基于空间金字塔视觉词袋模型的交通视频车型分类方法研究
2016-06-29戴光麟许明敏董天阳
戴光麟,许明敏,董天阳
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
基于空间金字塔视觉词袋模型的交通视频车型分类方法研究
戴光麟,许明敏,董天阳
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
摘要:为了提高交通视频中车型分类的实时性和准确率,提出了一种基于空间金字塔视觉词袋模型的车型分类方法.该方法利用SIFT进行车辆特征的提取,采用空间金字塔优化车辆特征,在SVM分类器中引入车辆特征因子的视觉词袋模型进行交通视频车型分类.实验结果表明:基于空间金字塔视觉词袋模型的车辆分类方法不仅提高了车辆分类的准确率,也加速了车型分类过程.
关键词:视觉词袋;空间金字塔;智能交通;车型分类
智能交通系统(Intelligent transportation system,简称ITS)在交通和科技日益发展的今天得到凸显,其中车型分类技术是重要的一个分支.现有的车型分类算法主要利用车辆颜色、纹理、形状以及空间关系等特征进行识别,受限于车型姿态和环境变化,识别效率和精度较低,改进算法提高车辆分类效率成为当下研究的热点.围绕特征提取和分类技术进行车辆识别已有十多年的研究历史,国内外学者进行了很多研究工作,现有的车型分类方法主要有两类.
传统方法是基于车辆全局和局部特征的方法.比较典型的有Dgupte等[1]于2002年提出的车载摄像头车型分类方法,但该方法致力于车辆阴影的处理,实际意义有限.Sun等[2]使用Gabor滤波提取车辆纹理信息,该方法在速度上达到了应用水平,但在精度上不能让人满意.Chris和Mike等提出了一种Harris角点算法[3],是对Moravec角点检测算子的一个扩展,但是该方法对噪声干扰较为敏感.Arrospide等[4]使用HoG特征实现车辆分类,但计算量太大.Aditya等[5]使用边缘特征结构输入到支持向量机方法进行分类,但只达到74%的准确率.针对传统车型分类方法分类准确率低,近年来局部特征结合机器学习方法使得车型分类准确率得到提高.2013年,Meher等[6]使用PCA降维后进行SIFT车辆提取,然后输入支持向量机进行分类.但是该方法的计算过程非常复杂,不能满足车型实时分类的需求.其他的基于机器学习的算法如SVM分类模型的车辆识别[7],随机马尔可夫链模型[8],这些方法在实际使用中误识别率较高,性能上也不能达到实时的效果.借鉴了文本分析的词袋模型提出的图形视觉词袋模型(Bag of words, BOW)[9]广泛使用于图像检索领域,但针对车型这类细分的图像分类没有研究.随着局部特征结合机器学习算法的发展,基于机器学习车型分类方法中车型数据样本高相似度和传统方法对车辆外界影响关注少,容易导致误分类的问题比较突出.为此提出了一种基于空间金字塔视觉词袋模型的车型分类方法.在此基础上,设计和实现了基于视觉词袋模型的图像分类系统,并通过应用和实验验证了方法能在兼顾时间和准确率的前提下有效地从视频图像中识别车辆和车型分类.
1面向交通视频的视觉词袋模型构建
视觉词袋模型源于文本分类技术,假定对于一个文本看做单词的集合,车辆看作文本对象,车辆中不同的局部区域特征看做文本中的词汇,相近的特征作为一个单词,所有单词组合成为一个视觉词典,把文本检索和分类中的词袋模型应用到车辆分类中.视觉词袋用于图像分类可以跨越“语义鸿沟”的限制,在图像识别中得到了广泛的应用.
面向交通视频的视觉词袋模型构建过程如图1所示.首先进行特征聚类,将SIFT提取的特征点聚类成特征,特征聚类结果即为视觉单词.图中不同形状的图像代表不同特征聚类后产生的单词.然后对车辆的视觉单词统计,统计结果变成视觉单词直方图.视觉直方图即为车型的特征表达.以此类推,对相同类型车辆采用上述方式进行特征提取,最终绘制某类车型的直方图.

