基于深度神经网络的四川方言识别
2016-06-08石佳影黄威
石佳影,黄威
(四川大学软件学院,成都 610065)
基于深度神经网络的四川方言识别
石佳影,黄威
(四川大学软件学院,成都610065)
摘要:
关键词:
0 引言
中国话将普通话作为官方语言,但是各地区、各民族的方言种类众多,四川方言则普遍的通用于西南地区。四川方言是盛行于四川省和重庆市的主要方言,并对云贵地区方言产生深远影响,方言发音主要从古巴蜀语的西南官话演变而来。但由于四川方言缺少舌尖后音声母和韵母儿化的特点,四川方言发音与普通话有很大区别,这也同时表现在声学特征方面,其中重点是表现在声韵母系统和语音韵律不同。元音声学特征的共振峰上的差异是四川方言与普通话声韵母系统不同的主要表现;普通发音音调和说话语速之间的差别导致四川方言的语音韵律有明显不同,其中用来衡量说话人发音韵律变化的特征向量的连续动态变化轨迹的差分特征表现最为明显[1]。国内对于语音识别技术已日趋成熟,但是方言识别还甚少研究,针对四川话的独特发音特点和其声学特征的明显差异,本文提出一种基于深度神经网络的四川方言识别技术。
声学模型的使用决定着语音识别准确与否。传统的声学建模方法是以隐马尔科夫模型(Hidden Markov model,HMM)框架为基础,并采用混合高斯模型(Gaussian Mixture Model,GMM)来描述语音声学特征的概率分布。但是这种声学模型构建方法是在一些不合理的假设基础上提出的,其中主要的假设有声学特征各维之间线性无关、概率分布形式服从混合高斯等[2]。这些假设的存在导致真实的概率分布不能准确描述。在本文的研究中,提出了一种基于Kaldi平台的深度神经网络模型的四川方言识别技术,研究发现了四川方言的发音特征,并构建了四川话发音字典和基于语音与普通话文本的四川方言语料库,实现了从四川方言对普通话的映射识别。实验结果表明,利用深度神经网络进行四川话方言识别,出错率随着训练集数据的增多,有明显下降趋势,并保持在较低状态,当训练集有1435条数据量时,出错率明显下降到5%。
1 特征参数的提取
在进行特征提取时,常用的倒谱系数有:线性预测倒谱系数(Linear Prediction Cepstrum Coefficient简称LPCC)和梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficient简称MFCC)[3]。倒谱系数作为声道共振性能的反映,其中基于MFCC的特征利用了听觉模型的研究成果,并且对输入信号没有限制,也不会因为信号性质不同而造成明显的特征差异。因此,采用鲁邦性更好的梅尔倒谱系数特征能更有效地提取语音特征参数,除此之外梅尔倒谱对卷积性信道失真有补偿的能力,基于以上原因,本研究同样采取MFCC进行四川方言语音特征参数提取。
