利用交叉推荐模型解决用户冷启动问题
2016-06-08朱坤广郝春亮
朱坤广 杨 达 崔 强 郝春亮
1(中国科学院软件研究所基础软件国家工程研究中心 北京 100190)2(中国科学院大学 北京 100190)3(中国科学院软件研究所计算机科学国家重点实验室 北京 100190)
利用交叉推荐模型解决用户冷启动问题
朱坤广1,2杨达1,3崔强1,2郝春亮1,2
1(中国科学院软件研究所基础软件国家工程研究中心北京 100190)2(中国科学院大学北京 100190)3(中国科学院软件研究所计算机科学国家重点实验室北京 100190)
摘要用户冷启动是推荐系统的一个重要问题。传统的推荐系统使用迁移学习的方法来解决这个问题,即利用一个领域的评分信息或者标签预测另外一个领域的用户和物品评分。上述迁移学习模型通常假设两个领域没有重叠的用户和物品,与上述假设不同,很多情况下系统可以获取同一用户在不同领域的数据。针对这种数据,提出一种新的推荐系统冷启动模型—crossSVD&GBDT(CSGT), 通过有效利用重叠用户的信息来解决用户冷启动问题。具体地,首先提出新模型获取用户和物品的特征,然后利用GBDT模型进行训练。实验数据表明,在豆瓣数据集中corssSVD&GBDT可以得到比传统方法性能更高、鲁棒性更强的实验结果。
关键词推荐系统迁移学习用户冷启动交叉推荐
0引言
随着互联网的发展,产生的信息呈指数级增长,推荐系统在解决这种信息过载问题中越来越重要。推荐系统利用用户的历史信息主动给用户推荐用户未来需要的信息(用户喜欢的衣服、书籍等),并且已经在工业界得到了成功的应用,比如亚马逊、淘宝等公司。虽然推荐系统得到广泛的应用,但是也面临很多问题,其中用户冷启动是个非常重要的问题。用户冷启动指当用户在一个领域没有任何历史信息时,如何给该用户推荐他需要的当前领域的信息?如果不能够很快速地给一个新用户推荐感兴趣的信息,会让用户认为该领域的信息对他没有价值,这样就会错失掉该用户。
针对冷启动中的数据稀疏问题,有些学者提出使用交叉领域推荐的方法解决。交叉领域推荐即利用信息丰富领域(原领域)中探索到的知识(用户的兴趣、物品的特征)提高信息稀疏领域(目标领域)中的推荐性能。当前探索出来的交叉领域推荐模型都是基于两个领域没有用户重叠和物品重叠的数据设计的。但是,从业界来看,越来越多的公司同时在很多个领域开展业务,这样就会收集到很多用户在多个领域的行为信息,就可以挖掘这些重叠用户的价值。通过这些重叠用户的行为,可以探索用户会对两个领域的哪些物品同时产生兴趣。比如对喜剧电影感兴趣的用户会很有可能喜欢喜剧类的书籍,对于某个武侠小说感兴趣的用户同时会对这个小说改编的电影感兴趣。
基于以上分析,本文是利用重叠用户的评分信息解决用户冷启动问题。解决这种问题最直接的做法是将两个领域的评分合在一起,利用已有的推荐模型。比如基于物品的推荐,基于用户的推荐或者矩阵分解的方法进行计算。但这样首先会使数据更加稀疏,得到的结果更加不稳定不准确[8],对于这一点,本文将在实验部分进行证实。其次,两个领域的知识或者特征不可能完全相同,必然都有各自独立的特征。比如图书和电影两个领域,武侠是两个领域共同的物品类别,但是经管类书籍只属于图书所有,利用用户对经管类书籍的评分学到的特征对于预测用户对电影的评分没有任何用处,如果强行迁移,只会引起负作用。
所以,本文提出的模型假设两个领域有一些共同的特征,但同时都有各自独立的特征,模型分为2部分。首先,得到两个领域中的每个用户和每个物品的特征,包括独立特征和共同特征。这部分工作是基于LFM[13]进行改进,使得LFM模型适合处理多领域信息的问题,本文的模型将LFM中定义的特征分割为3部分:(1) S领域的独立特征;(2) T领域的独立特征;(3) 两个领域共同的特征。如图1所示,U2用户群中的每个用户最后会得到S领域中的独立特征以及两个领域共同的特征,U3用户群中的用户最后会得到T领域中的独立特征以及两个领域的共同的特征,U1用户群会得到S和T两个领域独立的特征,同时也有两个领域共同的特征。S领域中的物品会获得S领域中独立的特征以及两个领域中共同的特征,T领域中的物品会获得T领域中独立的特征以及两个领域中共同的特征。
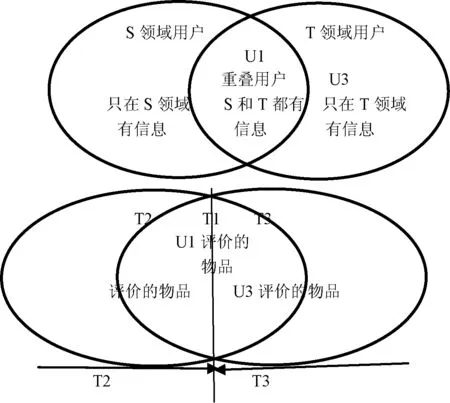
图1 符号说明
其次,选择特征和模型预测评分。目的是预测S领域的用户对T领域的物品的评分或者预测T领域的用户对S领域的物品的评分,那么属于每个领域的独立特征就不会起作用,所以只需选择两个领域共同的特征来预测用户对物品的评分。这样就将该问题转化成一个回归问题,特征是两个领域共同的特征,即每个用户在共同特征下的值和每个物品在共同特征下的值,y值是该用户对该物品的评分,采取当前比较好的一个回归模型GBDT。并且经过实验结果,本文提出的crossSVD&GBDT相对于其他模型更加准确、稳定。本文的贡献点主要分为2个部分:
(1) 尝试使用两个领域重叠的用户信息解决单领域的用户冷启动问题。
(2) 基于传统模型,提出新的模型crossSVD&GBDT,获取两个领域用户和物品共同的隐含特征。
1相关工作
正式介绍模型之前,先描述矩阵分解的背景知识。然后介绍交叉推荐系统相关领域的知识。
1.1基于矩阵分解的推荐系统模型
矩阵分解是将一个矩阵拆解成2个或者更多个矩阵的乘积,这些矩阵乘积的结果可以近似等于原矩阵。在推荐系统中,矩阵分解模型是将一个user-item-rating矩阵(R∈Rm×n,m是指有m个用户,n是指有n个物品)分解成一个用户矩阵U∈Rm×k和一个物品矩阵V∈Rn×k。
R=U×VT

