热红外与可见光图像融合算法研究*
2016-06-13李海超李成龙
李海超,李成龙,汤 进,2,罗 斌,2+
1.安徽大学计算机科学与技术学院,合肥2306012.安徽省工业图像处理与分析重点实验室,合肥230039
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2016/10(03)-0407-07
热红外与可见光图像融合算法研究*
李海超1,李成龙1,汤进1,2,罗斌1,2+
1.安徽大学计算机科学与技术学院,合肥230601
2.安徽省工业图像处理与分析重点实验室,合肥230039
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2016/10(03)-0407-07
E-mail: fcst@vip.163.com
http://www.ceaj.org
Tel: +86-10-89056056
* The National Natural Science Foundation of China under Grant No. 61472002 (国家自然科学基金); the National High Technology Research and Development Program of China under Grant No. 2014AA015104 (国家高技术研究发展计划(863计划)); the National Science and Technology Supporting Program of China under Grant No. 2012BAH95F01 (国家科技支撑计划).
Received 2015-05,Accepted 2015-07.
CNKI网络优先出版: 2015-08-11, http://www.cnki.net/kcms/detail/11.5602.TP.20150811.1515.002.html
摘要:融合热红外与可见光图像能够达到信息的互补,弥补单一模态在某些条件下的不足,因此具有较高的book=408,ebook=112研究和应用价值。采用了一种基于稀疏表示模型的热红外与可见光图像融合算法。首先,根据一定量图像样本学习出较为完备的字典。其次,对于给定的两模态图像对,通过稀疏表示模型在学习出的字典上分别对其进行稀疏表示。同时,为了提高鲁棒性,使用了拉普拉斯约束对表示系数进行正则化。然后,根据融合算法对两模态图像进行有效融合。最后,在公共的图像以及收集的图像上进行了实验,实验结果表明,该算法能够有效地融合两模态图像的信息。
关键词:多模态融合;稀疏表示;拉普拉斯正则化
1 引言
多模态图像融合是指将不同模态的传感器所采集到的关于同一场景的图像数据经过相关技术,最大限度地提取不同模态中的有用信息,最后合成新的信息量丰富的图像。热红外传感器是通过物体的热辐射(绝对零度以上)进行成像,对光照变化不敏感,能够很好地克服可见光传感器在特定条件下的不足,如低照度环境、雾霾等恶劣天气。因此,融合热红外与可见光图像有较高的研究和应用价值,被应用于诸多领域中,如图像增强、工业设备诊断和智能监控等。
