超高频RFID新型后退式二叉树防碰撞算法*
2016-06-07唐志军吴笑峰席在芳胡仕刚
唐志军,阳 懿,吴笑峰,席在芳,胡仕刚
超高频RFID新型后退式二叉树防碰撞算法*
唐志军+,阳懿,吴笑峰,席在芳,胡仕刚
湖南科技大学信息与电气工程学院,湖南湘潭411201
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2016/10(05)-0646-11
E-mail: fcst@vip.163.com http:
//www.ceaj.org Tel:
+86-10-89056056
* The National Natural Science Foundation of China under Grant Nos. 61377024, 61274026, 61376076 (国家自然科学基金); the Scientific Research Fund of Hunan Provincial Education Department under Grant No. 14B060 (湖南省教育厅青年项目); the Science and Technology Project of Hunan Province under Grant Nos. 2014FJ2017, 2013FJ2011 (湖南省科技计划项目).
Received 2015-06,Accepted 2015-08.
CNKI网络优先出版: 2015-09-01, http://www.cnki.net/kcms/detail/11.5602.TP.20150901.1538.006.htm l
TANG Zhijun, YANG Yi, WU Xiaofeng, et al. Novel back-off binary tree anti-collision algorithm for ultra high frequency RFID. Journal of Frontiersof Com puter Scienceand Technology, 2016, 10(5): 612-622.
摘要:针对目前超高频射频识别(radio frequency identification,RFID)二叉树防碰撞算法通信量大和传输时
延长等问题,结合跳跃式动态搜索(jumping dynam ic search,JDS)和新颖跳跃式动态搜索(novel JDS,NJDS)防碰撞算法,引入后退寻呼策略,提出了一种新的后退式二叉树(novel back-off binary tree,NBBT)防碰撞算法。该算法通过在阅读器寻呼指令中加入引导位使标签以更快的速度响应阅读器,从而减少总通信量和传输时延。仿真结果表明,与现有JDS或NJDS防碰撞算法相比,该算法在传输时延和通信量方面更高效。此外,该算法能够显著提高阅读器和标签之间的通信速率。
关键词:射频识别(RFID);二叉树防碰撞算法;后退寻呼;引导位
1 引言
物联网是构成物与物之间相互通信的一种网络,被称为继计算机、互联网之后世界信息产业的第三次浪潮[1]。作为实现物联网的关键技术[2],射频识别(radio frequency identification,RFID)是一种以电磁波为传输介质来实现数据双向通信的非接触式自动识别技术。超高频RFID系统识别距离远,目前广泛应用于物流、交通、军事等各个领域,但在对多目标的识别上还存在识别时间长,准确率低和通信量大等问题,这已成为超高频RFID技术发展的瓶颈。为了顺应物联网的发展,RFID技术正在不断革新,而解决超高频RFID系统在识别标签过程中存在的碰撞问题,就显得至关重要。因此,选择一种好的防碰撞算法对物联网中的RFID系统性能影响很大。
目前RFID系统的标签防碰撞算法大多采用时分多址方法,该方法可分为非确定性算法和确定性算法两大类[3]。ALOHA算法是一种传统的非确定性算法,但其标签存在“饥饿”问题(tag starvation)。二进制树型搜索算法是一种典型的确定性算法,这种算法实现起来比较复杂,识别时间也相对较长,但不存在标签饥饿问题[4]。对于需要保证准确率的识别系统选择二叉树防碰撞算法是一个不错的选择[5-6]。基于二叉树的确定性算法虽然解决了标签饥饿的问题,但与ALOHA算法相比其存在识别周期长,询问次数多,吞吐率低和标签耗能大等问题[7]。最近几年,国内外学者对二叉树防碰撞算法进行了广泛研究。如文献[8]提出了一种增强型智能分组时隙二叉树算法,通过将标签进行智能分组的方式有效地解决了标签响应的碰撞问题。