IEEE802.11a基带系统中高速Viterbi译码器的FPGA实现
2016-06-03钟东波刘玥谢宇飞
钟东波 刘玥 谢宇飞
【摘要】 提出了一种应用于IEEE802.11a协议系统的高速Viterbi译码器的新结构,以一种改进的归一化管理高效的解决了PMU单元的数据溢出问题、采用一种分块循环回溯算法以减少延时,并用Verilog语言具体实现。实验表明在该译码器以较少的资源实现了较高的速度,完全满足IEEE802.11a的协议标准,具有很高的实用价值。
【关键词】 FPGA 软判决 加比选单元 归一化处理 回溯算法
一、引言
伴随着无线数据传输与多媒体应用的不断发展,无线传输系统对传输速率与传输质量保证等方面的要求也相应的不断提高。IEEE802.11a是基于OFDM技术的高速无线局域网技术标准。
文章提出了一种应用于IEEE802.11a系统的高速Viterbi译码器新的结构,实践表明该译码器以较少的资源实现了较高的数据吞吐量,具有较高的实用价值。
二、Viterbi 译码器的基本系统结构
在IEEE802.11a标准中采用(2,1,6)卷积码,生成多项式为G(x)=(1+x1+x2+x3+x6 ,1+x2+x3+x6+x5),表示为八进制为G=(171,133)8,,其Viterbi译码器的基本结构如图1所示,包括增信单元(depuncture),分支度量单元(BMU),累计路径度量单元(PMU),加比选单元(ACSU),幸存路径管理单元(SMU)和译码控制单元。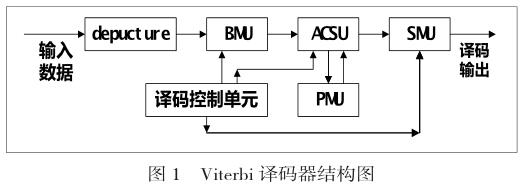
三、改进的Viterbi译码器的电路结构
3.1 BUM单元的设计
分支度量单元(BUM)用于计算接收码元符号和期望码元符号之间的距离。软判决相比硬判决,可以多获得2dB~3dB的增益。当量化电平数Q>8时获得的增益变化很小,因此本设计采用3bit量化。
3.2 归一化处理
传统设计中的归一化方法,无论是减数法,还是移位法均需要设置一个路径度量门限,每次的路径度量值均要和判决门限进行比较,再根据判决结果决定是否进行归一化处理。假设每次和判决门限比较的延时为x,则到达一次译码深度的延时为36x,显然对ACS单元的高速性是不利的。文献[2] 已经证明了每一时刻路径度量的最大值和最小值满足:PMmax - PMmin≤ (m - 1) (BMmax - BMmin ) 。
在本设计中,m = 7, BMmax=14, BMmin=0,最大的路径量度和最小的路径量度之间的最大差值为84,需要用 7 bit来表示路径量度值[3],所以在开始的第一个在约束长度内,任一状态的路径度量值均不会溢出,那么便可设置一个模36计数器,分别在6的倍数时进行归一化判决,这样在译码深度之内判决延时就变为原来的1/6,大大减少了延时,提高了运算速度,且只需要利用控制译码深度的计数器即可,并不需要单独设置计数器。
把64个状态度量的最高位相与作为归一化判决标志,当64个状态路径度量值最高位均为1时,由于动态度量值动态范围的限制,所有路径度量值均没有溢出,便把所有的路径度量值右移2位。这样既防止了溢出,也没有破坏度量值之间的差别。
而利用译码深度计数器控制归一化判决的次数,只是增加了一个多路选择器,硬件开销极小,有效的减小了延时;由于判决比较次数减少,相应的归一化次数也就减少,功耗也比传统方案有所降低。
3.3改进的回溯算法
本次设计采用回法,回溯深度为36,采用了一种分块循环回溯算法,以减小延时提高速度。
由于对幸存路径的读写不是同时启止的,故设置三块大小为128×36的RAM(每块由两块64×36单元组成),即每块RAM可以存放两个回溯深度的幸存路径,每块RAM在同一时刻分别完成数据写入、路径回溯、译码输出的功能。译码开始时间,向第一块RAM写数据,当达到译码深度时,开始回溯读数据,由于回溯需要延时36个时钟周期,输出数据时可以每次从RAM中读取两个时刻的数据。当回溯完毕准备输出第一个译码信息时,第一块RAM的数据中两个译码深度的数据正好被读完。
由于开始回溯和译码存在36个译码深度的时间差,故还需要一块RAM作为数据缓存。回溯操作和输出基本一致,其结构如图2所示,回溯时每次读出两个时刻的幸存路径值,分别写入一块RAM中两个64b寄存器,并由多路选择器,每次选择两位幸存路径完成对状态寄存器的更新。这样和输出RAM构成流水,不断输出译码信息。当然还需设置一个RAM片选控制信号,用于指示哪块RAM处于工作状态,并通过译码深度控制信号,控制三块RAM轮流处于不同的工作状态。