图1 视觉词袋模型构建过程Fig.1 The construction process of visual word bag model
1.1提取视觉特征
车辆特征提取作为车型识别的第一步,直接关系到后面聚类的效果.在所有车辆特征中,可以作为识别和区分车辆的特征包括车辆的外观(长、宽、高),车辆的角点、边缘特征.采用车辆外观作为车型识别特征的方式有简单、训练时间短的优势,但由于视频中车辆是动态变化的,车辆外观的形变,导致车辆外观特征动态改变.早在2001年AHS等[10]提出了道路三维建模来获得车辆外观数据,但是在实际中摄像头角度和道路情况不同,道路三维建模的效果产生较大差异,无法做到自适应.综合考虑提取复杂性、效果和车辆特征独特性采用边缘特征作为车型识别特征,使用SIFT(Scale-invariant feature transform)特征提取图像局部信息,在图像二维空间和DOG(Difference of gaussian)尺度空间中将检测的空间和极值作为特征.其算子表达式为
D(x,y,θ)=(G(x,y,kθ)-G(x,y,θ))I(x,y)
(1)
式中:θ为尺度坐标;G(x,y,kθ)为高斯函数尺度可变表示;I(x,y)为图像函数.产生尺度空间的表达式为
L(x,y,θ)=D(x,y,kθ)I(x,y)
(2)
进行SIFT特征描述后形成图像的特征映射,获得图片的特征点集,即feature列表.每个feature代表一个图片的某个局部特征,每个feature的数据结构由一个128维浮点数组表示.训练集所有图像的SIFT特征构成SIFT特征集R={r1,r2,…,ri,…,rn-1,rn},至此,训练集图像转换为SIFT特征.
SIFT局部特征具有平移、缩放和旋转不变性,同时对光照变化、仿射及投影影响也有很好的鲁棒性.如图2所示,在不同环境角度下SIFT特征能够实现准确匹配.

图2 SIFT实现特征匹配Fig.2 SIFT achieve feature matching
1.2获取视觉单词
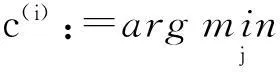
(3)
由于一张车辆图像中通常包含1000多个128维的特征点,因此在聚类过程中时间效率非常低,对于实时性要求较高的车型分类来说是绝对不允许的.另外,K-means算法基于欧氏几何距离,容易陷入局部最优解,并且其算法不稳定[11].为了克服以上缺点引入精确欧式位置敏感哈希(E2LSH)[12]到随机化视觉词典,生成的流程如下:
1) 首先利用SIFT获取车辆的特征集R={r1,r2,…,ri,…,rn-1,rn},其中,ri为对应特征,n为对应特征数量.
2) 将位置敏感函数g作用到SIFT特征集R,得到R中SIFT特征ri对应的k维向量g(ri).
3) 计算ri的主哈希h1(g(ri))和次哈希值h2(g(ri)).
4) 将R中主、次哈希值都相同的特征放到同一个集合中.
利用E2LSH将R聚类后获得哈希集合Tg={b1,b2,…,bk,…,bz-1,bz},聚类后每个中心视为一个词典中的词汇,获取全部词汇后就获得了对应的码本(Code word),所有视觉词汇形成一个视觉词典,对应一个码书,即码字的合集,通过统计视觉词典的视觉直方图对车辆进行分类.
1.3优化视觉单词
在获得随机化视觉词典后,利用视觉单词能够区分车辆类型.但是,仅仅依靠视觉词典分类是完全不够的:直方图是全局性的图像视觉单词的统计,但是没有对单词的位置特征加以关注.视觉单词的空间位置关系作为车辆分类的重要依据,特别是车型之间视觉单词相似度很高,引入视觉单词的空间位置关系尤为关键.引入空间金字塔模型到视觉词袋模型中,有效提高车辆分类的表达能力,能够提高分类准确率.具体操作过程如图3所示.
