基于SVM和词向量的Web新闻倾向性分析
2016-06-22肖宇伦欧阳纯萍刘志明南华大学计算机科学与技术学院衡阳421000
肖宇伦,欧阳纯萍,刘志明(南华大学计算机科学与技术学院,衡阳 421000)
基于SVM和词向量的Web新闻倾向性分析
肖宇伦,欧阳纯萍,刘志明
(南华大学计算机科学与技术学院,衡阳421000)
摘要:
关键词:
0 引言
随着互联网的普及,网络上的信息量与日俱增,而这些信息多是以文本方式产生的,因此利用计算机对文本进行有效、准确的倾向性分析是一项非常有意义的研究课题。例如对商品评论进行褒贬分析,可以反映该商品是否受到消费者的青睐。新闻作为舆情的一个重要来源,反映了公众对某一事件的关注度,同时随着新闻的传播容易诱发网络舆情。从而对Web新闻倾向性进行全面、有效和准确地分析可以帮助有关部门对突发的舆情进行预警。
在对于篇章级的新闻文本进行倾向性分类上,黄萱菁等[1]认为若将篇章作为一个整体笼统地进行倾向性分析存在很大的局限,其主要缺陷在于文本中包含多个对象,而不同对象涉及到的主观信息是有差异的。因此目前针对篇章级文本的倾向分类的方法主要是对文本进行降维,降维后再以基于语义或基于机器学习的方法进行篇章倾向性分析。
在基于语义的篇章性分析中,左维松[2]等在进行分析时,将篇章拆分为句子,通过对句子的情感分析,得出篇章的情感倾向性。申晓晔等[3]在分析Web新闻倾向性时,选取文本中每个段落的情感倾向性强度最高的句子,作为代表该段的关键句。再根据关键句的位置及关键句所在段落位置计算关键句的权值,最后结合关键句的倾向值和权值得到篇章的倾向性。尤建清等[4]提出了基于主题句抽取的新闻文本倾向性分析方法,该方法通过分析新闻文本中的高频词、新闻标题、句子位置和倾向词等特征提取出文本的主题句,由主题句的倾向性作为整个篇章的倾向性。
基于机器学习的倾向性分析主要分为两个阶段:特征选择阶段和机器学习阶段。昝红英等[5]在特征选择时,将词汇的IDF与Χ2统计量结合起来,并采用SVM进行分类。在语料不平衡的情况下取得了较高的正确率。徐军等[6]在特征选择时,不仅考虑了词汇的TF和Binary一些统计特征,还结合了词汇的词性和否定词。分类器采用Naive Bayes和Maximum Entropy。实验结果表明在结合了文本的语义后,分类的正确率有一定的提高。Dongwen Zhang等[7]在对商品评价的分类上,将语料通过Word2Vec进行训练后,获取词汇的上下文信息,然后将词汇的上下文信息及词性作为特征,使用SVM进行分类。这种方法同样取得了较高的正确率。此外Google公司在2013年发布的一款用于训练词向量[8]的软件工具——Word2Vec。它可以根据给定的语料库,快速的将一个词语表示为向量形式。Word2Vec训练出的词向量的形式为distributed representation。一个distributed representation是一个稠密、低维的实值向量,它的每一维表示词语的一个潜在特征,该特征捕获了有用的句法和语义特性。由于词向量具有良好的语义特征,因此我们选取词向量和SVM来进行Web新闻的倾向性分析。