通过RAM的轮流的读写操作,减小了延时。当达到译码深度时,可以马上进行回溯,整个回溯模块延时仅为译码深度,即36。相对与传统的单译码向量回溯算法,译码输出速率提高了一倍。
虽然有33%存储空间的闲置,并且需要增加一些额外控制信号,但是这样的资源消耗是极其有限的。
四、硬件的仿真与综合
该译码器采用Verilog语言编写,使用QuartusII9.0软件进行综合,布线,并在Altera公司的Cyclone EP2C35F672C6型FPGA上完成了板级验证。
4.1 资源及速度评估
表1是与几种具有代表性的高速译码器的性能比较。
对比结果分析:
A、文献[7]采用的是4比特量化数为优于本文,但是该文回溯深度为36优于文献[7],从实际应用上讲二者的误比特率基本相当。本设计的数据吞吐量为文献[7]的70%左右,但是其LE消耗仅为文献[10]的21%左右,在数据吞吐率下降有限的情况下,极大地减少了硬件开销。
B、文献[8]采用的是RE算法,速度较高,其最高数据吞吐量为231Mbit/s,在同样的芯片型号下该文的数据吞吐量虽然为文献[8]的70%,但是其资源开销仅为前者的50%左右,由于该文采用的是三块ram轮流工作的算法,存储资源消耗大于文献[8],但是FPGA的存储比特都在百万bit以上,(使用芯片的存储比特数超过了700bit),这样的增加的硬件开销只占资源总数的0.6%左右,几乎可以忽略不计。
C、文献[9]工作频率仅为80MHz,虽然采用基四算法使其数据吞吐率达到了160Mbit/s,但是消耗了大量的硬件资源,本文设计的数据吞吐量为文献[12]的72%左右,但是其资源消耗仅为其的18.4%,极大地减少了硬件开销。
综上所述,该文提出的Viterbi译码器,在仅消耗传统设计的20%~50%左右的逻辑资源,却达到了传统设计约70%数据吞吐量。
五、结论
设计的Viterbi译码器采用全并行和流水线结构以提高速度,采用矢量差的“1范数”代替欧氏距离作为判决距离以减小硬件开销,以一种改进移位寄存方法高效的解决了数据溢出问题,采用改进的TB(回溯)算法以减少延时,经仿真和硬件实现表明,该译码器以较少的资源实现了较高的数据吞吐量,充分满足了IEEE802.11a的技术标准,具有较高的实用价值。
参 考 文 献
[1]IEEE Std 802.11a-1999 Patat 11: wireless LAN Medium Access Control (MAC)and physical Layer (PHY) Specifications[s].Sponsor :LAN/MAN Standards Committee of IEEE Computer Society ;Approved by IEEE–SA Standards Board.1999.
[2]Ungerboeck, H K Thapar . VLSI Architectures for Metric Normalization in the Viterbi Algorithm[ C ] / / . IEEE International Conference on (vol . 3) . 1999: 1497 - 1500.
[3]张健,刘小林,匡镜明,王 华.高速 Viterbi译码器的FPGA实现[J].电讯技术2006,(3):37-41
[4]刘晓莹,王一,王新安.应用于无线局域网的高速维特比译码器电路[J]计算机技术与发展,2008,(1):11-14.
[5]Ishitani T. A Scarce-state-transition Viterbi-decoder VLSI for Bit Error Correction [J]. IEEE J. Solid-state Circuits, 1987, 22(4): 575-582.)
[6]I Kang , A N Willson1 A low2power state2sequential Viterbi de2coder for CDMA digital cellular applications1 ISCAS96 , New York : IEEE Press , 19961 272~275.
[7]金文学,刘秉坤,陈 岚. 低功耗软判决维特比译码器的设计[J]. 计算机工程,2007,(5):243—245
[8]李 刚,黑 勇,乔树山,仇玉林. 一种高速 Viterbi译码器的设计与实现[J].电子器件,2007,(5):1186—1189
[9]丁 锐,杨知行,潘长勇. 高速维特比译码器的设计[J].电讯技术,2004,(4):51—54. G