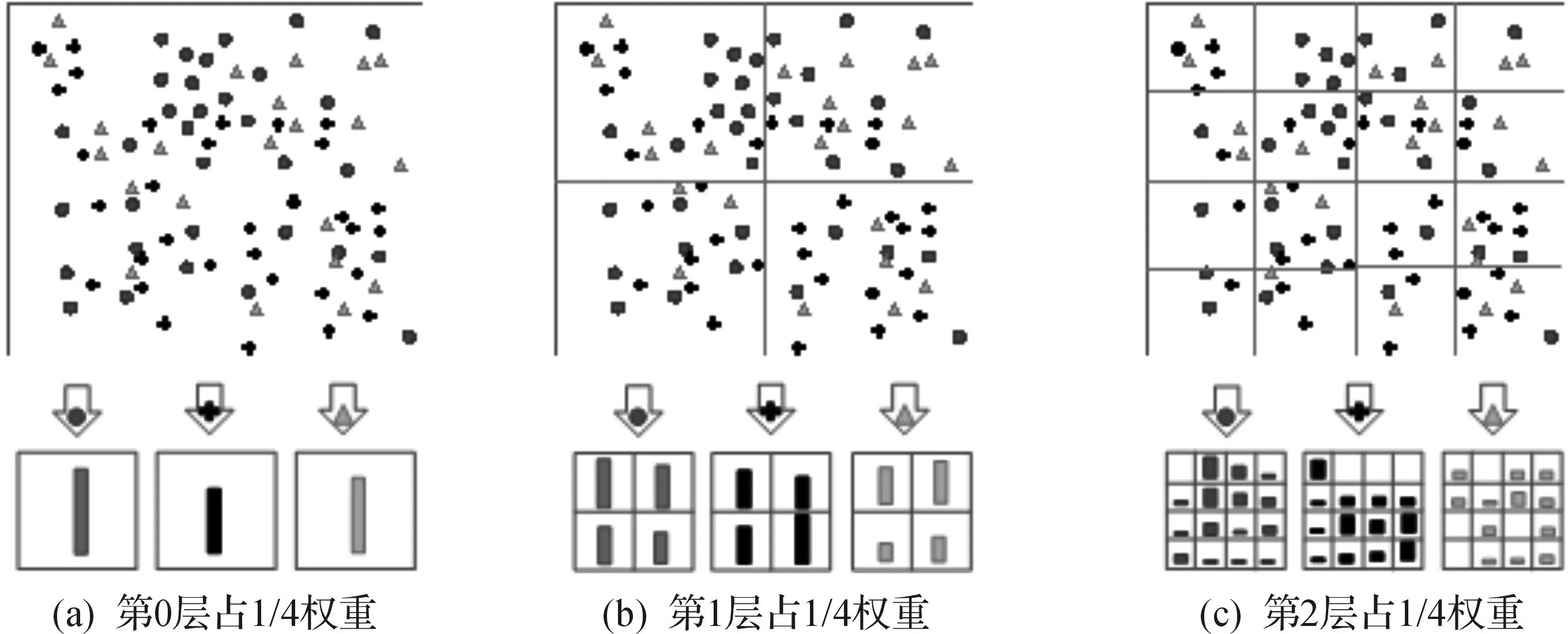
图3 视觉单词分层优化Fig.3 Hierarchical optimization of visual words
图3中原始的图片看做空间金字塔第0层,对该层图像做视觉直方图统计;然后将图片均分成四张子图片,该图片为空间金字塔第1层,对该层图像每个子空间进行直方图统计;然后再对1层图片进行4等分,均分成4份,得到空间金字塔第2层,对该层图像每个子空间进行直方图统计.在每个子层上迭代上述过程,并标记金字塔的层数Li.每一层占权重不同,越往后分,视觉单词在每一区域的分布越清晰,但是时间效率也会相应降低.在没有引入空间金字塔之前,传统的车辆分类方法大都采用矢量量化方法.统计视觉单词wn在图像中出现的次数,其公式为
VQ={r(w1),r(w2),…,r(wn),…,r(wz-1),r(wz)}
(4)
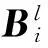
(5)
那么得到第l两张图像间的直方图相似度量公式为
(6)
金字塔分解体现了视觉单词在图像中的空间分布,而传统的视觉直方图侧重于单词在整幅图像中的比重,两种方式体现了对图像特征的不同描述,两者结合后整体和局部判断结合,有效提高准确率,整体准确率为
(7)
1.4基于车辆视觉因子的直方图分类
完成视觉直方图统计后,每种车型得到图4车辆特征直方图.车辆分类的特点是样本彼此的相似度和维度高,在车型分类多的情况下区分两个车型的难度很大,这是与图像类型检索的一大区别.为了增强车型识别率,在直方图中加入车辆特征因子(si{s1,s2,…,s5})以进行分类器的识别.共设定了五类视觉因子,分别是格栅、车灯、玻璃、引擎盖和其他.不同类型车辆在特征聚类后获得的车辆特征总类别规定后分类得到的结果是不同的,归一化后获得如下直方图.如行人基本特征都落在其他一列,而公交车的挡风玻璃面积较大,玻璃在所有因子中特别突出.

图4 车辆特征直方图Fig.4 Vehicle feature histogram