文献[9]将二叉树防碰撞算法和时隙ALOHA防撞算法相结合,提出了二叉树时隙ALOHA防撞算法,这种算法不需要估计标签数量,从而提高了防碰撞算法的效率。文献[10]提出了一种广义的二叉树协议,将识别进程分配到多个二叉树中来解决识别效应问题。堆栈二叉树算法[11]构建一个“ID二叉树”,并用堆栈存储标签的碰撞信息,同时标签利用计数器来跟踪自身在堆栈中的位置,从而减少与阅读器的通信量,使系统识别效率得到提升。Yang等人[12]对基于查询树16位随机数算法进行了性能分析,并提出了高效查询树的16位随机数算法。文献[13]通过分析后退式索引二进制树形搜索算法的基本原理,提出了一种基于后退式索引二进制树形搜索的RFID防碰撞算法。该算法利用碰撞节点的信息,有效地减少了数据的传输量,提高了阅读器识别标签的速率。王鑫等人[14]通过制订一组特殊的编码,在二叉树碰撞跟踪树算法基础上,提出了三叉碰撞跟踪树算法,此算法通过降低搜索树的整体深度,有效地提高了算法识别速率。文献[15]提出了一种改进的四叉树算法,该算法的标签根据不同的阅读器寻呼命令来修改自身应答概率并进行分组,以减少阅读器寻呼次数和通信量,从而有效提高了阅读器的识别效率。目前,虽然二叉树算法较多,对RFID系统性能改进各异,并偏向不同的改进点,但是根据对这些算法进行分析可以得出,其主要改进方式有分组、后退、自适应、多叉树、索引、标记和堆栈等。其中引用分组的算法减少了阅读器寻呼次数,但是根据分组方式的不同会要求增强阅读器或者标签的功能。后退算法是在阅读器的阅读方式上进行改进,在算法性能上的改进主要是减少了阅读器的寻呼数据量。运用自适应功能的算法主要改进点在标签的响应方式上,标签需具有记忆功能。多叉树算法主要是通过改变编码方式使标签自动分组,达到减少阅读器寻呼次数的目的,但是这种方式使标签的通用性变差。索引是在阅读器寻呼指令前端加入引导标签响应的字段,减少标签响应的通信量。标记是在标签中添加一个与自身响应次数有关的计数器,减少标签响应次数。索引和标记都使标签的功能复杂化,不利于当前降低标签价格的发展趋势。堆栈是阅读器一种存储通信数据的结构,可以记录阅读器的寻呼指令和记录标签的响应信息,它一般不单独出现,是后退等功能实现的依靠。
基于此,本文结合跳跃式动态搜索(jumping dynam ic search,JDS)防碰撞算法和新颖跳跃式动态搜索(novel jumping dynam ic search,NJDS)防碰撞算法,引入一种改进的阅读器后退寻呼方式,提出了一种新的后退式二叉树(novel back-off binary tree,NBBT)防碰撞算法,期望能够为物联网RFID技术的发展提供帮助。
2 NBBT算法机理
如图1所示,设有4个标签A、B、C、D,标签ID分别为1000、0001、0100、0110。图中有两种后退方式,其中后退方式1是目前一般采用的方法,NJDS算法就是用的这种后退方式,后退方式2是JDS算法中采用的方法。在步骤2中阅读器发送00后只有标签B响应,识别标签B后,后退方式1中阅读器将发送命令改为01,而后退方式2中阅读器则还是发送0信号,其阅读器通信量就比后退方式1减少了1位。在图例中只出现了一次有差异的后退方式,而在实际应用中这个减少的数据量就可能扩大很多倍。从图1中可看出,两种后退方式的阅读器通信量相差较大,这一点在后续仿真部分中会得到进一步验证。
通过对JDS和NJDS算法所采用的后退策略比较可以发现:JDS算法使用的后退策略比NJDS算法使用的后退策略要先进;在同等条件下不考虑阅读器寻呼指令中的标志位时,JDS算法的阅读器通信量要比NJDS算法的通信量少。对JDS算法中的后退策略进行分析发现,其识别一个标签后,从堆栈中取得上一次寻呼命令的唯一标识码(unique identifier,UID)再一次寻呼。而NJDS算法识别一个标签后,是改变当前寻呼命令中的UID来寻呼,而上一次寻呼命令总是要比当前寻呼命令的数据量要少,因此JDS算法的阅读器通信量要少。NBBT算法就是在NJDS算法的基础上采取JDS算法中的后退策略,来达到减少防碰撞算法中总通信量的目的。鉴于篇幅限制,关于JDS和NJDS算法的具体分析过程在此不再赘述,下面主要阐述NBBT算法的改进思路及机理。
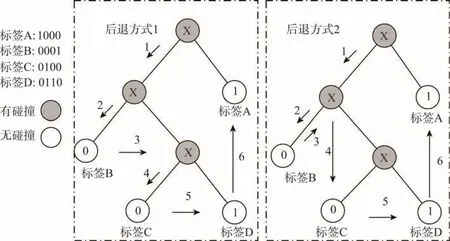
Fig.1 Comparison of back-off reading mode图1 后退阅读模式比较
