复杂室内图像的灭点检测与箱体重建方法*
2016-06-07王海菲贾金原
王海菲,贾金原,谢 宁
复杂室内图像的灭点检测与箱体重建方法*
王海菲,贾金原,谢宁+
同济大学软件学院,上海201804
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2016/10(05)-0678-10
http://www.ceaj.org Tel: +86-10-89056056
* The National Natural Science Foundation of China under Grant No. 61272276 (国家自然科学基金); the Key Projects in the National Science & Technology Pillar Program During the Twelfth Five-Year Plan Period of China under Grant No. 2012BAC11B00-04-03(国家”十二五”计划重大科技支撑项目); the Specialized Research Fund for the Doctoral Program of Higher Education of China under Grant No. 20130072110035 (高等学校博士学科点专项科研基金); the Key Scientific and Technological Projects of Jilin Province under Grant No. 20140204088GX (吉林省重点科技攻关课题); the Young Scholar Plan of Tongji University under Grant No. 2014KJ074 (同济大学青年优秀人才培养行动计划).
Received 2015-11,Accepted 2016-01.
CNKI网络优先出版: 2016-01-04, http://www.cnki.net/kcms/detail/11.5602.TP.20160104.0953.006.htm l+ Corresponding author: E-mail: ningxie@tongji.edu.cn
WANG Haifei, JIA Jinyuan, XIE Ning. Vanishing point detection and scene reconstruction of cluttered room. Journal of Frontiersof Computer Science and Technology, 2016, 10(5): 678-687.
摘要:近年来,随着家居虚拟展示应用的推广,针对图像的室内场景建模技术成为研究和应用的热点。在图像理解的基础上,针对单张复杂室内图像提出了一套箱体建模方法。首先进行代表房间主轴方向的灭点检测,并通过分析影响灭点检测的因素,对灭点检测算法提出相应的改进,从而显著改善算法的执行效率和准确性。然后对图像的场景布局信息进行自动还原,并通过加入布局优化步骤,提高布局还原结果的准确率。最后利用灭点得到相机的内、外部参数,并以此为基础实现图像到三维模型的转换。实验表明,单张复杂室内图像的箱体重建方法能够快速地对图像场景进行分析,并恢复场景的箱体布局,满足虚拟重建的需要。
关键词:家居虚拟展示;图像理解;灭点检测;三维重建;室内场景箱体建模
1 引言
随着互联网3D大数据的蓬勃发展,家居虚拟展示跨越了时空的局限,可以帮助用户直观、快速、全面地实现室内设计方案的展示,因而被家居行业广泛使用[1-2]。现有的家居虚拟展示技术多采用单纯的3D技术,虽然操作灵活,交互简单,但场景的真实性表现差强人意,且三维家居模型的制作过程耗时,需要大量繁琐的人工操作。
