基于影响力的微博新兴热点事件检测
2016-06-08李华朱荔
李 华 朱 荔
(重庆大学计算机学院 重庆 400044)
基于影响力的微博新兴热点事件检测
李华朱荔
(重庆大学计算机学院重庆 400044)
摘要从微博中准确高效地挖掘出正在发生的热点事件是近年来研究的热点。通过综合考虑微博用户的粉丝数量和微博本身的转发、评论次数计算每条微博的影响力,从而提出一种基于影响力的微博新兴热点事件检测方法IEED(Influence-Based Emerging Hotspot Event Detection)。该方法运用层次聚类将微博帖子聚类为事件集,并提取出事件中的关键词构成事件摘要。通过运用现实生活中的新浪微博数据作为实验数据集来测试所提出的方法,实验结果证明,基于影响力的微博新兴热点事件检测方法(IEED)能在早期高效地检测出微博中的新兴热点事件,具备一定的应用价值。
关键词新兴事件检测微博影响力聚类
0引言
微博作为一个新兴的社交媒体服务,是当前最流行的网络社交应用之一。国外最具代表性的微博平台是Twitter,在中国最具代表性的则是新浪微博(现已改名为微博),新浪微博全球注册用户已经超过6亿。
微博具有支持多平台终端的特点,人们可以随时随地发布自己的所见所闻,但是发布的信息不能超过140个字符,这使得微博产生大量贴近现实生活的数据。然而由于微博数据量十分巨大,用户无法通过阅读大量微博获取自己感兴趣的热点事件,因此对微博的海量信息进行挖掘,发现微博中的新兴热点事件能有效地帮助用户找到感兴趣的话题。 本文主要的研究方向是新兴热点事件的检测,定义新兴热点事件为何时(when)、何地(where)正在或者即将要发生的事件(what)。
新兴热点事件需要在正确的时间检测出来,特别是某些事件,如自然灾害、传染疾病和危害巨大的袭击等事件如果在早期就能检测出来能有效地帮助政府或者个人及时预防和处理相关事件,从而尽量减少不必要的伤害和损失。针对上述问题本文提出一种基于影响力的微博新兴热点事件检测算法IEED。该算法运用微博帖子的转发、评论次数和用户的粉丝数量计算微博的影响力,同时运用不同时间段发布的微博数量对事件的新兴程度进行界定,综合考虑进行新兴热点事件检测。
1相关工作
传统的文本话题发现方法是将文本看作向量,然后运用聚类的方法找出热点话题。当前多数事件检测研究工作都是针对文本新闻和网页新闻的,但是随着微博用户的迅速增长,微博文本的相关研究已经成为热点,针对微博事件检测的研究,国内外也已经取得了很多成果。
不管是针对新闻文本还是微博文本,事件检测的相关工作都主要是TDT(topic detection and tracking)[1]。微博事件检测方面国内外已有大量的研究。Sayyadi等人在文献[2]中提出了一种构造关键词图(KeyGraph)检测博客中事件的算法,算法检测效果显著,但是算法检测到的事件数量取决于阈值的设定,而且没有对得到的结果进行评估。Ozdikis等人在文献[3]中提出一种Twitter下基于主题标签(Hashtag)聚类的事件检测方法,但是在该方法中每个tweet只用一个主题标签标记,这样会忽略一些重要的事件。童薇等人在文献[8]中提出一种基于微博数据文本特征的事件检测算法(EMD),但是该算法没有增量地对事件进行检测。李凤岭等人在文献[9]中研究了基于LDA 模型的微博话题发现技术;郭跇秀等人综合考虑用户影响力和微博本身的文本特征和传播特征提出一种微博突发事件检测方法[11]。