1 Web新闻的倾向性分析框架设计
对Web新闻文本的倾向性分析是指利用分类算法分析出该新闻的情感主题是褒义还是贬义,我们围绕这一目标主要完成以下工作:第一,对收集到的新闻语料进行分词,并通过Word2Vec进行训练,获得词语的词向量表示。第二,对需要分类的新闻文本,依次进行以下三个步骤:提取关键句、分词及词性标注及通过SVM进行分类。最后得到由SVM分类后的新闻类别。具体框架如图1所示。
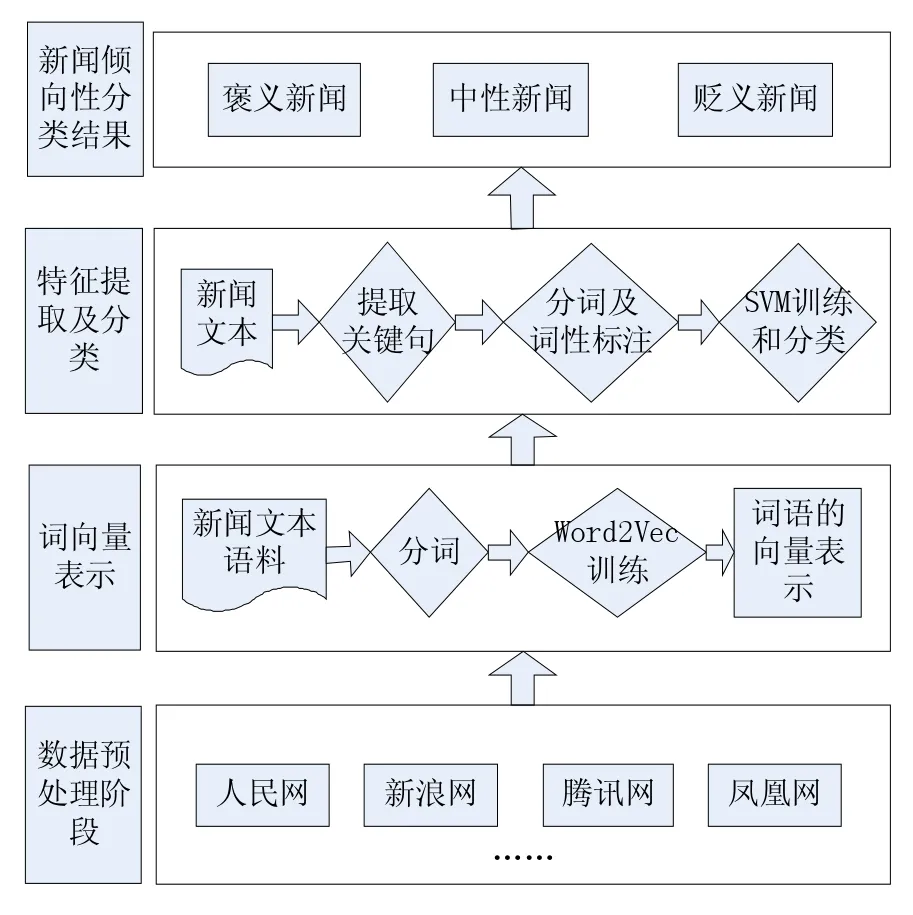
图1 系统功能框图
2 特征抽取及情感分类
2.1关键句的提取
由于新闻文本的特殊性,可以从文本中提取到一些其他文本所不具有的信息。因此以下三个影响因素被确定为选取关键句的标准。
(1)含有新闻文本标题中实词的句子
Web新闻标题不同于传统的报纸一样,讲究各种修辞表达方法、讲究生动形象和讲究对称有韵味等,而是以最简洁的语言以最直接的方式把主要新闻事实叙述出来。因此含有新闻文本标题中实词的句子跟新闻主题有一定的关联度,含有新闻标题中的实词越多的句子与新闻主题的关联度越大。
(2)含有主张词的句子
对Web新闻进行观察后,发现有这样的一类词,例如“认为”,“觉得”等,我们把这些词称为主张词。含有主张词的句子往往代表观点持有者的一种态度,具有强烈的倾向性。特别是在评论性的新闻文本中,例如:“我认为,事情到了今天这个地步,必须要回答下列问题——除了山西,别的地方还有多少类似的人道主义危机”。
(3)句子在文本中所处的位置
申晓晔等[3]在处理句子位置权值时,认为处于文章开头和结尾的句子相较于文本中的其他句子具有较高的权值。本文采取同样的方式。计算方式如下:

其中i是句子在文本中的位置,a是文本中所有的句子总数。
2.2倾向性句子的识别
(1)预处理阶段
由于要获取到某个词语在大多数文本中的句法和语义特性,因此本文预先选择大规模的新闻文本语料,然后通过Word2Vec进行训练,获得词语的词向量表示。在实验中,采用默认参数对新闻文本语料进行训练。
(2)特征选择
在分类算法中,词语的词性通常用来作为分类特征。不同词性的选择可能会导致分类结果的不同[9]。例如,如果只以形容词作为特征,分类结果并不会好于以名词、动词和形容词同时作为特征。这是由于不同的词性有不同的语义倾向[7]。因此,本文在对新闻文本进行分词和词性标注后,保留名词、动词、形容词和副词,以这些文本中出现频率最高的词性作为特征。
(3)SVM训练和分类