近年来,基于图像的家居虚拟设计方法不断涌现,在一定程度上克服了纯3D技术渲染速度慢,模型制作复杂等缺点,且素材丰富,获取容易。然而图像往往缺少一些关键的场景信息,如场景的深度信息、空间结构信息等,因此如何从图像中还原三维场景信息成为关键。目前由于数据采集的局限性,现有的特定室内场景多仅存单幅图像,且图像中包含丰富的物品,物品之间的相互遮挡会造成场景信息恢复困难。因此,针对单张复杂室内图像的场景三维信息还原与重建为本文的研究重点。
针对单张复杂室内图像的场景建模问题,本文在基于单张图像的场景三维重建的基础上,得到了一种速度更快,准确性更高的基于图像理解的场景重建方法。在进行图像重建之前,通过对复杂室内图像的分析,发现大多数场景中存在共同的特点,且这些特点对推测室内场景布局起到重要的作用:(1)房间及其内部物品均可以用立方体模型粗略表示(如图1所示,黄线代表房间模型,绿线为物品模型);(2)房间存在许多平行于墙面的平面[3]。

Fig.1 An illustration of cuboid proxy in indoor image图1 家居图像中存在的立方体模型
本文基于灭点的场景重建方法(vanishing point based scene reconstruction,VPSR)可分为三步:首先,通过对图像中物体轮廓的分析,得到代表场景特征的灭点信息。其次,根据灭点信息,推测出符合图像内容的场景布局信息。最后,将二维图像场景还原到三维真实空间中。
本文的主要贡献包括:
(1)分析影响灭点检测算法的因素,并通过更改图像边缘检测方法和灭点选择策略,明显提高了灭点检测算法的效率和准确性。
(2)提出房间箱体模型优化算法,在得到最终的场景布局信息之前,根据物品的立方体模型对房间的最优模型做进一步优化。
(3)将提出的场景重建方法运用到家居虚拟展示的应用中,用户只需上传图像即可,具有简单、方便等特点。
2 相关工作
(1)基于多张图像的场景三维重建
图像的场景重建在计算机图形学领域中一直都是研究热点。在场景的三维重建中,通过获取多张场景图像可以得到全面的场景信息,从而进行准确的场景三维重建[4]。其难点在于如何处理从不同图像中提取出的特征,将这些特征联合并推测出场景信息。除此之外,还可通过特殊格式的场景图像(如全景图像、鱼眼图像)对场景进行重建[5-6]。
(2)基于单张图像的场景三维重建
相对于多张图像的场景重建,单张图像的场景三维重建更加困难,其难点主要源于图像处理中的不适定问题:深度信息缺失和物体间的相互遮挡。单张图像无法确定三维重建所需要的精确相机参数,并且无法提供物体被遮挡部分的信息,因此针对单张图像进行精细的三维场景重建并不现实。
现有的针对单张图像的建模方法在进行相机校准步骤时,主要依赖于灭点的检测、用户的深度标注或物体的对称性等方式[7-10]。在计算相机参数的过程中,引入简单几何图元可以对相机校准起到明显的帮助作用,并获得一种基于代理的三维重建[3,11-13]。TIP(tour into the picture)[14]就是一种经典的基于箱体模型的图像三维重建方法。它在相机参数计算过程中主要运用蜘蛛网格来确认场景中的透视关系,并通过蜘蛛网格中的关键点来构建三维场景。但TIP在重建过程中所需的场景关键信息都是由人手工给出的,并且对输入的图像要求很高。
给定一张包含丰富物品内容的室内家居图像,若想让计算机自动地获取场景的关键信息是十分困难的。然而,人们却可以从图像中很快获取房间的布局信息。这主要是由于人对图像内容的理解不仅局限于其中可见的物品,如床、沙发、墙等,通过这些物品信息可以推测出整个场景的空间结构。如果让计算机也进行相同的检测,需要先让计算机理解图像。
(3)图像理解
通过图像中的特征信息来合理地解释输入图像,并进行图像参数化的过程称为图像理解。目前,有许多与本文相关的工作都采用图像理解的方法进行图像的参数化,进而自动地还原出图像的场景信息。Make3D[15]中,通过针对输入图像的超级像素的分析得到图像场景的方向和深度信息,从而推测出场景的结构信息。Hoiem等人[16]通过分析颜色、纹理、位置和视角,提出了针对图像区域进行分类标记的方法。在获取图像的区域标记后可以得到场景结构信息,但该方法不能进行遮挡情况下的场景深度估计。Hedau等人[3,13]将箱体模型和Hoiem的区域分类方法相结合,针对室内图像生成与之相符的房间模型。类似的还有Lee等人在文献[12]中提出的方法,该方法将物品与房间之间的体积限制加入到房间模型的推测过程中,从而获得更为精确的场景结构。
