基于Hadoop云计算平台的文本处理算法的研究与改进
2016-06-27陈静
陈 静
(1. 同济大学 上海200092;2. 天津中石化工物流有限公司 天津300270)
基于Hadoop云计算平台的文本处理算法的研究与改进
陈 静1,2
(1. 同济大学 上海200092;2. 天津中石化工物流有限公司 天津300270)
Hadoop是Apache基金会下的一个开源分布式计算平台,以分布式文件系统HDFS(Hadoop Distributed File System)和 MapReduce分布式计算框架为核心,为用户提供了底层细节透明的云分布式基础设施。在对 Hadoop进行深入分析和研究的基础上,搭建基于 Hadoop的云计算平台,并完成分布式文本文件处理任务以及对文件文本内容处理算法的改进和实现。
云计算 Hadoop 数据去重算法 HDFS MapReduce
0 引 言
云计算是一种按使用量进行付费的模式,这种模式提供可用、便捷、按需的网络访问,使用可配置的计算资源共享池,共享池的资源包括网络、服务器、存储、应用软件、服务等,这些资源能够通过云计算平台快速提供给客户。它是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物,被称为是继大型计算机、个人计算机、互联网之后的第4次IT产业革命,将成为带动IT、物联网、电子商务等诸多产业强劲增长、推动信息产业整体升级的基础。而Hadoop是Apache基金会下的一款开源软件,实现了包括分布式文件系统和MapReduce框架在内的云计算软件平台的基础架构,并且在其上整合了包括数据库、云计算管理、数据仓储等一系列平台,已成为工业界和学术界进行云计算应用和研究的标准平台,旨在帮助更多的企业和个人认识和了解云计算相关技术,并利用此技术解决自身问题,从而带来一定的经济效益。
1 研究内容
本系统从 Hadoop的核心技术 HDFS、MapReduce和 HBase入手,深入理解其工作流程,在对Hadoop的核心组件 Hadoop分布式文件系统 HDFS和分布式计算模型 MapReduce进行深入分析、研究的基础上,搭建基于 Hadoop的云计算平台,通过实验有效验证该平台可以完成分布式文本文件处理任务以及对文件文本内容处理算法的改进。
2 Hadoop相关技术研究
2.1 HDFS
Hadoop采用的是分布式存储结构,读写速度有了极大的提高。同时是基于 Java语言来开发的,其HDFS分布式文件系统具有高容错的特性和超强的数据管理能力,图1为HDFS体系结构图。
2.2 MapReduce
在Hadoop中,每一个MapReduce的任务都被初始化为一个job,每个job又可分为map和reduce阶段。它们可用两个功能函数来表示,即 map函数和reduce函数。map函数负责接收<key,value>形式的输入,然后产生同形式的中间输出结果,之后Hadoop将中间结果集合到一起传递给 reduce函数,reduce函数再去接收<key,(list of values)>形式的输入,最后进行并行处理。图 2描述了 MapRe-duce处理大数据集的具体流程。

