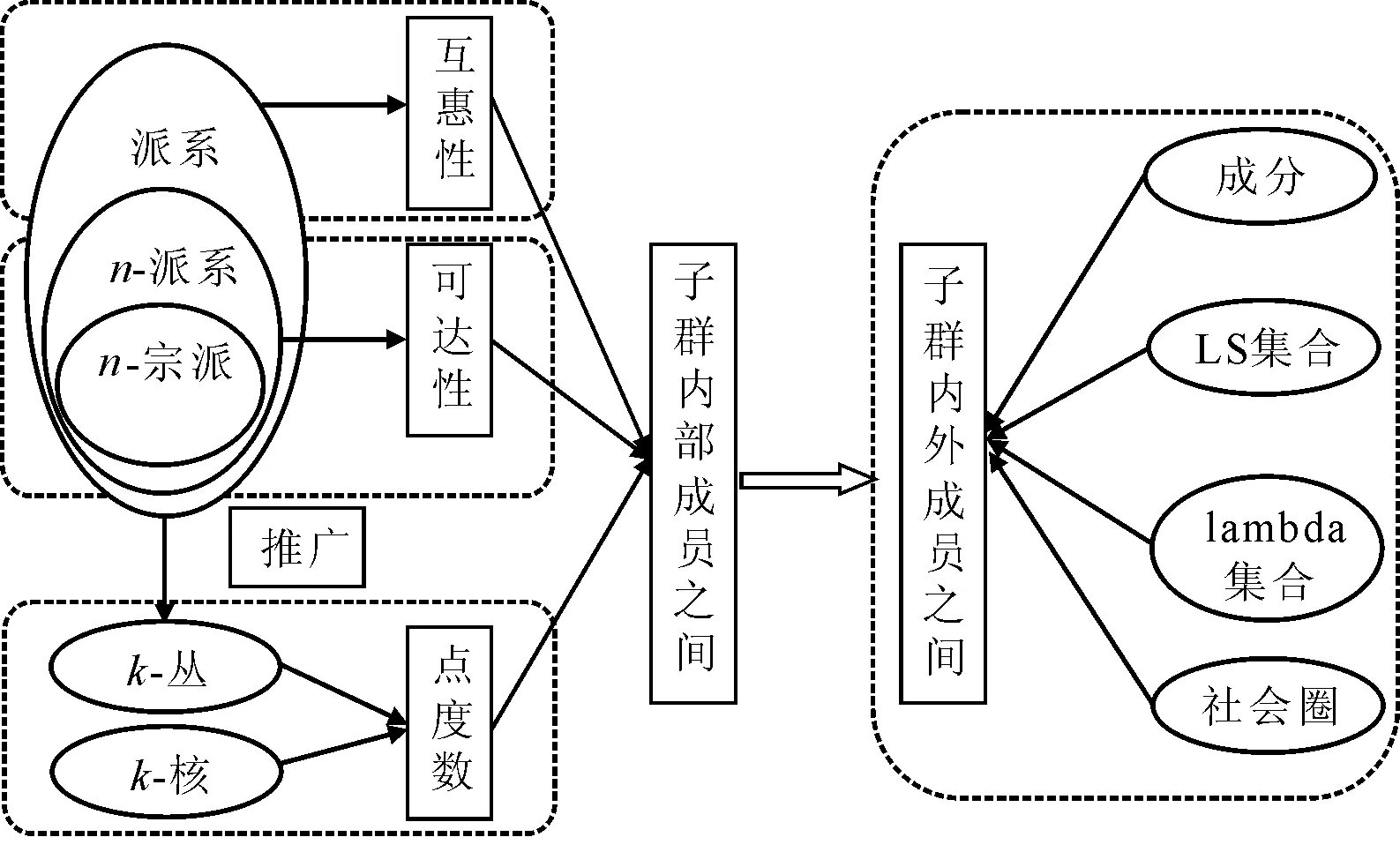
图1 基于凝聚子群分析的多层次结构划分方法结构图
刘佳骑着一只破旧的木马,白净的脸上泛着腼腆的红晕,这是他第一次当新郎倌,说话都有些结巴。我看得眼睛都直了,直接从许飞的背上跳下来,冲到他面前撅着嘴往他嘴上叭唧亲了一口。
因此,在基于凝聚子群分析的多层次结构划分方法中,当只关注子结构内节点间关系来进行多层次结构划分时,n-宗派和k-核均为较理想的方法。当需要兼顾子结构内节点间关系强度或频次相对于子结构内、外节点间关系强度或频次时,lambda集合则较为理想,但由于lambda集合没有对同一个子结构中的节点间距离进行限定,所以划分到同一个子结构内节点间距离可能很远。
在此,需要从对等性思想的角度考虑一些不同的方法。网络与角色的对等性思想本质上关注社会网络研究中的“相似性”,至少包含“结构对等性”、“自同构对等性”、“规则对等性”三种不同的类型[12]。结构上对等的行动者在任何结构属性(比如度数)上都相同,则可以相互替代。以截面相似性(即邻接矩阵中行和列的信息)可以说明节点间关系,截面相似性的具体测度方法包括对比法、相关法和欧氏距离法等。自同构对等性要求当两个节点相互替换位置时,允许所有其他节点都调换位置,且保证网络的性质不改变,而测量自同构对等性包括测地线对等性、Maxism算法、Tabu搜索法等方法。Sailer提出的规则对等性要求一系列节点的对等性,现实世界的网络在节点对等性的定义上往往不满足自同构对等性和规则对等性的假定,因此需要根据结构上的对等性,构建结构对等性矩阵,矩阵中第(i,j)项表示节点i和j的截面相似性测度。图2清楚展示出基于对等性思想的多层次结构划分方法及其间的关系。
R.J.Mokken提出的n-宗派,是对n-派系概念的推广。n-宗派和n-派系最主要的区别在于对“距离”的理解:n-派系中的“距离”指两点在整个网络中的距离;n-宗派是指两节点在子结构中的距离,由此可知n-宗派比n-派系的概念更加严格。与n-派系相似,k-丛实质上也是对派系概念的一个推广。Seidman和Foster观察到n-派系常常不稳健,即去掉网络中一个或几个点后,网络结构会受到很大影响。与n-派系相比,k-丛更能体现凝聚力的思想。k-核与k-丛不同,k-丛则要求各个节点都至少与k个点之外的其他节点相连,而k-核则要求任何节点至少与k个点相连[10]。