单张图像的家居虚拟展示在算法速度、分析准确度、场景普适度上都有比较高的要求,目前的图像分析及重建方法还无法完全满足这些要求。现有方法在算法效率和结果准确性方面还存在提升的空间,因此本文着力于对灭点检测算法的效率和场景布局还原的结果进行研究,并提出了一套行之有效的箱体重建方法,具体流程见图2。
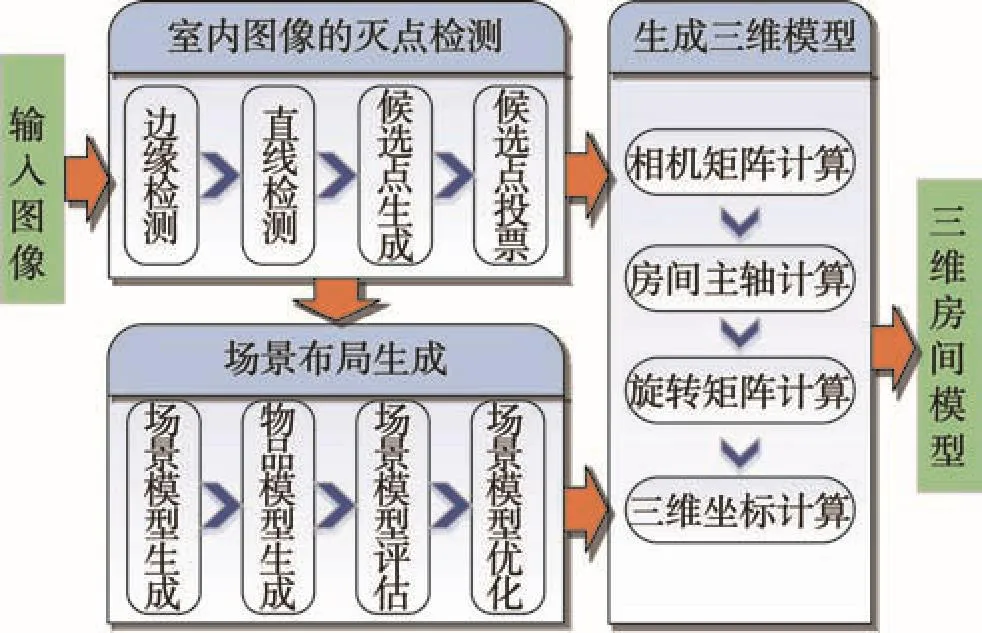
Fig.2 Workflow of vanishing points based scene reconstruction of single image图2 单张图像基于灭点的场景重建算法流程图
3 单张室内图像的灭点检测算法
为了从单张图像中提取出房间的布局信息,并生成与其符合的箱体模型,需要一种快速、准确的图像场景参数化方式。在相机类型未知的情况下,可以假设所有图像都是由针孔摄像机拍摄的,从而极大地简化了图像参数化问题。人造的真实空间中存在许多的平行线和正交线,并且这些平行线在二维图像中的投影将相交于一点,该点称为灭点。二维图像平面上的灭点,在三维空间中代表这些平行线的方向,即代表房间三维主轴的方向。灭点所处的平面在图像中会表现为一条直线,该直线就称为灭线。如图3所示,图像的物体可以用立方体模型来代替,立方体的边缘用蓝色实线表示。二维图像中,通过立方体平行边缘的延长线(黄色虚线)将相交于灭点,并确定灭线(绿色虚线表示)。因此,对于人造场景图像的理解和推测过程可以简化为灭点检测的过程。
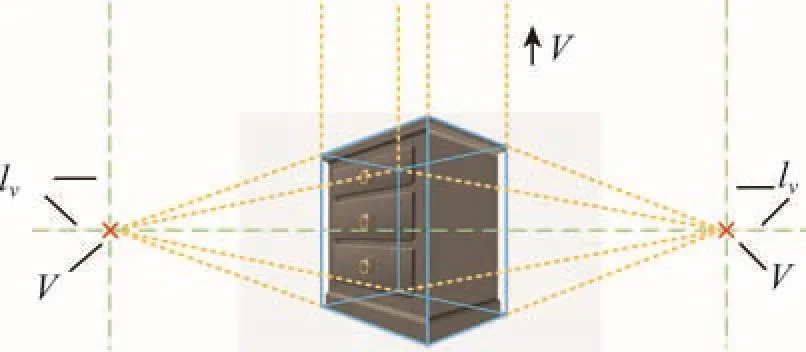
Fig.3 Relationship between vanishing points and vanishing lines for a cubiod图3 立方体在图像中与灭点和灭线的关系
灭点检测算法首先要进行图像内投影直线的检测,之后根据投影线的结果判断代表房间主轴方向的灭点在图像平面中的坐标,最后以是否与灭点共线为标准将投影线分类。与所有检测出的灭点都不共线的一类直线称为冗余直线。由此可见,灭点检测算法主要依赖于直线检测的结果,且应尽量减少检测出的冗余直线数量。
3.1投影线检测
已知室内场景图像中包含许多种类的家居物品,如沙发、桌子、椅子等,且这些物品的摆放符合假设。因此,通过这些家居物品的轮廓线可以提取出多条平行于房间方向的直线,而这些直线将作为计算灭点的主要依据。由此可知,图像边缘检测结果直接影响图像中投影线的检测,间接影响灭点检测算法的效率和准确性。
Hedau等人[3]的灭点检测算法中使用Canny算子进行边缘检测,常见的方法还有Sobel算子、Prew itt算子、LOG算子等。这些算法都是通过比较灰度图像的像素梯度方向来确定边缘,容易受噪声的影响,从而导致检测出过多的冗余直线。冗余直线对灭点的影响将会体现在两个方面:(1)灭点计算的耗时随着冗余直线的数量成指数增长;(2)冗余直线过多将会导致错误的灭点结果。因此,Hedau等人[3]在图像输入之前需要对图像尺寸进行调整,使图像中的主要轮廓信息得以凸显,但依然无法有效减少冗余直线的数量。
本文采用基于结构化的边缘检测算法[17]取代Canny边缘检测,针对每个图像块中的结构化特点,通过结构化森林得到一个准确、快速的边缘检测器。该算法将RGB值和梯度值作为特征输入,输出一幅拥有强度值的边缘图像。强度值为0到1之间的任意数值,数值越高代表该边缘越重要。结构化的边缘检测算法[17]可以有效减少检测到冗余直线的数量,无需调整输入图像的尺寸,可以在短时间内处理分辨率很高的图像,又无须忽略细节信息。边缘检测结果中的边缘强度值可以作为灭点选取的重要因素,运用到灭点投票的计算中。
3.2灭点投票策略