为了进一步明确特征直方图和车型之间的关系,根据图4绘制了图5车辆因子折线图.该图将不同因子作为数据点,不同车型作为直线.可以直观看出不同作用因子对车型的贡献.为了最大程度区分车型,将最明显的特征因子扩大两倍max{si}×2,将影响最小的因子缩小两倍min{sj}×0.5,拉开特征间的差距,使一类车辆能以最大程度落在某一车型中.然后将特征{max{si}×2,min{sj}×0.5,s1,s2,s3}作为分类器的输入.

图5 车辆特征因子Fig.5 Vehicle characteristic factor
2基于视觉词袋的交通视频车型分类方法研究
在对交通视频中的车型进行分类时将视频中提取的车辆特征因子输入到分类器中.数据类型和使用环境一般能够决定分类器的选择,数据量而言如果数据集非常大,分类算法的选择对最后的结果影响不大.由于交通视频中车辆跟踪和识别时需要对车型进行实时分类,对分类器在车型实时性上的要求非常高.另外在数据量上,由于获得的特征为128维的特征向量,数据集特征多,对于分类器在大数据情况下的处理提出了要求.鉴于数据的特点,要求保证车型分类实时性的同时,尽可能提高分类准确率是我们分类的标准.
为此采用了支持向量机分类方法[13].相对于朴素贝叶斯分类器和K-近邻算法,BOVW结合支持向量机效果较好[14].朴素贝叶斯算法利用概率来判断样本属于某个类别的可能性,该算法特点是需要的参数很少,对缺失数据不太敏感,算法比较简单.该算法成立条件苛刻,现实中无法满足会导致结准确率下降.而K-近邻算法是一种懒惰算法,这K个样本属于哪个类型多就属于哪个类.在数据量大的情况下这种算法就不适用了.
Kotsiantis[15]从准确率、学习速度、分类速度、容错率和噪点容忍度五个角度衡量三种分类算法的性能.车型分类中准确率和分类速度是最重要的因素,结果表明了SVM准确率和分类速度在3种分类算法中最高,由于SVM分类算法的复杂性决定了SVM学习速度较慢,学习阶段是在分类阶段前,这点是可以忍受的.
为了验证3种算法在实际图像分类的效果,下面实验采用PASCAL VOC2016年数据进行分析.一共5类数据,特征数15个,训练样本300个,测试样本900个.本实验采用3种分类算法,分别从时间和准确率考量3种算法的特点.
下面对SVM建模简单阐述:
1) SVM算法已有很多软件包,采用大家使用较多的Chih-Jin教授编写的LIBSVM软件.
2) 在挑选核函数上,RBF核在不同的图像分类中得到的效果都不错,因此采用RBF核作为SVM分类器的核函数.