k-核的优势在于研究者可以自行决定k值的大小,从而发现一些有意义的节点组合。虽然k-核不一定具有高度凝聚力的指标群体,但是仍然表现出与派系类似的性质。如果整个结构可分为几个子结构,每个子结构内节点存在关联,但各子结构间没有关联,则称为成分。通过图1可以更清楚地展示出基于凝聚子群分析的多层次结构划分方法及其之间的关系。

图2 基于对等性思想的多层次结构划分方法结构图
作为研究网络位置模型的方法之一,块模型最早由White,Boorman和Breiger提出,是对社会角色的描述性代数分析,可以更好地理解各个节点及所属结构间异同点。一个块模型包含两部分:第一,按照一定标准,把一个网络中的各个节点分成几个离散的子结构,称为“块”;第二,考虑每个“块”之间是否存在关系。块模型就是一种关于多元关系网络的假设,所提供的信息是关于各个“块”之间的关系,而不是每个节点间的关系,因此研究的是网络的总体特点,而且每个“块”中的各个节点都具有结构对等性。Concor模型是块模型最常用的方法,其多层次划分结果的可视化成为该方法的一大优势,其基本算法思想如下:
STEP1:计算矩阵各行(列)间的相关系数,得到相关系数C1。
STEP2:输入C1,继续计算各行(列)间的相关系数,得到C2。
其验证流程也十分简明,客户端使用用户凭据登录系统,服务器验证通过后,依据上述规则生成jwt 返回给客户端。客户端之后在向服务器请求时,通过header 中的Authorization 字段以Bearer 形式携带此token 来发送至服务器端验证身份和权限。一般的token流程可以由图2 来表示,申请为1~2 步骤进行,请求资源以3~6 步骤进行。
由于水泥砂浆需要凝固时间,因此有必要对渗透胶浆进行一定的养生[3]。当施工气温在30℃以下时,不需要特殊的养护方式,只需常温下养护2~3d即可;而当施工气温在30℃以上时,需要采用塑料薄膜进行覆盖养生。如在砂浆中使用的是早强水泥或掺加了早强剂,则可在养护数小时砂浆硬化后开放交通[2]。
首句透露了诗人失偶的痛苦而点到即止,立即援引荀息、屈平典故,转向对丈夫节行的表彰,体现出作者的深明大义。当然,商景兰不可能将全部的心绪都反映在这首广为传诵、具有公众性的悼亡诗中,但诗中欲语还休、隐隐透出的怨意,已经奠定了她后半生诗作的感情基调。