在已知代表边缘重要性的强度值的前提下,本文对原有的灭点投票策略[3]进行了改进,将直线的强度值引入到投票计算公式中,更加明显地区分好的和坏的候选点。对一条直线来说,它的重要性与其长度和强度成正比,与直线和候选点的夹角成反比。在投票过程中,直线越重要投出的票数就越高。本文使用L(l,i)表示一条直线,其中l为直线的长度,i为直线的强度值。使用公式r(L,p)定义一条直线L对候选点p的投票分数:
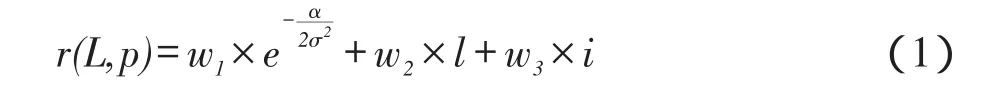
其中,α指候选点p与线段L中点的夹角(如图4所示);σ为鲁棒性阈值,设定为0.1;wj(j=1,2,3)为权重,设定w1= 0.4,w2= w3= 0.3。
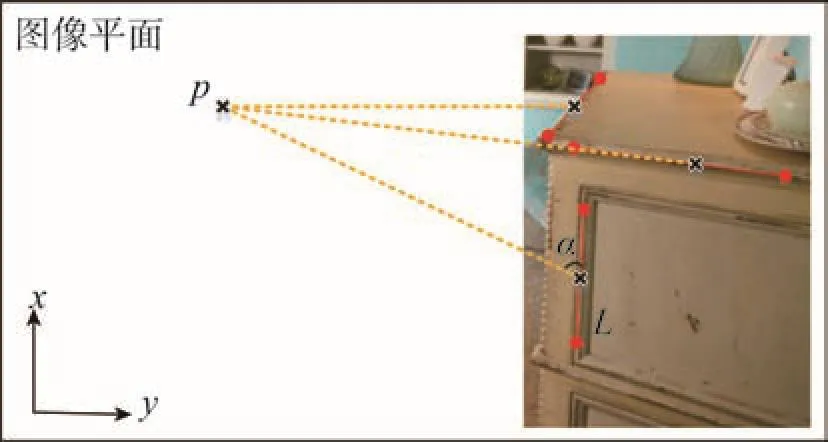
Fig.4 An illustration of angle between a candidate point p and a line segment L图4 灭点候选点p与线段L的角度关系示意图
3.3灭点检测算法
本文采用的灭点算法是运用灭点投票策略对被检测到的投影线的交点进行选取,最终得到3个灭点,分别代表真实空间中3个相互正交的方向,即X轴、Y轴和Z轴。为了提高算法效率,灭点的选择采用贪心策略取代RANSAC(random sample consensus)算法[7],直接选取拥有票数最高的候选点为第一灭点,并将于第一灭点共线的投影线归为一类。之后,根据第一灭点的结果对所有候选点进行再次筛选,从而得到第二、三灭点与其对应的投影线集合,具体的算法过程如下:
步骤1读入直线数据l,利用式(1)对所有直线两两相交得到的交点进行投票。
步骤2选择当前拥有最大票数的候选点作为第一灭点V1,并将属于V1的直线归为集合L1。
步骤3对剩余的候选点进行筛选。
(1)计算剩余候选点到图像中心的距离d,根据d的长度决定阈值T。当候选点之间的距离小于阈值T时,将其中一个候选点移除。
(2)选取剩余候选点与V1进行正交性检测,即任意两个候选点与V1之间形成的三角形的垂心能否在图像范围内,如不能则移除这组候选点。
步骤4再次使用式(1)对候选点进行投票,拥有票数最高的两个点作为第二灭点V2和第三灭点V3,并将属于V2和V3的直线归为集合L2和L3。
4 场景布局的生成
在获得代表场景方向的灭点信息后,进行场景布局信息的还原,分3个步骤进行:
(1)根据灭点信息生成固定数量的候选场景模型,并选择出与图像最为相符的模型作为初级场景模型。
(2)对图像进行特征提取,分析并推测出图像内潜在物品的立方体模型。
(3)根据场景模型和物品模型之间的关系,对场景模型进行优化,从而得到最终的三维场景布局。
4.1房间箱体模型的生成
本文使用箱体模型代替真实的场景模型,从而获得场景的粗略估计。在生成房间箱体模型的过程中,最为核心的问题就是如何在遮挡的情况下确定箱体模型顶点在图像上的投影点的位置。图像中至多拥有箱体模型的5个可见面,分别为顶面、地面、后墙、左墙和右墙,且每个可见面在图像中的投影都将看作一个多边形。
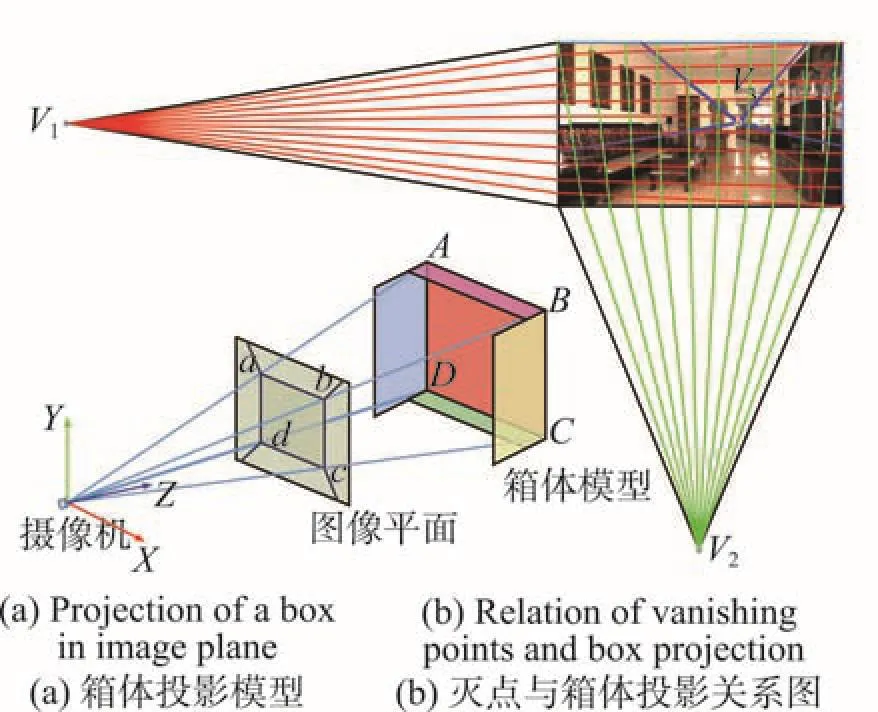
Fig.5 An illustration of box projection and how to generate layout from vanishing points图5 箱体模型投影示意图
已知箱体模型的顶点,在图像平面上对应的投影点与代表房间主轴方向的灭点之间存在严格的几何约束。图5(a)为箱体模型的投影示意图,在三维空间中箱体模型的4个顶点用A、B、C、D表示,其对应二维图像中的投影点分别为a、b、c、d。代表场景主轴方向的3个灭点记为Vi(i = 1,2,3)。在灭点已知的条件下,可知在图像平面中:
(1)线段ab和cd应与灭点V1共线;
(2)线段ad和bc应与灭点V2共线;
(3)灭点V3在图像四边形区域abcd中。
