基于增量更新的协同过滤推荐算法
2016-06-28严克文
方 芳,严克文
(合肥工业大学 管理学院,安徽 合肥 230009)
基于增量更新的协同过滤推荐算法
方芳,严克文
(合肥工业大学 管理学院,安徽合肥230009)
摘要:为解决传统协同过滤推荐算法相似度矩阵不能局部更新的问题,提出了一种基于增量更新的协同过滤推荐算法。该算法首先根据用户评分数据构建用户相异度矩阵,然后选取与目标用户相异度较小且同现次数较多的若干用户作为目标用户最近邻居并产生推荐。算法可以对相异度矩阵进行在线局部更新,无须离线导入全部数据重新计算,从而实现了算法的增量更新,使算法具备了良好的扩展性。进一步实验表明,基于增量更新的协同过滤算法具有很高的推荐准确性。
关键词:个性化推荐;协同过滤推荐;电子商务;用户相异度;增量更新
一、引言
随着互联网的普及和电子商务的迅猛发展,“信息过载”问题变得越来越严重。一方面用户很难从中找到自己感兴趣的内容,另一方面大量有用的信息也很少被用户触及,成为网络上的“暗信息”。个性化推荐作为解决“信息过载”的有效手段,逐渐成为互联网,尤其是电子商务中的一个重要研究内容。目前,几乎所有大型的电子商务系统,如淘宝、Amazon、京东、当当等都不同程度地使用了各种形式的个性化推荐系统。
根据推荐算法的不同,个性化推荐技术主要分为协同过滤推荐、基于内容的推荐、基于关联规则的推荐和混合推荐[1-2]。其中,协同过滤推荐是目前应用最为广泛的个性化推荐技术。协同过滤算法的基本思想是根据所有用户对物品或者信息的偏好,发现与目标用户兴趣偏好相似的邻居用户群,然后,基于邻居的历史偏好信息,为目标用户进行物品的推荐。
随着电子商务规模的不断扩大,用户数量和商品数量越来越多,协同过滤算法面临的扩展性问题变得越来越严重,从而也影响了推荐生成的速度和质量。很多学者及研究机构已经提出了很多方法改善协同过滤的扩展性问题,采用聚类、矩阵分解、数据集缩减等方法是改善扩展性问题的主要研究方向。文献[3-6]均是通过聚类的方式减少最近邻的搜寻空间,从而提高算法的可扩展性。文献[7-8]则是采用矩阵分解的思想,主要通过奇异值分解(SVD)等方法将高阶的用户评分矩阵分解为几个低阶的子矩阵,并在低阶矩阵上进行个性化推荐。文献[9-10]则采用适当方法压缩用户评分矩阵,降低数据集规模,以应对扩展性问题。这些算法均部分地改进了协同过滤算法。