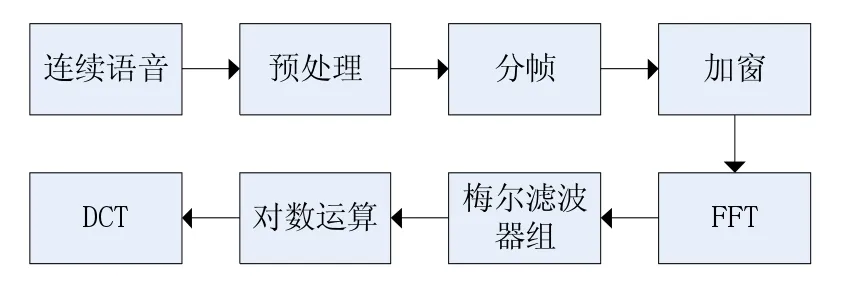
图1 特征参数的计算过程
图1为语音特征参数MFCC提取过程。连续的一段语音经过预加重处理,提升语音中高频部分,是信号的族谱变得平坦,使其能用同样的信噪比求频谱。之后进行分帧处理和加窗处理,在分帧处理中帧长设置为256,采样频率设置为为8 kHz;下一步是FFT处理,在这个环节中对加窗处理之后的每帧语音信号x(n)进行FFT变换得到信号的频谱X(n);之后i将每帧信号的离散功率谱用M阶三角滤波器滤波(传递参数为Hm(k),中心频率为f(m),m=1,2,…,M,关系如图2所示),三角滤波器的频率响应定义为:
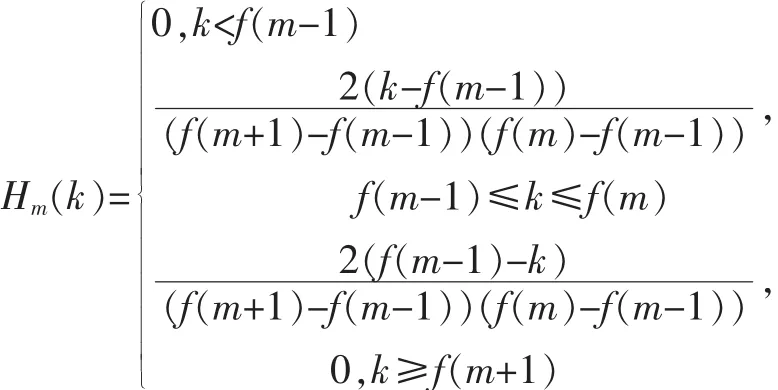
其中:

计算每个三角滤波器组输出的对数能量谱:
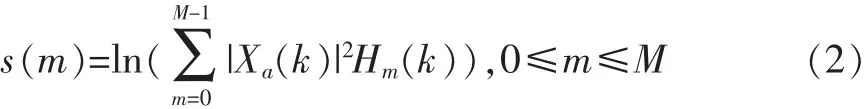
经离散余弦变换(DCT)得到MFCC系数:
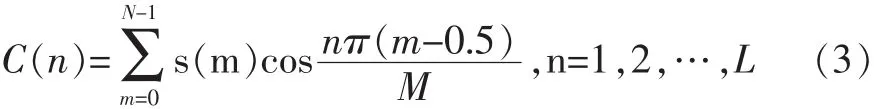
提取了MFCC参数后,再求一阶查分特征参数(ΔMFCC)和二阶差分参数(ΔMFCC),其公式为:
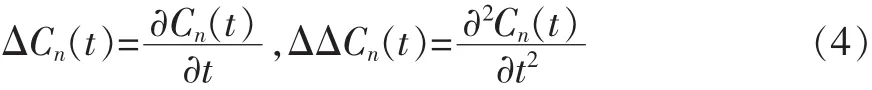
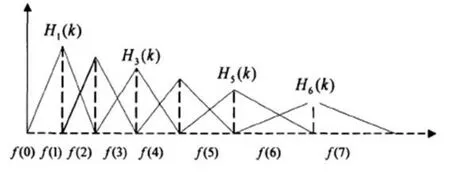
图2 f(m)与H(m)的关系
图3 一段语音的MFCC和阶数与幅值的关系
2 模型及训练
2.1深度神经网络模型(DNN)
深度神经网络的结构本质上是一个带有很多隐含层的多层感知器。深度神经网络(DNN)是在专家乘积(PoE)系统上的改进,并且DNN与传统的专家求和系统(SoE)有本质差异。按照Hinton的说法[4],DNN是由输入层、隐含层和输出层构成,这种神经网络之所以称为深度神经网络是因为它的中间隐含层多于3层。深度神经网络进行语音识别在一定程度上优于相比于混合高斯模型,主要体现在两个方面。第一,使用DNN可以直接使用相邻的帧的结构信息;第二,DNN模型允许的输入特征是没有限制的,离散或者连续或者多种混合特征都可以作为输入。并且研究发现DNN的性能提升最重要的原因是相邻帧的结构信息的互相使用。为了描述神经网络,先介绍最简单的神经网络,即单个神经元,如图4所示。
该神经元接收4个输入,x1,x2,x3,x4和一个偏置+1,其输出为:
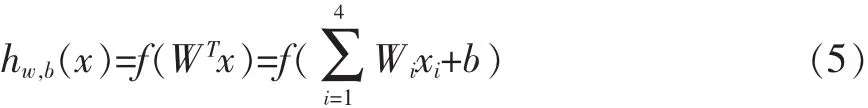
其中,Wi为xi在输入中的权重,函数f(x)被称作激活函数。
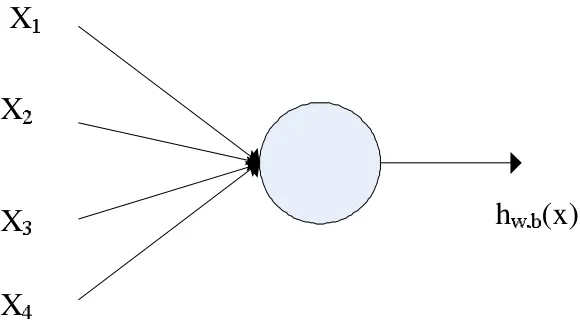
图4 单个神经元
神经网络将许多单一的神经元连接在一起,而DNN则是由多层神经网络构成的庞大网络模型,如图5所示。其中a表示当前层输入,z表示当前层的输出。对于中间层采用sigmoid激活函数[5]的神经元来说输入和输出按如下公式进行计算:
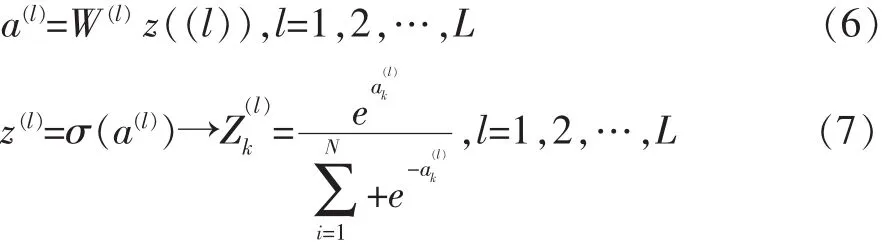
对于输出层采用softmax分类器的神经元,输入和输出计算公式如下:
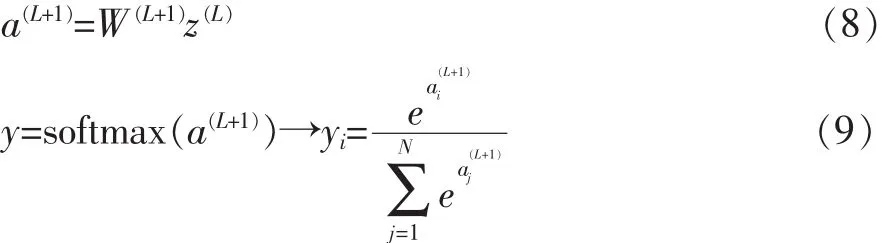
其中,y表示神经网络输出,L表示神经网络隐层数,N表示输出层神经元数量。
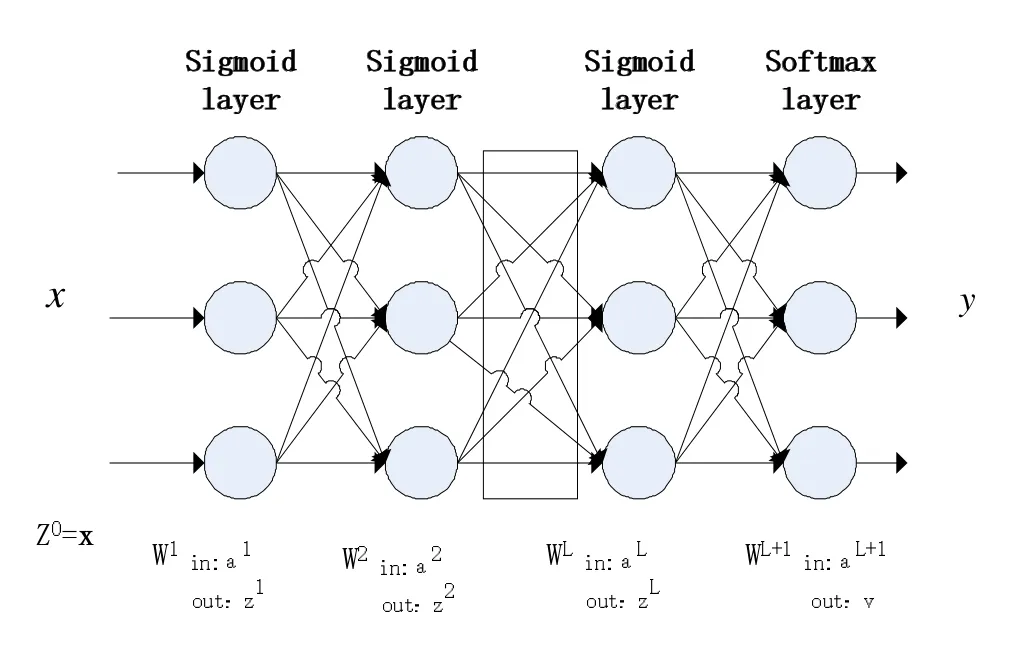
图5 深度神经网络
2.2四川方言语料库
为了支持四川方言的语音识别系统设计了四川方言语料库。该语料库由1435条四川方言发音(涵盖四川方言中成渝片及灌赤片)构成。其中80%数据来源为四川地区本土风情影视作品,20%数据来源为10个说话人(男性:10人,女性:7人),其中每个说话人的发音包括12或13条语句。并且该语料库的所有数据均配有对应四川话、普通话中文释义和对应字词典,以及分词文件。
语音数据中来源于影视作品的部分数据源为《王保长外传》、《奇人安世敏》、《让子弹飞》、《傻儿军长》、《李伯清单口相声》等。语音数据中来源于说话人录制的数据录音设备为三星I9500移动手机,录音环境为普通办公室环境。所有的语料库数据均为wav格式,单声道,量化精度16bit,采样频率16khz,语速为正常说话语速。录音时,没有刻意避免周围环境噪声。
2.3模型训练
DNN模型训练主要分为三个阶段。第一,基于RBMS(受限波尔滋蔓机),对每一层进行预训练;第二,每一帧进行交叉熵训练;第三,用格子框架通过sMBR准则(状态的最小贝叶斯风险),对序列的区分性训练。
预训练中,我们将句子级别和帧级别上分别置乱来模仿从训练数据分布里提取样本,每一个Minibatch更新一次。在交叉熵训练中,采用BP算法,由DNN计算得到的预估概率分布之间的交叉熵作为目标函数再通过Mini-batch随机梯度下降算法来将每一帧分成三音素状态来训练,默认的学习率为0.008,Minibatch的大小为256。模型学习率在最初的几次迭代中是保持不变的,当神经网络不在提高,我们在每次训练时将学习率减半,直到它再次停止提高。
3 实验及讨论
实验分别用不同的训练集Train1和Train2进行模型训练,训练集的数据分布如表1所示。对测试语言进行24维MFCC特征提取,并用DNN模型和softmax函数进行分类计算。
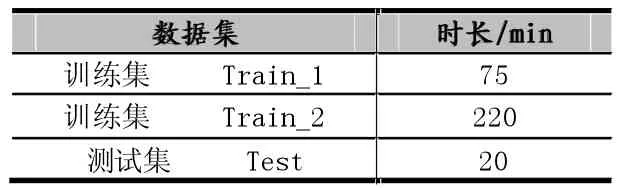
表1 实验数据分布