为生成场景模型,选取两个距离图像较远的灭点V1和V2,从两个灭点向图像发射固定数量的射线,文中取10。图5(b)中,红色和绿色线分别代表从两个不同灭点发出的射线,并最终在图像中相交,投影点a、b、c、d将从这些交点中选择。四边形区域abcd代表了后墙的范围,剩余的墙面将由灭点V3与投影点的连线构成。
在生成候选点集的过程中,存在两种发射射线方式:(1)依照图像边缘设定固定间隔值,再由灭点向图像发射射线;(2)根据图像中已有的投影线,使由灭点出发的射线经过这些投影线。本文工作采用的是前者,其主要优势在于可以生成数量固定,候选点分布均匀的候选模型集合,使算法保持稳定性,不易受到噪音影响。但这也意味着,很难从生成的候选点集中直接得到准确的投影点位置。因此,根据该步骤得到箱体模型为初级场景模型。投影点的选择将使用Structured-SVM[18]训练出的参数自动地进行。
4.2房间内物品箱体模型的生成
从上文可知,得到的初级场景模型并不能保证一定符合图像场景,因此需要对得到的场景模型做进一步的优化。如果能从图像中提取出一些较为重要的物品模型,并考虑场景内房间布局和物品布局的体积关系,即物体模型必摆放在场景模型内部,从而推测出更为合理的场景模型。
从单张图片中提取出物体的三维模型是非常困难的,但本文通过图像特征来搜寻图像中的物品,并使用立方体模型来粗略表示物品,从而达到推测场景空间布局的目的。
本文使用两种方法提取图像中的特征: Hoiem等人[16]的图像区域分类器和Lee等人[12]的线段扫描算法。Hoiem等人[16]的分类器可以将图像分为不同的特征区域,从而帮助人们提取出场景内的关键投影线。首先,将图像分割成若干像素块[19],每个像素块粗略代表类似的可见物品。结合像素块和场景模型,可以将图像内的像素归类到不同墙面中。结果如图6(c)所示,其中粉色的像素代表图像中潜在的物品。Lee等人[12]的算法通过图像中检测到的灭点与投影线推测出平行于三维空间主轴的平面。已知某个灭点和一条与其共线的投影线段,该线段的端点沿着它与另一灭点的连线方向移动。在移动因另一条直线阻挡而停止后,将得到两个新的端点,并与原端点组成一个平面。结果如图6(d)所示,其中3种颜色分别表示平行于不同主轴方向的平面。
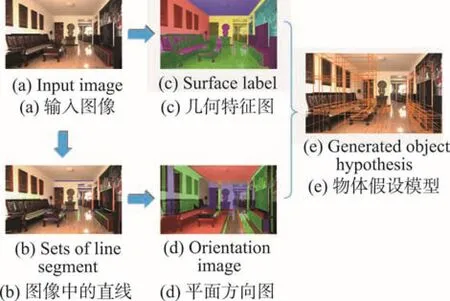
Fig.6 Generation workflow of cubiod proxy for indoor funiture图6 物体模型生成图流程
在得到两种图像特征后,通过对图像特征数据的推测可以自动检测出图像中较为重要的物品,如椅子、桌子、柜子等。首先,通过平面特征的分析找到图像中物品的立方体模型。对平面特征中属于两种不同方向的平面进行成对的检测,取两个平面上的3个角点,则可以判定是否这两个平面能确定一个立方体的平面投影。对于可以组成立方体的每组平面,找到其最为合适的3个角点,并生成相应的立方体模型。之后,将得到的立方体模型与图像的几何特征相结合,从而得到筛选后的物体模型。对于每个立方体模型,计算其图像投影内所包含的潜在物体像素与投影内像素的比率,并将比率较低的立方体模型移除。
5 基于灭点的场景三维重建
在得到场景布局后,为生成对应的三维模型,需要进行图像到三维模型的转换,其关键步骤是计算图像上的点对应的三维空间坐标。根据房间主轴方向和灭点的相关性,重新对相机的标记矩阵和旋转矩阵进行推导,并根据箱体模型的特点设定:在世界坐标系下,底面和顶面平行于平面X=0,左墙和右墙平行于平面Y=0,后墙平行于平面Z=0,且相机到底面的高度为1。
假定空间中存在一点P,在世界坐标系下的齐次坐标记为Pw= (Xw,Yw,Zw,1)T,在图像平面上对应的投影点的齐次坐标记为pi= (xi,yi,1)T。相机模型如图7所示,C为投影中心,投影中心到图像平面的垂线称为摄像机的主轴Z,其交点为主心c= (xc,yc,1)T,投影中心C到主心c的距离为焦距f。由针孔模型可知三维空间坐标到图像坐标的变换为:
pi=K[R|t]Pw(2)
其中,矩阵K为相机的标定矩阵;R和t分别为世界坐标系到相机坐标系的旋转矩阵和平移向量。