SVM(支持向量机)目前广泛运用于模式识别、知识发现、计算机视觉与图像识别和自然语言处理等技术中。在自然语言处理中SVM广泛运用于短语识别、词义消歧、文本自动分类、信息过滤等方面。本文采用台湾大学林智仁教授等开发的LIBSVM用于模型的训练和新闻文本的分类,训练采用LIBSVM提供的默认参数。核函数选择径向基核函数,以保证分类时不会出现太大的偏差,在无参调优的情况下能同时保证准确率和召回率[10]。
3 实验结果与系统实现
3.1实验结果
实验中训练词向量的语料和句子级的倾向性分析实验数据均来自于谭松波博士提供的10 000篇中文酒店评论语料。选取6000条评论语料,其中褒义类3000篇,贬义类3000篇,将训练数据和测试数据按2:1随机分配。实验结果如表1所示。

表1 基于词性特征的实验结果
从表2中可以看出,以名词、动词、形容词和副词作为特征进行分类,比单一特征具有较高的F值。同时又发现只以形容词做特征时,正面情感分类的正确率和负面情感分类的召回率都比较高,但F值相较于其他结果却比较低。这是由于大多数形容词具有明显的语义倾向,是倾向性分类的一个重要依据。但在形容词与否定副词结合后,原有的语义倾向发生了改变。因此只以形容词作为特征时,分类的综合性能较差。
3.2系统实现
本方法已在南华大学舆情监测系统倾向分析模块中实现,系统预先通过信息提取模块采集到2002年至2015年之间所有针对南华大学的新闻,新闻分别来自于人民网、腾讯网、新浪网、凤凰网等主流新闻媒体。然后对所有新闻进行倾向性分析,并按网站进行分类,分别得出每个网站在这段时间内对对南华大学有关报道的正负面新闻。
(1)获取文章关键句
倾向性分析模块每次从新闻中抽取3句话作为代表该新闻的关键句。以发表于新华网的《南华大学分专业靠抓阄引质疑回应称院领导酝酿讨论良久》新闻为例,分析得到关键句如图2所示。

图2 新闻关键句SVM分类
例如图2内三个句子进行分在获得新闻关键句之后,再通过特征提取,获取关键句的词向量表示,最后通过SVM进行分类,就可以得到每个关键句的倾向性。分类后,倾向性分别是1.0,-1.0,1.0,以1.0表示正面,-1.0表示负面。由此得出该篇新闻是一篇总体倾向为中性的新闻。
(2)新闻倾向性分析结果
在对搜狐、红网论坛、新浪等网站进行倾向性分析后,统计各个网站在一段时间内对南华大学褒、中、贬三种倾向的新闻报道的数量,分析结果展示如图3所示。

图3 新闻倾向性分析结果
4 结语
本文研究了对Web新闻倾向性分析问题,通过提取文章关键句,在大规模新闻文本下构建词向量反映词语的上下文含义,选择倾向性词语常用词性作为特征,采用SVM对关键句倾向性进行分类,最后以关键句倾向性反映Web新闻的倾向性。由于词语的词性不足以反应词语的语义倾向,下一步的工作将对特征选择的方法进行改进,进一步提高关键句的分类正确率。
参考文献:
[1]黄萱菁,赵军.中文文本情感倾向性分析[J].中国计算机学会通讯,2008,4(2):41-46.