用户和产品的信息是动态改变的(新用户、新产品的加入,用户选择或评价已经存在的产品),如果每次改变都需要重新计算,这个计算量是巨大的。比较可行的方案是设计某种近似的动态算法,每次都只是局部改变,而不需要完全的重新计算。而关于这方面算法的研究,现在还非常少。基于此,本文提出一种基于增量更新的协同过滤算法(User-Based Collaborative Filtering with Incremental Updating, IU-UserCF)。IU-UserCF算法可基于发生变化的评分向量,对相异度矩阵进行在线局部更新,克服了以往算法更新矩阵需要导入全部数据重新计算的问题,使得算法具备良好的扩展性。
二、相关工作
1.传统相似性度量方法
协同过滤算法进行推荐的基础是构建一个相似度矩阵,这需要通过相似性度量方法进行计算得出。度量相似性的方法主要有如下三种:余弦相似性、修正的余弦相似性和皮尔逊相关系数。

(1)
修正的余弦相似性:在余弦相似性度量方法中没有考虑不同用户的评分尺度问题,修正的余弦相似性度量方法通过减去用户对项目的平均评分来改善上述缺陷。设用户i和用户j共同评分的项目集合用Iij表示,Ii和Ij分别表示用户i和用户j评分的项目集合,则用户i和j之间的用户相似性sim(i,j)为:
sim(i,j)=
(2)
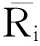
皮尔逊相关系数:又称相关相似性,计算时首先找到两个用户的共同评分项目集,设用户i和用户j共同评分的项目集合用Iij表示,则用户i和用户j之间的相似性sim(i,j)为:
sim(i,j)=
(3)
通过用户相似性计算,并对计算结果整合,则得到用户相似度矩阵。基于用户相似度矩阵,推荐算法找到目标用户的邻居用户,并根据邻居用户评分数据对目标用户产生推荐。
2.传统相似性度量方法存在的问题

显然,基于所有评分数据对相似度矩阵进行完全更新代价太大,尤其是在具有海量用户和海量商品的系统中,问题会更加严重。为此,本文从算法增量更新的角度进行研究,提出了一个可以对矩阵进行在线局部更新的协同过滤算法。该方法可以只使用发生变化了的评分向量,而不需要其他的评分向量的参与,通过一定的运算对矩阵进行在线局部更新。此方法在保证算法准确性的基础上大大提高了算法的可扩展性。
三、基于增量更新的协同过滤算法
1. 用户相异度
本文将提出一个新的概念——用户相异度,其理论基础来源于Daniel在2005年提出的Slope One算法。在文献[11]中,Daniel提出了“物品相异度”的概念,而“用户相异度”是对它的一个变形。
物品相异度是用于衡量物品相异程度的指标,它基于同一用户对不同物品的评价,通过评分相减计算得出。给定一个训练集x,以及任意两个物品i和j,用户u对它们的打分分别为ui和uj,Sj,i(x)表示训练集中同时对物品i和j打过分的用户集,u∈Sj,i(x),card(Sj,i(x))表示用户数量,则物品i与j的物品相异度计算如下:
(4)
可见,对于物品i和j,假如若干用户对它们的打分均十分接近,则它们的物品相异度小,反之则大。物品相异度是对用户评分矩阵从用户维度上进行分析得到的一个结果。如果从物品维度上来看,将得到用户相异度。
用户相异度:用于衡量用户偏好相异程度的指标,它基于不同用户对同一物品的评价,通过评分相减取绝对值计算得出。给定一个训练集,以及任意两个用户a和b,用户a和b都对物品i打过分,用户a对物品i的打分为ai,用户b对物品i的打分为bi,Sb,a(x)表示训练集中同时被用户a和b打过分的物品集,i∈Sb,a(x),card(Sb,a(x))表示物品数量,则用户a与b的用户相异度计算如下:
(5)
可见,对于任意两位用户,假如他们在若干个物品上的评分都十分相近,那么他们的用户相异度就小,反之则大。当两两用户间的相异度都计算出来之后,则得到用户相异度矩阵。
2.算法流程
(1)输入数据
算法的输入数据为用户—物品评分数据集,该评分数据集是一个m*n阶的矩阵,记为A(m,n)。行代表m个用户,列代表n个物品。第i行第j列的元素ri,j表示用户i对物品j的打分,见表1。

表1 用户—物品评分矩阵
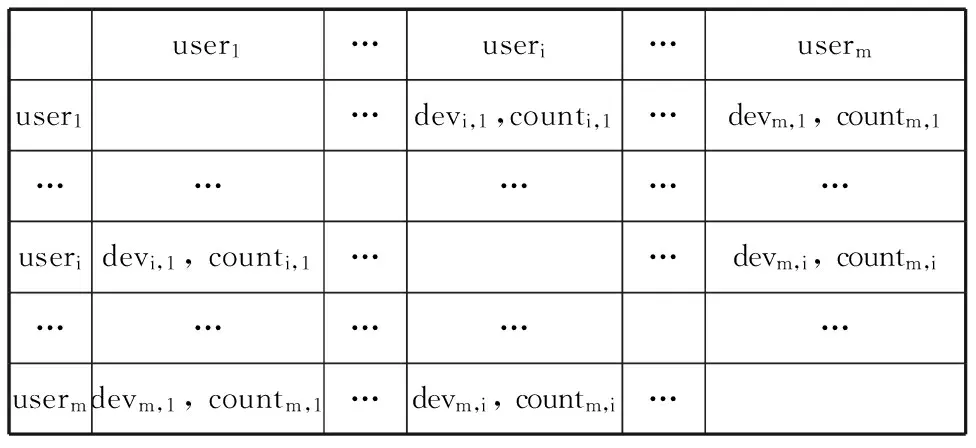
表2 用户相异度矩阵
(2)构建用户相异度矩阵
通过公式(5)可以计算出两两用户间的相异度,从而得到用户相异度矩阵,如表2。其中dev表示用户相异度,count表示同现次数(即两个用户同时打分过的物品的数量)。这是一个对称矩阵,可以只存储上三角或下三角以优化性能。
(3)在线推荐
通过相异度矩阵可以得到目标用户的最近邻居,选择最近邻可以通过设定阈值的方式进行,比如选取用户相异度小于1并且同现次数大于5的用户作为最近邻。下一步就是根据邻居用户的评分对目标用户产生相应的推荐。设用户u的最近邻居集为NNu,则用户u对项目i的预测评分pu,i可以通过用户u的最近邻居集NNu中的项目评分得到,计算方法如下:
(6)
公式中使用同现次数count作为权重,ru’i表示邻居用户u’对项目i的评分。最后将预测结果按降序排序,产生Top-N推荐。
3.算法的增量更新
增量更新是指在进行更新操作时,只更新需要改变的地方,不需要更新或者已经更新过的地方则不会重复更新,增量更新与完全更新是相对的概念。
上文已经分析了传统相似度矩阵的更新方式,它是完全更新的过程。而用户相异度矩阵则是一个增量更新的矩阵,它可以在线局部更新。矩阵的每次更新最少可以只使用一个评分向量,而不需要与其他评分向量相互运算。若新增评分,则评分向量发生变化,此时系统对变化的评分向量进行标记,同时算法程序对被标记的向量进行调用,然后运算并局部更新矩阵。其具体更新策略如下:

