一种基于非监控学习的数据清洗算法
2016-06-02李景民吉林工商学院长春130062
李景民(吉林工商学院,长春130062)
一种基于非监控学习的数据清洗算法
李景民
(吉林工商学院,长春130062)
摘要:在数据库的应用中经常会出现数据的“相似重复记录”问题,笔者提出一种基于非监控学习的数据清洗算法。这种算法主要采用了基于非监控学习的方法,在学习过程中能够结合需要增添新的聚类,去除错误聚类,进而能够避免出现死神经元问题,经实验数据证明可以有效地实体识别。
关键词:非监控学习;数据清洗;数据库;数据转换
在现代高等院校科研系统信息化的建设过程中,管理人员发现存在数量庞大的异构系统、海量的资源。面对如此多的不同来源、较为分散和清洁度不够的信息,科研系统管理人员需要提炼有效信息,以供决策,因而急需信息集成和整合的行之有效的方法。创建数据仓库的主要目标是提供准确的数据,为数据分析服务,为科研领导的决策提供参考。为了能够对正确决策提供足够的支持,需要依据的参考数据应该是可靠的,没有偏差的,以体现科研的实际情况[1,2]。鉴于以上的环境及需求,ETL技术作为一种工具和手段蓬勃发展起来。ETL主要是指数据抽取、转换、清洗、加载的过程。ETL是建立数据仓库非常重要的一个步骤,管理员从数据源中提炼出需要的数据,经过数据转换及数据清洗过程,最后根据事先确定好的数据仓库模型,把数据最终加载到数据仓库中去。
在科研管理系统当中,由于数据仓库中的数据可能来源于多种不同的数据源,该数据源又可能存在于差异的硬件平台上,数据库管理系统也千差万别,这就导致这些数据在很多方面都是不同的,甚至是相互冲突的,所以控制数据质量成为极为重要的问题。
1 ETL技术中的数据质量控制方法
1.1数据质量问题的类别
在科研管理系统中进行数据ETL过程时,管理者有可能碰到形形色色的数据质量问题,有必要将它们进行分类管理。通过总结该问题的产生究竟是在模式层还是在实例层,进而把数据质量问题进一步划分成四大类:A.单数据源模式层问题。B.单数据源实例层问题。C.多数据源模式层问题。D.多数据源实例层问题。
如果在模式层次上存在问题,那么在实例层次上会有相应的体现,不好的数据模式设计、定义的完整性约束缺乏、多个数据源之间命名冲突以及结构冲突等,全部都是这类问题。人们可以采用改进模式设计、模式转化和模式集成的方法解决模式层次上的问题。目前主流的方法是通过相关问题域的专家,采用手工方法来处理此类问题,但是效率低下。
1.2数据质量评估方法
在高校科研系统中,需要解决不同数据质量的异常问题,首要任务是分析产生异常的根源。导致数据异常的因素较多,可能是系统自身的原因,也可能是历史因素[3]:在不同阶段,系统的数据模型可能存在差异;相应的处理过程有所区别;新旧几套系统模块处理财务、人事等有关信息时有所区别;老旧系统与新增业务以及管理系统数据在进行集成时的不完备也会产生差异;源系统在数据输入时没有对数据进行数据验证,无法拦截不合格的数据输入到系统。分析数据质量应该从以上几个方面进行考量,评估采集到的具体数据源,衡量数据源的质量,进而确定采用的ETL规则。
2 基于非监控学习的数据清洗策略
2.1数据清洗
所谓数据清洗就是在检测数据集中过程之后出现的错误和差异,并通过人工或者自动化工具将其删除和修正,进而提升数据质量。
在对实例层次的数据进行清洗的过程中,即使通过模式转化和集成取得了一致模式,在实例层上依旧需要对不一致性进行清除,关键是对缺损属性修正,并进行相应的实体识别。处理缺损属性时,主要是针对不确定信息的理论,对于不完全数据,需要进行推理和相应的研究,并且提出合适的规则。在实体识别时,对于相同的实体,在不同的数据源的记录中,有可能标识的主键是不同的,这些信息在内容上互为补充,可能存在冗余情况,严重时甚至会有互相矛盾的情况。
针对相似重复记录的处理方式,笔者采用了非监控的学习方法,以此来处理数据集中过程中的实体识别困难。非监控学习是针对海量的、未标记的数据分析的聚类技术。主要目的是提供一系列类,而且要求相同类中数据的特性要保持一致,类别不同的数据要有明显的、便于区分的差异。
2.2非监控学习算法
这种学习方法主要包括竞争学习和增强式学习两种方法。笔者在实体识别中总结出采用基于Hebbian假设的一种非监控的学习算法。
由Hebbian的假设,神经元的学习规则能够用如下的函数进行表示:
表达式中的W为突触权值向量,X表示输入样本向量,ψ()是可微函数,α≥0是遗忘系数。神经元的输出为:
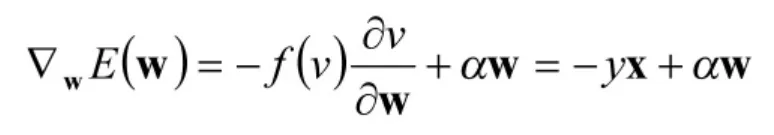
2.3非监控学习算法性能测试
在对非监控学习算法性能进行测试的过程中,设计了两组数据。其中一组是系数σ=0.05服从高斯分布的测试数据,另外一组是系数σ=0.5测试数据。结果是σ=0.05,数据相对集中,聚类边界明显;σ=0.5,数据不集中,聚类边界不够清晰。
因为从多数据源当中直接进行对象识别具有非常大的困难,所以我们可以把整个识别过程分成不同的阶段来完成。
3 结论
在进行数据清洗操作中,利用非监控学习算法处理在实体识别方面的问题,完成“相似重复记录”的查询,可以进一步提高清洗的准确程度。
参考文献:
[1]Wand Y,Anchoring Wang R Y.Data Quality Dimensions In Ontological Foundations[J].Commun ACM39,1996,(11):86- 95.
[2]Strong Diane M,Lee Yang W,Wang Richard Y.Data Quality In Context[J].Commun ACM40,1997,(05):103- 110.
[3]郭志懋,周傲英(Guo Z.M., Zhou A.Y.).数据质量和数据清洗研究综述(Research on Data Quality and Data Cleaning:a Survey)[J]软件学报(Journal of Software),2002,13(11):2076- 2082.
中图分类号:TP311.13
文献标志码:A
文章编号:1674- 8646(2016)02- 0044- 02
收稿日期:2015- 12- 19