常用的多模态图像融合方法包括加权平均融合[1]、分层PCA(principal components analysis)融合[2]和基于稀疏表示模型的图像融合[3-4]。加权平均融合对原图像的像素值取相同的权值,然后进行加权平均得到融合图像的像素值。但是,当待融合图像灰度相差较大时,该方法会出现明显的拼接痕迹并丢失大量原始信息。分层PCA的融合算法找到待融合图像的主成分,然后根据主成分来确定各待融合图像的权重。当待融合图像的近似图像存在一定差异时,PCA融合算法通常能够得到比较好的权重分配;但是当待融合图像的近似图像差异过大,即相关性较弱,往往不能准确地分配权重,甚至会导致图像严重失真。基于稀疏表示的融合算法得到的融合图像局部特征信息可能会出现丢失,还会因为局部特征差异造成完全不同的融合结果,所以得到的融合图像质量会受到一定损失。
为了克服以上问题,本文采用一种鲁棒的稀疏表示算法对热红外与可见光图像进行融合。首先,使用一定量的图像样本通过字典学习算法学习出字典。其次,给定待融合图像对,在学习出的字典上进行稀疏表示。为了提高鲁棒性,使用拉普拉斯约束对重构系数进行正则化。然后,使用最大值原则融合两模态的重构系数,进而结合字典重构出融合图像。实验表明,本文的融合结果优于其他方法。
2 稀疏表示模型简介
图像稀疏表示的目的是在给定的过完备字典中用尽可能少的非零原子来表示图像信号,获得信号更为简洁的表示方式,从而使人们更容易获取信号中所蕴含的信息,更方便进一步对信号进行加工处理,如压缩、编码等[5]。
假设信号向量xi∈Rn×1(i=1,2,…,n),字典向量φi∈Rn×1(i=1,2,…,m),并且m>n,每个向量φi表示一个字典原子。将字典原子作为字典Φ的列,字典Φ=[φ1,φ2,…,φm],ai∈Rm×1(i=1,2,…,n)为表示系数向量。信号可以表示为字典原子的近似线性组合,字典的线性组合提供更大范围的原子。这样一个字典是过完备的,被称为过完备字典[6]。字典的过完备表示在图像信号表示方面有很好的灵活性,且在信号处理时十分有效。
通俗地说,稀疏表示就是为了在过完备字典中找到最稀疏的表示。它是一个最优化问题:
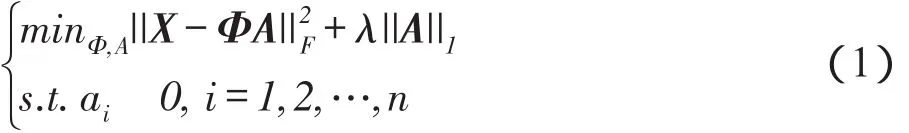
这里,A=[a1,a2,…,an]为表示系数矩阵,X=[x1,x2,…,xn]为信号向量集。式(1)中,λ||A||1用来保证表示的稀疏性。
目前,最常用求解该最优化问题的算法是OMP (orthogonal matching pursuit)算法[7],它在每次迭代中从字典中选择一个最匹配的原子来逐渐实现原始信号的稀疏逼近,可以减少迭代次数和重构误差。
3 基于鲁棒稀疏表示模型的多模态图像融合算法
本文通过字典学习算法独立地学习出字典,然后在学习得到的字典上对输入的各模态图像进行稀疏表示,分别得到各模态图像的表示系数。接着,融合各个模态图像的表示系数生成融合图像的表示系数,进而结合字典重构出融合图像。
3.1多模态图像字典学习
图像信号集X可以从原始图像中直接获得,但字典Φ却不能从原始图像中直接获得,因此本文通过学习得到字典。字典可以从一种模态的图像中学习得到,也可以从多种模态的图像中学习得到。本文选取了多种模态的图像作为学习样本,通过KSVD(K-singular value decomposition)算法[8-9]独立地学习出字典。具体方法如下:
首先,选择一定量各模态的图像作为学习样本。将其按照原子大小逐像素地分为大小为8×8的块,将图像块按照列向量方式排列成样本矩阵,构成样本X。字典学习目标函数为:
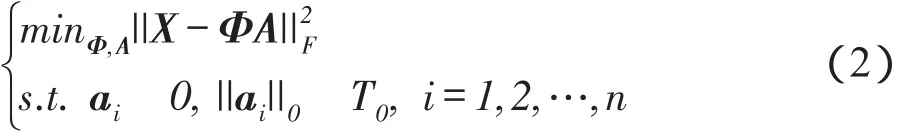
这里,T0为一个设定的阈值,当T0足够小时,得到的解是接近理想的。
其次,以DCT(discrete cosine transform)字典[10]作为初始化字典,X为样本数据,利用K-SVD算法学习出所需要的字典。
字典的生成是通过寻找稀疏表示下的最优基来完成的。原始图像信号能否尽可能地稀疏表示直接反映了生成字典的优劣,生成的字典要使图像信号更精确地表示。