在NBBT算法中,将标签响应的信息分为4部分:第一部分为最高碰撞位与最高碰撞位之前的信息,参与形成下一次寻呼的UID,保存每一次的UID在堆栈0中;第二部分为最高碰撞位与次高碰撞位之间的信息,为阅读器已知信息存入堆栈1中,设这部分信息为String1;第三部分为次高碰撞位与最低碰撞之间的信息,为阅读器未知部分,是需要标签响应的部分,标签只要知道其ID中未知部分的范围即可,保存次高碰撞位和最低碰撞位加入到下一次寻呼命令中;第四部分为最低碰撞位到末尾的信息,这部分信息也是已知信息存入堆栈2中,设这部分信息为String2。设标签响应的信息为1X0X0X1,这4个部分的划分如表1所示。

Table 1 Example of tag response information division表1 标签响应信息划分举例
阅读器寻呼的信息包含提供给标签匹配的UID和需要标签返回其ID信息中有用信息的两个标志位。阅读器收到标签响应的信息后先形成一个与标签ID长度相同的信息设为TC,TC就是所有响应的标签ID的完整叠加信息。将当前的TC存入堆栈3中,其表达式为:
TC=UID+String1+ID+String2(1)
NBBT算法中的阅读器寻呼分为向前搜索和后退搜索两部分,如果标签响应的信息中有两个或两个以上的碰撞位则阅读器采取向前搜索,反之向后搜索。当阅读器向前搜索时存储TC,当阅读器识别一个标签后开始后退搜索,移除堆栈3中的顶部信息后,读取当前顶部信息得到上一次的TC,从而形成String1、String2和标签所要响应的ID范围,移除堆栈0中的顶部信息后,读取当前顶部信息作为下一次寻呼的UID。例如,得到的上一次TC为00X0X0X0,上一次的UID为0,则下一次寻呼指令中的UID为0,取得TC中次高位之前的位除去首部UID的信息0得到P(0X0),按照向前搜索规则,上一次寻呼的UID为000,最后一位就是TC中最高碰撞位置0得出的,而这次就将最高碰撞位置1,将P中的X改为1得到010存入String1中。最高碰撞位与次高碰撞位之间的0保存在String2中,标签需要返回的ID信息就是次高位与最低碰撞位之间的信息。假设TC从左至右的位数第一位为0,则标签需要返回的ID信息的范围为[4, 6],阅读器寻呼这段指令后假设收到标签的信息为100,阅读器根据式(1)形成标签的ID信息为00101000。这里UID和String1中的信息组成形式就是改进后退策略的特点。利用这种方法就减少了阅读器的通信量,当阅读器后退搜索的次数越多,在后退中的UID与上一次识别了一个标签的UID信息长度相差越多,在标签识别过程中阅读器的寻呼量就减少得越多。在此假设中后退中的UID为0,上一次识别了一个标签的UID为000,按照原来的后退策略,后退中的UID应该为001,则经过改进后标签通信量减少了2,而这两位信息存入了String1中。
3 NBBT算法相关指令
因为在NBBT算法中阅读器寻呼加入了两个位置序号,所以其寻呼指令与传统二叉树算法有所不同,但其主要的指令数量不变,只改变了阅读器寻呼指令,其他指令与传统的二叉树算法相同,这里只介绍其不同部分。
REQUEST(UID,P0,P1):阅读器寻呼指令。因为在后退算法中有向前寻呼和向后寻呼模式,所以在不同的寻呼模式下,寻呼指令中的参数来源不同。当阅读器处于向前寻呼时,与大多数算法相同,UID来自于标签响应信息中的最高碰撞位之前的位加上一个0,这时就代表搜寻二叉树的0分支,直至识别一个标签。P0和P1代表阅读器对标签ID未知序列的范围,也就是标签响应信息中第三部分在TC中的范围。假设标签的ID从左至右由低到高,则P0代表标签ID序列中需要响应的最高位,P1代表最低位,则标签ID序列响应的区间是[P0,P1]。当阅读器处于向后搜索时,因为每一次阅读器寻呼的UID都存入了堆栈0,所以先使堆栈0出栈一次,再推出堆栈0的顶部信息形成UID。P0、P1来自于堆栈3,也是先使堆栈3出栈一次,然后再通过堆栈3的顶部信息来判断标签响应信息中的第三部分的形成。标签接收到寻呼指令后先判断寻呼指令中的UID是否匹配,相匹配则将其ID中P0至P1位中的信息响应给阅读器。
REQUEST(NULL,0,P1),阅读器广播指令。这是一条特殊的寻呼指令,其UID等于空,代表所有标签都要响应;P0等于0代表标签响应的信息从ID的起始位开始;P1是一个常数,其值等于标签ID的长度,代表标签响应的信息到ID的最高位结束。这条指令的整体意义在于所有处于激活状态的标签都将其自身的ID响应给阅读器。
