融合语义知识库的流程匹配算法
2016-06-28常关羽杨海成
常关羽, 杨海成, 孙 鹏
(西北工业大学 机电学院, 西安 710072)
融合语义知识库的流程匹配算法
常关羽, 杨海成, 孙鹏
(西北工业大学 机电学院, 西安 710072)
摘要:为在流程相似度计算中加入流程间深层语义关联的度量,同时在流程节点较多的情况下,实现流程匹配算法在寻优时间复杂度和相似度匹配输出值两方面的综合优化,提出一种面向流程的遗传匹配算法,将遗传算法引入并应用在流程语义和结构的相似度计算寻优过程中. 确定遗传算法的参数编码方式,并利用贪婪算法进行初始种群的设置,定义各个遗传算子,提出有效的简化策略,解决了流程节点较多时流程匹配过程寻优问题. 实验研究表明,在流程节点数较多时,本文算法在寻优时间花费和相似度值两方面的折中优化性能明显优于其他两种算法. 将遗传算法应用到流程的相似度计算及其寻优过程,可以有效地控制时间复杂度并保证较好的匹配输出结果.
关键词:业务流程; 文本相似度; 语义知识库; 匹配相似度; 遗传算法
海量流程资产的有效利用取决于信息系统的流程管理技术水平,而有效的流程相似度查询技术则成为提升业务流程管理水平的关键技术之一[1]. 在相似性计算方面,标注于流程节点上的文本标签的相似度是进行流程相似性分析的基础[2-3]. 传统的基于文本的匹配检索可以用来索引和搜寻业务流程模型知识库. 但这类匹配和检索是以关键词和字符匹配[4-5]或其特征值[6]的近似程度为基础,若模型标记的文本标签包含特定的关键词或字符,那么这种方式是确有成效的[7]. 但是,这种相似的应用没有考虑语义异构性的存在. 这使得采用以关键词和字符匹配为基础的传统流程相似匹配难以实现更加准确的语义查询[8]. 基于语义知识库的语义相似度是一种计算文本与文本间在其概念关联上相似程度的度量方法. 因此,本文引入基于语义知识库的概念相似度计算方法,将其应用在流程匹配中的文本标签的相似度计算中,以提高流程匹配的准确度.
在流程匹配过程的寻优算法上,现存的几种流程匹配算法都具备各自的特点,但在流程节点较多时,都表现出各自的不足. 例如贪婪算法[9],可以在很短时间内得到一个匹配结果以及匹配的相似度值,但很可能得到的不是最优匹配. 而作为典型的启发式算法的A*算法[10],虽然可以确保找到最优解,但其耗时代价可能会随着节点数增加而急剧增长. 因此,本文提出一种基于遗传算法[11-12]的折中优化的算法,旨在节点数较多时,既能在相似度上达到较为满意的值,又可以在匹配寻优过程的时间耗费上处于可以接受的范围.
1节点语义相似度计算模型
1.1语义相似度及其关键定义
定义1义原相似度[13]. 设s1与s2为两个义原,义原间距离记为D(s1,s2),相似度记为Ssem(s1,s2),则

其中:d1和d2分别是义原s1和义原s2所处的层次,α>0,且α是相似度为0.5时s1和s2之间的距离.
定义2义原最佳匹配[14]. 设S1={s11,s12,…,s1m} 和S2={s21,s22,…,s2n}分别为包含m和n个义原的集合,且有m≤n. 定义从S1到S2的一个单射集合为M. 则义原的最佳匹配是指一个单射集合Mopt,对于所有其他的单射集合M都有
其中Ssem为两个义原间的相似度.
定义3义项相似度. 设C1、C2为两个义项,C1由m 个义原描述s11,s12,…,s1m,C2由n个义原描述s21,s22,…,s2n,且m≤n . Mopt为描述两个义项的义原集合的最佳匹配,则C1、C2的相似度为[15]
其中wi是为不同的义原映射赋予的不同权值.