[2]左维松.规则和统计相结合的篇章情感倾向性分析研究[D].硕士学位论文].郑州:郑州大学,2010.
[3]申晓晔,封化民,毋非.基于语义理解的Web新闻倾向性分析.in第四届全国信息检索与内容安全学术会议论文集(上).2008.
[4]尤建清,张仰森,童毅轩.基于主题句抽取的新闻文本倾向性分析方法.第十五届汉语词汇语义学国际研讨会.2014.中国澳门.
[5]Zan H Y,Guo M,Chai Y M,et al.Research on News Report Text Sentiment Tendency[J].Jisuanji Gongcheng/ Computer Engineering,2010,36(15).
[6]徐军,丁宇新,王晓龙.使用机器学习方法进行新闻的情感自动分类[J].中文信息学报,2007,21(6):95-100.
[7]Zhang,D.,et al.,Chinese Comments Sentiment Classification Based on Word2vec and SVM perf.Expert Systems with Applications,2015.42(4):p.1857-1863.
[8]Turian J,Ratinov L,Bengio Y.Word Representations:a Simple and General Method for Semi-Supervised Learning[C].Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.Association for Computational Linguistics,2010:384-394.
[9]Liu B,Zhang L.A Survey of Opinion Mining and Sentiment Analysis[M].Mining text data.Springer US,2012:415-463.
[10]刘铭,昝红英,原慧斌.基于SVM与RNN的文本情感关键句判定与抽取[J].山东大学学报(理学版),2014,49(11):68-73.
Web News Sentiment Analysis Based on SVM and Word Embedding
XIAO Yu-lun,OUYANG Chun-ping,LIU Zhi-ming
(School of Computer Science and Technology,University of South China,Hengyang 421000)
Abstract:
Proposes an approach for classifying the sentiment of news text based on SVM and Word Embedding.Firstly,word embedding is achieved by training the pre-collected news corpus with word2vec.Secondly,key sentences are constructed from some key words in news text.At last,the word embedding and key words' part-of-speech are selected as combination features to apply in SVM algorithm,and then the sentiment classification of news text is obtained.Experimental results show that SVM based on combination features has high F value in sentiment classification.
Keywords:
提出一种通过提取词向量,并利用机器学习对新闻文本进行分类的方法。首先,通过对预先收集好的新闻语料进行分析,获取到词的向量表示形式;然后通过新闻中的一些关键词提取出新闻的关键句;最后把词向量和关键句当中的关键词词性作为组合特征,采用SVM算法进行分类,得到新闻的倾向性类别。实验表明,基于组合特征的SVM文本分类方法具有较高的F值。
新闻倾向性分析;SVM;词向量;词性特征
基金项目:
湖南省哲学社会科学基金(No.14YBA335)
文章编号:1007-1423(2016)14-0052-04
DOI:10.3969/j.issn.1007-1423.2016.14.011
作者简介:
肖宇伦(1995-),男,湖南怀化人,本科,研究方向为自然语言处理
欧阳纯萍(1979-),女,湖南衡阳人,副教授,硕士生导师,研究方向为自然语言处理、语义网
刘志明(1972-),男,湖南浏阳人,教授,硕士生导师,研究方向为大数据分析、知识工程
收稿日期:2016-03-17修稿日期:2016-05-10
News Sentiment Analysis;SVM;Word Embedding;Part-of-Speech Feature
