基于CUDA的拉普拉斯金字塔的优化*
2016-06-02邵靖凯厉旭杰温州大学物理与电子信息工程学院浙江温州325035
邵靖凯,厉旭杰(温州大学物理与电子信息工程学院,浙江温州325035)
基于CUDA的拉普拉斯金字塔的优化*
邵靖凯,厉旭杰
(温州大学物理与电子信息工程学院,浙江温州325035)
摘 要:提出了基于CUDA的并行拉普拉斯金字塔算法。算法采用的并行拉普拉斯算法很好地解决了共享存储器的bank冲突和全局存储器的合并访问的问题,为了最大化并行效率,计算了SM占用率,并通过公式进行了论证。在GTX480平台下,基于CUDA的并行拉普拉斯金字塔算法获得了几十倍的加速比。最后,将基于CUDA的并行拉普拉斯金字塔算法成功地应用于图像融合和增强图片的细节处理,充分证明了并行拉普拉斯金字塔算法广泛的有效性和必要性。
关键词:CUDA;拉普拉斯金字塔;GPU;并行计算
0 引言
拉普拉斯金字塔算法可以进行多尺度的图像分解,广泛应用于图像分析[1-2]。PARIS S等人[3]用拉普拉斯金字塔算法实现了边缘突出的图像处理,但是算法的效率很低。因此又提出限制拉普拉斯分解的层数的算法,从而提高图像处理的速度,但是图像处理的效果有所下降。虽然拉普拉斯金字塔分解本身算法复杂度不高,但是因为应用中通常需要进行很多层的拉普拉斯分解和重构,使得整个过程需要消耗大量的时间。因此提高拉普拉斯金字塔算法的速度显得非常重要。祁艳杰[4]实现了基于FPGA的实时拉普拉斯金字塔。
本文研究了基于CUDA的拉普拉斯金字塔算法的实现。本算法采用并行拉普拉斯算法很好地解决了共享存储器的bank冲突和全局存储器的合并访问的问题,而且最大化了并行效率,从而使性能得到了很大的提高。
1 图像金字塔
1.1高斯金字塔的构建过程
设原图像为G0,高斯金字塔的第L层的构造方法如下:先将L -1层图像GL-1和窗口函数w(m,n)进行卷积,结果做隔行隔列的降采样,即

其中,(i,j)为像素索引,w(m,n)是5×5高斯核:
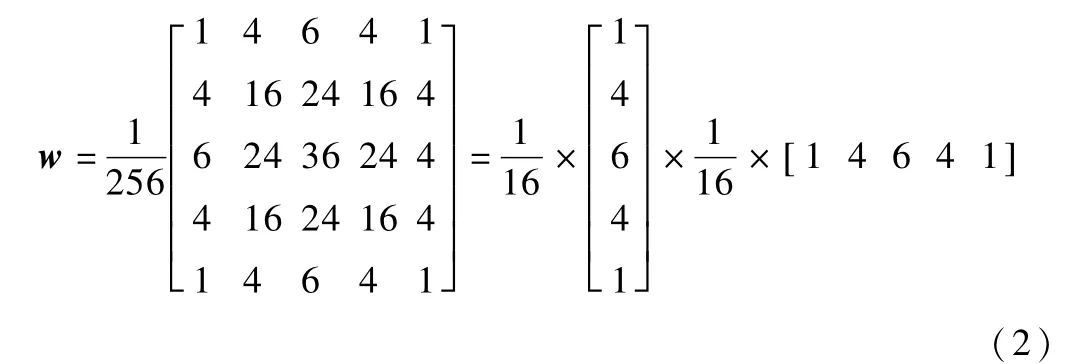
计算G0,G1,…,GN就构成了高斯金字塔。
1.2拉普拉斯金字塔的构建过程
将GL内插放大,得到放大图像的尺寸与GL -1的尺寸相同:
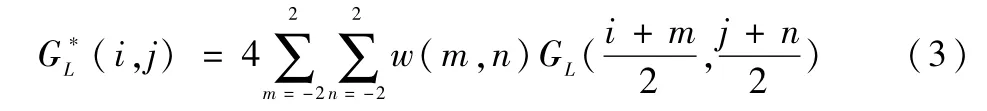