定义4概念相似度. 设概念S1的名称L1有m个义项C11,C12,…,C1m,概念S2的名称L2有n个义项C21,C22,…,C2n,则概念S1和概念S2的相似度为[16-17]
其中SConcept(C1i,C2j)表示义项C1i、C2j之间的相似度. 1.2流程节点的语义相似度计算
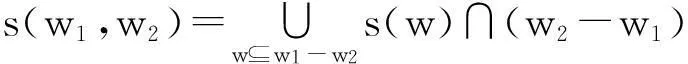
定义6文本标签的语义相似度. 设l1,l2∈Ω为文本标签,W为所有词语或单词的集合,w∶Ω→P(W)为分离文本标签成单词集合的函数. sword是基于语义知识库的一个词汇相似度函数. 令w1=w(l1),w2=w(l2),M为词汇集合w1与w2的词汇单射集合. Mopt为使得词汇映射相似度值之和最大的映射. S(l1,l2)为文本标签l1和l2的语义相似度,即
其中:|w1|、|w2| 分别表示w1和w2中的词汇数, w1i、w2j分别表示w1和w2中的一个词语.
定义7节点特性相似度. 设B1(N1,E1,τ1,λ1,α1)和B2(N2,E2,τ2,λ2,α2)是两个流程图,令n1∈N1和 n2∈N2分别为B1和B2的一个节点. S为相似度函数. 那么可以定义节点n1和n2特性的相似度为
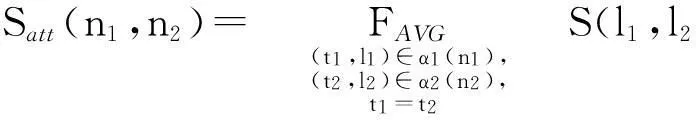
特性相似度一般与其他相似度结合起来使用.
定义8节点类型相似度. 设有流程图B1(N1,E1,τ1,λ1,α1)和B2(N2,E2,τ2,λ2,α2),令n1∈N1和 n2∈N2分别为B1和B2的节点. 令t∶ T×T→[0,1]为节点类型的相似度函数,则
为节点类型相似度函数. t是预先定义的. 可选择以下参考定义形式:
综上,本文设计了如图1的节点相似度计算模型.
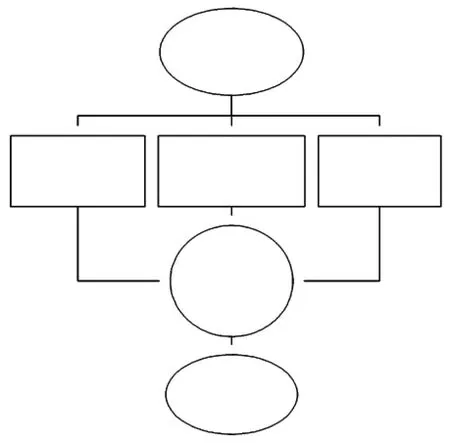
图1 节点相似度计算模型
2流程相似度计算模型
第2种要研究的相似度是业务流程的结构相似度. 结构相似度基于图编辑距离来定义[19].
定义9图的编辑距离. 设B1(N1,E1,τ1,λ1,α1)和B2(N2,E2,τ2,λ2,α2)是两个流程图,S为相似度函数,M∶(N1→/ N2)为一个局部单射. n∈(N1→N2)为一个节点. 当且仅当n∈dom(M)或n∈cod(M)时,n 是被“替换”的. 若n不是被“替换”时,则n为“插入”或“删除”. sn为所有“插入”或“删除”的节点集. (n,m)∈E1为边,当且仅当不存在(n,n′)∈M或(m,m′)∈M以及Eedge(n′,m′)∈E2. se是所有“插入”或“删除”的边集. 图编辑距离表示如下:
图的编辑距离是由两个流程导出的最小化距离. 其计算方法是:1减去“插入”或“删除”节点“插入”或“删除”边集以及“替换”节点平均距离的平均值的分数部分的差.
定义10图编辑距离相似度. 设B1=(N1,E1,τ1,λ1,α1)和B2=(N2,E2,τ2,λ2,α2)为两个流程图,S为相似度函数,令M∶ (N1→/ N2) 为导出两个流程图编辑距离的局部单射,sn和se同定义9中所述,图的编辑距离相似度为
定义11等价映射和最优等价映射. 设B1(N1,E1,τ1,λ1,α1)和B2(N2,E2,τ2,λ2,α2)为两个流程图,设节点对相似度函数为S∶N1×N2→[0,1]. 一个局部单射MS∶(N1→/ N2) 为等价映射的条件是,当且仅当对于所有的n1∈N1和n2∈N2∶(n1,n2)∈M可使S(n1,n2)>0.