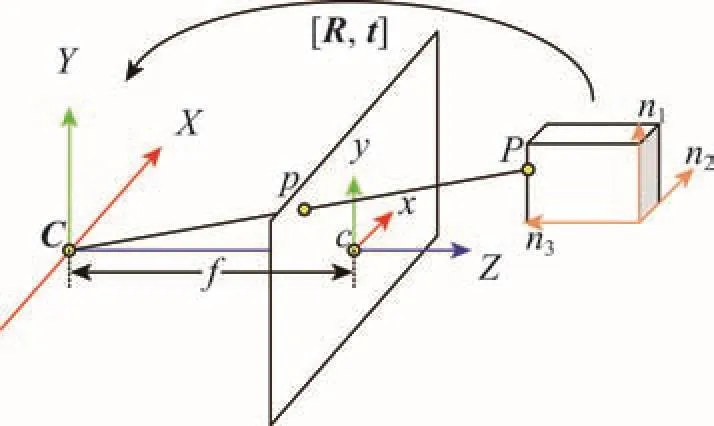
Fig.7 Transformation model between world coordinate and camera coordinate图7 世界坐标系与相机坐标系的转换模型
(1)相机标定矩阵K
假定摄像机和像素都是理想状态,那么标定矩阵K可以直接由代表3组正交方向的灭点计算得到。Vj(j = 1,2,3)代表3个相互正交灭点,其在图像平面的坐标记为vj= (xvj,yvj,1)T,在相机坐标系下的坐标记为Vj= (Xvj,Yvj,f)T,其中Xvj= xvj-xc,Yvj= yvj- yc。可知,主心p即为以灭点Vj(j = 1,2,3)为顶点的三角形的垂心,焦距f满足关系XvjXvk+ YvjYvk+ f2= 0。
(2)旋转矩阵R
已知灭点Vj(j = 1,2,3)代表世界坐标系中3个方向的无穷远点,且这3个方向分别为世界坐标系中3个主轴的方向。记V为灭点方向在世界坐标系下的单位向量,V'为灭点方向在相机坐标系下的单位向量,R为从世界坐标系到相机坐标系变换的旋转矩阵,则V'= RV,其中V为单位矩阵。由此可得R= V',其中V'= (V'1,V'2,V'3),V'j的计算公式为:

6 实验结果
为验证方法的有效性,本文对上述理论与算法进行性能测试。分别从Hedau等人[3]的图像数据库和部分互联网图像中(总计共500张),选择分辨率不同,场景不同的图像进行测试,部分实验结果见图8。实验中计算机配置为: Intel Core Q9400处理器,4 GB内存,NVIDIA GeForce GTX 460显卡及64位W indows7系统。
在同等条件下,针对不同分辨率的图像,对改进后的灭点检测算法与Hedau等人[3]的灭点检测算法进行测试,并对两种算法在时间和冗余直线的数量上进行比较。
如图9所示,随着分辨率的增加,本文的灭点检测算法在时间消耗上远远少于Hedau等人[3]的算法。图10结果说明,结构化的边缘检测算法有效减少了检测到的冗余直线的数量。实验结果表明,经过改进的灭点检测不但可以快速处理分辨率很高的图像,而且避免了由于冗余直线数量过多导致错误灭点检测结果的最坏情况。
如表1所示,在像素错误率上本文算法结果低于Hedau等人[3]的算法,但正确率依然不高。出现错误的原因主要在于选取了错误的局部最优箱体模型,或由于物品模型不准确影响房间模型优化结果。通过图8所示的场景布局还原结果可以看出,本文算法可以基本还原出图像场景结果,并找到图像内物品的模型。
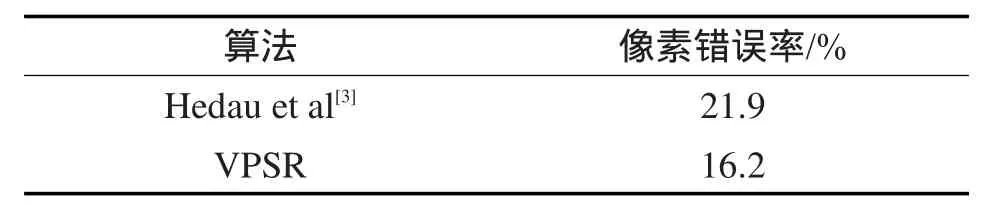
Table 1 Pixel error comparison between two algorithms表1 算法像素错误率的比较
7 结束语
本文将结构化的边缘检测方法引入到灭点检测算法中,有效减少了冗余直线的数量,极大提高了灭点计算的效率和准确性。本文在还原场景布局的过程中,加入了模型优化的步骤,从而显著改善了图像布局还原的结果。

Fig.8 Results of indoor scene layout restoration图8 场景布局还原的部分实验结果
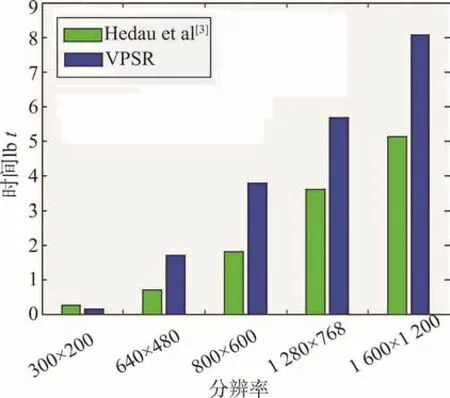
Fig.9 Average computing time of vanishing points detection图9 灭点检测算法平均耗时
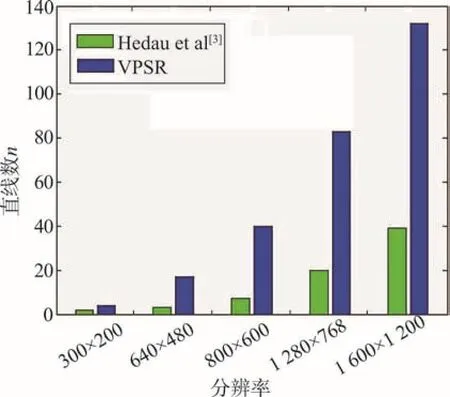
Fig.10 Number of redundant lines of line segments detection图10 投影线检测到的冗余直线的数量
实验过程显示,场景还原的结果还不够准确,在未来研究中考虑将家居环境的语义分割引入到场景还原过程中以提高算法的运行结果。由于重建出来的场景真实度不高,将改进纹理的提取与映射方法。并且为实现图像的家居虚拟编辑与设计,将针对图像物品的立方体重建进行研究。