4 NBBT算法流程
采用NBBT算法的阅读器在其工作时用到了4个堆栈,堆栈存放的信息如下:
Stack0:在阅读器发送寻呼指令前,将UID存入其中。
Stack1:保存标签信息的第二部分String1。
Stack2:保存标签信息的第四部分String2。
Stack3:在收到标签响应信息后,保存形成的TC。
下面阐述阅读器的工作流程:
(1)阅读器发送广播命令REQUEST(NULL,0,P1),将一个空的信息存入Stack0、Stack1和Stack2中。标签收到这个信息后都发送自己的ID给阅读器,进入步骤(2)。
(2)分析接收到的标签信息,如果响应信息为空,代表在阅读器寻呼范围内没有标签,则结束识别过程。如果有响应且没有碰撞,则识别这个标签进入步骤(3),后退阅读模式;如果有响应且只有一个碰撞,则识别两个标签进入步骤(3),后退阅读模式;如果有响应且有一个以上的碰撞位,则进入步骤(4),向前阅读模式。
(3)后退阅读模式。推出Stack0顶部信息,如果顶部信息为空,则代表阅读器处于根节点,不可后退,结束识别过程。如果不为空,则保存这部分信息,设其为UID1;Stack0的顶部信息继续推出,设为UID0,UID1信息长度必定大于UID0,设UID1相比UID0多出的部分D,Stack1出栈两次,保存后一次的信息为Str1;将D与Str1结合形成新的String1存入Stack1中,Stack2出栈一次,Stack3出栈两次,保存后一次信息TC;去掉TC中与UID0信息相同的部分得到信息ID,将信息ID当作标签响应信息分为4部分,将第二和第四部分存入对应堆栈中;根据标签响应信息中的第三部分得出阅读器寻呼指令中的P0和P1,将UID0作为这次寻呼指令中的UID,阅读器发送寻呼指令REQUEST(UID,P0,P1),进入步骤(2)。
(4)向前阅读模式。将标签响应信息Stack1、Stack2的顶部信息代入式(1)形成TC,并将其存入Stack3中,将Stack1和Stack2出栈,根据标签的响应信息的4部分,将第二和第四部分存入对应堆栈中。从Stack0中得到上一次的寻呼UID与第一部分信息相结合形成UID,将UID最后一个碰撞位X改为0,形成新的UID;利用标签信息的第三部分信息得出P0和P1,阅读器发送寻呼指令REQUEST(UID,P0,P1),进入步骤(2)。
从NBBT算法的工作流程中可以看出其工作步骤只有两步:向前阅读和向后阅读。如果阅读器寻呼范围内有标签时则结束识别过程,其一定是处于向后阅读模式中。NBBT算法识别流程图如图2所示。
5 NBBT算法识别演示
设在阅读器寻呼范围内有5个标签,标签的ID和识别过程如表2所示。
下面对NBBT算法识别这5个标签的过程进行详细说明。
(1)阅读器发送广播指令REQUEST(NULL,0,7),将NULL存入堆栈0、1、2中。标签接收到广播指令都将自己的ID发送给阅读器,发送的混合信号为X1XXXXXX。
(2)阅读器对接收到的信息进行译码,得到的ID 为X1XXXXXX,ID的碰撞位大于一个,根据ID得出Part1为X,Part2为1,Part3为XXXXXX,Part4为NULL。读取Stack0、Stack1、Stack2的顶部信息分别赋给UID (NULL)、String1(NULL)、String2(NULL),根据式(1)生成TC等于X1XXXXXX,将TC存入Stack3,分析TC得出下一次寻呼的UID、P0、P1分别为0、2、7。将UID(0)存入Stack0,Part2(1)的数据存入Stack1,Part4(NULL)的数据存入Stack2。阅读器发出寻呼指令REQUEST(0,2,7)。标签接收到寻呼指令,根据寻呼指令的UID信息进行匹配,匹配的标签发送其ID的2 到7位的序列号给阅读器。Tag1、2、4、5匹配成功。
(3)阅读器接收的ID为XX0XXX,ID的碰撞位大于一个,根据ID得出Part1为X,Part2为NULL, Part3为X0XXX,Part4为NULL。读取Stack0、Stack1、Stack2的顶部信息分别赋给UID(0)、String1(1)、String2(NULL),根据式(1)生成TC等于01XX0XXX,将TC存入Stack3,分析TC得出下一次寻呼的UID、P0、P1分别为010、3、7。将UID(010)存入Stack0,Part2(NULL)的数据存入Stack1,Part4(NULL)的数据存入Stack2。阅读器发出寻呼指令REQUEST(010,3,7)。Tag1、2、4响应,发送其ID的3到7位的数据给阅读器。