使用以下目标函数求解U,V,使得结果近似R。
(1)
式中,Iij表明Rij是否为0,即用户i对物品j是否有评分。如果有评分为1,没有评分为0。Rij表明用户i对物品j的评分,Ui表明用户i的特征,Vj表明物品j的特征。为了解决稀疏性问题,加入了正则项。

(2)
以上2个目标函数都可以使用SGD(Stochastic Gradient Descent)或者LBFGS(Limit Quasi-Newton Methods)解法求解。
1.2基于迁移学习的交叉领域推荐系统
迁移学习的思想有2个领域:一个领域信息量丰富;另一个领域信息量稀少。如何利用信息量丰富领域中的信息来解决信息量稀少领域中遇到的问题。用户在其他电影网站(源领域)的一些行为预测用户在当前电影网站(目标领域)对电影的评分。比如文献[1,2],使用用户是否喜好一个电影(0/1)或者看电影的时间长度,预测用户对电影的评分。同时训练源领域和目标领域的数据,假设用户在两个领域的特征分布是一样的,因为两个领域都是关于电影的。文献[3] 假设当前领域的用户和物品都很稀少,比如当前电影网站用户行为稀少,物品被访问得也少,而这个领域里的用户在另外一个网站的行为很多,那么可以利用另外一个网站的行为学习这个用户的特征,用另外一个电影网站学习到电影的特征。然后将这2个特征应用到当前电影网站中。还有一部分文献是利用图书中的信息推荐电影中的信息。比如文献[4]利用图书中的信息学到用户群对物品群的评分,然后将该信息应用到电影中。文献[11]对迁移学习有一个总结,描述了迁移学习的分类。文献[5] 假设两个领域中有共同的特征,在每个领域中建立一个user×item×tags的三维矩阵,并且将该3维矩阵分解,得到每个用户的特征分布,以及每个物品的特征分布以及标签的特征分布,模型中假设的目标领域和源领域中共同的知识是用户、物品、标签3个维度之间的关系。然后将信息量丰富的领域中学到的特征应用到信息量稀少的领域中。文献[6,7]同时训练图书和电影中的数据、图书和电影间共同的知识是指他们有着共同的用户类、共同的物品类,并且某一类用户对某一类物品的评分也是共同的。利用这个共同的信息,得到每个用户属于哪一个特征,哪个物品属于哪一个特征。文献[7]假设是多个领域间有共同的用户群个数,但是物品类个数可以不一样,多个领域间共同的特征是用户群和其中一部分物品群之间的关系是相同的,而并不是用户群和所有的物品群之间的关系是相同的并且物品群个数是相同的。利用在两个领域间有共同行为的用户推荐商品。建立一个用户和物品的二部图,将2个领域的数据混合在一起,进行文献[10]这种方法的缺陷训练,基于随机游走的方法,结果不稳定并且需要大量的计算。
2crossSVD&GBDT模型
2.1利用重叠用户信息获取用户和物品在两个领域的共同特征
最直接得到两个领域中用户和物品的特征,是将两个领域的评分混合在一起,行数是两个领域中的用户数,列数是两个领域中的物品数。矩阵中的每个元素即相应下标是用户对物品的评分,然后直接利用SVD模型或者其他隐含因子模型进行求解。但是这种办法非常的粗糙,缺点在文献[8]中也有阐述,这样会使得矩阵更加稀疏,得到的结果更加不精确。同时这种方法是默认2个领域的隐含特征是一样的,就像在背景中分析的那样,有很大的缺陷。基于背景中提出的思想,本文的模型就是假设每个领域都有自己独立的隐含特征,都是另外一个领域不具备的。但同时这2个领域肯定也会有一些共同的topic,否则也不可能有那么多用户在这2个领域同时会有那么多评分信息的。
假设两个领域特征总数有k个,属于S领域的特征个数有x个,属于T领域的特征个数有y个,他们共有z个特征。满足等式x+z+y=k,如图2所示。
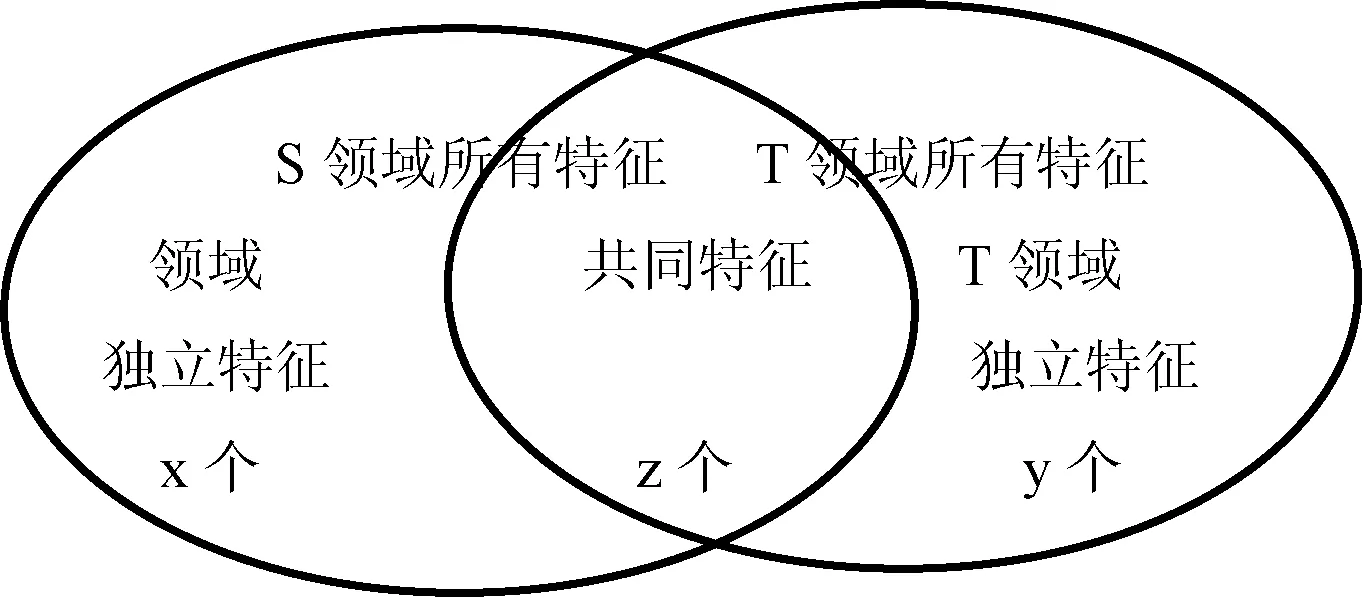
图2 特征的表示形式
假设该k维向量中,前x+z个隐含特征属于S领域,后面y+z个隐含特征属于T领域。
本文的损失函数如下:

(3)
式中,Sm表示S领域中用户的个数,Sn表示S领域中物品的个数。Tm表示T领域中用户的个数,Tn表示T领域中物品的个数。由此可以得到每个用户的特征向量,共有k维。其中U2用户群后面y个特征的数值都是0(这y个特征只算一个数值的补充,没有任何物理含义),U3用户群前面x个特征的数值都是0(同理,这个x个特征没有任何物理含义)。得到每个物品的特征向量,共有k维。T1物品群后面y个特征都是0(同理,这y个特征没有任何物理含义,只是数值补充),T3物品群前面x个特征都是0(这x个特征没有任何物理含义)。
使用SGD的方法求解该目标函数。
1) 对于S领域中的评分信息,即对于任意评分信息Rij,如果物品j属于S领域,更新用户i的特征向量,即Ui向量的前x+z个值,以及物品j的前x+z个值。根据第一个平方误差等式,求导如下:
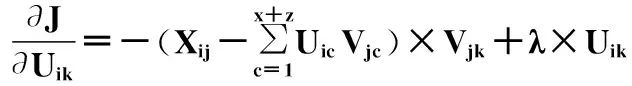
(4)
2) 对于T领域中的评分信息,即对于任意评分信息Rij,如果物品j属于T领域,更新用户i的特征向量,即Ui向量的后z+y个值,以及物品j的后y+z个值。根据第二个平方误差等式,求导如下:

(5)
可以将该模型分为3个部分去观察:
1) 针对U1用户群以及该部分用户的评分信息:对S领域的这部分评分信息体现在第一个平方误差等式中,对T领域的这部分评分体现在第二个平方误差等式中。假设用户a属于U1用户群,i是S领域的物品,j是T领域的物品,a分别对i和j有评分。根据a对i的评分,模型每次更新用户a的前x+z个特征,以及物品i的前x+z特征。根据a对j的评分,模型每次更新用户a的后z+y个特征,以及物品j的后y+z个特征。这样无论是在哪个领域的评分,都会更新用户a在z个公共特征的值。
2) 针对U2用户群以及该部分用户的评分信息:该部分的评分信息只包含在第一个平方误差等式中。假设用户a属于U2用户群,物品j属于S领域,用户a对于物品j有评分信息,则根据用户a对于物品j的评分,模型每次更新用户a的前x+z个特征,以及物品j的前x+z个特征。
3) 针对U3用户群以及该部分用户的评分信息:该部分的评分信息只包含在第二个平方误差等式中。假设用户a属于U3用户群,物品j属于T领域,用户a对于物品j有评分信息,则根据用户a对于物品j的评分,模型每次更新用户a的后z+y个特征,以及物品j的后y+z个特征。
可以明确该框架的3个优点:(1) 假设两个用户有一部分特征是相同的,也都有各自独立的特征,这种假设较假设两个领域中有共同的特征更适合现实中的数据。(2) 将2个领域的评分信息混合在一起,同时得到每个用户和每个物品的特征,并用一个统一的特征体系表达出不同领域的用户以及物品特征。(3) 本模型分布式计算很容易实现,计算复杂度较低。
2.2使用GBDT模型以及用户和物品在两个领域的共同特征预测用户对新领域的评分
本文目的是预测U2用户群对T领域的评分以及预测U1用户群对S领域的物品。2.1节获取了用户在每个单独领域的隐含特征以及两个领域共同的隐含特征,物品在每个单独领域的隐含特征以及两个领域共同的隐含特征。单独领域的隐含特征只能特定表明用户在该领域的特征或者物品在该领域的特征,而两个领域的关系只能通过两个领域的共同隐含特征体现。两个领域各自独立的隐含特征之间是没有任何关系的,所以只选择共同领域的隐含特征作为GBDT模型的输入。
2.2.1GBDT模型简介
GBDT(Gradient Boosting Decision Tree)模型是一种解决回归问题的树模型,详细的方法不再描述,只描述一些核心的部分。模型的输入即上述构造的样本集合,输出是n颗树,每颗树都有若干个叶节点,每个叶节点都有一个值,该值是该节点上的样本的标签的平均值。算法如下:每一次特征的选择方法有2种:
第一种是采用平方误差:
(6)
R1=(xj≤s)R2=(xj≥s)
c1=ave(yi|xi∈R1(j,s))
c2=ave(yi|xi∈R2(j,s))
第二种采用绝对值误差:
(7)
R1=(xj≤s)R2=(xj≥s)
c1=ave(yi|xi∈R1(j,s))
c2=ave(yi|xi∈R2(j,s))
这样,最后子节点中的y值基本上是相近的。
最后的终止条件有3种情况:(1) 特征都已经用完(基本上不会发生)。(2) 当前节点的损失小于一定阈值。(3) 当前节点个数小于一定阈值。
2.2.2构造样本
由上一节得知,每个用户用统一的k维向量表示,每个物品用统一的k维向量表示,抽出z个共同的隐含特征构造样本,对于每一个评分Rij,用如表1形式表示。
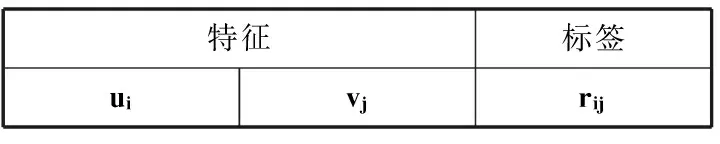
表1 样本的形式
表1中,ui指的用户i的z个共同隐含特征,vj指的物品j的z个共同隐含特征,rij表示用户i对物品j的评分。样本共有2z个特征。
2.2.3模型训练
根据上述得到的样本,使用GBDT模型进行训练的。最后的结果就是产生若干颗树,每个树上有很多个叶子节点。每个叶子节点包含一部分评分信息,对应一个特征组合规则。该特征组合规则指的是从root节点到该叶子节点的路径,路径上的每个节点对应一个特征,并且每个节点都有一个阈值,大于该阈值的特征是该节点的右子节点,小于该阈值的特征是该节点的左子节点。应用到当前的推荐场景,当前叶节点中的某个评分是用户i对物品的j的评分。那么用户i和物品j的2z个特征满足当前叶节点的特征组合规则。
根据GBDT模型,每个叶节点上的样本的评分是相似的,每个节点上的评分信息有3种可能:(1) 该叶节点上所有的评分都来自于用户对S领域物品的评分。(2) 该叶节点上所有的评分都来自于用户对T领域物品的评分。(3) 该节点上的评分包含2个领域的评分。
每个叶节点的值等于该叶节点上所有评分的平均分,由此认为在该叶节点上的所有用户对该叶节点上所有物品的评分都是该平均分。如果是上述第一种可能或者第二种可能,那么该叶节点没有起到交叉领域的作用,只是说明在单领域中,该领域的用户对该领域的物品的评分。如果是第三种可能,得到某个领域的用户对另外一个领域的物品的评分。
3实验
3.1数据处理
实验数据来自于对豆瓣的采集,共有50 000个用户,电影多少条,书籍多少条,评分信息共有x条。采用以下条件处理数据满足实验的需求,如表2-表4所示。
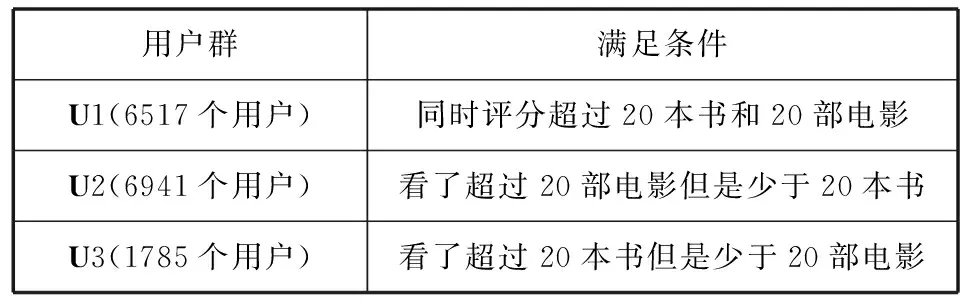
表2 用户群的组成