|{n|n∈N1,τ1(n)∉ts}|+
|{n|n∈N2,τ2(n)∉ts}|.
基于以上定义,流程相似度计算模型如图 2.
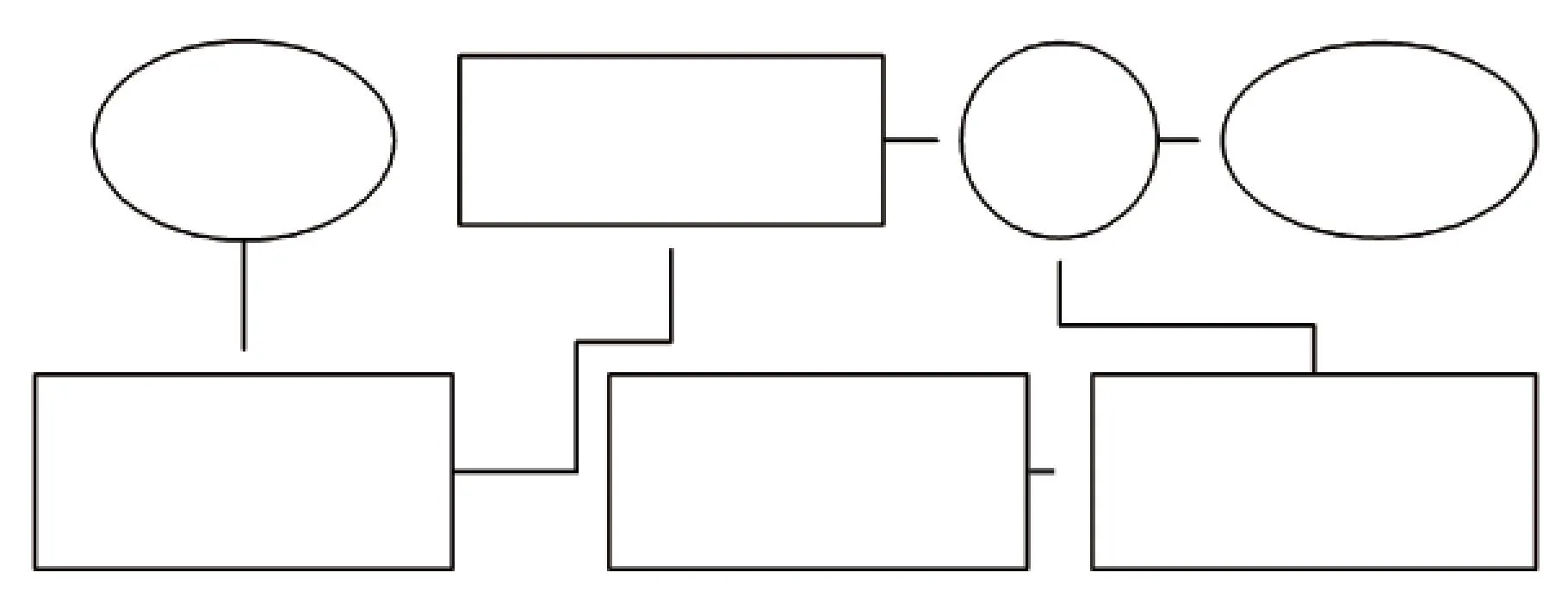
图2 流程相似度计算模型
3流程匹配过程寻优算法设计
本文设计了一种基于遗传算法的匹配过程寻优算法,使得计算效率和匹配效果都能满足应用需求. 算法关键设计细节如下.