本文采用的学习样本中包含待融合的图像。因此,学习得到的字典包含待融合图像的特征,更容易稀疏表示融合图像。
3.2鲁棒的稀疏表示模型
稀疏表示在特征量化上体现出了它的有效性。但也存在一定的局限性:第一,稀疏表示采用过完备字典编码,因此局部非常小的一个特征差异就会造成完全不同的稀疏编码。这将会影响图像最终的稀疏表示。第二,局部特征中的依赖信息在稀疏编码的过程中会有丢失。然而,这些特征在图像表示中是十分重要的。
为了更好地描述图像的局部特征,减小稀疏编码对局部特征的影响。本文引入拉普拉斯正则化[11-12]保证稀疏编码相似局部特征的一致性。鲁棒的稀疏表示模型可表示为:
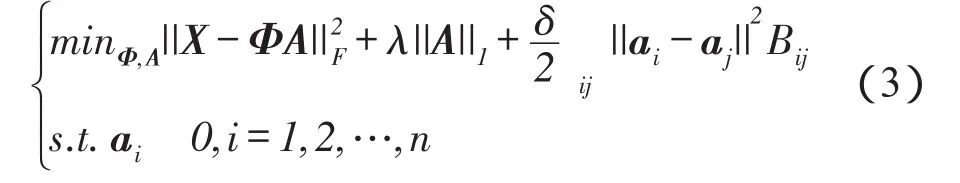
这里,δ用于调整正则化项;B表示一个二元矩阵,即表示两个特征的关系:若ai是aj的k近邻,Bij=1,否则,Bij=0。式(3)中最后一项可以转化为:
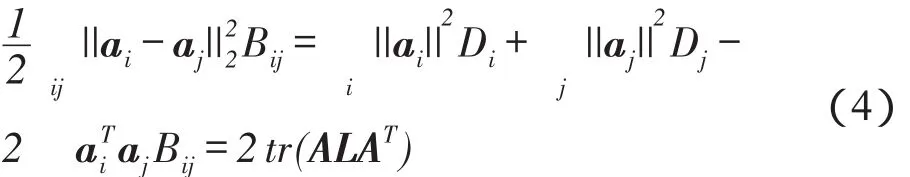
这里,L=D-B是一个拉普拉斯矩阵,ai的度定义为:
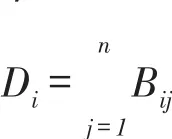
D=diag(D1,D2,…,Dn)(5)因此,式(4)可以写成:
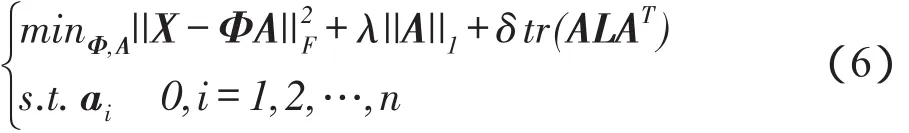
用1∈Rm(m表示ai中元素个数)表示ai中所有值都为0,并将列向量的值用ψ(ai)进行表示:
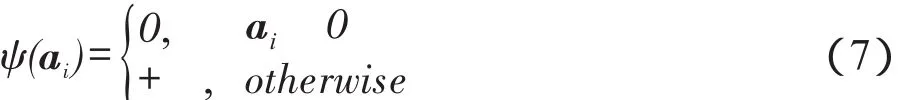
因此,式(6)可以写成:
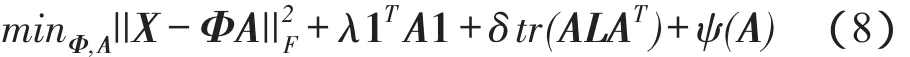
用APG(accelerated proximal gradient)算法[13]求解上述最小化问题。
3.3多模态图像融合算法
将多种模态图像进行融合为了最大限度地提取各模态中的有用信息,最后合成新的信息量丰富的图像,增强对场景的理解。本文采用基于鲁棒稀疏表示模型的融合算法对各模态图像进行融合。
假设I1,I2,…,Ik分别表示k种模态的图像。X1,X2,…,Xk分别为k种模态图像的向量化表示形式,其每一列,,…(i=1,2,…,k)对应原各模态图像I1,I2,…,Ik中的图像块,,,…,分别对应,,…,的表示系数,A1,A2,…,Ak为各模态图像的表示系数矩阵。
本文融合图像的过程如下:
(1)输入原始各模态图像I1,I2,…,Ik,通过滑动窗口技术[14]利用8×8的滑动块将各模态图像每隔1个像素从左上角滑动到右下角,将得到的滑动块图像向量化表示为X1,X2,…,Xk。
(3)选择表示系数矩阵A1,A2,…,Ak中相应的列,根据最大值原则,得到融合后图像的表示系数,进而得到融合后图像的表示系数矩阵AFusion。
(4)由学习得到的字典Φ,结合鲁棒的稀疏表示模型得到融合后图像的向量化表示XFusion。
(5)将融合后图像的向量化表示XFusion通过逆运算重新表示为8×8的图像块,此时得到融合后的图像。
在同一字典下,各模态图像的表示系数一定程度上反映了各模态图像中原子的活动水平,表示系数的绝对值越大,其对应的原子活动水平越高[15]。因此,本文采用最大值原则选择各模态图像中表示系数绝对值大的列,得到融合后图像的表示系数。最大值原则可表示为:
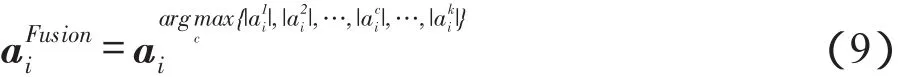
本文的融合算法主要包括3个步骤:字典学习、稀疏表示和多模态融合。首先,通过一定量各模态图像样本离线学习出字典。其次,通过鲁棒的稀疏表示模型得到各模态图像的表示系数。最后,结合字典重构出融合后的图像。