在微博新兴标题和事件检测方面,国内外研究都很稀少。Cataldi等人在文献[4]中提出了一种检测新兴标题的方法,但是该方法需要运用到用户权限计算权值,在现实中用户权限是很难收集全的。Alvanaki等人提出一种跟踪标签关联项的新兴标题检测方法,开始的种子标签从当前滑动窗口选择获得[5]。Unankard等人在文献[6]中提出了一种基于位置信息的新兴热点事件检测方法,该方法检测效果很好,但是需要用到发布微博的位置信息,用户有可能不愿意透露自己的位置信息。
与上述方法不同,本文综合考虑微博的转发、评论次数及发布微博用户的粉丝数量,得到微博帖子的影响力,并运用微博帖子的影响力计算事件的热点值。同时考虑事件各个时间段包含帖子的数量对事件新兴性进行评定,提出一种基于影响力的微博新兴热点事件检测算法IEED。运用此算法能在早期有效的从微博帖子中检测出新兴热点事件。在进行事件摘要时提取出与主题最相关的关键词(what、where、who)、事件最早发帖时间(when),总结出事件摘要。
2IEED算法结构
本文的IEED算法主要分为三个步骤:微博数据预处理、微博文本聚类和新兴热点事件检测,算法的详细结构如图1所示。

图1 IEED算法结构
2.1微博文本预处理
微博文本通常简短且含有很多噪声数据,为了加快算法处理的效率和提高检测的精确度,在进行新兴热点事件检测之前需要对微博文本进行预处理,去除噪声数据,保留高质量的微博数据。微博数据主要由用户ID、用户名、发布时间、发布地址、内容、粉丝数量、转发次数、评论次数等组成,表1详细展示了新浪微博数据的字段。其中F表示该用户的粉丝数量(关注他的用户总数),R和C分别表示该条微博的转发、评论次数。

表1 新浪微博帖子字段
在微博帖子中提取出微博内容、发布时间、转发次数、评论次数和对应发布该微博用户的粉丝数量。对于提取出的微博内容去除hashtag、内嵌链接URL、表情符号、@后的用户名和转发标记”RT”,采用中科院提供的中文分词软件ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)[12]对微博内容进行分词,分词得到的结果去除中英文的停顿词(stopwords),过滤掉虚词和停用的词。最后去除剩余关键词少于三个的微博。预处理过后的微博可以表示为Di={wi,1,wi,2,…,Ri,Ci,Fu}。
2.2微博文本聚类
本文面对的问题是如何从给定的微博帖子中识别出事件。现实中一个事件往往对应多条微博,而在大多数情况下每条微博只讨论了一个事件,本文只考虑每条微博只讨论一个事件的情况。微博中讨论的事件的数量非常大,不知道到底有多少事件正在被讨论,因此本文运用层次聚类自动将微博帖子聚类为事件集。同时为了处理大量流入的微博文本,运用滑动窗口来跟踪控制微博文本流入系统,窗口的大小可以设定为文本的具体数量或者一定的时间段。本文运用时间段来定义窗口大小,如5小时。1天等,时间段的大小可以随着实际情况做出改变。此外,以前时间段的聚类事件会作为历史聚类记录在系统中,因为后面计算事件的新兴评分时会用到。