图1 HDFS体系结构图Fig.1 HDFS system structure
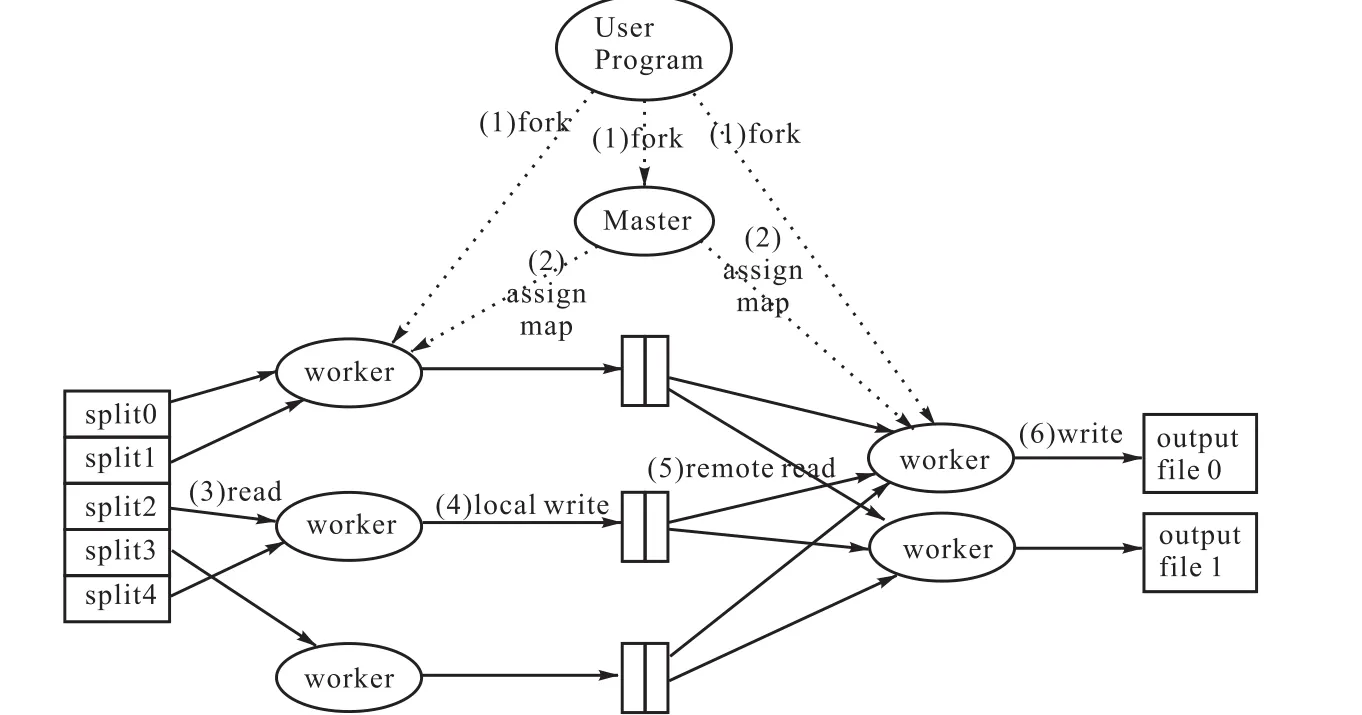
图2 MapReduce处理过程Fig.2 MapReduce treating process
2.3 HBase
Hadoop的第3大核心技术就是 HBase,它是一个面向列的分布式数据库,同时也是一种开源数据库。相对于普通数据库,HBase非常适合于非结构化的数据存储。HBase还是一种基于列的模式存储。
3 系统环境搭建
云计算平台机群中包括3个节点:1个Master和2个 Slave。节点之间采用局域网连接并且相互之间可连通。
这3个节点上均是CentOS6系统,Master虚拟机主要扮演NameNode和JobTracker的角色,另外的两台 Salve虚拟机扮演 DataNode和 TaskTracker的角色。
3.1 Hadoop集群安装
进入hadoop的安装目录,进入配置目录conf。
修改hadoop-env.sh文件。
修改core-site.xml文件。
修改hdfs-site.xml文件。
修改mapred-site.xml文件。
修改masters和slaves文件。
向各个节点复制Hadoop:

3.2 Hadoop集群成功截图
在浏览器里地址栏输入“http://hadoop001∶50030/”,显示结果如图3。
图3 50030界面Fig.3 50030 interface
在浏览器里地址栏输入“http://hadoop001∶50070/”,显示结果如图4。

图4 50070界面Fig.4 50070 interface
这样就完成了Hadoop集群平台的搭建。
4 WordCount算法研究与改进
4.1 运行WordCount程序
创建本地示例文件。在 HDFS上创建输入文件夹。上传本地 file中文件到集群的 input目录下。在集群上运行 WordCount程序。以 input作为输入目录,output目录作为输出目录。已经编译好的WordCount的Jar在"/usr/local/hadoop"下面。
此时可以通过之前搭建好的 Hadoop集群环境http://192.168.80.101∶50030/jobtracker.jsp的守护进程监控 MapReduce具体的运行进度情况,如图 5所示。

图5 50030界面Fig.5 50030 interface
4.2 改进WordCount算法程序
本文在对 Hadoop 分布式并行程序有了比较深入的了解之后,将 WordCount 程序改进成具备以下两点功能的程序:①改进后的程序不仅能够满足单词不区分字母大小写,还能正确切分单词;②最终的运算结果将会按单词出现的次数降序排序。
4.2.1 修改Mapper类,实现目标①
要实现目标①需修改 Mapper类,它需要实现Mapper 接口中的 map 方法。输入的参数中值代表文本文件中的一行,利用 StringTokenizer方法将文本中的字符串拆成N个单词,接着将样式为<单词,1>的输出结果写到 org.apache.hadoop.mapred.OutputCollector,然后再实现 map和 reduce 函数的时候,只需要将其输出的<key,value>对放入OutputCollector即可。
4.2.2 实现目标②
此时需要利用Hadoop 任务管道传输能力,将词频统计的结果作为排序方法输入,并且按顺序依次执行这两个并行的计算任务。
为了实现按词频排序,需指定使用 InverseMapper 类作为排序任务的 Mapper 类,这个类的 map函数将输入的 key(单词)和 value(词频)互换后,然后作为中间结果输出。
还有一个需要解决的问题,即按降序进行排列。使用 Int Writable DecreasingComparator 类来实现,并指定 Comparator 类对刚刚输出数据中的 key进行排序:sortJob.Set OutputKey Comparator Class(Int Writable Decreasing Comparator.class)。
本文采用1篇英语作文做为测试数据,因为它满足混有大小写、混有各种标点符号的特点,截图如图6所示。