那么对a与b之间的用户相异度的更新方法如下:
devb,a=dev'b,a+|bi-ai|
(7)
dev'b,a为旧的用户相异度。devb,a更新后,countb,a同时加1。处理完一个向量后取消标记并处理下一个被标记的评分向量。当然,也可以根据需要一次处理若干个或所有标记向量。但不管怎样,对于矩阵的更新,已经不再需要运用所有评分数据来进行完全更新了,而是基于变化的评分向量的局部更新,从而实现了算法的增量更新,大大提高了算法的可扩展性。
四、实验结果和分析
1.实验数据集
实验数据采用美国明尼苏达大学GroupLens项目组提供的MovieLens100K数据集(http://grouplens.org/)。MovieLens是一个基于Web的研究型推荐系统,通过用户对电影的评分进行电影推荐。MovieLens100k包含943位用户对1 682部电影的十万条评分数据,其中每个用户至少对20部电影进行了评分,评分值为1~5的整数。本次实验采用五折交叉验证法,把数据集分成五份,轮流取一份做测试集,其他四份做训练集。
2.度量标准
评价推荐系统质量的度量标准主要包括统
计精度度量方法和决策支持精度度量方法。统计精度度量方法中的平均绝对误差(Mean Absolute Error,MAE)易于理解和计算,可以直观地对推荐质量进行度量,是最常用的一种推荐质量度量方法。本文将采用MAE作为度量标准。设目标用户的预测评分集合为{p1,p2,…,pn},对应的实际评分集合为{q1,q2,…,qn},则平均绝对误差MAE定义为:
可见,MAE是通过计算目标用户的预测评分与实际评分之间的偏差,来度量预测的准确性。因此,MAE值越小,说明预测评分与实际评分越相近,预测精度越高。
3.结果及分析
IU-UserCF算法中存在两个变量:用户相异度dev和同现次数count。依据单一变量原则,实验需测定:①在DEV一定的情况下,count变化对结果的影响;②在count不变的情况下,dev变化对结果的影响;③通过实验确定一组阈值,并将其得出的MAE值与其他算法进行比较。
(1) 同现次数对结果的影响
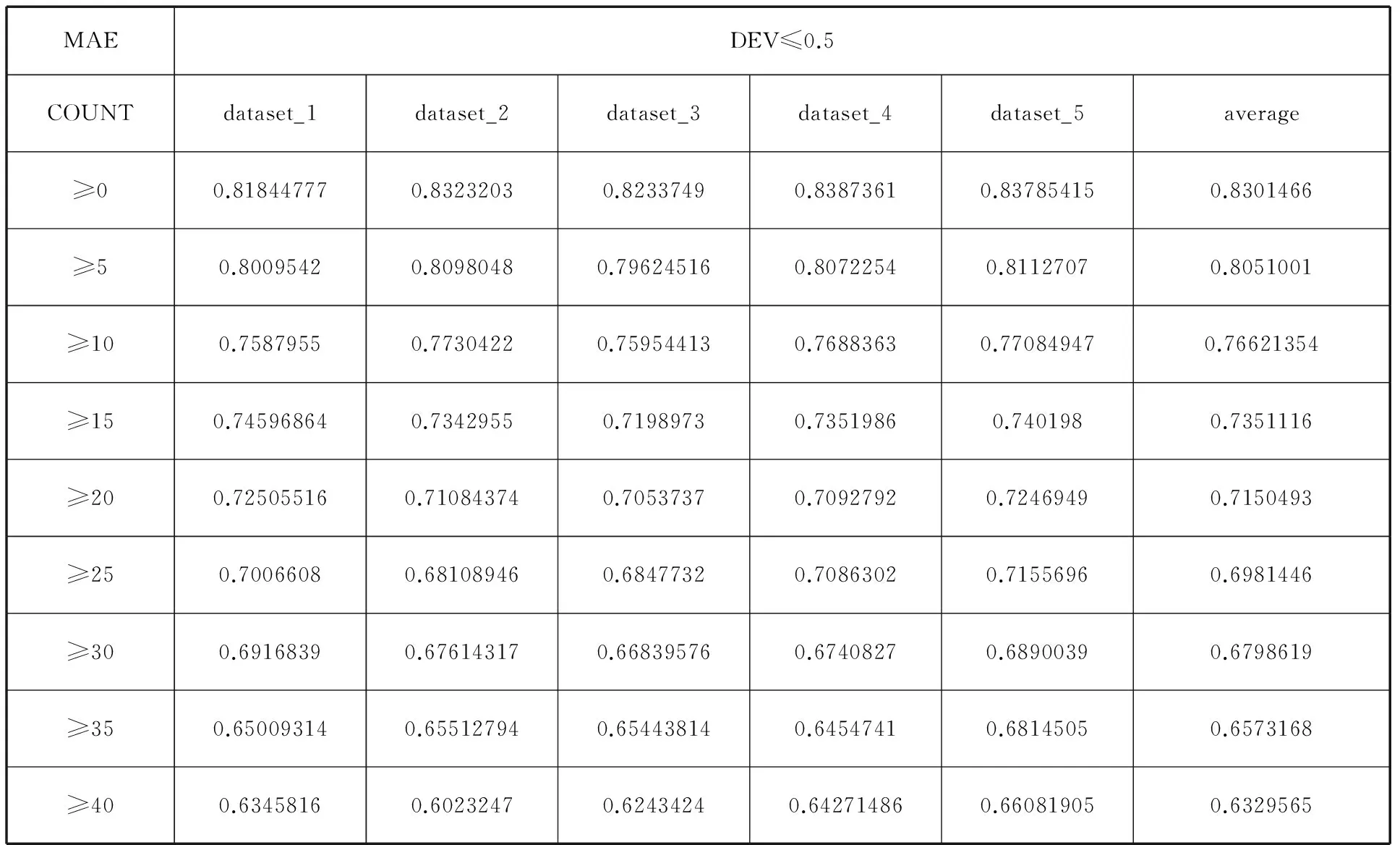
表3 同现次数对IU-UserCF预测结果的影响
从表3 average列可以看出,在dev不变的情况下,随着count的递增,MAE值呈下降趋势。因为同现次数越大,得到的邻居用户与目标用户会越相似,对预测能产生积极的影响,这从实验结果也能体现出来。但需要注意的是,同现次数不宜设置过大,过大的同现次数可能会使部分用户无法找到邻居。实际使用中应根据数据集的特点进行调整,以取得一个最优值。