4 实验与分析
为了验证本文算法的有效性,在3对图像上进行实验,将加权融合算法、分层PCA融合算法和基于原稀疏表示模型的融合算法与本文算法进行比较。采用图像的熵、平均梯度和空间频率这3种指标对融合后的图像质量进行评价。具体地,图像的熵是一种具有加和性的状态函数,熵值越大,则信息量越大,也就说明效果更好。平均梯度反映了图像微小细节反差变化的速率,即图像多维方向上密度变化的速率,表征图像的相对清晰程度。平均梯度越大,图像层次越多,也就越清晰。空间频率是图像函数在单位长度上重复变化的次数,其值越大,则图像越清晰。
4.1定量分析
表1给出的是SourceImage数据集(http://www. imagefusion.org)、本文收集的数据集和OSU Color-Thermal数据集上部分图像的实验结果。通过表1可以得知,在上述数据集的几组图像上,本文融合算法得到的融合图像的熵均高于其他几种融合算法,且熵的平均值也高于其他几种融合算法,说明本文算法得到的融合图像信息量大于其他几种算法。另外,本文融合算法得到的图像平均梯度和空间频率的平均值高于其他几种融合算法,说明本文算法得到的融合图像相对更加清晰。实验表明本文算法有效地保留了原图像的信息,融合效果较好。
4.2定性分析
本文在之前所述的3个数据集上选取了部分图像进行实验,包括SourceImage数据集的SourceImage3 和SourceImage2,本文收集的数据集上的车和行人的场景,以及OSU Color-Thermal数据集的两组图像,实验效果如图1所示。
从图1中可以看出,加权融合算法对融合后图像的细节体现不太明显,丢失了原图像的一些原始信息。而分层PCA融合算法对热红外图像的热目标体现得比较明显,而对可见光信息表达较弱。
基于原稀疏表示模型的融合算法所得到的融合结果相比其他算法,图像从视觉上较为稳定,图像上各个像素波动较小,但对图像细节描述一般。与基于原稀疏表示模型的融合算法相比,由于本文的融合算法增加了拉普拉斯正则化项,其对图像细节反映较好,对两模态图像局部特征保留较好,图像总体信息量体现得较好。从总体上说,基于鲁棒稀疏表示模型的融合方法得到的融合图像质量较高,与实验数据分析一致。
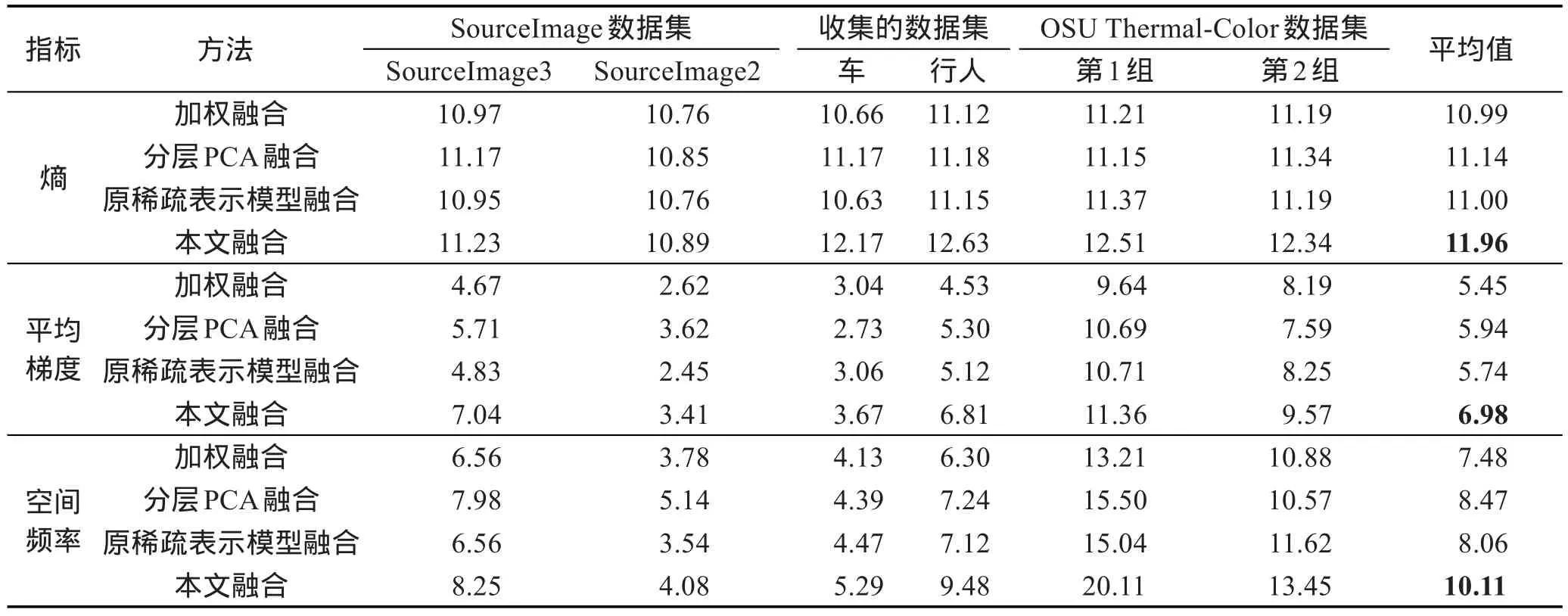
Table 1 Index of fusion images on three datasets using four fusion algorithms表1 4种融合算法在3个数据集上的融合图像指标

Fig.1 Fusion result images图1 融合效果图
5 结论
本文采用基于鲁棒稀疏表示模型的算法实现了热红外与可见光图像的融合,并运用常用的3种指标对融合图像的效果进行评价,通过对比实验,其融合后的图像指标优于其他融合方法。但由于基于稀疏表示的模型融合算法要进行字典学习和稀疏分解,该算法的时间复杂度较高,运算速度较慢。下一步,可对算法进行优化,提高算法的运算速度,进一步优化算法的性能。
References:
[1] Garcia F, Mirbach B, Ottersten B, et al. Pixel weighted average strategy for depth sensor data fusion[C]//Proceedings of the 17th IEEE International Conference on Image Processing, Hong Kong, China, Sep 26-29, 2010. Piscataway, USA: IEEE, 2010: 2805-2808.