本文选用增强规范化词频[14]计算词汇在每个微博帖子中的权重,该方法能降低微博长度对权重计算的干扰,具体计算公式如下:
(1)
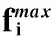
微博文本具有内容较短的特点,预处理后得到的词汇较少,本文选用余弦相似性函数计算已经存在的聚类和新进入系统微博帖子间的相似性,计算公式如下:
(2)
其中,Di是微博帖子i,C是聚类的中心点,wi,j是词汇j在Di中的权重。
本文选用引导者-追随者聚类[7]算法,当进入系统的微博帖子的时间跨度大于滑动窗口大小时,系统开始聚类。当新的微博帖子进入系统时,系统会计算它与已存在聚类之间的相似度,如果相似度大于预先设定的阈值时,记录下来,最后把微博加入与其相似度最大的聚类中(相似度大于阈值的聚类);如果微博文本和已存在的所有聚类的相似度都小于阈值,则建立一个新的聚类,将微博加入。计算微博帖子和已存在聚类的相似度时,每个聚类都用质心替代(质心的凝聚力很强,能代表该聚类),这有利于提高系统聚类的速度和效率。最后是聚类间的合并,合并最相似的聚类,计算聚类间的余玄相似性,如果相似度大于阈值,则合并两个聚类。
2.3新兴热点事件检测
2.3.1计算事件热点评分
新兴热点事件检测需要事件的热点评分,计算事件的热点评分需要用到微博影响力,本文综合考虑微博用户的粉丝数量和微博帖子的转发、评论次数得到微博帖子的影响力。
计算微博影响力评分InfScorei,需要微博用户的粉丝数量评分、微博转发和评论次数评分,定义微博用户粉丝数量评分FNScoreu的计算公式如下:
(3)
其中,Fu为用户u的粉丝数量,Fmax为粉丝数最多的用户的粉丝数量。因为现实中用户粉丝数量相差非常大,为了消除数量级之间的差距,对用户粉丝数量取对数,添加平滑因子1是为了保证对数底数大于0。
不同于Twitter,中国的微博用户中存在大量的僵尸粉和活跃度很低的用户,用户的粉丝数不能完全说明该条微博的影响力。所以微博影响力不能简单的只运用用户粉丝数来评定,因此本文加入微博的转发、评论次数更直观地说明微博的影响力,微博转发、评论次数评分RCScorei计算公式如下:
(4)
其中,Ri和Ci分别为微博帖子Di的转发次数、评论次数,取对数同样是为了消除数量级的影响;r为转发、评论次数之和取对数后的一个阀值,当微博的转发、评论次数之和取对数后的值大于该阀值时认为微博转发、评论次数评分为1。
运用粉丝数量评分和微博转发、评论次数评分计算微博帖子Di的影响力评分InfScorei,计算公式如下:
InfScorei=α×FNScoreu+(1-α)×RCScorei
(5)
其中,FNScoreu为发布该微博的用户粉丝数量评分,RCScorei为微博转发、评论次数评分,α∈[0,1]设置用户粉丝数量评分和转发、评论次数评分各自所占的比重,本文设置α=0.5。