(2)用户相异度对结果的影响
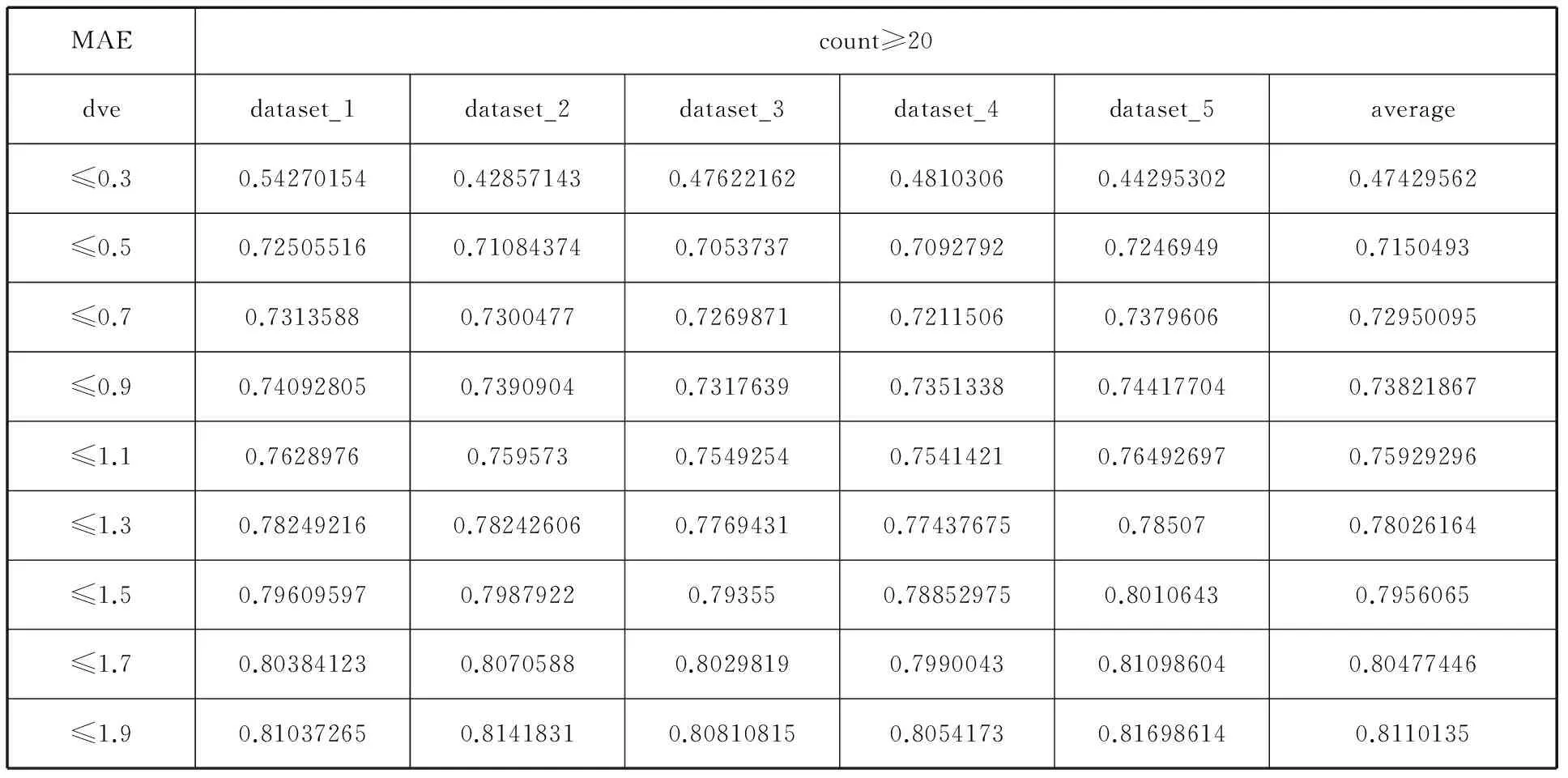
表4 用户相异度对IU-UserCF预测结果的影响
从表4 average列可以看出MAE值呈逐步上升的趋势。因为用户相异度设置过大,找到的邻居会比较多,其中掺杂较多并非很相似的邻居,从而影响预测的准确性。而在用户相异度较小的时候,找到的邻居相似度极高,因此预测精度高。但即便如此,也并非说用户相异度取值越小越好,因为过小的用户相异度可能会使部分用户无法找到邻居,从而也无法对其产生推荐。实际使用中应结合具体情况进行调整。
(3)算法MAE比较
本组实验使用IU-UserCF算法与几种常见推荐算法进行比较。根据之前实验,本文算法将采用阈值为:dev≤0.5 count≥35,即作为目标用户邻居的条件是:与目标用户的相异度小于等于0.5,并且与目标用户共同评价过35个及以上的相同物品。IU-UserCF算法在该阈值下得到的MAE值为0.6573168。参与比较的算法包括:基于项目的协同过滤(ItemCF)、Slope One加权算法(WEIGHTED Slope One)[11]、基于用户的协同过滤(UserCF)(近邻数为20)[12]和基于奇异值分解的推荐算法(SVD)[13]。实验结果如图1所示。
从图1可以看出,本文提出的IU-UserCF算法MEA值是最低的,在预测准确性上高于其他几种算法。由此可知,本文提出的算法不但可以增量更新,具备良好扩展性,并且具有很高的推荐准确性,可以有效提高推荐系统的性能及推荐质量。

图1 IU-UserCF与其他算法准确性比较
五、结语
传统的协同过滤推荐算法使用余弦相似性、皮尔逊相关系数等相似性度量方法构建矩阵,但这会存在着矩阵不能在线局部更新的问题。每一次对矩阵的更新都是基于所有数据的计算然后完全更新,这势必会对推荐系统造成严重的扩展性问题。针对此问题,本文提出了一种基于增量更新的协同过滤推荐算法IU-UserCF。IU-UserCF算法不但可以基于变化的评分向量在线局部更新矩阵,并且经实验证明具有很高的推荐准确性,很好地解决了推荐系统面临的扩展性问题。另外,由于本文中的邻居集是基于阈值的设定动态生成的,可能会造成部分用户邻居很多,部分用户邻居则较少甚至没有邻居的情况。因此,下一步的工作可以考虑从固定邻居数、动态阈值等角度出发,进一步优化目标用户邻居集,以取得更高的推荐准确性。
参考文献:
[1]刘建国, 周涛, 汪秉宏. 个性化推荐系统的研究进展.自然科学进展,2009,19(1):1-15.