3) 将上述数据特征作为分类器的输入.
4) 将二类分类器扩展到N类分类,针对N类分类问题构造N(N-1)/2个二分分类器,组合这些二分分类器使用投票法,投票最多的即为样本所属的类别.
K-近邻算法和其他两类算法不同的是该算法使基于实例的算法,即给定一个测试元组才开始构造分类模型,故在时间上和下面两类先训练再测试的算法差距较大,由实验看出时间落后一个数量级.朴素贝叶斯和支持向量机是给定训练元组后,接收测试元组前就构造好了分类模型,测试时间非常接近,在算法准确率上支持向量机略胜一筹,结合表1考量后发现支持向量机在能够胜任实际车辆分类中实时准确分类的要求,因此在挑选分类算法中倾向于支持向量机.
表1三类分类算法实验结果
Table 1Experimental results of three kinds of classification algorithms
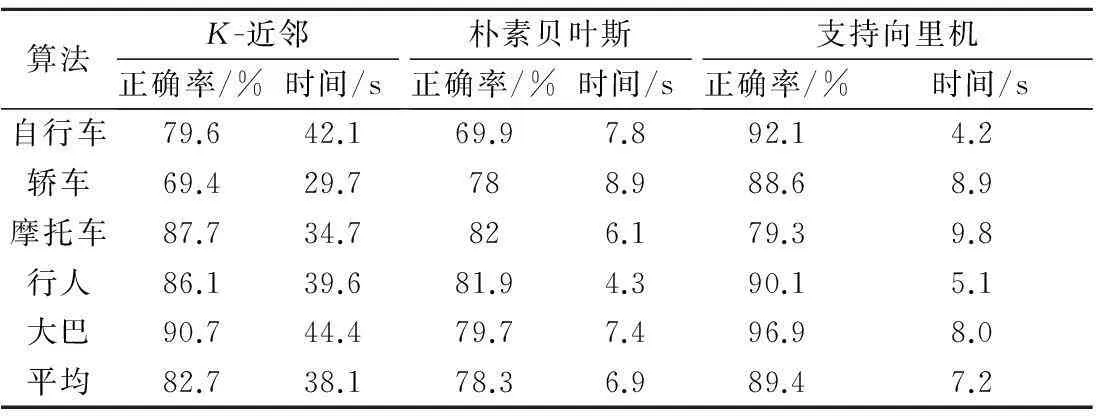
算法K-近邻正确率/%时间/s朴素贝叶斯正确率/%时间/s支持向里机正确率/%时间/s自行车79.642.169.97.892.14.2轿车69.429.7788.988.68.9摩托车87.734.7826.179.39.8行人86.139.681.94.390.15.1大巴90.744.479.77.496.98.0平均82.738.178.36.989.47.2
3实验结果与分析
为了验证该算法相比传统机器学习方法在精度上得到了提升,将从多方面对改进的基于视觉词袋模型的车辆分类算法进行评价:介绍数据集的来源;考察改进的聚类算法相比经典聚类算法存在的优势;将加入空间金字塔算法与不加入时候进行比较;在实验条件相同的情况下将该算法与近年来车型分类结果较好的两类算法进行比较得出结论.
3.1数据集获取
我们收集的数据集采用的图像数据采集自本地普通道路,拍摄工具为非高清摄像头.该视频拍摄于下午天气较一般情况,有阳光和阴天,像素在150×150左右.所有的训练和测试数据都来自本视频,包含六类车辆,分别是公交车、卡车、SUV、面包车、轿车和行人.随后采用无损压缩扣取车辆图片,其中570张公交车、568张卡车、589张SUV、562张面包车、609张轿车以及704张行人图片,数据集示例如图6所示.为了更好的模拟该场景下的车辆分类,我们没有新增其他视频中的车辆图片进来.根据特征提取中获得每类车型的特征向量集,分别为R1~R6,在此基础上,根据视觉词袋的算法流程,处理R1~R6,生成视觉词袋.