表3 物品的组成

表4 训练集和测试集的组成
3.2实验评价标准
实验采用2种衡量标准:Mean Absolute Error(MAE) 和Root Mean Square Error(RMSE),衡量本实验的预测精确度。定义如下:

3.3对比方法
在实验中,我们检测了提出的模型在真实数据中的效果,并且跟其他经典的单领域推荐模型相比,包含3种模型:LFM(Latent Factor Model)、biasSVD(Bias-Singluar Value Decomposition)、pureSVD(pure Singluar Value Decomposition)。
LFM[13]:一个单领域的模型,使用矩阵分解的方法学习每个领域的隐含特征,使用这些隐含特征预测评分。模型如下:
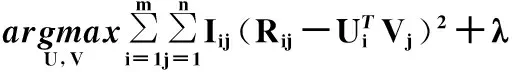
biasSVD[14]:一个单领域的模型,在上述LFM的基础上加入了全局平均数,用户偏置项,物品偏置项。模型如下:
λ(‖U‖2+‖V‖2)
pureSVD[15]:一个单领域的模型,使用传统的SVD分解方法,将评分矩阵分解成3个矩阵,一个矩阵存储用户特征,一个矩阵存储物品特征,一个矩阵存储用户群和物品之间的关系。模型如下:

crossSVD&GBDT:本文的模型。首先改进LFM,使得单领域的LFM适用到2个领域上。获取每个领域的用户以及物品特征。其次在上述特征的基础上,使用GBDT模型。
3.4性能对比
本文将两个领域的数据混合在一起,然后使用已有的3个模型进行预测,有2个因素影响这3个模型的效果,隐含特征个数和正则项。对于crossSVD&GBDT ,有4个因素影响效果:两个领域共同的特征个数;GBDT中的树的个数;树的深度;下降速率。通过以下实验的对比,可以看到本文提出的模型比传统的3个模型得到结果更准确更具有鲁棒性,并且利用传统模型的结果证明本文的假设是对的,即两个领域的特征不可能完全相同。
3.4.1准确度对比
如表5所示,是通过交叉验证,调试较多参数得到的每个模型最好的效果。