最后,聚类事件C的热点评分HotScorec根据聚类中微博帖子的影响力计算得到,具体计算公式如下:
(6)
其中,Di为聚类C中发布的微博帖子,InfScorei为Di的影响力评分,NC是聚类C中包含的微博帖子数量,由前面的计算公式分析可以知道HotScoreC的取值范围为[0,1]。热点评分将会在接下来计算事件的新兴热点评分中用到,最终会选择出top-k评分的事件作为检测出的新兴热点事件推荐给用户。
2.3.2新兴热点事件检测
本文的研究的目的是为了检测出新兴热点事件,所有以前时间段发生的事件都不是新兴热点事件。现实生活中有些事件的微博发布数量增长得非常快但还是过去发生的事件,所以微博当前阶段发布的数量不能作为判定事件是否为新兴热点事件的唯一条件。本文运用增长率作为事件新兴性的评定条件,增长率定义为事件当前时间段包含微博帖子数量和以前时间段包含微博帖子的平均值加上标准差的比值。
计算事件的新兴热点评分首先需要计算事件C以前时间段平均包含的微博帖子数量和标准差。当增长率大于等于1时将事件列为候选新兴热点事件,同时计算事件的新兴热点评分,事件C在当前时间段的新兴热点评分EmergScoreC计算公式如下:
(7)
其中,HotScoreC为事件C的热点评分,NC为事件C当前时间段微博帖子数量,Meanprev和SDprev分别为事件C以前时段平均包含的微博帖子数量和标准差。
计算所有增长率大于等于1的事件的新兴热点评分,并按照新兴热点评分大小降序排序,选出top-k的事件作为IEED系统检测结果,并给出事件摘要。
2.3.3事件摘要
为了更好地理解每个事件具体谈论的内容,为用户提供更加直观可读的事件归纳,需要对每个事件作事件摘要。本文提取关键词(what、who、where)和事件发生时间(when)作为事件摘要。提取关键词时,希望提取出最能表达事件主题的关键词,采用童薇等人在文献[8]中提出的方法提取事件的关键词和时间作为事件摘要,主要思路分为以下二个步骤:(1) 提取出关键词;(2) 提取出事件发生的最早时间。
采用词汇wj在事件C包含的微博帖子中出现的总次数w_countj来度量一个词汇和该事件主题的相关性。同时考虑微博的转发和评论次数对关键词的影响,采用转发、评论次数之和加权进一步计算关键词与主题的相关性,因为转发、评论次数一定程度反应了微博帖子的影响力,从而在一定程度上可以影响出现在该微博中的词汇。由于两条微博的转发和评论次数相差可能非常大,可能出现数量级的差距,所以对微博的转发、评论次数之和取对数以消除数量级的差异。由于某条微博的转发和评论次数之和可能为0,但是对数的自变量必须大于0,所以在计算公式中加一个平滑因子1。具体计算公式如下:
(8)
其中,w_currenti,j为词汇wj在微博帖子Di中出现的次数,Ri和Ci分别为Di的转发和评论次数。
计算出事件C中所有词汇与该事件的相关性,对w_countj进行降序排序,取出top-k个词汇作为事件C的关键词,即为事件摘要的what、who、where。
提取出事件C的主题后,还需要提取出事件C最早发生时间,提取出事件C中最早发布的微博帖子的时间作为事件的发生时间when,本文的时间精确度只到某天。