图6 测试数据英语作文截图Fig.6 Screenshot of English writing testing data
采用原先的 WordCount程序运行此测试数据并与改进后的运行结果作了对比,差异显而易见。如图7所示。
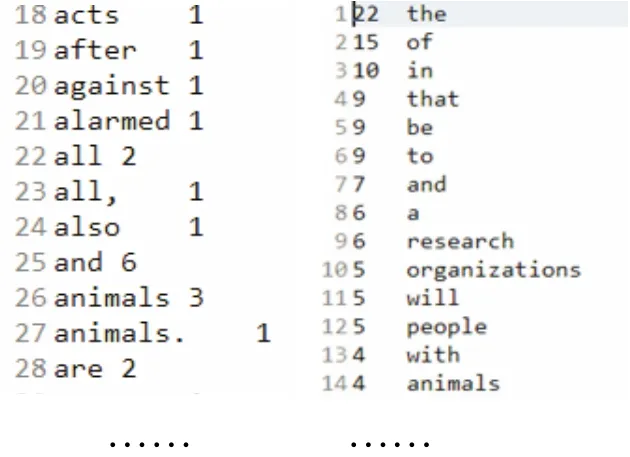
图7 运行结果对比Fig.7 Contrast of running results
4.3 文本数据去重算法研究
当利用 Hadoop进行数据去重时,方法通常是将相同数据的所有记录统一交给同一台 reduce机器,不论此数据出现几次,最后输出结果只输出一次。具体做法就是将 reduce的输入信息作为 key值,当reduce成功接收到一个<key,value-list>时,就立刻复制这个key值到输出的key值中,同时value被设置成空值即可。
当 MapReduce开始执行任务时,map的输出形式是<key,value>,经过 shuffle过程之后,聚集成<key,value-list>后会交给reduce。
运行成功得到图8所示的结果。

图8 数据去重结果Fig.8 Data duplicate removal results
4.4 分布式文本数据平均成绩算法研究
计算学生平均成绩其实就是一个模仿“WordCount”例子微变版本,同样,程序依然只包括两部分即 map部分和 reduce部分,目的在于实现map和reduce的功能。
和WordCount程序中的MapReduce部分的功能类似,map负责处理纯文本文件。Mapper处理的文本数据是让 InputFormat来分解成众多的小数据集,而每个小数据集又交给单独的 Mapper去统一处理。另外,InputFormat还提供 RecordReader的实现,InputSplit被它解析成<key,value>形式对交给map函数。Map的结果最后由partion传递给Reducer,待Reducer完成reduce操作后,以格式OutputFormat来输出。
Reducer收到 Mapper的最终处理结果<key,value>,它会进行合并,将带有相同的 key对交给同一个Reducer。Reduce的结果由Reducer.Context的write方法输出到文件中。然后放入Eclipse里进行调试。得到图9所示的结果。

图9 算平均成绩运行结果Fig.9 Running result of average scores
5 结 语
近几年,随着云计算技术的蓬勃发展,Hadoop作为云计算技术的一把利刃,已经被运用到诸多领域。本文对Hadoop的核心组件HDFS和MapReduce进行深入分析,搭建基于 Hadoop的云计算平台,通过实验有效验证了该平台可以完成分布式数据处理任务。
[1] 陈康,郑纬民. 云计算:系统实例与研究现状[J]. 软件学报,2009,20(5):1337-1348.
[2] 林清滢. 基于 Hadoop的云计算模型[J]. 现代计算机月刊,2010(7):114-116.
[3] HDFS [EB/OL]. http://hadoop.Apache.org/common/ docs/r0. 20. 2/hdfs_user_guide. Html.
[4] Wikipedia. Cloud Computing[EB/OL]. http://en. wikipedia. org/wiki/Cloud_computing.
[5] Wang Y D,Que X Y,Yu W K,et al. DhirajSehgal-Hadoop acceleration through network levitated merge[C]. Proceedings of 2011 International Conference for High Performance Computing,Networking,Storage and Analysis,2011.
A Hadoop Cloud Platform Based Text Processing Algorithm:Research and Improvement
CHEN Jing1,2
(1.Tongji University,Shanghai 200092,China;2.China Tianjin ZhongShi Chemical Logistics Co.,Ltd.,Tianjin 300270,China)
Hadoop is an open source distributed computing platform under Apache Foundation.Taking HDFS(Hadoop Distributed File System)and MapReduce distributed computing framework as the core,it provides users with details of transparent distributed cloud infrastructure of the lower tier.Based on an in-depth analysis and study of Hadoop,a Hadoopbased cloud computing platform was established and distributed text file processing tasks and algorithms were completed.
cloud computing;Hadoop text processing;data deduplication algorithm;HDFS;MapReduce
TP311.1
A
1006-8945(2016)01-0052-04
2015-12-16