表5 模型结果
从表5中,有以下几点分析:
(1) CSGT在MAE上相对其他3个模型有较大的提升,在RMSE上也有一小部分提升。
(2) 使用LFM或者pureSVD,CSGT的方法比biasSVD得到的效果要好很多。从模型的角度来看,全局均分,用户偏置对结果影响很大,即电影和图书两个领域的均分是有较大差别的。用户对电影和图书的评分也是有很大区别的,说明这2个不同领域有很多特征都是不同的。
(3) 从pureSVD、LFM、CSGT这3种方法效果来看,利用用户在一个领域的评分信息预测用户在另外一个领域的评分信息是有较好效果的。说明用户在两个领域的行为还是有一些相同点的。
3.4.2鲁棒性对比
设定迭代次数是50次,分别将正则项参数设置为0、0.01、0.1。将topic的个数从20到50,得到如图3-图8所示。
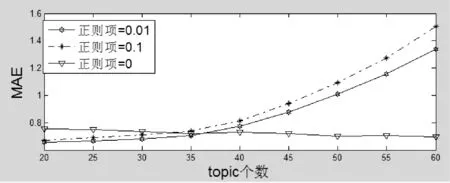
图3 MAE:LFM:正则项权重和topic个数
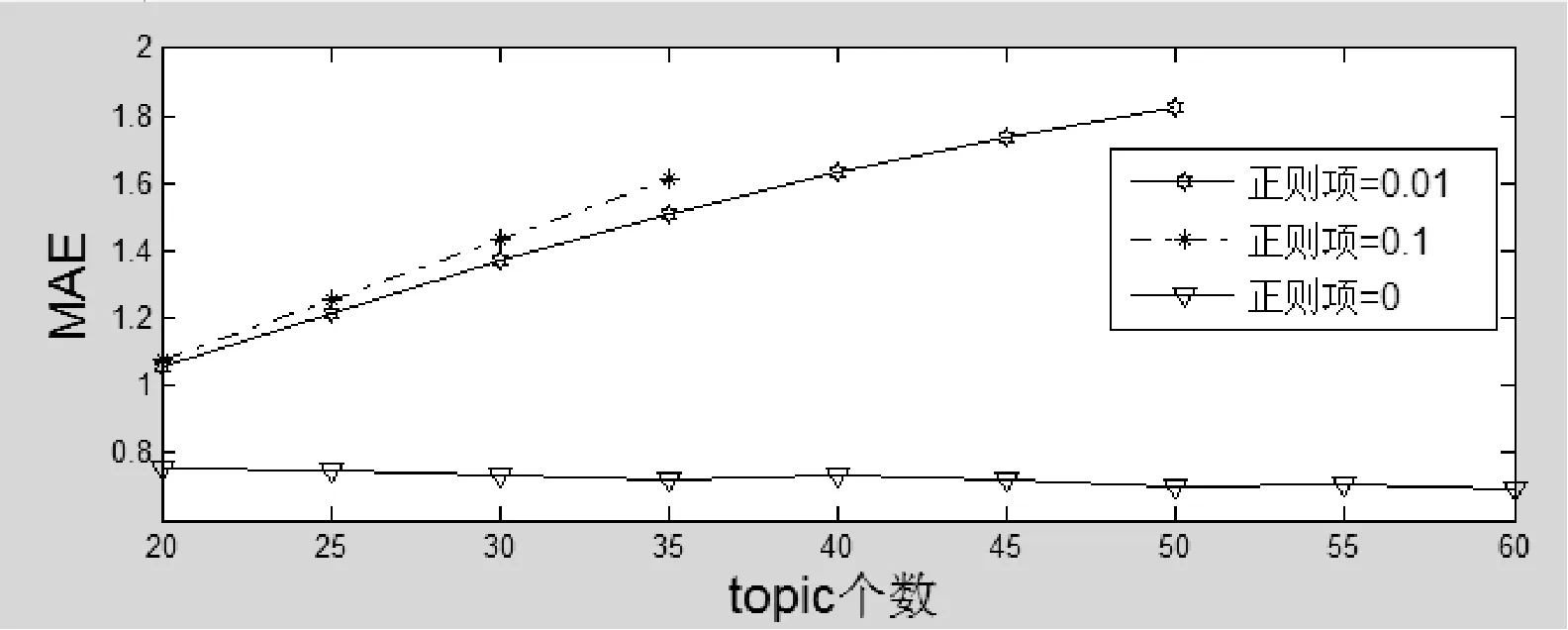
图4 MAE:biasSVD:正则项权重和topic个数

图5 MAE:pureSVD:正则项权重和topic个数