3实验结果及分析
3.1数据集
采用新浪微博提供的API接口,收集了从2012年9月30日至2012年10月22日间712 543条微博帖子,同时获取到微博帖子的转发、评论次数及微博用户的粉丝数量。收集到的微博帖子包含字段如表1所示。
3.2实验结果
3.2.1评估指标
传统的信息检索评估中,精确度(precision)和召回率(recall)是两个重要的指标。本文采用文献[10]中的定义精确度,如下:

(9)
由于没有专门的工具能给出数据集中检测到的事件是否真实发生,本文采用百度新闻搜索检测所有事件,如果能搜索出相关事件的新闻则认为该事件为真实发生过的事件。
召回率(recall)是指实验结果检测到的事件占数据集中现实生活中所有真实事件的比例。因为无法知道数据集内描述现实世界发生事件的总数,本文采用文献[13]中定义的召回率,由于检测出的事件中可能有多个事件都对应现实中的一个事件,召回率定义为:

(10)
精确度和召回率将作为本文的评估指标对本文提出的IEED算法得到的实验结果作出评估。
3.2.2实验结果及分析
在数据集上用KeyGraph[2]算法与本文提出的算法IEED比较,具体实验结果如表2所示。比较后可以发现采用本文提出IEED算法能以0.691的精确度高效地检测出微博中的新兴热点事件,比KeyGraph 算法的0.420高出很多。同时IEED算法检测出的真实发生事件的总量也远高于KeyGraph算法,同时也具有很高的召回率。表3、表4为检测出的具体事件的例子。

表2 KeyGraph和IEED算法检测结果
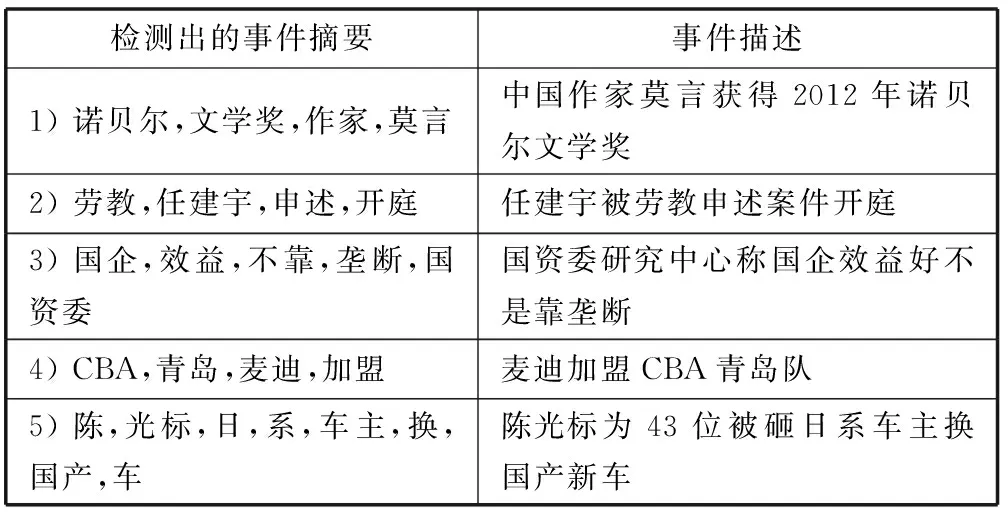
表3 KeyGraph算法检测出的结果(2012年10月11日)
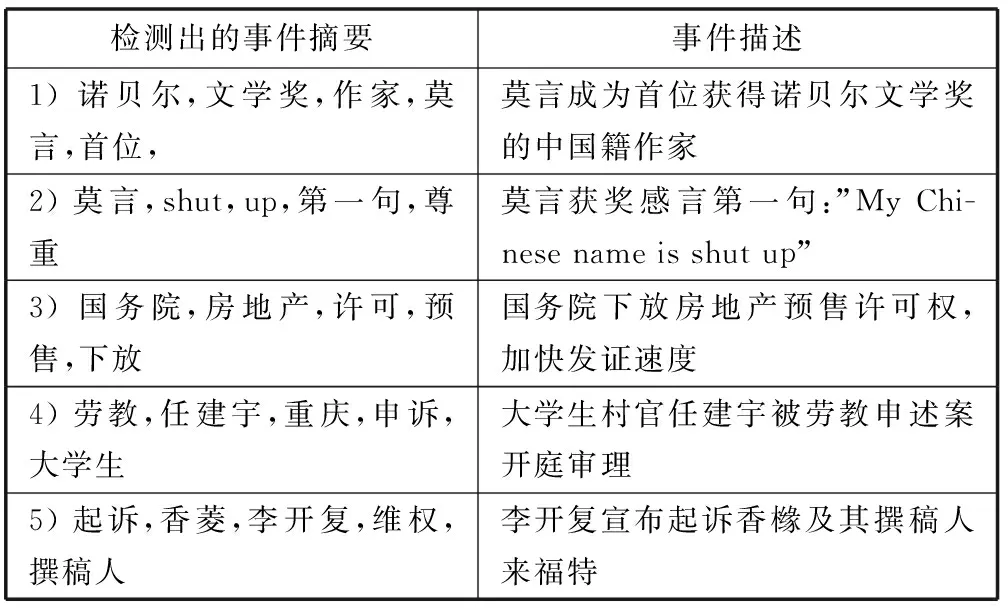
表4 IEED算法检测出的结果(2012年10月11日)
4结语
本文基于微博的数据特征,运用微博用户的粉丝数量,微博的转发、评论次数计算得到微博的影响力,提出了一种基于影响力的微博新兴热点事件检测方法IEED。实验结果证明,本方法能在早期有效地检测出微博中的新兴热点事件,具有很高的事件检测精确度,同时能生成直观可读的事件摘要。
由于微博数据量大、文本短、噪声数据多的特点给微博热点事件检测带来很大的挑战。本文在综合考虑微博数据多样化的特征进行热点事件检测上做了初步的探索。如何尽可能多的去除噪声数据提高数据质量、如何消除微博数据稀疏的特征以及如何进一步提高新兴热点事件检测的精确度和召回率,将是未来工作中需要研究的重点。
参考文献
[1] Allan J,Carbonell J,Doddington G,et al.Topic detection and tracking pilot study final report[C]//Proceedings of the DARPA Broadcast News Transcription and Understanding Workshop,Feb 1998:194-218.