3.1流程编码
设一个有n 个节点的流程Pn,采用编码1,2,…,n-1,n对每个节点进行编码. 设另一个有m个节点的流程Pm,则其编码为1,2,…,m-1,m. 任意两个流程的节点数总有n≥m. 因为,总可用n表示节点数较多的流程节点数. 当两个节点数分别为n和m的流程Pn和流程Pm进行匹配时,编码的位数便为n,编码每一个基因位上的取值范围是1~n,且每一个基因位上的取值不重复. 编码中每个基因位代表Pn的一个节点,而该基因位的取值代表Pm中的一个节点. 注意到n≥m,因此在基因位的取值中,超过m的值m+1,…,n-1,n是没有意义的. 因此,当某基因位的取值为m+1,…,n-1,n中的一个时,表示该基因位代表的流程Pn的节点不能与Pm中节点匹配. 3.2种群初始化
首先,可以确定一个表示节点间的相似度的矩阵S. 以P9和P7为例,则有相似度矩阵S9×7为
式中,sij为P9的第i个节点和P7中的第j个节点的相似度值.
3.3适应度函数
匹配的目标在于求解相似度最大的匹配. 根据定义11中的节点匹配相似度定义,可以将适应度函数设为个体m中所有节点映射相似度之和,因此节点匹配的相似度适应度函数定义如下:
其中:m(i)为所求个体第i基因位上的值,si,m(i)为两流程节点相似度矩阵中第i行第m(i)列的值. 求这些匹配上的节点的相似度之和,是最简单的一种适应度函数.
根据流程的结构相似度定义,可以分别得
式中:m(i) 为所求个体第i基因位上的值,si,m(i)为两流程节点相似度矩阵中第i行第m(i)列的值. 进一步得到结构相似度的适应度函数:
3.4遗传算子设计
由于采用了非二进制编码,所以变异算子需要采用对应离散数字的变异方法. 在此采用映射互换模式的变异方法、基因段逆转、互换位置相结合的方法进行遗传处理以提高遗传多样性.
3.5参数设定
种群规模根据问题的节点数进行设定. 例如,匹配中,节点较多的流程节点数为n,则相应的种群规模可设为n~2n. 迭代代数为节点数3~5倍,或者采用某个估计函数Af(n) ,其中A为一个基准常数,f(n)为一个节点数的增函数. 交叉概率可设为Pc=0.9,变异概率为Pm=0.01.
最终的算法运行流程如下:

图3 遗传匹配算法流程图
4实验
根据前述工作,该节根据流程节点数不同,将流程库中的流程分成98类,即2~99个节点的流程根据其节点数各成一类. 每一类流程一般有8~12个. 通过对不同类别流程的匹配计算,观察算法的性能表现. 在语义相似度的计算上采用了基于《知网》的语义知识库及其词汇语义相似度计算方法,并结合前文的分析实现流程配对和相似度计算. 实验时,首先通过确定截断值对测试结果的影响来确定合适的实验参数;其次,在确定的截断值条件下,通过匹配的相似度结果和匹配过程的时间消耗来确定匹配综合效果.
式中:t为所耗费的时间,A为比例调节常数,s为求解的相似度值,s0为通过贪婪算法得到的相似度值,α为一较小的常数,以避免分母为零;Cn为两流程节点数的减函数. 通过函数Cn的调节,使得在节点增多时,函数成本适当减小.Cn的确定与常数A和α相关,例如可取Cn=-Aeαn. 根据实验数据特点,也可采用以下变形:
(1)
实验证明,截断值(δ)的选取对流程匹配算法的实用性具备重要影响,特别是A*算法在节点数逐渐增大约到15个节点时,平均耗时会开始超过1s/百对. 增加至54个节点时,程序耗时已经超过2d,因此采用文献[9]建议,δ的下界取0.6,此时得到的A*算法在相似度值和耗时两方面都处于可接受范围内. 实验中对贪婪算法、A*算法、遗传算法进行包括时间复杂度、匹配结果以及时间成本代价等指标的对比,截断参数δ可选0.6、0.8, 当δ=0.6时,对比较果明显. 由于流程的相似度值差异值较小,为了清晰地表达实验结果,将3种算法得到的相似度值减去贪婪算法得到的值绘图,结果见图4. 由图4可知,与δ=0.6相比,δ取0.8时,流程匹配相似度的绝对值整体下降了. 因为δ的变大,直接忽略相似度值较小的节点匹配,从而导致整体相似度值下降.