[2]冷亚军, 陆青, 梁昌勇. 协同过滤推荐技术综述. 模式识别与人工智能, 2014,27(8): 720-734.
[3]Herlocker J.Clustering Items for Collaborative Filtering.Proceedings of the Acm Sigir Workshop on Recommender Systems,1999.
[4]Sarwar B M, Karypis G,Konstan J,et al.Recommender systems for large-scale e-commerce: Scalable neighborhood formation using clustering. Conference on Computer and Information Technology,2002.
[5]邓爱林,左子叶,朱扬勇.基于项目聚类的协同过滤推荐算法.小型微型计算机系统,2004,25(9):1665-1670.
[6]Tao L I,WANG Jian dong,YE Fei yue, et al.Collaborative filtering recommendation algorithm based on clustering basal users.Systems Engineering & Electronics,2007,29(7):1178-1182.
[7]Vozalis M G,Margaritis K G.Using SVD and demographic data for the enhancement of generalized Collaborative Filtering. Information Sciences,2007,177(15):3017-3037.
[8]Chen G,Wang F,Zhang C.Collaborative Filtering Using Orthogonal Nonnegative Matrix Tri-factorization.Data Mining Workshops,2007.Seventh IEEE International Conference on.IEEE,2007:303-308.
[9]Yu K, Schwaighofer A, Tresp V, et al. Probabilistic memory-based collaborative filtering. Ranaon on Nowldg & Daa Ngnrng, 2004,16(1):56-69.
[10]Acilar A M, Arslan A. A collaborative filtering method based on artificial immune network.Expert Systems with Applications, 2009, 36(4):8324-8332.
[11]Lemire D, Maclachlan A. Slope One Predictors for Online Rating-Based Collaborative FilteringSDM. 2005,(5): 1-5.
[12]董丽,邢春晓,王克宏.基于不同数据集的协作过滤算法评测.清华大学学报:自然科学版,2009,49(4):590-594.
[13] Anil R, Dunning T, Friedman E. Mahout in action. Shelter Island:Manning,2011.
责任编校:田旭,马军英
Collaborative Filtering Recommendation Algorithm Based on Incremental Updating
FANG Fang, YAN Ke-wen
(School of Management, Hefei University of Technology, Hefei 230009, China)
Abstract:In order to solve the problem that the similarity matrix of the traditional collaborative filtering recommendation algorithm cannot update partial. A collaborative filtering recommendation algorithm based on incremental updating is proposed. First, the algorithm constructs user-deviation matrix according to the user rating data. And then it selects a number of users whose user-deviation with target user is small and the co-occurrence times is high as nearest neighbor and generates recommendations. This algorithm can update partial for the deviation matrix online. It doesn't have to import all the data to recalculate offline. It implements the incremental updating of the algorithm, which makes it has a good scalability. The experiment result shows that the collaborative filtering algorithm proposed by this paper has very high recommendation accuracy.
Key words:personalized recommendation; collaborative filtering recommendation; E-commerce; user-deviation; incremental update
收稿日期:2016-04-05
基金项目:国家自然科学基金面上项目(61474035);安徽省科技攻关项目(1206c0805039);教育部博士点新教师基金(20130111120030)
作者简介:方芳,女,安徽合肥人,博士,讲师,研究方向为决策优化、系统芯片测试。
DOI:10.19327/j.cnki.zuaxb.1007-9734.2016.03.019
中图分类号:F713.36
文献标识码:A
文章编号:1007-9734(2016)03-0112-06