图6 实验使用的数据集Fig.6 Dataset for experiment
3.2特征聚类
实验采用上述提到的数据集,总共6类图片,图片像素在150×150 pixel.每类图片采用200张作为训练集,40张作为测试集.图7显示采用SIFT特征提取方法后得到的特征点,左侧为采用K-means聚类后得到的聚类点,右侧为采用E2LSH得到的聚类点.蓝色圆点是特征点,橘色三角是聚类结果.可以发现在E2LSH算法下获得的视觉词典更加松散,相比K-means聚类算法具有更好的图像表达能力.在时间效率上,K-means聚类方法的时间复杂度为O(tKmn),其中:t为迭代次数;K为簇的数目;m为记录数;n为维数.而局部敏感哈希的时间复杂度为O(nρlogn)获取特征点后采用E2LSH代替传统的聚类方法,得到了如图7所示的效果.

图7 两类聚类效果对比Fig.7 Comparison of two kinds of clustering effects
3.3空间金字塔优化
实验数据集为上述提到自己采样的数据集,对SUV、轿车和公交车进行训练和测试.各随机选取300张作为训练集,100张作为测试集.实验采用传统基于视觉词袋的分类算法(BOVW)与加入空间金字塔优化后的算法(BOVW+SPCMK)进行比较.由表2可知:加入金字塔模型后,视觉词袋模型的分类能力得到了有效的提高.
表2空间金字塔建模对视觉词袋的影响
Table 2Influence of spatial pyramid modeling on visual word bag

%
3.4分类结果
使用基于视觉词袋的分类算法与基于动态贝叶斯分类算法(Dynamic bayesian networks)[16]、K最近邻(KNN,K-nearest neighbor)[17-18]分类算法进行比较,车辆样本采用上述的数据集,为了公平起见,获得了类似光照、角度和分辨率的数据集,在此基础上对三类算法进行比较.在四类和六类车辆分类实验中采用每类训练车辆200张图片,测试图片40张的方式进行实验.在四类车辆分类实验中,分类准确率如表3所示,车辆测试的分布结果如图8(a)所示.由于类别只有四类,三种算法得到了较高精度.采用的算法在四类车辆中获得了整体和每类车辆最高的准确率.同时,发现误识别率较高的都是卡车被识别为了公交车.这也符合公交车和卡车在外形上较相似的特点.在六类车辆分类中方法也获得了整体最高的识别率,分类准确率如表4所示,车辆测试的分布结果图8(b).在时间效率上如表5所示,由于BOVW分类方法在车辆识别过程中采用分片聚类的方式,时间上并没能超越主流算法,但就效果而言也在同一数量级.

表3 四类车型分类分布结果

图8 车辆准确率直方图Fig.8 Vehicle accurate rate histogram
Table 4Six types of vehicle classification results

%

表5 四类和六类车型时间耗费和识别率
4结论
从视觉词袋入手,建立车辆提取、特征聚类、提取视觉词袋和车型分类等一系列图像模型,同时在特征点聚类时将K-means聚类方法替换成E2LSH方法,有效提高了聚类的效果.此外,以往车辆分类算法往往只考虑整体视觉直方图的统计,在视觉加入金字塔模型提高了车辆的分类的准确率,同时在时间效率上提高了不少,满足了智能交通系统高实时性的要求.本实验针对车辆单一特征进行研究,没有描述车辆其他特征.在实际生活中,车辆的多特征分类是车辆识别、分类的关键,今后要对车辆其他特征研究,以达到准确识别车辆的目的.
参考文献:
[1]DGUPTE S, MASOUD O, MARTIN R F K, et al. Detection and classification of vehicles[J]. IEEE transactions on intelligent transportation systems,2002,3(1):37-47.
[2]SUN Z, BEBIS G, MILLER R. On-road vehicle detection using evolutionary gabor filter optimization[J]. IEEE transactions on intelligent transportation systems,2005,6(2):125-137.