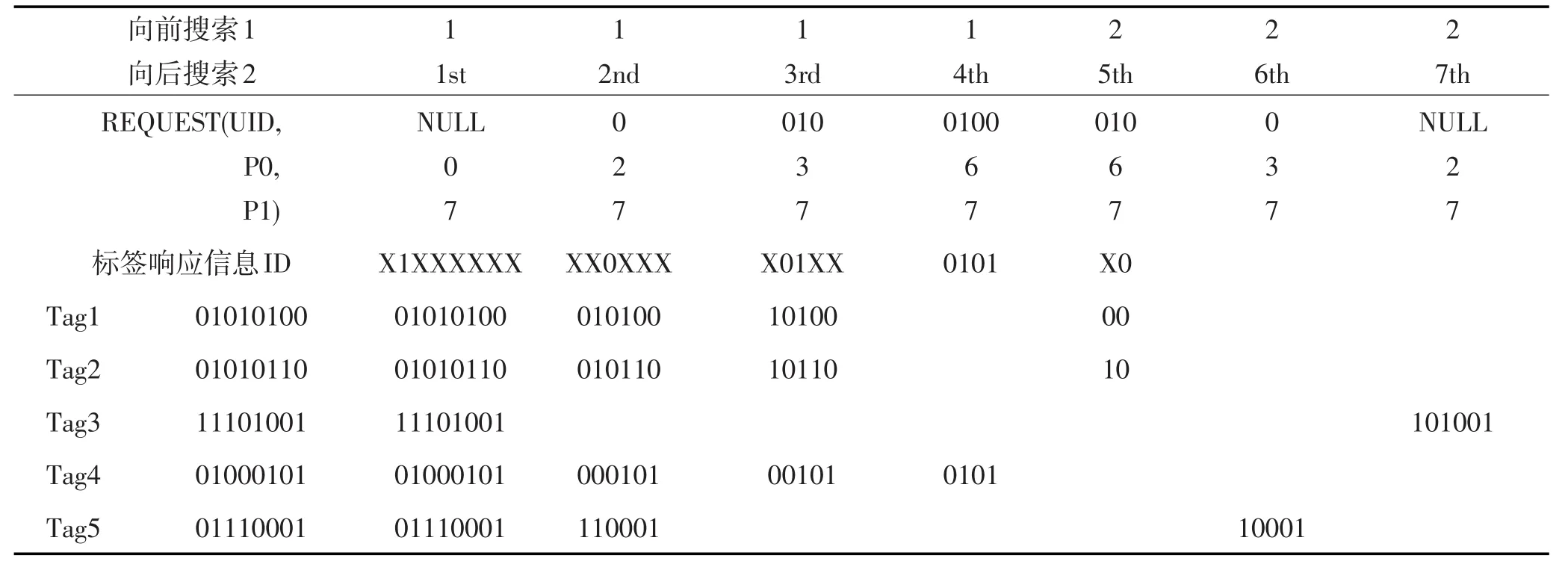
Table 2 Demonstration of NBBT algorithm identification process表2 NBBT算法识别过程演示
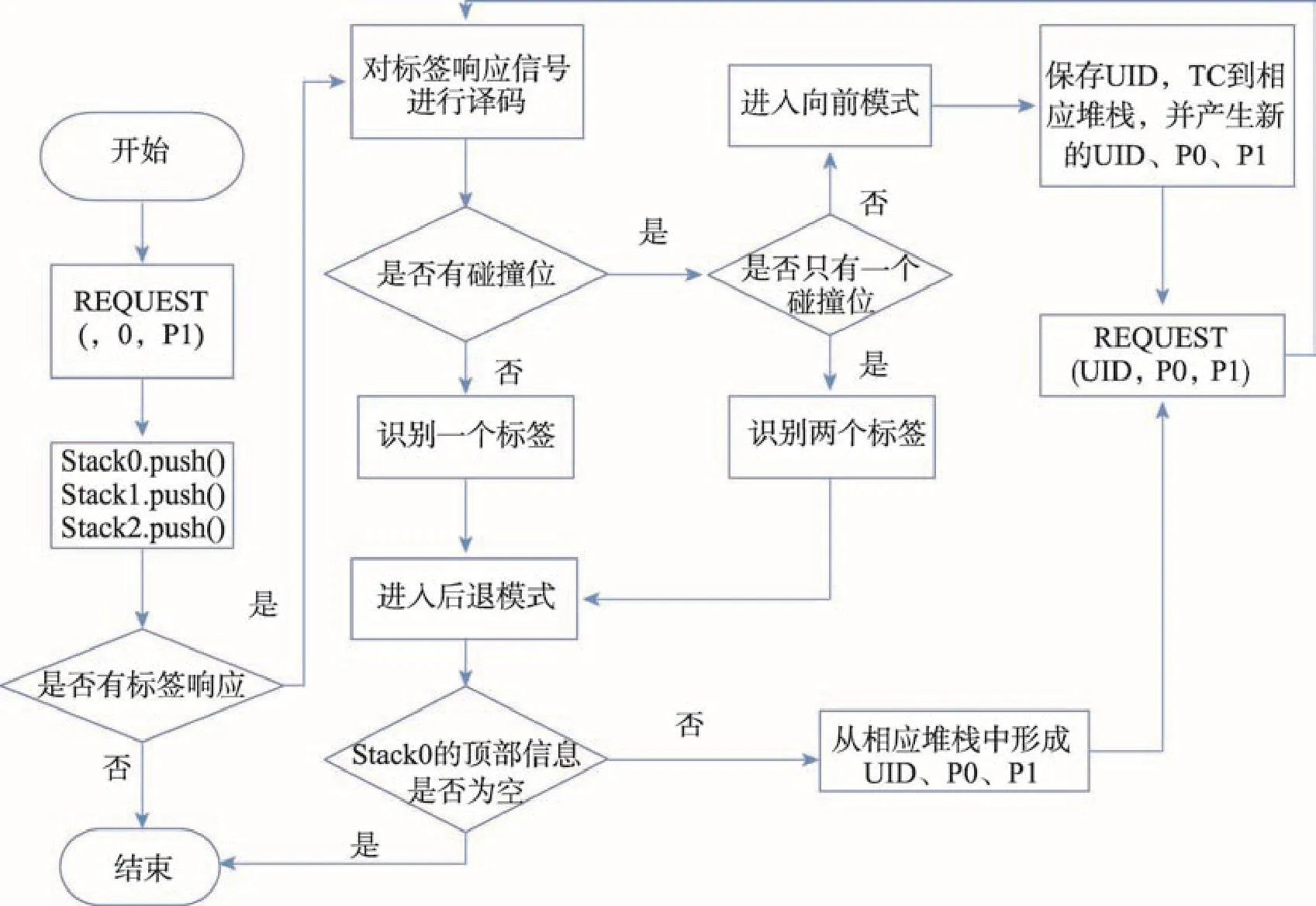
Fig.2 Flow chart of NBBT algorithm identification图2 NBBT算法识别流程图
(4)阅读器接收的ID为X01XX,ID的碰撞位大于一个,根据ID得出Part1为X,Part2为01,Part3为XX,Part4为NULL。读取Stack0、Stack1、Stack2的顶部信息分别赋给UID(010)、String1(NULL)、String2 (NULL),根据式(1)生成TC等于010X01XX,将TC存入Stack3,分析TC得出下一次寻呼的UID、P0、P1分别为0100、3、7。将UID(0100)存入Stack0,Part2 (01)的数据存入Stack1,Part4(NULL)的数据存入Stack2。阅读器发出寻呼指令REQUEST(0100,3,7)。Tag4响应,发送其ID的3到7位的数据给阅读器。
(5)阅读器接收到的ID为0101,ID没碰撞位,读取并推出Stack0、Stack1、Stack2的顶部信息分别赋给UID(0100)、String1(NULL)、String2(NULL),根据式(1)得出TC等于01000101,识别Tag4。将Stack3出栈形成新的TC为010X01XX,将Stack0出栈得到UID(010),将Stack1出栈得到String1(01),更改String1的信息为101存入堆栈Stack1中。目前阅读器未知的信息是TC的最后两位,则P1、P2分别为6、7。阅读器发出寻呼指令REQUEST(010,6,7)。Tag1、2响应,发送其ID的6到7位的数据给阅读器。
(6)阅读器接收到的ID为X0,ID只有一个碰撞位,读取并推出Stack0、Stack1、Stack2的顶部信息分别赋给UID(010)、String1(101)、String2(NULL),根据式(1)得出TC等于010101X0,识别Tag1、2。将Stack3出栈形成新的TC为01XX0XXX,将Stack0出栈得到UID(0),将Stack1出栈得到String1(1),更改String1的信息为11存入堆栈Stack1中。目前阅读器未知的信息是TC的最后5位,则P1、P2分别为3、7。阅读器发出寻呼指令REQUEST(0,3,7)。Tag5响应,发送其ID的3到7位的数据给阅读器。
(7)阅读器接收到的ID为10001,ID没碰撞位,读取并推出Stack0、Stack1、Stack2的顶部信息分别赋给UID(0)、String1(11)、String2(NULL),根据式(1)得出TC等于01110001,识别Tag4。将Stack3出栈形成新的TC为NULL,将Stack0出栈得到UID(NULL),将Stack1出栈得到String1(1),TC的最高位为碰撞位,将其改为1后加上出栈的1,String1的信息更改为11存入堆栈Stack1中。目前阅读器未知的信息是TC的最后6位,则P1、P2分别为2、7。阅读器发出寻呼指令REQUEST(NULL,3,7)。Tag3响应,发送其ID 的3到7位的数据给阅读器,阅读器收到信息后读取其没碰撞识别Tag3。将Stack0推出时发现其中没有元素,从而结束识别过程。
6 NBBT算法仿真及性能分析
NJDS算法相对于JDS算法主要改进的地方是标签通信量,而NBBT算法相对于NJDS算法的改进是在阅读器的通信量上。这3种算法其阅读器寻呼指令中加入了引导位,指定标签返回特定的信息。
本文利用Java开发的RFID防碰撞算法仿真平台对算法进行仿真,统计JDS、NJDS、NBBT算法的阅读器寻呼次数、阅读器通信量、标签通信量。下面对其统计的数据进行分析。
图3~图6中数据为算法不含引导位的仿真结果,其中标签长度(ID_len)为16,运行次数(Ave_run)为20。阅读器寻呼次数如图3所示,NBBT算法所需寻呼次数较少,其原因是NBBT算法中使用单个碰撞位的直接识别方法,所以寻呼次数少于NJDS算法。图4~图6分别代表阅读器通信量、标签通信量、总通信量。从图4中可发现,NJDS需要的阅读器通信量最多,NBBT算法最少,JDS所需要的阅读器通信量与NJDS算法的差值大于其与NBBT算法的差值。通信量的不同主要是由后退策略不同造成的,这表明NBBT算法的改进型后退策略性能最佳。