STEP5:经多次迭代,得到concor树形图,展示多层次划分结果。
四、APP多层次划分的实现
(一)APP信息可视化初探
然而,上述方法都是根据子结构内部节点间关系来完成对节点进行多层次结构划分的。Alba指出,一个结构既要重点关注结构内部的关系,又要比较结构内部节点间相对于结构内、外节点间的关系强度或频次。LS集合要求子结构内节点间关系相对较紧密,但与其他子结构节点关系相对较小。Borgatti等人推广了LS,提出了Lambda集合,其重要性质是集合中的点不一定具有凝聚性。因为Lambda集合对各节点间距离不加限制,所以同一子结构中各个节点间可能距离很远[11]。
20类APP的关系型数据W中,{wij,i,j=1,2,…,20}表示关系强弱,称为权重。经统计,权重最大值为16.4,最小值为7.6。最大值位于W第6行第6列的w66,表示通信聊天的总人次天数的自然对数;最小值位于W第12行第18列的w12,18,表示教育培训与健康医疗通信聊天被一个用户在一天当中同时使用的总人次天数的自然对数。根据权重取值,从[7.00,16.4)、[8.00,16.40)、[9.00,16.40)、[10.00,16.40)、[11.00,16.40)、[12.00,16.40)、[13.00,16.40)、[14.00,16.40)、[15.00,16.40)、[16.00,17.00)10个权重限定条件下,绘制10个20类APP社群图(见图3)。

图3 20类APP社群图
为了清晰展示不同权重限制条件下社群图的变化情况,图3只展示了部分APP社群图。不难发现,20类APP间确实存在不同程度的关系,随着权重的增加,APP社群图结构越来越简洁。20类APP海量信息的可视化初探,为APP组合的多层次划分提供了可能和基础。
(二)APP多层次划分全程
根据Concor模型可以完成对20类APP的多层次划分,划分全程及结果如图4所示[13]13-26。
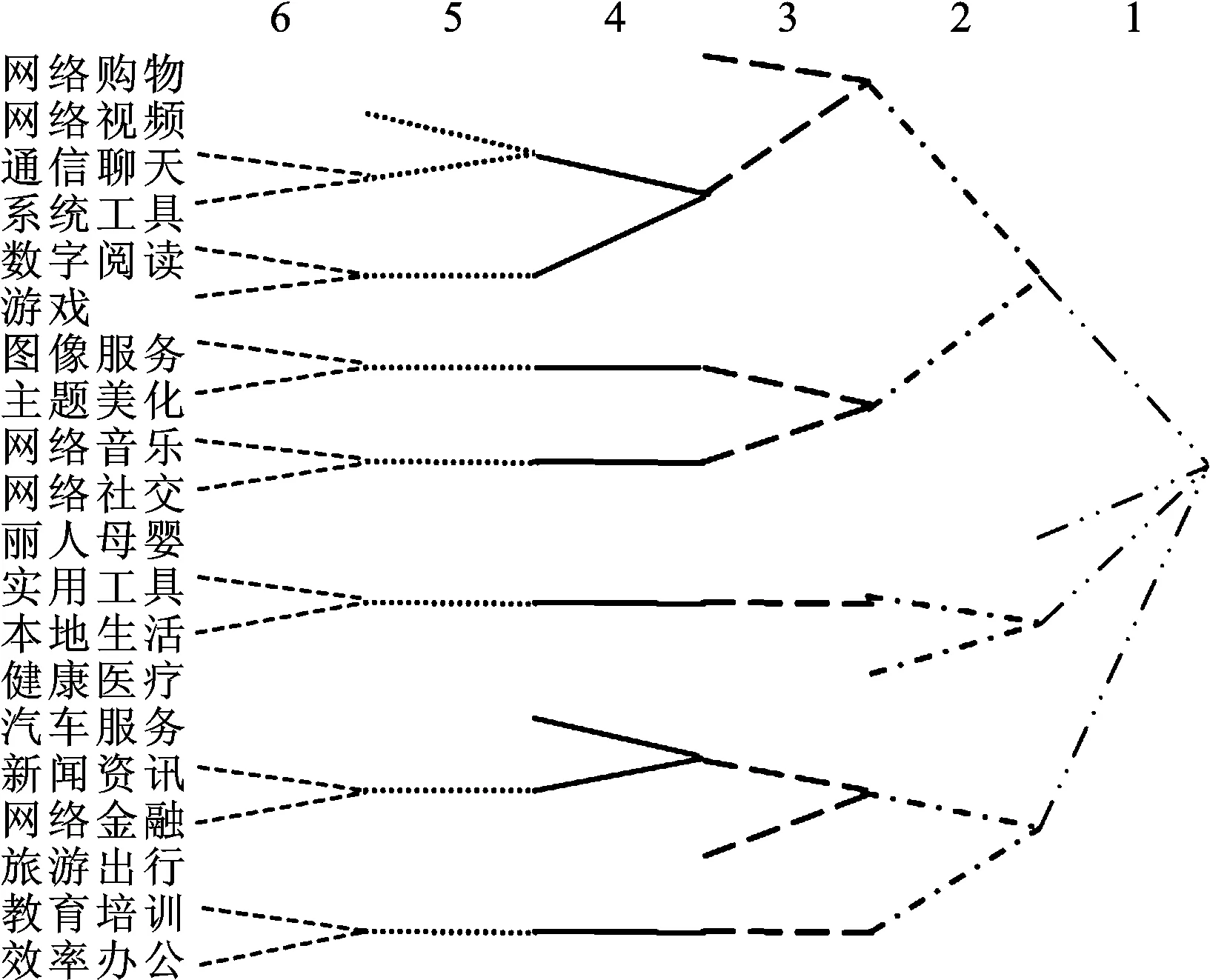
图4 Concor树形图