[3]XU W, WANG S Z. Measurement o vehicle speed based on harris corner detector[J]. Journal of image and graphics,2006,11(11):1650-1652.
[4]ARROSPIDE J, SALGADO L, CAMPLANI M. Image-based on-road vehicle detection using cost-effective histograms of orineted gradients[J]. Journal of visual communication and image representation,2013,24(7):1182-1190.
[5]KANITKAR A R, BHARTI B K, HIVARKAR U N. Object calssification using encoded edge based structural information[C]//Journal of the American Statistical Association: Advances in Computing and Communications. Berlin Heidelberg: Springer,2011:358-367.
[6]MEHER S K, MURTY M N. Efficient method of moving shadow detection and vehicle classification[J]. AEU-International journal of electionics and communications,2013,67(8):312-320.
[7]周辰雨,张亚岐,李健.基于SVM的车辆识别技术[J].科技导报,2012(30):53-57.
[8]张昕,王松涛,张欣,等.基于马尔可夫链的混合动力汽车行驶工况预测研究[J].汽车工程,2014,12(10):1216-1220.
[9]ZHAO R, GROSKY W I. Narrowing the semantic gap-improved text-based web document retrieval using visual features[J]. IEEE transactions on multimedia,2002,4(2):189-200.
[10]AHS Lai, GSK Fung, NHC Yung. Vehicle type classification from visual-based dimension estimation[J]. IEEE intelligent transportation systems,2001,25(29):201.
[11]高雪,谢仪,侯红卫.基于多指标面板数据的改进的聚类方法及应用[J].浙江工业大学学报,2014,42(4):468-472.
[12]李红梅,郝文宁,陈刚.基于精确欧氏局部敏感哈希的协同过滤推荐算法[J].计算机应用,2014,34(12):3481-3486.
[13]叶永伟,任设东,陆俊杰,杨超.基于SVM的汽车涂装线设备故障诊断[J].浙江工业大学学报,2015,43(6):670-675.
[14]杨全,彭进业.采用SIFT-BoW和深度图像信息的中国手语识别研究[J].计算机科学,2014,41(2):302-307.
[15]KOTSIANTIS S B. Supervised machine learning: a review of classification techniques[J] Informatica,2007,12(11):249-268.
[16]BHANU B, KAFAI M. Dynamic bayesian networks for vehicle classification in video[J]. IEEE trans onimage processing,2012,8(1):100-109.
[17]董天阳,阮体洪,吴佳敏,等.一种Haar-like和HOG特征结合的交通视频车辆识别方法研究[J].浙江工业大学学报,2015,43(5):503-507.
[18]ZHANG C J, CHEN Y Z. The research of vehicle classification using SVM and KNN in a ramp[J]. International forum on computer science-technology and applications,2009,3(2):391-394.
(责任编辑:刘岩)
Research on vehicle classification method in traffic video based on spatial pyramid visual word bag model
DAI Guanglin, XU Mingmin, DONG Tianyang
(College of Information Engineering, Zhejiang University of Technology, Hangzhou 310023, China)
Abstract:In order to improve the real-time performance and classification accuracy of vehicle classification in traffic video, a new classification method based on space pyramid visual word bag model is proposed. The SIFT method is used to extract the features of vehicle and the vehicle features are optimized by the space pyramid model. The visual word bag model of vehicle feature factor is introduced in SVM classifier in order to classify vehicles in traffic video. The experimental results show that the vehicle classification method based on space pyramid visual word bag model not only improves the accuracy of vehicle classification, but also accelerates the process of vehicle classification.
Keywords:visual bag; space pyramid; intelligent transportation; vehicle type classification
收稿日期:2016-01-21
基金项目:国家自然科学基金资助项目(61202202)
作者简介:戴光麟(1979—),男,浙江宁波人,讲师,主要从事计算机网络、无线传感网和视频图像处理等,E-mail:dgl@zjut.edu.cn.
中图分类号:TP391.2
文献标志码:A
文章编号:1006-4303(2016)03-0247-07