图6 RMSE:LFM:正则项权重和topic个数

图7 RMSE:biasSVD:正则项权重和topic个数

图8 RMSE:pureSVD:正则项权重和topic个数
以上是计算出来的LFM、biasSVD、pureSVD三种模型在不同topic个数和正则项权重下的误差。可以看到参数对于结果的影响很大,效果不稳定,并且三种模型除个别参数,大部分情况下都是随着topic个数的增多,误差减小。这说明两个领域不可能那么多共同的topic,必然都有各自独立的特征,两个领域的评分不能简单的混合在一起进行计算。所以本文模型的假设即两个不同的领域有共同的主题,但都有各自独立的主题,这样的假设更符合数据。
图9、图10是在树的权重是0.1和树的深度是3的基础上,GBDT不同的树的个数和不同的topic下,两种误差的趋势。可以看到结果非常平稳,随着树的个数增多或者树的大小增多,两种误差都没有太明显的变化,topic个数的变化对于结果的影响也不明显。
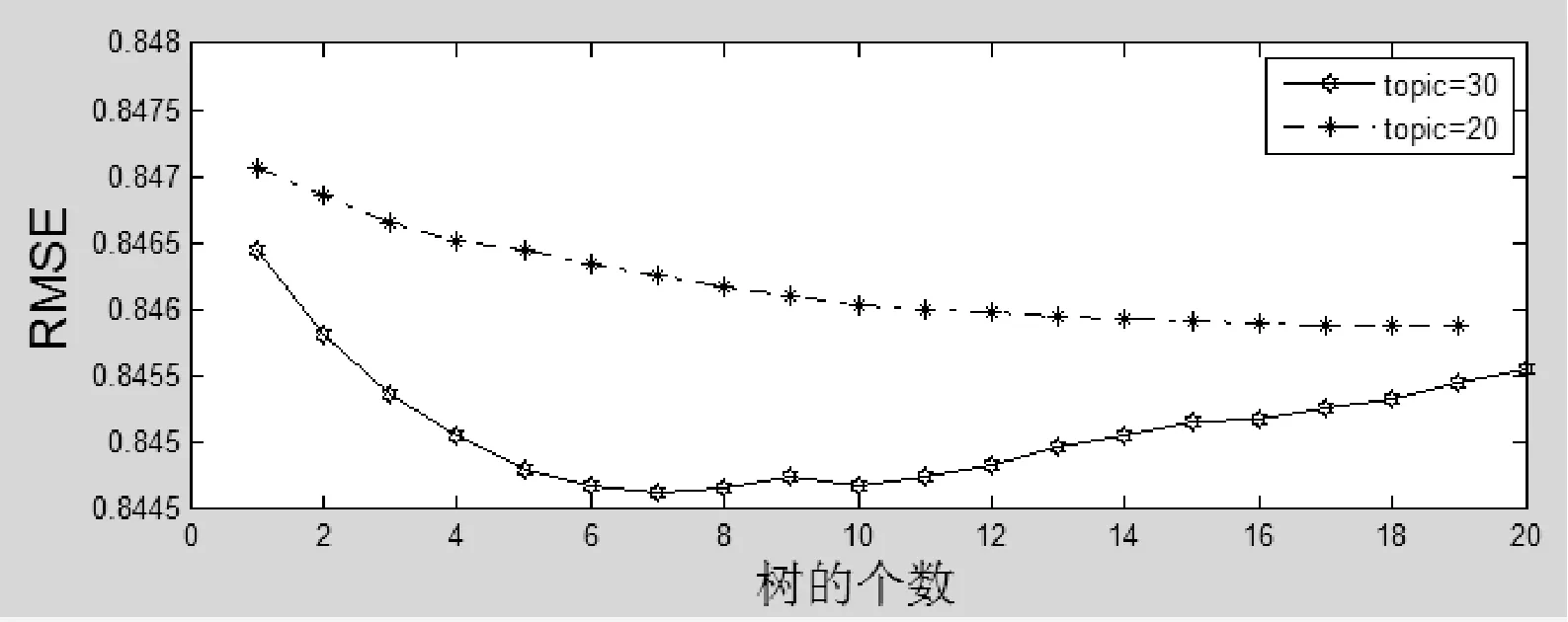
图9 RMSE:crossSVD&GBDT:两个领域共同topic个数的影响

