主题爬虫的主题相关度算法研究
2016-06-22徐杨王未央上海海事大学信息工程学院上海201306
徐杨,王未央(上海海事大学信息工程学院,上海 201306)
主题爬虫的主题相关度算法研究
徐杨,王未央
(上海海事大学信息工程学院,上海201306)
摘要:
关键词:
0 引言
伴随着互联网的发展,网络资源日益丰富。传统通用搜索引擎的弊端日益突显,资源的覆盖率、搜索结果的准确性和相关性均有所下降,用户的搜索难度日益增大。于是,垂直搜索引擎应运而生,在近几年得到了快速的发展,并成为搜索引擎领域的发展的热点和难点之一。
对于搜索引擎而言,网络爬虫是核心模块。在传统搜索引擎中,网络爬虫将网络资源不加区分地爬取下来,然后通过以PageRank算法为核心的排序算法对网页进行打分,并按得分高低排序。而垂直搜索引擎则是针对特定主题的网络资源进行下载和整合的,具有更专业、更具体,以及更高的主题相关度。主题爬虫是垂直搜索引擎为用户提供高相关度检索结果的核心部分所在。
针对主题爬虫的主题相关度识别,本文提出一种利用两步向量空间模型算法的主题相关度识别的方法。第一步空间向量模型算法用于计算当前页面的主题相关度,第二步空间向量模型算法用于计算当前页面所包含所有出度链接的主题相关度,用于对当前待爬取链接进行排序,进一步确定主题相关度的高低,防止主题漂移。经实验表明,该爬虫在主题相关的识别的准确度和运行效率均表现良好。
1 相关知识
在传统主题爬虫中,主题相关度识别方法主要有基于内容的识别和基于链接分析的识别。
基于内容评价的搜索策略主要是根据链接页面内容与主题之间的相似度来评价链接价值的高低。主要以向量空间模型为基础,通过将页面文档映射成向量,与主题词集向量进行余弦值计算,然后将之与人为设定的阈值进行比较,高于阈值表示符合主题相关度,低于阈值则丢弃该页面。但是这种主题识别策略存在一定的问题,例如一些页面设置虚假关键词可能会导致相关度计算失真,并且忽略了链接在网络中的相互关系,如果爬虫继续爬去页面就会偏离主题。
而基于链接分析的主题爬虫主要以PageRank算法为基础,依靠PageRank算法来建立主题相关度模块。然而PageRank的算法模型是建立在随机访问基础之上的,也就是说用户浏览当前网页上的任意链接都是随机的,也由此假定所有链接被用户点击的概率都是相等的。但实际上往往并非如此,页面上的出链并不会被用户以相等的概率而访问,除此之外,更重要的是并非所有的出链都是符合主题相关度要求的,很容易造成“主题漂移”。因此主题爬虫的相关度并不能单纯依靠PageRank算法,需要引入更多的因子以提高主题爬虫的相关度,从而更好地改善垂直搜索引擎的发展。
有人提出结合遗传算法或者蚁群算法,引入网页的被访问数、创建时间等因子,但通常这些因子的获取都需要过程,而且许多参数因子难以获取,并且遗传算法的不断迭代的过程无疑延长了主题爬虫的抓取数据的过程和爬虫的执行效率。同时这种结合PageRank算法的主题识别方法要求以Web图结构为基础,而在爬取页面并提取其中的URL后,Web图也会相应地改变,所以计算量很大,会对爬虫的速度造成一定的影响,并且在爬虫爬行过程中,准确地计算出那些从来没有被访问过的网页的PageRank值几乎是不可能的。
在本文中依然采用向量空间模型作为页面相关度计算的基础,通过将页面向量与手工设定的主题关键词集向量的余弦值作为主题相关的大小,与阈值进行比较,而链接分析同样以向量空间模型为基础,通过计算页面中所有出度链接的主题相关度的余弦值,作为当前页面的主题相关度的加权系数,对待爬取链接进行相关度排序的同时进一步检测页面的主题相关度,防止“主题漂移”的产生,避免无关页面的下载影响爬虫的执行效率。
2 基于两步空间向量模型的主题爬虫策略
2.1主题词集确立