[2] Patil U, Mudengudi U. Image fusion using hierarchical PCA [C]//Proceedings of the 2011 International Conference on Image Information Processing, Shimla, Nov 3-5, 2011. Piscataway, USA: IEEE, 2011: 1-6.
[3] Ding Meng, Wei Li, Wang Bangfeng. Research on fusion method for infrared and visible images via compressive sensing[J]. Infrared Physics & Technology, 2013, 57: 56-67.
[4] Li X, Qin S Y. Efficient fusion for infrared and visible images based on compressive sensing principle[J]. IET Image Process, 2011, 5(2): 141-147.
[5] Deng Chengzhi. Applications of sparse representation in image processing[D]. Wuhan: Huazhong University of Science and Technology, 2008.
[6] Chen S S, Donoho D L, Saunders M A. Atomic decomposition by basis pursuit[J]. SIAM Review, 2001, 43(1): 129-159.
[7] Tropp J A, Gilbert A C. Signal recovery from random measurements via orthogonal matching pursuit[J]. IEEE Transactions on Information Theory, 2007, 53(12): 4655-4666.
[8] Aharon M, Elad E, Bruckstein A M. The K-SVD: an algorithm for designing of overcomplete dictionaries for sparse representation[J]. IEEE Transactions on Image Processing, 2006, 54(11): 4311-4322.
[9] Aharon M, Elad M, Bruckstein A M. K-SVD: an algorithm for designing of overcomplete dictionaries for sparse representation[J]. IEEE Transactions on Signal Processing, 2006, 54(11): 4311-4322.
[10] Liu Yan, Li Hong. Image and video pressing techniques in the DCT domain[J]. Journal of Image and Graphics, 2003, 8 (2): 121-128.