图10 MAE:crossSVD&GBDT:两个领域共同topic个数的影响
由图11、图12可以看到,树的个数和树的深度对于结果的影响也不大,效果也比较稳定。
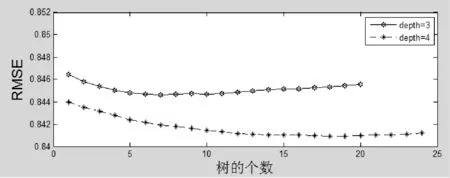
图11 RMSE:crossSVD&GBDT:树的个数和树的深度

图12 MAE:crossSVD&GBDT:树的个数和树的深度
图13、图14是在树的个数为50、topic个数是20的基础上,随着下降速率的变化,两种误差的变化。由图形可以看到结果比较稳定。
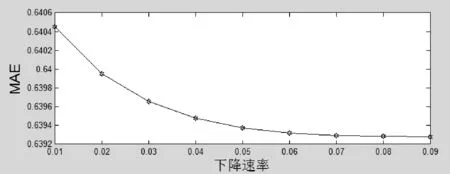
图13 MAE:crossSVD&GBDT树的下降速率

图14 RMSE:crossSVD&GBDT:树的下降速率
综合以上图形,可以总结,本文提出的模型的参数对于结果的影响不大,效果比较稳定。
3.4.3时间复杂度对比
本文模型分为2部分:获取共同特征和使用GBDT模型处理。获取共同特征的模型和传统模型求解的原理是一样的,这部分处理的时间和传统模型的处理时间相近,所以本文的时间复杂度相比传统模型多了一步GBDT处理的时间。当前分布式系统中也有很多分布式的GBDT模型,处理速度都很快,比如当前流行的Spark分布式系统中MLlib库中的GBDT算法。综上所述,本文模型可以分布式处理,时间复杂度是可控的。
3.5实验总结
综上所述,实验有如下总结:
(1) 在准确性上,本文提出的CSGT模型相比传统模型结果更加精确。
(2) 在鲁棒性上,本文的模型相比传统模型,受参数影响较小。
(3) 从以上结果分析,更进一步证明本文的假设是正确的,即两个领域有共同的特征,但同时都有各自独立的特征。
(4) 利用用户在一个领域的评分信息预测用户在另外一个领域的评分信息,结果还是比较准确的,说明用户在两个领域的行为还是有一些相似之处的。
(5) 利用两个领域重叠用户的信息可以更好地解决用户冷启动问题。
(6) 模型可以分布式处理,时间复杂度是可控的。
4结语
本文提出了crossSVD&GBDT模型,利用重叠用户数据可以更精确更稳定地解决推荐系统中的用户冷启动问题,提出的假设能够更好地符合真实数据的分布。基于上述工作,未来的工作分为以下2个部分:
1) 引入标签信息,使用标签的相似度传递。标签相对于通过model得到特征更加精确,将标签特征加入到当前特征体系。
2) 使用回归树模型得到很多个叶子节点。可以认为每个叶节点上的用户和物品是相似的,认为他们之间可以使用协同过滤的思想解释,基于用户的协同过滤和基于物品的协同过滤思想都是适用的。即在这个子节点上,用户喜欢某个物品,必然也喜欢这个子节点上和该物品最相似的物品,两个用户相似,则他们对某些物品的评价必然是一致的。这样在每个叶子节点上使用传统的推荐模型来预测分值,相当于将一个大矩阵分成分解成若干个小矩阵,然后在每个小矩阵上使用矩阵分解的办法或者其他办法预测其他缺失的评分。
参考文献
[1] Pan W,Yang Q.Transfer learning in heterogeneous collaborative filtering domains[J].Artificial Intelligence,2013,197(4):39-55.
[2] Pan W,Xiang E W,Yang Q.Transfer Learning in Collaborative Filtering with Uncertain Ratings[C]//AAAI,2012.
[3] Pan W,Xiang E W,Liu N N,et al.Transfer Learning in Collaborative Filtering for Sparsity Reduction[C]//AAAI,2010,10:230-235.
[4] Li B,Yang Q,Xue X.Can Movies and Books Collaborate? Cross-Domain Collaborative Filtering for Sparsity Reduction[C]//Paper presented at the IJCAI,2009.
[5] Li B,Yang Q,Xue X.Can Movies and Books Collaborate? Cross-Domain Collaborative Filtering for Sparsity Reduction[C]//IJCAI,2009,9:2052-2057.
[6] Li B,Yang Q,Xue X.Transfer learning for collaborative filtering via a rating-matrix generative model[C]//Paper presented at the Proceedings of the 26th Annual International Conference on Machine Learning,2009.
[7] Li B,Yang Q,Xue X.Transfer learning for collaborative filtering via a rating-matrix generative model[C]//Proceedings of the 26th Annual International Conference on Machine Learning.ACM,2009:617-624.
[8] Hu L,Cao J,Xu G,et al.Personalized recommendation via cross-domain triadic factorization[C]//Proceedings of the 22nd international conference on World Wide Web.International World Wide Web Conferences Steering Committee,2013:595-606.
[9] Shi Y,Larson M,Hanjalic A.Tags as bridges between domains:Improving recommendation with tag-induced cross-domain collaborative filtering[M]//User Modeling,Adaption and Personalization.Springer Berlin Heidelberg,2011:305-316.
[10] 张亮,柏林森,周涛.基于跨电商行为的交叉推荐算法[J].电子科技大学学报,2013(1):154-160.
[11] Pan W,Xiang E W,Liu N N,et al.Transfer Learning in Collaborative Filtering for Sparsity Reduction[C]//AAAI,2010,10:230-235.