主题爬虫在工作前要确定该主题爬虫的相关主题词集。主题词集的确定通常有两种,一种是人工确定,另一种是通过初始页面分析所得。本文中采用人工确定主题词集,并为每个主题词指定不同的权值。主题词的个数作为主题向量的维数,而相应的权值则为主题向量的各个分量值。记主题词集向量为:K={k1,k2,…,kn}(n为主题词的个数)。
2.2页面相关度计算
为了确保页面与主题的相关度,尽可能避免“主题漂移”的发生,必须对页面进行主题相关度计算,这是主题爬虫至关重要的一个步骤,所以需要对链接所对应的页面中的文本信息进行提取,以便进行主题相关度的计算。
本文关于页面主题相关度的判别采用的是基于向量空间模型方法。向量空间模型概念简单,通过计算页面特征向量和主题中心向量的余弦距离来表示两者的相似度,从而对当前页面的主题相关度进行评价,直观易懂。在对页面预处理过程中,大量HTML标签的存在带来了一定的麻烦,但却可以加以利用,从而进一步提高页面相关度的预测。通常情况下,位于锚文本和标题处的文本信息要比在正文中出现的信息具有更高的重要性。因此,不同位置出现的关键词对页面信息的描述能力具有一定的差异性。那么,针对关键词出现的不同位置,需要对关键增加额外的权重位置权重,这样可以更好地反映页面与主题的相关度。关键词词频计算公式如下:

其中,wi代表不同位置的权重系数,fi表示关键词在该位置出现的次数。

解决了位置权重问题,就可以通过向量空间模型,将页面文本数据就转换成计算机可以处理的结构化数据,页面和主题词集之间的相似性问题转化成两个向量之间的相似性问题了。计算公式如下:
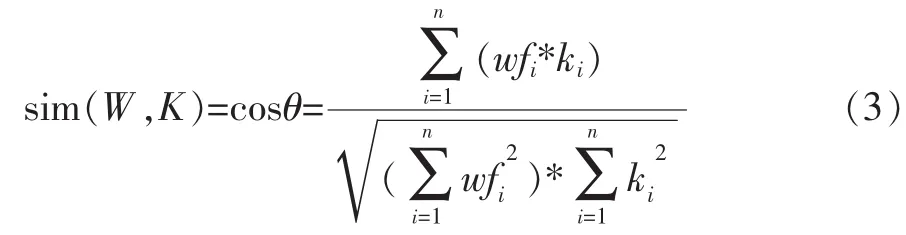
其中wfi表示页面文本特征项的第i项特征值,ki表示主题词集特征向量第i项特征值。相似度由向量的余弦值表示,用来衡量两个个体之间的差异的大小,当余弦值越接近1时,就说明夹角越接近于0度,也就表示两个向量越相似度越高,这也叫“余弦相似性”。
然而只运用向量空间模型算法对当前页面进行相关度计算,往往存在一定的问题。例如,页面中一些无关的友情链接的存在,虚假关键词的设置等等都会造成对主题相关度的误判,从而影响主题爬虫的前行,偏离主题。此外,在当前页面爬取完毕后,如何在待爬取队列中众多URL中选择下一个爬取链接也是一个至关重要的问题。所以,要同基于链接分析的相关性评价结合使用,综合考虑待分析链接之间的相关性。
2.3候选URL优先级排序
对候选URL进行优先级排序决定下一个爬行URL是主题爬虫需要解决的另一个关键问题。在传统主题爬虫策略中往往采用基于PageRank算法的策略,通过考查页面入度去计算链接之间的相互关系,对页面进行“打分”,然后根据相应的评分高低进行优先级排序。但其中存在的一些问题在第1节已经做出相关叙述。
那么,我们不妨考虑一下页面的出度。因为对于一个页面而言,出度是明确的。网页中所包含的出度链接,也就是指向其他页面的链接信息,是近几年研究中比较关注的对象,出度不仅反映页面之间的相互关系,并且对于判别页面的内容也具有很重要的作用。但是通过以往的研究表明,通过出度去研究页面的主题,也具有一些弊端,例如广告链接、版权信息、导航条以及一些无关的友情链接或者是一些恶意URL指向都可能造成判断失真。因此,需要对这些不可靠的噪声URL进行丢弃处理。
本文提出基于两步向量空间模型的主题爬虫策略,也就是在第一步判别页面的主题相关度后,并不直接对页面进行保留或丢弃处理,而是进一步判断该页面的出度URL页面的主题相关度来对其进行与主题相关度的加权判断。
然而存在一个问题,正如上文所述,在实际的情况中,页面的出度链接中可能会对应一些噪音页面,那么这些噪音页面给予待分析URL的支持是不可靠的,那么就需要进行过滤。考虑到两种情况,一种是待分析页面的出度URL对应页面集合中,大多数均有较高的主题相关度(此相关度仍用上节所述方法计算),但由少量出度页面具有极低的相关度或者不相关,那么直接丢弃该出度URL,出度数也做相应的减少。另一种情况是,所有出度URL页面集合均不具由高相关度,则直接忽略出度对待分析页面的相关度贡献。计算公式如下:

其中α为权重因子,score由页面主题相关度和页面出度URL对应页面相关度两部分组成,通过对score进行排序,从而选出下一个爬行的URL。举例如下:
如图1所示,假设初始URL由3个出度链接分别为a,b,c,而这3个候选URL又各自拥有3个出度链接。通过VSM计算,各页面的主题相关度如图2所示。那么基于传统向量空间模型策略的主题爬虫第二步就会去保存页面a,然后继续考察a页面中的出度链接。实际情况下这种a,b,c的候选URL排序可能是不合理的,按照本文所提出的策略,需要在对a,b,c三条链接排序时,先分别对候选链接a,b,c的所有子URL进行主题相关度计算,假设结果如图2所示,依据页面出度信息对页面主题相关度具有一定贡献的原则,对候选URL进行重新加权计算。按照公式(4)可以计算的到,a的页面的得分是0.7*0.9+0.3*((0.9+0.8+0.7)/3)=0.87(实验表明α取值0.7附近时效果较好,故此处α取0.7),同样,计算可得b,c的得分分别为0.65,0.76。通过公式3.1“打分”后,候选URL排序为a,c,b。

图1 网页Web简图
通过利用待分析页面出度URL相关度的分析,进一步确定待分析页面与主题的相关性程度,在一定程度上克服了页面恶意关键词的设置。此外,在一定程度上扩大了主题爬虫的在整个网络中的搜索范围,有利于引导主题爬虫穿越网络隧道,解决“隧道现象”,提高了主题爬虫的爬全率和爬准率。
3 实验结果及分析
3.1评估指标
对于主题网络爬虫性能的衡量,查全率和查准率是常用判断指标。它们可以定量化的考查主题爬虫的“过滤能力”,即判断页面“保留”还是“丢弃”的能力。但是,进一步分析,就会发现查全率的计算具有一定的困难。众所周知,在整个网络中的主题资源数量几乎是不可知的,那我们也就无从知晓检漏的页面数量。通过其它方式计算查全率又具有一定的不准确性,所以本文经不针对查全率进行计算。然而相当于查全率,查准率则要相对容易计算,查准率是指在已提取页面中与主题相关的页面数占所提取页面总数的比例。除此之外,时间维度也是判断爬虫性能的另一个至关重要的标准,从这个角度考虑,引入另一个考查标准,就是爬虫在不同时间所能爬虫到的相关页面数量。
综上所述,本文将采用查准率和不同时间点的执行情况作为主题爬虫进行考查标准。

图2 查准率结果比较

图3 时间维度结果比较
3.2实验结果分析
依据上节所述评估标准,将本文所提策略爬虫与传统VSM策略爬虫进行比较,以验证本文所提策略的可行性。实验以搜狐体育(http://sports.sohu.com)为初始URL入口,爬取与“中国足球”相关的页面。取关键词集:国足,亚冠,世预赛,足球,中超。搜索策略采用传统基于VSM策略和本文所提策略,结果如下:
(1)从查准率的角度来看,在爬取了不同数量页面的对比中可以发现本文改进策略的普遍高于传统VSM的爬虫策略。
(2)从时间的角度来看,在刚开始是基于本文策略的爬虫爬取的相关页面要略少,但随着时间的推移,优势会逐渐显现。这是因为本文的策略在计算复杂度上开销稍大,在短时间内虽然爬取页面的相关度比例要高,但是总数会略少,所以在开始的时间节点比较时,会有略微的劣势,但随着爬取时间的不断增加,优势会逐渐明显。
4 结语