References:
[1] Zhang Bo, Xie Ning, Xu Hao, et al. Web3D CID: Web3D collaborative interior design based on transparent adaptation[C]//Proceedings of the 13th ACM SIGGRAPH International Conference on Virtual-Reality Continuum and its Applications in Industry, Shenzhen, China, Nov 30-Dec 2, 2014. New York, USA:ACM, 2014: 113-121.
[2] Houzz. Desgin home online[EB/OL]. [2015-08-03] http:// www.houzz.com.
[3] Hedau V, Hoiem D, Forsyth D. Recovering the spatial layout of cluttered rooms[C]//Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 2009. Piscataway, USA: IEEE, 2009: 1849-1856.
[4] Bao S Y, Furlan A, Li Feifei, et al. Understanding the 3D layout of a cluttered room from multiple images[C]//Proceedings of the 2014 IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, USA, Mar 24-26, 2014. Piscataway, USA: IEEE, 2014: 690-697.
[5] Yang Hao, Zhang Hui. Indoor structure understanding from single 360 cylindrical panoram ic image[C]//Proceedings of the 2013 International Conference on Computer-Aided Design and Computer Graphics, Guangzhou, China, Nov 16-18, 2013. Piscataway, USA: IEEE, 2013: 421-422.
[6] Jia Hanchao, Li Shigang. Estimating the structure of rooms from a single fisheye image[C]//Proceedings of the 2013 2nd IAPR Asian Conference on Pattern Recognition, Naha, Japan, Nov 5-8, 2013. Piscataway, USA: IEEE, 2013: 818-822. [7] Rother C. A new approach to vanishing point detection in architectural environments[J]. Image and Vision Computing, 2002, 20(9): 647-655.
[8] Zhang Jian, Kan Chen, Schw ing A G, et al. Estimating the 3D layout of indoor scenes and its clutter from depth sensors[C]//Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 2013. Piscataway, USA: IEEE, 2013: 1273-1280.