实验结果表明,利用深度神经网络模型进行四川方言识别大大提高了语音识别的准确率。由于训练数据的增多,会加大的增加模型训练数量,所以适当的训练数据量对于识别效率的限制是比较大的,在本次研究采用的训练数据量为75min的479条语音数据和220min的1435条语音数据。从表2可以看出采取适当并且尽可能多的训练数据,可以明显的提高四川方言的识别率,减少识别出错率。并在220min的训练模型下的语音识别出错率明显降为4.5%,比75min的训练模型出错率下降了16.3%,得到了明显的准确率的提升。

表2 实验结果
4 结语
本文提出的深度神经网络模型是一个高容量复杂的网络模型,其层数较多,每一层都单独训练。研究中采用的基于深度神经网络的四川方言语音识别方法,基于Kaldi平台,成功搭建了四川方言深度神经网络模型,同时构建了拥有1435条数据量的四川方言语料库。本实验为了减少训练数据质量对识别结果的影响,利用HMM中基于三因素的方法进行识别。实验显示该方法极大地降低了方言识别的出错率,随着训练集数据的增多,有明显下降趋势,并保持在较低状态。当训练数据量为220min时,四川方言识别出错率为4.5%。
参考文献:
[1]王岐学,钱盛友,赵新民.基于差分特征和高斯混合模型的湖南方言识别[J].计算机工程与应用,2009,45(35):129-131.
[2]Auger L. The Journal of the Acoustical Society of America.[M]. American Institute of Physics for the Acoustical Society of America,1929.
[3]Zhang H,Li D. Naive Bayes Text Classifier[C]// Granular Computing,2007. GRC 2007. IEEE International Conference on. IEEE,2007:708-708.
[4]Hinton G,Deng L,Yu D,et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups[J]. IEEE Signal Processing Magazine,2012,29(6):82-97.
[5]张雨浓,曲璐,陈俊维,等.多输入Sigmoid激励函数神经网络权值与结构确定法[J].计算机应用研究,2012,29(11):4113-4116.
Sichuan Dialect Speech Recognition Based on Deep Neural Network
SHI Jia-ying,HUANG Wei
(College of Software Engineering,Sichuan University,Chengdu 610065)
Abstract:
Keywords:
针对四川方言的发音以及音调的特点,提出一种新的基于深度神经网络(Deep Neural Network,DNN)的四川方言语音识别方法。该研究基于Kaldi平台提供的深度神经网络模型,利用梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficient,MFCC)对四川方言进行特征提取并构建四川话发音字典对四川方言进行识别研究,实现从四川方言对普通话的映射识别,并构建基于语音与普通话标签的四川方言语料库。实验结果表明,采用该方法进行四川方言识别,出错率随着训练集数据的增多有明显下降趋势,并保持在较低状态。
四川方言识别;深度神经网络;语音识别
文章编号:1007-1423(2016)13-0003-04
DOI:10.3969/j.issn.1007-1423.2016.13.001
作者简介:
石佳影(1995-),女,河北唐山人,本科,研究方向为机器智能
黄威(1995-),男,浙江温州人,本科,研究方向为机器智能
收稿日期:2016-01-12修稿日期:2016-04-30
In view of the pronunciation and tone of Sichuan dialect,presents a new method of speech recognition based on deep neural network (DNN)in Sichuan dialect. This study is based on the deep neural network model provided by Kaldi platform,which uses Mel-scale Frequency Cepstral Coefficient(MFCC)to extract the features and constructs the pronunciation dictionary of Sichuan dialect. This recognition method maps from Sichuan dialect to mandarin,and we also construct the Sichuan dialect corpus based on the pronunciation and the Chinese label. The experimental results show that with this method of speech recognition,the error rate has a clear downward trend with the increase of the training set data,and keeps in a low state.
Sichuan Dialect Speech Recognition;Deep Neural Network;Speech Recognition