[12] Zhong E,Fan W,Wang J,et al.Comsoc:adaptive transfer of user behaviors over composite social network[C]//Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2012:696-704.
[13] Gemulla R,Nijkamp E,Haas P J,et al.Large-scale matrix factorization with distributed stochastic gradient descent[C]//Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2011:69-77.
[14] Koren Y.Factorization meets the neighborhood:a multifaceted collaborative filtering model[C]//Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2008:426-434.
[15] Ding C,Li T,Peng W,et al.Orthogonal nonnegative matrix t-factorizations for clustering[C]//Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2006:126-135.
[16] Jiang M,Cui P,Liu R,et al.Social contextual recommendation[C]//Proceedings of the 21st ACM international conference on Information and knowledge management.ACM,2012:45-54.
[17] Cremonesi P,Quadrana M.Cross-domain recommendations without overlapping data: myth or reality?[C]//Proceedings of the 8th ACM Conference on Recommender systems.ACM,2014:297-300.
[18] Chen W,Hsu W,Lee M L.Making recommendations from multiple domains[C]//Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2013:892-900.
CROSS RECOMMENDATION MODEL IN SOLVING COLD-START PROBLEM
Zhu Kunguang1,2Yang Da1,3Cui Qiang1,2Hao Chunliang1,2
1(NationalEngineeringResearchCenterofFundamentalSoftware,InstituteofSoftware,ChineseAcademyofScience,Beijing100190,China)2(UniversityofChineseAcademyofScience,Beijing100190,China)3(StateKeyLaboratoryofComputerScience,InstituteofSoftware,ChineseAcademyofScience,Beijing100190,China)
AbstractCold-start problem is a critical challenge for recommendation system. Traditional recommendation systems employ transfer learning techniques for this problem, i.e. to use rating/tags information in one domain to predict users and items rating in another domain. The above transfer learning model usually assumes that there aren’t the overlapping users and items between two domains. However, in many cases a system can obtain the data of same users from different domains, which differs from the above assumption. In light of such data, this paper proposes a new cold-start model for recommendation system-crossSVD&GBDT, called CSGT. It solves the cold-start challenge of user by effectively leveraging the information of overlapping users. More specifically, the proposed method extracts features from both the users and the items, and then constructs a GBDT model for training under the above assumption. Experimental data show that in Douban dataset, crossSVD&GBDT can gain the experimental result with higher performance and stronger robustness than the traditional methods.
KeywordsRecommendation systemTransfer learningUser cold startCross recommendation
收稿日期:2014-12-23。国家高技术研究发展计划项目(2012AA 011206);中国科学院战略性科技先导专项(XDA06010600,91318301,91218302,61432001)。朱坤广,硕士,主研领域:推荐系统。杨达,副研究员。崔强,博士。郝春亮,博士。
中图分类号TP3
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.05.017