从图4可知,NBBT算法与NJDS算法的标签通信量数目近似相等,这说明NBBT算法继承了NJDS算法的优点。通过图4和图5可知,总通信量最少的一定是NBBT算法。图6是在不计阅读器引导位的前提下得出的总通信量,从中可以看出,JDS算法的总通信量是最多的,而NBBT算法总通信量最少,再次验证了NBBT算法中后退策略的先进性。
对于JDS、NJDS、NBBT这种阅读器寻呼指令带引导位的算法,其引导位加入的目的在于减少阅读器和标签的通信量,其减少的幅度取决于引导位在信号中的标签形式。下面对引导位处理方法进行详细分析。
将JDS阅读器寻呼指令REQUEST(UID,P)记为RQ1,NJDS算法和NBBT算法的寻呼指令REQUEST (UID,P0,P1)记为RQ2。如果单独用一个字节来存放引导位,那么相对于前面的性能数据分析,在JDS算法中阅读器一次寻呼所需要的数据量要增加一个字节,而NJDS和NBBT算法则要增加两个字节。通过增加引导位,当标签数目为1 000时进行统计数据分析,其结果如表3所示。由表3可知,如果引导位占一个字节,则NJDS算法和NBBT算法在通信量方面的改进就没有多大意义,因为引导位的数据量在总通信量中的比重过大,特别是在NJDS算法和NBBT算法中,而且JDS算法的总通信量要比NJDS、NBBT算法少。因此采取一种好的引导位处理方式对含有引导位的算法来说意义重大。
从表3中也可以可看出,NJDS和NBBT算法比JDS算法多一个引导位,而寻呼次数也相差不多,一般来说其阅读器通信量会比JDS的阅读器通信量多。然而可以通过对引导位做特殊处理减小这种差距,使算法具有更高的应用价值。
在数字通信中信息都是以二进制信息存在,阅读器寻呼指令中的引导位也一样,将引导位的十进制以二进制形式表示,其表示长度不做限制,那么可得出十进制越大二进制表现形式越长,但是对于有界的十进制可以将数据进行如下处理:
如P1∈[0,ID_len-1]且P1≥ID_len,那么--P1= ID_len-1-P1。例如P1∈[0,15],且P1=14,那么--
P1=1。对于REQUEST(UID,P0,P1)⇒REQUEST (UID, P0,--
P1);设P0=0,则REQUEST(UID,0,14)⇒REQUEST (UID,0,1ˉ);1410=11102,-110=~12(~代表信号1做了处理)。
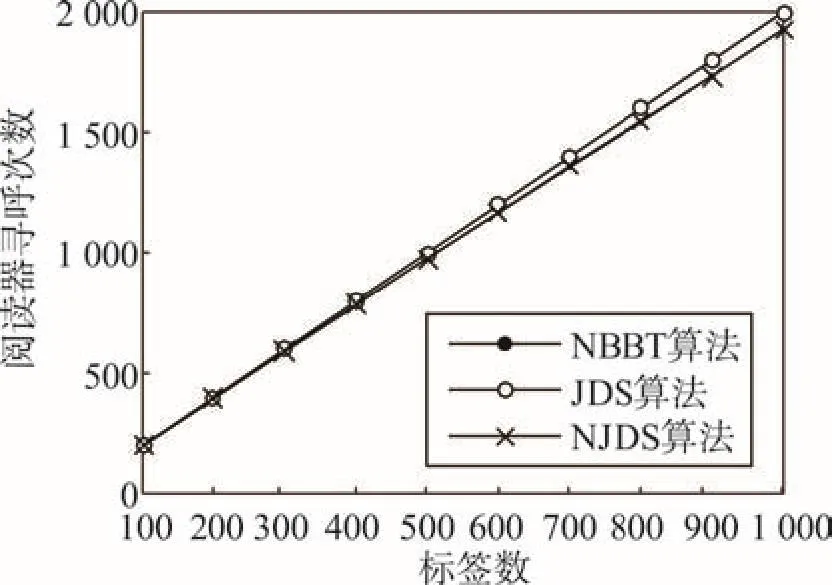
Fig.3 Comparison of paging number图3 寻呼次数比较
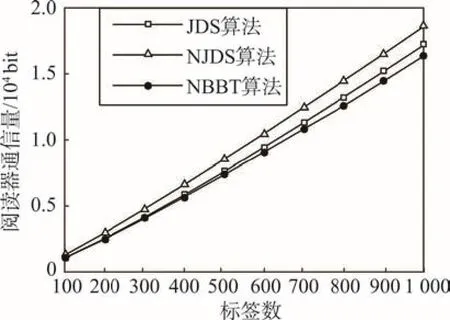
Fig.4 Comparison of reader traffic图4 阅读器通信量比较
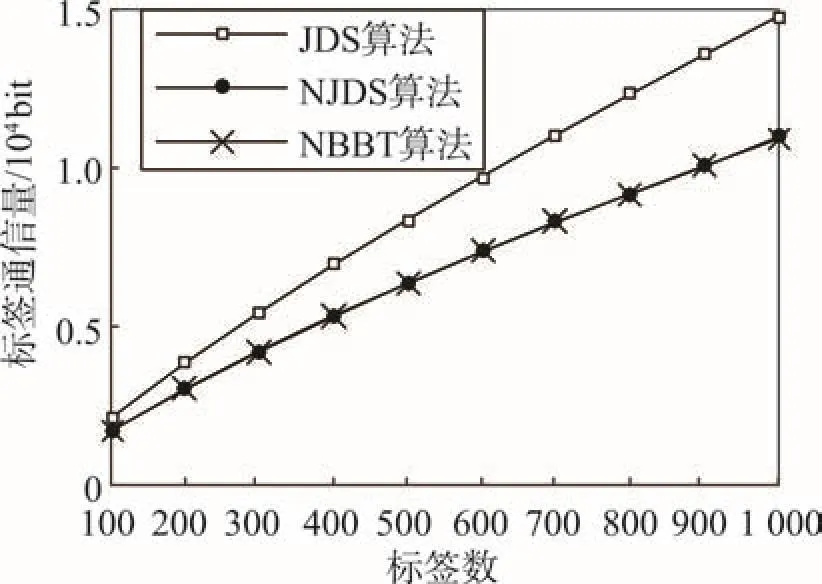
Fig.5 Comparison of tag traffic图5 标签通信量比较
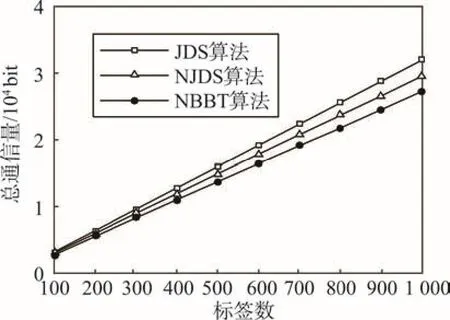
Fig.6 Comparison of total traffic图6 总通信量比较
由以上推导可知,对P1做处理后其阅读器传输信息将减少很多,在防碰撞算法仿真软件中运行采用这种处理方式的JDS、NJDS、NBBT算法,统计出通信量的结果如图7~图9所示(Y-代表有引导位的算法)。
从图8中可以看出,引导位的添加对标签通信量没有影响。因为标签的返回指令没有变化,与没加入引导位时的通信数量相同。从图7中可知,引导位对算法阅读器通信量的影响随着标签数目的增加逐渐增大,但对加入引导位时3种算法的阅读器通信量大小排序影响不大,NBBT算法的通信量与JDS算法相当,与NJDS算法的通信量差距随着标签增加而加大。这说明引导位对NBBT算法通信量的影响小于对NJDS算法的影响。
对比表3中标签数目为1 000时的实验结果可知,将引导位进行数据处理后可急剧减少引导位对算法通信量的影响。综合图7~图9可得出,在NBBT算法中加入引导量统计后,其阅读器通信量与JDS算法近似,标签通信量与NJDS算法近似,总通信量最少。