[9] Gupta A, Efros A A, Hebert M. Blocks world revisited: image understanding using qualitative geometry and mechanics[C]//LNCS 6314: Proceedings of the 11th European Conference on Computer Vision, Heraklion, Greece, Sep 5-11, 2010. Berlin, Heidelberg: Springer, 2010: 482-496.
[10] Chen Tao, Zhu Zhe, Sham ir A, et al. 3-Sweep: extracting editable objects from a single photo[J]. ACM Transactions on Graphics, 2013, 32(6): 195.
[11] Gupta A, Hebert M, Kanade T, et al. Estimating spatial layout of rooms using volumetric reasoning about objects and surfaces[C]//Advances in Neural Information Processing Systems 23: Proceedings of the 24th Annual Conference on Neural Information Processing Systems, Vancouver, Canada, Dec 6-9, 2010: 1288-1296.
[12] Lee D C, Hebert M, Kanade T. Geometric reasoning for single image structure recovery[C]//Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, M iami, USA, Jun 20-25, 2009. Piscataway, USA: IEEE, 2009: 2136-2143.
[13] Hedau V, Hoiem D, Forsyth D. Thinking inside the box: using appearance models and context based on room geometry [C]//LNCS 6316: Proceedings of the 11th European Conference on Computer Vision, Heraklion, Greece, Sep 5-11, 2010. Berlin, Heidelberg: Springer, 2010: 224-237.
[14] Kang H W, Pyo S H,Anjyo K, et al. Tour into the picture using a vanishing line and its extension to panoramic images[J]. Computer Graphics Forum, 2001, 20(3): 132-141.
[15] Saxena A, Sun M, Ng A Y. Make3D: learning 3D scene structure from a single still image[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(5): 824-840.
[16] Hoiem D, Efros A A, Hebert M. Recovering surface layout from an image[J]. International Journal of Computer Vision, 2007, 75(1): 151-172.
[17] Dollár P, Zitnick C L. Structured forests for fast edge detection[C]//Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, Dec 1-8, 2013. Piscataway, USA: IEEE, 2013: 1841-1848.
[18] Tsochantaridis I, Joachims T, Hofmann T, et al. Large margin methods for structured and interdependent output variables[J]. Journal of Machine Learning Research, 2005, 6: 1453-1484.
[19] Felzenszwalb P F, Huttenlocher D P. Efficient graph-based image segmentation[J]. International Journal of Computer Vision, 2004, 59(2): 167-181.

WANG Haifei was born in 1992. He is an M.S. candidate at Tongji University. His research interest is image-based virtual house.
王海菲(1992—),男,山东掖县人,同济大学软件学院硕士研究生,主要研究领域为基于单张图像的虚拟家居。

JIA Jinyuan was born in 1963. He received the Ph.D. degree from Hong Kong University of Science & Technology in 2004. Now he is a professor and Ph.D. supervisor at Tongji University, and the senior member of CCF. His research interests include Web graphics, virtual reality and 3D game engine, etc.
贾金原(1963—),男,山东乐陵人,2004年于香港科技大学获得博士学位,现为同济大学软件学院教授、博士生导师,CCF高级会员,主要研究领域为Web Graphics,虚拟现实,游戏引擎等。发表过多篇SCI论文,承担的主要科研项目有国家“十二五”计划重大科技支撑项目子课题,国家自然科学基金面上项目等。

XIE Ning was born in 1983. He received the Ph.D. degree from Tokyo Institute of Technology in 2012. Now he is an assistant professor at Tongji University, and the member of CCF. His research interests include machine learning and application, digital media technology, computer image and graphics processing, etc.
谢宁(1983—),男,吉林长春人,2012年于东京工业大学获得博士学位,现为同济大学软件学院助理教授,CCF会员,主要研究领域为机器学习及应用,数字媒体技术,图形图像处理等。
Vanishing Point Detection and Scene Reconstruction of Cluttered Roomƽ
WANG Haifei, JIA Jinyuan, XIE Ning+
School of Software Engineering, Tongji University, Shanghai 201804, China
Key words:virtual house; image understanding; vanishing points detection; 3D reconstruction; box modeling of indoor scene
Abstract:Recently, the 3D reconstruction of indoor scene becomes a hot spot of research, as the popular of virtual house. Based on image understanding, this paper proposes an image-based box modeling method of 3D indoor scene reconstruction. Firstly, the vanishing points of indoor scene image are detected to represent the main axis of the room. With the analysis of algorithmƳs influence factors, this paper improves the vanishing points detection algorithm to ensure efficiency and accuracy. Then, this paper recovers automatically the scene spatial layout information w ith the layout reasoning steps which significantly improve the result. Finally, the calculation of camera parameters is performed by using vanishing point, so the conversion from image scene to 3D model is implemented. The experiments demonstrate that the proposed method can quickly analyze the indoor scene images and detect the 3D layout for virtual scene reconstruction.
doi:10.3778/j.issn.1673-9418.1512046 E-mail: fcst@vip.163.com
文献标志码:A
中图分类号:TP391.9