(b) δ=0.8
从图4可以清楚地看到3种算法得到的相似度值的差异. 由于贪婪算法自身减掉自身的值得到的值始终是0,因此,贪婪算法表现为一条恒为0的直线,延伸于坐标轴横轴方向上. 在δ为0.6时,可以看到遗传算法和A*算法大约在节点数达到45及其之前的匹配输出是完全重合的;当节点数>45时,遗传算法的值开始处于A*算法之下. 这说明遗传算法在节点数超过45时,不能再保证相似度值是最优解. 当δ为0.8时,遗传算法和A*算法得到的相似度值与贪婪算法相同,减掉贪婪算法的值后结果都为一条恒为0的直线,延伸于横轴方向上,如图4(b)所示. 因此,δ超过0.8时,贪婪算法是最好的. 即当δ超过0.8时,截断值过于简化了算法. 然而如果实际需要,可以将δ设得比较大,如0.8. 但δ设得过大,可能使得匹配不到真正的最优解,从而导致匹配算法失去优势.
5算法时间复杂度结果分析
在测试了截断值对匹配结果的影响后,实验取δ=0.6对3种算法的时间复杂度进行测试. 图5为3种算法随着节点数增加,时间复杂度的情况. 横轴表示节点数,纵轴表示每100对流程匹配所耗费的时间. 由于时间跨度较大,图中纵轴采用时间对数坐标.
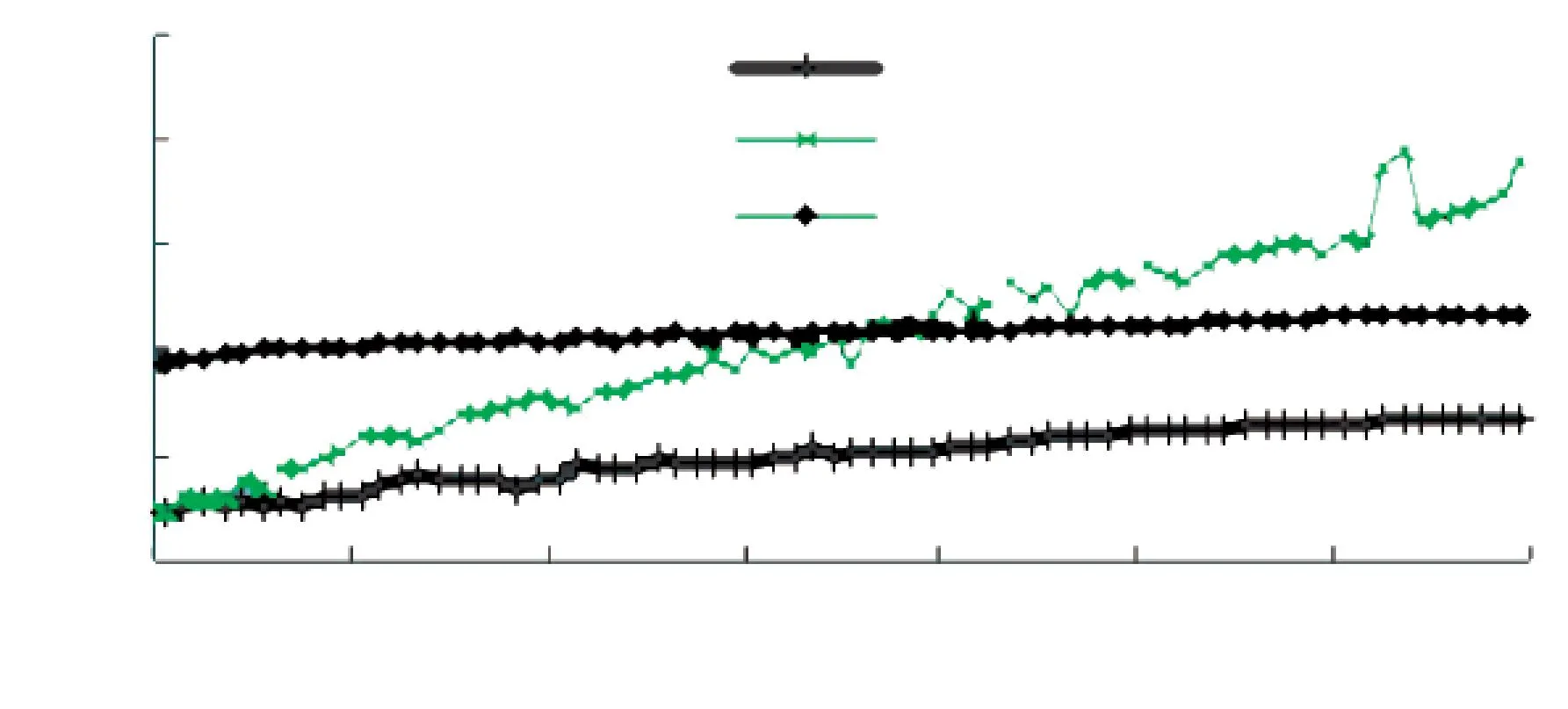
图5 算法平均时间复杂度随节点增多变化趋势
由图5可知,贪婪算法在时间上表现最好. 同时,A*算法在起初节点数较少时,时间和贪婪算法相当. 当节点数>5时,A*算法时间复杂度急剧增长,并在节点数为37附近,超越遗传算法呈剧烈上升趋势. 在节点数为37处,A*算法的时间耗费约为11(e11ms约为12s).A*算法的时间复杂度基本保持随着节点数逐渐增长而增长,偶尔出现时间耗费降低或者突然增大的情况,说明A*算法的波动性较大. 遗传算法的时间复杂度基本稳定,始终保持在11附近并缓慢增长. 出现以上实验现象是因为A*算法受启发策略的影响很大,同时其复杂度随着节点数的增加会呈现指数增长趋势,最终总体上体现出快速增长并偶有波动. 而采用贪婪算法,随着节点数的提升,时间复杂度呈对数增长模式,因此能有效避免状态空间爆炸问题. 遗传算法的复杂度取决于其迭代次数和进化过程,具备复杂度小且可控的特性.
6时间成本评比
基于式(1),参数采用了如下的取值:A=0.01,α=0.001,Cn=-Aeαn. 对实验数据进行二次处理,得出时间成本效果对比曲线.