[2] Sayyadi H,Hurst M,Maykov A.Event detection andtrackingin social streams[C]//Proceedings of the 3rd InternationalAAAI Conference on Weblogs and Social Media (ICWSM 09),San Jose,California,USA,May 17-20,2009:311-314.
[3] Ozdikis O,Senkul P,Oguztuzun H.Semantic expansion of hashtags for enhanced event detection in Twitter[C]//Proceedings of the 1st International Workshop on Online Social Systems(WOOS),2012.
[4] Cataldi M,Di Caro L,Schifanella C.Emerging topic detection on twitter based on temporal and social terms evaluation[C]//Proceedings of the Tenth International Workshop on Multimedia Data Mining(MDMKDD).ACM,2010:4.
[5] Alvanaki F,Michel S,Ramamritham K,et al.See what’s enblogue:real-time emergent topic identification in social media[C]//Proceedings of the 15th International Conference on Extending Database Technology.ACM,2012:336-347.
[6] Unankard S,Li X,Sharaf M A.Location-based emerging event detection in social networks[M].Web Technologies and Applications.Springer Berlin Heidelberg,2013.
[7] Duds R O,Hart P E.Pattern classification and scene analysis[M].A Wiley lnterscience Publication,John Wiley and Sons,Inc,1973.
[8] 童薇,陈威,孟小峰.EDM:高效的微博事件检测算法[J].计算机科学与探索,2012,6(12):1076-1086.
[9] 李凤岭,朱保平.基于LDA模型的微博话题发现技术研究[J].计算机应用与软件,2014,31(10):24-26,66.
[10] Weng J,Lee B S.Event Detection in Twitter[J].Proceedings of Association for the Advancement of Artificial Intelligence,2011(11):401-408.
[11] 郭跇秀,吕学强,李卓.基于突发词聚类的微博突发事件检测方法[J].计算机应用,2014,34(2):486-490.
[12] Zhang H P,Yu H K,Xiong D Y,et al.HHMM-based Chinese lexical analyzer ICTCLAS[C]//Proceedings of the second SIGHAN workshop on Chinese language processing-Volume 17.Association for Computational Linguistics,2003:184-187.
[13] Li C,Sun A,Datta A.Twevent: segment-based event detection from tweets[C]//Proceedings of the 21st ACM international conference on Information and knowledge management.ACM,2012:155-164.
[14] Salton G,Buckley C.Term-weighting approaches in automatic text retrieval[J].Information Processing and Management,1988,24(5):513-523.
INFLUENCE-BASED DETECTION OF EMERGING HOT EVENTS IN MICROBLOGS
Li HuaZhu Li
(SchoolofComputer,ChongqingUniversity,Chongqing400044,China)
AbstractTo accurately and efficiently mine the hot events on occurrence from microblogs is the focus of research in recent years. In this paper we propose an influence-based emerging hot events detection (IEED) approach by comprehensively considering the fans number of microblogging users and the influence of each microblog calculated from the number of its forwarding and comments. The approach uses hierarchical clustering to cluster the microblogging messages into event set, and extracts the keywords in the events to form event abstracts. We tested the approach presented in the paper by using the experimental dataset set up from Sina microblogging data in real life, the experimental result proved that the influence-based IEED could efficiently detect the emerging hot events in microblogs at early time, and had certain applied value.
KeywordsEmerging events detectionMicroblog influenceClustering
收稿日期:2014-11-18。李华,副教授,主研领域:计算机网络,网络教育,大数据。朱荔,硕士。
中图分类号TP391
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.05.025