图4由右到左实现了APP类别组合由粗到细的划分(层数为6时的划分为可实现的最大程度的划分)。显然,当层数为1时,所有APP类别属于同一组合;当层数为2时,APP类别组合情况为:{(网络购物、网络视频、通信聊天、系统工具、数字阅读、游戏、图像服务、主题美化、网络音乐、网络社交),(丽人母婴),(实用工具、本地生活、健康医疗),(汽车服务、新闻资讯、网络金融、旅游出行、教育培训、效率办公)};当层数为3时、APP类别组合情况为:{(网络购物、网络视频、通信聊天、系统工具、数字阅读、游戏),(图像服务、主题美化、网络音乐、网络社交),(丽人母婴),(实用工具、本地生活),(健康医疗),(汽车服务、新闻资讯、网络金融、旅游出行),(教育培训、效率办公)};当层数为4时、APP类别组合情况为:{(网络购物),(网络视频、通信聊天、系统工具、数字阅读、游戏),(图像服务、主题美化),(网络音乐、网络社交),(丽人母婴),(实用工具、本地生活),(健康医疗),(汽车服务、新闻资讯、网络金融),(旅游出行),(教育培训、效率办公)};当层数为5时、APP类别组合情况为:{(网络购物)、(网络视频、通信聊天、系统工具),(数字阅读、游戏),(图像服务、主题美化),(网络音乐、网络社交),(丽人母婴),(实用工具、本地生活),(健康医疗),(汽车服务),(新闻资讯、网络金融),(旅游出行),(教育培训、效率办公)};当层数为6时、APP类别组合情况为:{(网络购物),(网络视频),(通信聊天、系统工具),(数字阅读、游戏),(图像服务、主题美化),(网络音乐、网络社交),(丽人母婴),(实用工具、本地生活),(健康医疗),(汽车服务),(新闻资讯、网络金融),(旅游出行),(教育培训,效率办公)}。
五、APP组合推荐
考虑到每类APP存在多种实际软件,对划分结果最细的APP组合(层数为6)进行研究。
(一)单类APP组合
单类APP组合是指组合划分结果中一个组合只包含一类APP的情况。网络购物(淘宝、微店等),网络视频(优酷、直播吧等),丽人母婴(明星衣橱、宝宝故事等),健康医疗(健身宝典、用药助手),汽车服务(滴滴打车、驾校一点通),旅游出行(高德导航、携程旅游)仍然保持该类别独立成为一个组合。由此说明,这些类别的APP在所涉及功能方面较为全面,智能手机用户在使用该类APP时一般不考虑或不需要同时借助其他类别的APP,因此在引导APP功能拓展研发方面的作用较不明显。
(二)多类APP组合