可以看到,图 6的趋势与图5是一致的. 从图 6可得贪婪算法的成本基本上一直维持在最低. 因为贪婪算法的时间复杂度很小,使得贪婪算法在一些应用场景下始终具有优势. 遗传算法在节点数<37时,成本函数始终大于A*算法;超过37时,与A*算法相当,超过43个节点时,遗传算法相对于A*算法表现出优势,而且时间成本相对稳定,增长缓慢. 即当节点数超过43时,采用A*算法来求解匹配的最优值是不如遗传算法“划算”的. 综合前述实验结果,当流程节点达到一定数量时,采用遗传算法进行流程最优匹配是一个能兼顾匹配输出效果和时间成本的选择,对于实际应用来说,具备明显的折中优势.

图6 相似度计算综合代价随节点增多的变化趋势对比
7结论
1)从流程节点的语义相似度和流程结构匹配算法两方面进行了研究. 结合流程节点语义相似度和流程结构相似度的相关定义, 导出了本文的流程相似度计算模型.
2)针对流程相似度寻优过程,设计了一种基于遗传算法的过程寻优算法.
3)对目标算法进行了实验验证,通过对实验数据的分析,证明了本文设计的流程匹配算法在匹配的时间复杂度和匹配输出方面的综合优化能力,对比已有的匹配过程寻优算法,本文算法体现出很好的实用价值.
鉴于时间和实验条件,本文虽然在流程匹配中尝试了对语义的考察,但还有进一步深入的空间,如实现本体语义的语义匹配,尝试其他新算法在匹配寻优过程中的应用等.
参考文献
[1] JIN T, WANG J, LA ROSA M, et al. Efficient querying of large process model repositories[J]. Computers in Industry,2013, 64(1): 41-49.
[2] WANG P, LIU H. Assessing sentence similarity using wordnet based word similarity[J]. Journal of Software,2013, 8(6): 1451-1458.
[3] LI H, TIAN Y, CAI Q. Improvement of semantic similarity algorithm based on WordNet[C]// 2011 6th IEEE Conference on Industrial Electronics and Applications (ICIEA). Beijing: IEEE, 2011:564-567.
[4] 郭永利,卢颖颖. 基于Lucene对文件全文检索的研究与应用[J]. 微型电脑应用, 2014(1): 51-54.
[5] 李永春,丁华福. Lucene的全文检索的研究与应用[J]. 计算机技术与发展,2010, 20(2): 12-15.