[11] Zhuang Bohan, Lu Huchuan, Xiao Ziyang, et al. Visual tracking via discriminative sparse similarity map[J]. IEEE Transactions on Image Processing, 2014, 23(4): 1872-1881.
[12] Gao Shenghua, Tsang I W, Chia L T, et al. Local features are not lonely-Laplacian sparse coding for image classification[C]//Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, USA, Jun 13-18, 2010. Piscataway, USA: IEEE, 2010: 3555-3561.
[13] Bao Chenglong, Wu Yi, Ling Haibin, et al. Real time robust L1 tracker using accelerated proximal gradient approach [C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, Jun 16-21, 2012. Piscataway, USA: IEEE, 2012: 1830-1837.
[14] Yang Bin, Li Shutao. Multifocus image fusion and restoration with sparse representation[J]. IEEE Transactions on Instrumentation and Measurement, 2010, 59(4): 884-892.
[15] Yang Bin, Li Shutao. Pixel-level image fusion with simultaneous orthogonal matching pursuit[J]. Information Fusion, 2012, 13(1): 10-19.
附中文参考文献:
[5]邓承志.图像稀疏表示理论及其应用研究[D].武汉:华中科技大学, 2008.

LI Haichao was born in 1988. He is an M.S. candidate at School of Computer Science and Technology, Anhui University. His research interests include pattern recognition and digital image processing, etc.李海超(1988—),男,安徽合肥人,安徽大学计算机科学与技术学院硕士研究生,主要研究领域为模式识别,数字图像处理等。

LI Chenglong was born in 1988. He is a Ph.D. candidate at School of Computer Science and Technology, Anhui University. His research interests include pattern recognition, digital image processing and video analysis, etc.李成龙(1988—),男,安徽阜阳人,安徽大学计算机科学与技术学院博士研究生,主要研究领域为模式识别,数字图像处理,视频分析等。

TANG Jin was born in 1976. He received the Ph.D. degree in computer science from Anhui University in 2007. Now he is a professor and Ph.D. supervisor at Anhui University, and the member of CCF. His research interests include image processing, pattern recognition, machine learning and computer vision, etc.汤进(1976—),男,安徽合肥人,2007年于安徽大学计算机科学专业获得博士学位,现为安徽大学教授、博士生导师,CCF会员,主要研究领域为图像处理,模式识别,机器学习,计算机视觉等。

LUO Bin was born in 1963. He received the Ph.D. degree in computer science from York University in 2002. Now he is a secondary professor and Ph.D. supervisor at Anhui University, and the member of CCF. His research interests include large image database retrieval, image and graph matching, statistical pattern recognition and random graph model, etc.罗斌(1963—),男,安徽合肥人,2002年于英国约克大学计算机科学专业获得博士学位,现为安徽大学二级教授、博士生导师,CCF会员,主要研究领域为大规模图像数据库检索,图和图像匹配,统计模式识别,随机图模型等。
Research on Fusion Algorithm for Thermal and Visible Imagesƽ
LI Haichao1, LI Chenglong1, TANG Jin1,2, LUO Bin1,2+
1. School of Computer Science and Technology, Anhui University, Hefei 230601, China
2. Key Lab of Industrial Image Processing & Analysis of Anhui Province, Hefei 230039, China
+ Corresponding author: E-mail: luobin@ahu.edu.cn
LI Haichao, LI Chenglong, TANG Jin, et al. Research on fusion algorithm for thermal and visible images. Journal of Frontiers of Computer Science and Technology, 2016, 10(3):407-413.
Abstract:Fusion of thermal and visible images has a large research and application value due to their complementary benefits, which can overcome shortcomings of single modality under certain conditions. This paper adopts a sparse representation based algorithm to integrate thermal and visible information. Firstly, a relative complete dictionary is learned by some image samples. Secondly, given an image pair, this paper represents them on the learned dictionary by the improved sparse representation model, in which the Laplacian constraints on reconstructed coefficients are employed to improve its robustness. Then, the two modal images are integrated based on the constructed coefficients. Finally, extensive experiments on the public images and the collected images suggest that the method proposed in this paper can effectively fuse the information of two modalities.
Key words:multi-modal fusion; sparse representation; Laplacian regularization
doi:10.3778/j.issn.1673-9418.1506032
文献标志码:A
中图分类号:TP391.4