2 基于CUDA的拉普拉斯金字塔的并行化实现
本文主要介绍基于CUDA的可分离高斯滤波器的实现。

从公式(5)中可以看出,高斯滤波器很适合在GPU上进行高效的并行计算。公式(2)说明,采用可分离滤波器可以分解成两个一维高斯滤波器,可以使计算更加简单。
从图1中可以看出,基于CUDA的拉普金字塔首先采用高斯卷积,然后下采样得到高斯金字塔,高斯金字塔经过上采样,并经过高斯卷积得到拉普拉斯金字塔。

图1 拉普拉斯金字塔构建过程
对于图像的卷积,通常的方法是将图像的像素传输到globalmemory,然后每个thread负责计算一个像素的卷积结果。然而这种方法需要大量访问全局寄存器,导致性能下降,甚至运行的速度会比在CPU上的性能还要差。共享存储器位于GPU片内,速度比表1所示使用CUDA profiler测试程序基于CUDA的可分离高斯金字塔local/global memory快得多。在不发生bank conflict的情况下,share memory的延迟几乎只有local或global memory的1/100,访问速度与寄存器相当,是实现线程间通信延迟最小的方法。

表1 使用CUDA测试程序基于CUDA的可分离高斯金字塔
为了减少空闲的线程和充分利用共享存储器,本设计让每个thread负责将多个全局寄存器数据传输到共享存储器,负责多个像素的卷积,block尺寸为16×8,每个thread负责传输(2 +8)个全局存储器到共享存储器,同时负责8个像素的卷积计算。设置Apron的宽度为16的倍数,以便在存取全局存储器时符合合并访问的条件。计算16×8×4像素的卷积,只需要用16×10×4的共享存储器,有效利用了共享存储器。
表1显示了使用CUDA profiler测试程序基于CUDA的可分离高斯金字塔,其中行可分离高斯金字塔,每个线程用了11个寄存器,每个block使用了5 120 B的共享存储器。而每个SM最多可激活8个block,通过下面的公式可以计算得到寄存器和共享存储器的使用率。
块内总束数量Wblock如下[5]:

其中,T是块内线程数,Wsize是束尺寸,ceil(x,y)等于x向上取到y的整数倍。
分给一个块的总寄存器数量Rblock如下:
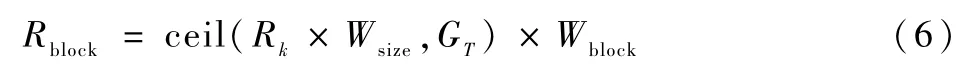
Rk是内核使用的寄存器数,GT是线程分配的粒度。
块内总共享存储器数量Sblock如下:

其中,Sk是内核使用的共享存储器总量,以字节为单位,GS是共享存储器分配的粒度。
通过公式(5)~(7)可以计算得到寄存器和共享存储器的使用率,为了选取合适的block大小,提高SM占用率,通过CUDA GPU Occupancy Calculator来选择block的大小,从图2中可以看出,选取block大小为16×8×1可以使SM占用率提高到0.667,这个结果与用CUDA profiler测试的结果和公式(5)~(7)计算的结果是一致的。如果继续增加block的大小,从表1或者公式(5)~(7)都很容易得到,因为共享存储器容量的限制,SM占用率不会因为block大小的增加而增加,而选择block大小为16×4 ×1,SM占用率为0.33。因此在GTX480上,选取Block大小为16×8×1是最合适的。