多类APP组合是指组合划分结果中一个组合不止包括一类APP的情况。对于通信聊天和系统工具类APP组合来说,通信聊天包括微信、Skype、QQ等,系统工具包括Firefox、百度手机卫士等。根据日常生活工作经验,如果人们使用通信聊天类是为了非事务性的,则在等候对方回复时很可能会同时打开系统工具,通过浏览网页或查收邮件等打发时间;如果以事务性为目的,比如会议等,则现有的会议报告或研究材料可能属于网页格式,亦或需要在联络途中同时检索,这些情况都为通信聊天和系统工具两类APP成为组合与同时使用提供可能的机会。对于数字阅读和游戏类APP组合来说,数字阅读包括iReader、漫画人等APP,游戏类相对较容易理解。两类APP均属于休闲娱乐的范畴,为数字阅读类型的游戏研发提供一些启迪。此外,由于功能上的相似性,图像服务和主题美化类APP属于同一组合不难理解。根据人们日常行为和经验判断,网络音乐和网络社交、实用工具和本地生活、新闻资讯和网络金融、教育培训和效率办公这四大组合的出现,也符合逻辑推理(此处不再赘述)。
随着智能手机的推广和普及,APP的研发速度会不断增加,不同APP的使用率也会日益提高。一方面,一套清晰完整的数据提取方案的提出为后续研究工作提供数据保证;另一方面,通过对智能手机APP组合实现多层次划分,不仅可作为不同类APP功能打碎重组的依据,并为多功能APP的研发提供方向,可进一步满足用户需求与拓展市场,而且消费者也可从中发现当下常见的APP组合使用规律,为手机APP的选择和安装提供依据,提高生活和工作效率。在产品使用阶段,建议生产商进行APP组合调整后的手机用户对多样性和相容性的满意程度进行调查[14],进一步预测客户选择偏好和流失情况[15]。但需要说明的是,本文以安卓系统的智能手机用户为例,没有涉及苹果手机用户,虽然苹果手机在APP方面与其他手机品牌不存在兼容性问题,但考虑到购买和使用人群的不同,本文关于智能手机APP组合推荐得出的研究结论是否适用于所有智能手机数据,还将有待进一步研究。
参考文献:
[1]陈康, 黄晓宇, 王爱宝, 等. 基于位置信息的用户行为轨迹分析与应用综述[J]. 电信科学, 2013(4).
[2]Pablo B. Extracting Patterns from Locationhistory[C]. In Proceedings of the 19th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, 2011, San Jose, California, USA.