[6] 付永贵. 一种改进的余弦向量度量法文本检索模型[J]. 图书情报工作,2011(19): 115-119.
[7] BERRETTI S, DELBIMBO A, VICARIO E. Efficient match-ing and indexing of graph models in content-based retrieval[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(10): 1089-1105.
[8] COLOMOPALACIOS R, GOMEZBERBIS J M, GARCIAC-RESPO A, et al. SeMatching: using semantics to perform pair matching in mentoring processes[C]//2nd World Summit on the Knowledge Society. Chania: Springer Verlag, 2009:137-146.
[9] DIJKMAN R, DUMAS M, GARCIABANUELOS L. Graph matching algorithms for business process model similarity search[C]//7th International Conference on Business Process Management. Ulm: Springer Verlag, 2009:48-63.
[10]THANUJA M K, MALA C. A search tool using genetic algorithm[M]//Information Technology and Mobile Communication. Chania: Springer, 2011: 138-143.
[11]HONDA K, NAGATA Y, ONO I. A parallel genetic algorithm with edge assembly crossover for 100,000-city scale TSPs[C]// 2013 IEEE Congress on Evolutionary Computation (CEC). Cancun: IEEE,2013:1278-1285.
[12]CEKMEZ U, OZSIGINAN M, SAHINGOZ O K. Adapting the GA approach to solve Traveling Salesman Problems on CUDA architecture[C]// 2013 IEEE 14th International Symposium on Computational Intelligence and Informatics (CINTI). Budapest: IEEE, 2013:423-428.
[13]葛斌,李芳芳,郭丝路,等. 基于知网的词汇语义相似度计算方法研究[J]. 计算机应用研究, 2010(9): 3329-3333.[14]周生宝,郭俊芳. 本体映射中概念相似度计算的改进[J]. 山西大同大学学报(自然科学版), 2008(4): 38-40.[15]王婷. 本体相似度研究[J], 电脑知识与技术(学术交流), 2007(6): 1609-1611.
[16]张艳霞,张英俊,潘理虎,等. 一种改进的概念语义相似度计算方法[J]. 计算机工程, 2012(12): 176-178.
[17]胡哲,郑诚. 改进的概念语义相似度计算[J]. 计算机工程与设计,2010(5): 1121-1124.
[18]DIJKMAN R, DUMAS M, DONGEN B V, et al. Similarity of business process models: Metrics and evaluation[J]. Information Systems,2011, 36(2): 498-516.
[19]ZHU J, PUNG H K. Process matching: A structural approach for business process search[C]//Computation World: Future Computing, Service Computation, Adaptive, Content, Cognitive, Patterns, Computation World 2009. Athens: IEEE Computer Society, 2009:227-232.
(编辑杨波)
Process matching method based on semantic repository
CHANG Guanyu, YANG Haicheng, SUN Peng
(School of Mechanical Engineering, Northwestern Polytechnical University, Xi′an 710072, China)
Abstract:To calculate the process similarity with consideration of deep semantics correlation between business processes, and to optimize the time complexity and matching result when the node number of business process becomes larger and larger, a process matching method based on GA (Genetic Algorithm) is put forward. This method is applied in similarity calculation for both process semantic and process structure, in which encoding is determined, and greedy algorithm is utilized to initialize the population of GA. By defining genetic operations and adopting some strategies for simplifying, the optimization of business process matching with large node number is fulfilled. As is expected, the experiments prove that the overall performance of algorithm proposed in this paper is better than the others that exist, especially when the count of process nodes grows to a large number. So it is concluded that the application of GA in business process similarity calculation and corresponding process optimization can effectively control the time complexity, meanwhile ensure the quality of the matching result, which shows a good practicability.
Keywords:business process; text similarity; semantic repository; match similarity; genetic algorithm
doi:10.11918/j.issn.0367-6234.2016.07.025
收稿日期:2015-03-26
基金项目:国家自然科学基金(51375395)
作者简介:常关羽(1985—),男,博士研究生; 杨海成(1959—),男,教授,博士生导师
通信作者:常关羽,dengxiao@mail.nwpu.edu.cn
中图分类号:TP315
文献标志码:A
文章编号:0367-6234(2016)07-0150-06