本文提出了基于两步向量空间模型的主题爬虫策略。同时考虑了待爬取页面的主题相关度以及待爬取页面所包含的URL的主题相关度,通过对多一步的页面相关度分析可以减小恶意URL对主题相关度的“贡献”,同时也有利于解决当前页面低于主题相关度阈值,但经过子URL后进入一个高主题相关度的页面的“隧道现象”,防止相关页面的丢失。实验表明,此方法在主题相关度识别方面具有可行性,实验结果较好。但是关于阈值的设定以及关键词集的设置都将直接影响到主题爬虫的执行。因为单纯提高阈值,会造成一些页面访问不到;降低阈值,又会抓取大量不相关页面,主题词集的设置也直接影响到主题相关度的计算,应该提升到语义本体的层面。所以,这也将是下一步研究的重点。
参考文献:
[1]刘建明,郝志峰.垂直搜索引擎中的主题爬虫技术研究[D].广东:广东工业大学,2013.
[2]高琪,张永平.PageRank算法中主题漂移的研究[J].微计算机信息,2010.
[3]刘国靖,康丽等.基于遗传算法的主题爬虫策略[J].计算机应用,2007.
[4]张翔,周明全等.基于PageRank与Bagging的主题爬虫研究[J].计算机工程与设计,2010,31(14).
[5]黄正德,张文燚等.主题爬虫关键技术研究[D].哈尔滨:哈尔滨工程大学,2013.
Research on Subject Relevance Algorithm of Theme Crawler
XU Yang,WANG Wei-yang
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
Abstract:
The core issue of the theme crawler is the discrimination of the topic.In the process of crawling,the fast and accurate identification of the topic relevance of crawling pages is the key to decide the strategy of the search strategy.Proposed method of two step vector space model is used to identify themes.And compared two-step vector space model strategy with traditional one-step vector space model strategy.Experimental results show that the two step vector space strategy in to identify topic relevance and efficiency have better performance,also has a certain improvement on the“tunnel phenomenon”.
Keywords:
主题爬虫核心问题是主题的相关性判别问题。如何在爬取过程中,快速、准确地判别爬取页面的主题相关度,是决定主题爬虫搜索策略好坏的关键所在。提出利用两步向量空间模型计算的方法进行主题识别,并将基于两步向量空间模型的主题爬虫与传统基于一步向量空间模型的主题爬虫进行比较,实验表明基于两步向量空间的主题爬虫在主题相关度判别和执行效率方面都有较好的表现,同时对“隧道现象”也有一定的改善。
搜索引擎;网络爬虫;主题相关度;向量空间模型
文章编号:1007-1423(2016)14-0048-05
DOI:10.3969/j.issn.1007-1423.2016.14.010
作者简介:
徐杨(1989-),男,安徽合肥人,在读硕士研究生,研究方向为软件开发方法与软件项目管理
王未央(1963-),女,江苏常熟人,副教授,研究方向为数据处理与挖掘
收稿日期:2016-04-06修稿日期:2016-05-10
Search Engine;Web Crawler;Theme Relevance;Vector Space Model