[3]Leskovec J, Kleinberg J, Faloutsos C. Graphs over Time: Densification Laws, Shrinking Diameters and Possible Explanations[C]. Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, 2005, Chicago, Illinois, USA.
[4]David J, Backstromb L, Cosleyc D. Inferring Social Ties from Geographic Coincidences[C]. Proceedings of the National Academy of Sciences of the United States of America, 2010.
[5]彭小川, 毛晓丹. BBS群体特征的社会网络分析[J]. 青年研究, 2004(4).
[6]Charu C, Social Network Data Analytics[M]. New York:Springer, 2011.
[7]Miller T W.Modeling Techniques in Predictive Analytics with Python and R:A Guide to Data Sciendce[C]: A Guide to Data Science. Pearson Education Inc., 2014.
[8]刘军. 社会网络分析导论[M].北京:社会科学文献出版社, 2004.
[9]Charu C. Aggarwal. An Introduction to Social Network Data Analysis[M]. New York:Springer, 2011.
[10]Borgatti S P, Everett M G. Models of Core/Periphery Structures[J]. Social Network, 1999(21).
[11]Borgatti S P, Everett M G, Shirey P R. LS Sets, Lamda Sets and Other Cohesive Subsets[J]. Social Network, 1990(12).
[12]Borgatti S P. A Comment on Doreian’s Regular Equivalence in Symmetric Structures[J]. Social Network, 1988(10).
[13]Borgatti S P, Everett M G, Freeman L C. Ucinet for Windows: Software for Social Network Analysis[M]. Harvard: Analytic Technologies, 2002.
[14]赖俊明. 大型购物中心的租户组合对消费者的影响作用研究[J]. 统计与信息论坛, 2016(3).
[15]张宇, 张之明. 一种基于C5.0决策树的客户流失预测模型研究[J]. 统计与信息论坛, 2015(1):89.
(责任编辑:郭诗梦)
Research in Smartphone APP Combinations Recommendation under the Background of Big Data
CHENG Hao1,2,3a,3b,3c,LU Xiao-ling1,3b,3c,5,ZHONG Yan3b,3c,FAN Chao3b,4,ZHAO Yu5
(1.Center for Applied Statistics, Renmin University of China, Beijing 100872;2.Mailman School of Public Health, Columbia University, New York 10032; 3.a.Center for Statistical Consultation,b.School of Statistics, c.Data Mining Center, Renmin University of China, Beijing 100872;4.International Statistics Information Center, National Bureau of Statistics, Beijing 100826;5.QM&Rucstat Mobile Big Data Research Institute, Beijing 100015)
Abstract:Be confronted with existed and emerging varieties of APP, a new data extraction program and deep researches on APP combinations have become a hot topic in big data era. With redefining the relationship measurement method among different kinds of APP, the paper comes up with a complete relational data extraction program. The social network visualization tool helps to find the relationship degree and distribution among different kinds of APP. Concor model provides a trustworthy methodology foundation in multi-level division of APP and its recommendation. The research shows that multi-level division of APP combinations mines the common APP sets in real life and gives good explanatory and practical significance, providing direction for the development of the smartphone APP producers and promoting the development of intelligent life and production process.
Key words:smartphone; APP application; multi-level division of combinations; recommendation research
收稿日期:2015-11-18;修复日期:2016-04-12
基金项目:中国人民大学科学研究基金《消费者网络购物行为统计建模研究》(2011030017)
作者简介:程豪,男,山西长治人,博士生,研究方向:数据挖掘,结构方程模型,社会网络;
中图分类号:C811
文献标志码:A
文章编号:1007-3116(2016)06-0086-06
吕晓玲,女,吉林省吉林市人,管理学博士,副教授,研究方向:统计学与消费者行为分析;
范超,男,北京人,博士生,研究方向:数据挖掘与机器学习;
钟琰,男,黑龙江哈尔滨人,硕士生,研究方向:数据挖掘与机器学习;
赵昱,女,北京人,硕士生,研究方向:移动互联网。
【统计应用研究】