一个算法效率高低的直接指标为算法复杂度,算法复杂度又分为时间复杂度和空间复杂度[16]。在二叉树防碰撞算法中,时间复杂度主要由阅读器寻呼次数所控制,如式(2)所示。其中n为算法的执行次数,f(n)为某个算法,T(n)为时间复杂度。空间复杂度由二叉树防碰撞算法阅读器与标签之间的总通信量决定,如式(3)所示。其中c为总通信量,f (c)为某个算法所需的存储空间,S(c)为算法的空间复杂度。结合图2和式(2)可知,NBBT算法的时间复杂度是最小的。结合图5、图8和式(3)可知,NBBT算法的空间复杂度也最小。
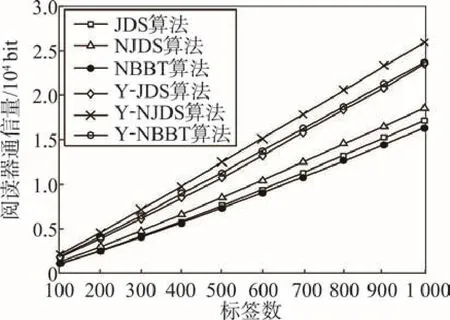
Fig.7 Comparison of reader traffic w ith guiding bit图7 具有引导位的阅读器通信量比较
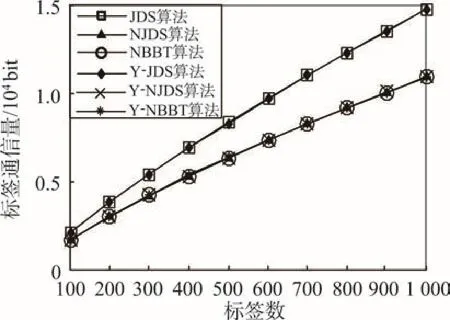
Fig.8 Comparison of tag traffic w ith guiding bit图8 具有引导位的标签通信量比较
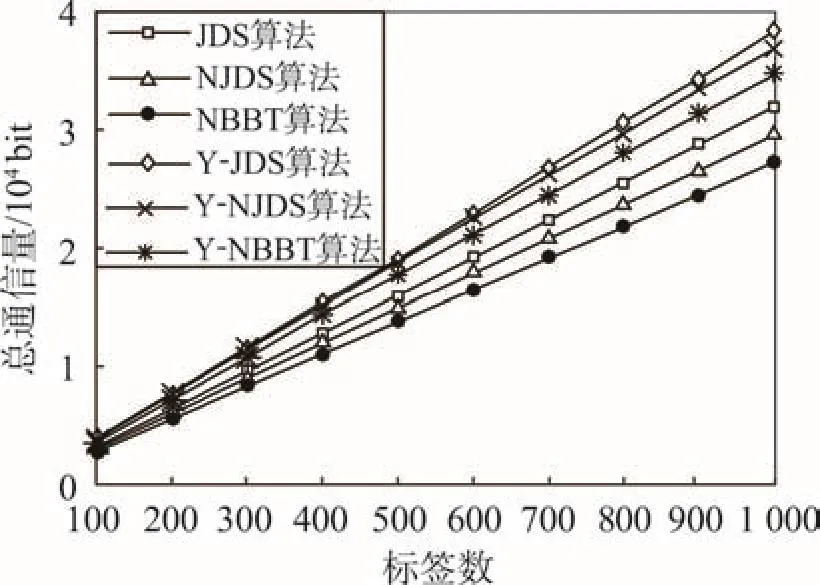
Fig.9 Comparison of total traffic w ith guiding bit图9 具有引导位的总通信量比较

Table 3 Analysis of guiding bit表3引导位分析

7 结束语
本文提出了一种改进的后退式二叉树防碰撞算法,并阐述了算法的后退策略和基本思想,给出了算法的流程图,对算法的识别过程进行了详细的说明,最后利用开发的防碰撞算法仿真软件比较分析了3种算法在阅读器通信量、标签通信量以及总通信量上的特点,同时分析了引导位对3种通信量的影响。总之,本文算法可以明显减少RFID系统的通信量,从而达到减少传输时延的目的。
References:
[1] Ning Huansheng. RFID national major projects and national Internet of things[M]. Beijing: China Machine Press, 2012: 7-20.
[2] Wang Gang. M inistry of industry and information issued the“Internet of things development planning”[J]. Internet of Things Technology, 2012, 2(3): 13-18.
[3] E-Batouty A S, Farag H H, E-Badaw y E-S. A new proposed anti-collision algorithm for RFID[C]//Proceedings of the 30th National Radio Science Conference, Cairo, Egypt, Apr 16-18, 2013. Piscataway, USA: IEEE, 2013: 15-17.
[4] Kim S C, Cho J S, Kim S K. Performance improvement of hybrid tag anti-collision protocol for radio frequency identification systems[J]. International Journal of Communication Systems, 2013, 26(6): 705-719.
[5] Kim S H, Park P G. An efficient tree-based tag anti-collision protocol for RFID systems[J]. IEEE Communications Letters, 2007, 11(5): 449-451.
[6] Lai Y C, Hsiao L Y. General binary tree protocol for coping w ith the capture effect in RFID tag identification[J]. IEEE Communications Letters, 2010, 14(3): 208-210.
[7] Cui Yinghua, Zhao Yuping. Performance evaluation of a multibranch tree algorithm in RFID[J]. IEEE Transactions on Communications, 2010, 58(5): 1356-1364.
[8] Kim S, Kim Y,Ahn K.An enhanced slotted binary tree algorithm w ith intelligent separation in RFID systems[C]//Proceedings of the 2009 IEEE Symposium on Computer and Communications, Sousse, Tunisia, Jul 5-8, 2009. Piscataway, USA: IEEE, 2009: 237-242.
[9] Wu Haifeng, Zeng Yu, Feng Jihua, et al. Binary tree slotted ALOHA for passive RFID tag anti-collision[J]. IEEE Transactions on Parallel and Distributed Systems, 2013, 24(1): 19-31.
[10] Lai Y C, Hsiao L Y. General binary tree protocol for coping w ith the capture effect in RFID tag identification[J]. IEEE Communications Letters, 2010, 14(3): 208-210.
[11] Choi J H, Lee D, Lee H. Query tree-based reservation for efficient RFID tag anti-collision[J]. IEEE Communications Letters, 2007, 11(1): 85-87.
[12] Yang C N, He J Y. An effective 16-bit random number aided query tree algorithm for RFID tag anti-collision[J]. IEEE Communications Letters, 2011, 15(5): 539-541.
[13] Jia Xiaolin, Feng Quanyuan, Yu Lishan. Stability analysis of efficient anti-collision protocol for RFID tag identification[J]. IEEE Transactions on Communications, 2012, 60 (8): 2285-2294.
[14] Wang Xin, Jia Qingxuan, Gao Xin. Effective RFID anti-collision algorithm based on 3-ary collision-track tree[J]. Journal of Huazhong University of Science and Technology: Nature Science Edition, 2014, 42(6): 73-78.
[15] Sun Yaolei, Wu Xiaobo, Chen Yuanwen. Improved quadtree RFID anti-collision algorithm[J]. Computer Engineering and Applications, 2014, 50(4): 63-68.
[16] Yan Weim in, Wu Weim in. Data structure[M]. Beijing: Tsinghua University Press, 2007: 13-17.
附中文参考文献:
[1]宁焕生. RFID国家重大工程与国家物联网[M].北京:机械工业出版社, 2012: 7-20.
[2]王刚.工信部发布《物联网“十二五”发展规划》[J].物联网技术, 2012, 2(3): 13-18.
[14]王鑫,贾庆轩,高欣.基于三叉碰撞跟踪树的高效RFID防碰撞算法[J].华中科技大学学报:自然科学版, 2014, 42 (6): 73-78.
[15]孙耀磊,吴晓波,陈元文.一种改进的四叉树RFID防碰撞算法[J].计算机工程与应用, 2014, 50(4): 63-68.
[16]严蔚敏,吴伟民.数据结构[M].北京:清华大学出版社, 2007: 13-17.

TANG Zhijun was born in 1974. He is an associate professor and M.S. supervisor at Hunan University of Science and Technology, and the member of CCF. His research interests include RFID technology, Internet of Things technology and UWB antenna, etc.
唐志军(1974—),男,湖南邵阳人,湖南科技大学副教授、硕士生导师,CCF会员,主要研究领域为RFID技术,物联网技术,超宽带天线等。

YANG Yi was born in 1990. He is an M.S. candidate at Hunan University of Science and Technology. His research interests include RFID anti-collision technology and communication system modeling, etc.
阳懿(1990—),男,湖南长沙人,湖南科技大学硕士研究生,主要研究领域为RFID防碰撞技术,通信系统建模等。

WU Xiaofeng was born in 1974. He is an associate professor and M.S. supervisor at Hunan University of Science and Technology, and the member of CCF. His research interest is the design and optim ization of high power m icrowave power amplifiers.
吴笑峰(1974—),男,湖南涟源人,湖南科技大学副教授、硕士生导师,CCF会员,主要研究领域为高功率微波功率放大器设计及优化等。

XI Zaifang was born in 1974. He received the M.S. degree from Hunan University in 2003. Now he is an associate professor and M.S. supervisor at Hunan University of Science and Technology. His research interests include signal processing and communication system, etc.
席在芳(1974—),男,湖南常德人,2003年于湖南大学获得硕士学位,现为湖南科技大学副教授、硕士生导师,主要研究领域为信号处理,现代通信系统等。

HU Shigang was born in 1980. He received the Ph.D. degree in microelectronics from Xidian University in 2009. Now he is an associate professor and M.S. supervisor at Hunan University of Science and Technology. His research interests include analog integrated circuit design and sem iconductor devices, etc.
胡仕刚(1980—),男,湖北咸宁人,2009年于西安电子科技大学获得博士学位,现为湖南科技大学副教授、硕士生导师,主要研究领域为模拟集成电路设计,半导体器件等。
Novel Back-off Binary TreeAnti-collision Algorithm for Ultra High Frequency RFIDƽ
TANG Zhijun+, YANG Yi, WU Xiaofeng, XI Zaifang, HU Shigang
College of Information & Electrical Engineering, Hunan University of Science and Technology, Xiangtan, Hunan 411201, China
+ Corresponding author: E-mail: zjtang@hnust.edu.cn
Key words:radio frequency identification (RFID); binary tree anti-collision algorithm; back-off paging; guiding bit
Abstract:Aiming at some problems of existing binary tree anti-collision algorithms in ultra high frequency radio frequency identification (RFID) systems, such as larger communication traffic and higher transmission delay, this paper proposes a novel back-off binary tree (NBBT) anti-collision algorithm by combining the jumping dynam ic search (JDS) and the novel JDS (NJDS) anti-collision algorithms, and introducing a back-off paging strategy. The proposed algorithm adds a guiding bit to the readerƳs paging instruction in order that the tag can respond to the reader quickly. As a result, the proposed algorithm can reduce total communication traffic and the transm ission delay. Compared w ith the existing JDS or NJDS algorithms, the simulated results show that the proposed algorithm is more efficient in transmission delay and communication traffic. Furthermore, the algorithm can significantly improve the communication rate between the reader and the tag.
doi:10.3778/j.issn.1673-9418.1507073
文献标志码:A
中图分类号:TN926;TN915