表2 基于CUDA的拉普拉斯金字塔(5×5高斯核)
3 实验结果
3.1性能测试
表2显示了基于CUDA的拉普拉斯金字塔性能的测试结果。结果显示提出的算法获得了几十倍的加速比。基于CUDA的拉普拉斯金字塔采用可分离卷积滤波核,很好地解决了利用了共享存储器和全局存储器的合并访问的要求。

图2 使用CUDA GPU Occupancy Calculator计算block大小、寄存器大小和共享存储器的使用对SM占用率的影响
3.2拉普拉斯金字塔的应用
(1)基于拉普拉斯金字塔的融合

图3 金字塔变换后区域特征量测所得图像(3层拉普拉斯金字塔分解)
采用基于区域特征量测的拉普拉斯金字塔分解的图像融合算法,图3显示了金字塔变换后区域特征量测所得图像(3层拉普拉斯金字塔分解)。当层数较低时,如分解层数小于5层,分解层数越大,融合图像的分辨率越高,图像越清晰;当层数大于5层时,增加层数对于改善分辨率的影响减小,但增大了计算量。而基于CUDA的拉普拉斯金字塔由于性能上有较大的提高,可以支持层数大于5层的实时图像融合。因此基于CUDA的拉普拉斯金字塔特别适合对图像融合效果要求高而需要进行很多层拉普拉斯金字塔分解的实时图像融合。
(2)基于拉普拉斯金字塔的增强图片的细节处理,PARIS S等人[4]用拉普拉斯金字塔算法在处理图像平滑、图像细节控制、色调映射等领域表现出了很好的特性,不足之处是每处理一万个像素需要近1 min时间,图4显示了图像边缘保持的细节提高,在图6中图像尺寸为300× 200的情况下,需要进行8次拉普拉斯分解和重构,整个程序需要耗时3 min。而基于CUDA的拉普拉斯金字塔算法在GTX480平台下获得了几十倍的加速比。

图4 图像边缘保持的细节提高
4 结语
本文提出了基于CUDA的并行拉普拉斯金字塔算法,二维高斯滤波被分解成可分离的两个一维卷积操作。提出的基于CUDA的拉普拉斯金字塔算法在GTX480平台下获得了几十倍的加速比。
参考文献
[1]赵健,高军,罗超,等.基于数字图像处理的玻璃缺陷在线检测系统[J].电子技术应用,2013,39(12):90-92.
[2]李波,梁攀,关沫.一种基于边缘提取的交互式图像分割算法[J].微型机与应用,2013,32(10):41-47.
[3]PARIS S,HASINOFF S,KAUTZ J.Local Laplacian filters:edgeaware image processing with a Laplacian pyramid[J].ACM Transactions on Graphics,2011,30(4):1244-1259.
[4]祁艳杰.LOG算子在FPGA中的实现[J].电子技术应用,2007,33(3):63-65.
[5]NVIDIA.NVIDIA CUDA programming guide 4.0[EB/OL]. (2011-3-2)[2016-03-29]http://developer.nvidia.com/cudatoolkit-40.
邵靖凯(1998 -),男,本科,主要研究方向:图形图像处理技术、高性能并行计算。
厉旭杰(1981 -),男,通信作者,讲师,CCF高级会员,主要研究方向:图形图像处理技术,高性能并行计算。E-mail:lixujie101@aliyun.com。
引用格式:邵靖凯,厉旭杰.基于CUDA的拉普拉斯金字塔的优化[J].微型机与应用,2016,35(10):40-42.
Optimizations on Laplacian pyramid based on CUDA
Shao Jingkai,Li Xujie
(College of Physics&Electronic Information Engineering,Wenzhou University,Wenzhou 325035,China)
Abstract:This paper presents a parallel Laplacian pyramid algorithm using CUDA.The parallel Laplacian pyramid algorithm using CUDA is a good match to the banked structure of shared memory and the coalescing requirement for high devicememory throughput.The occupancy analysis for kernel is calculated and measured tomaximize utilization.W ith a programmable NVIDIA GTX 480 GPU,the GPU-accelerated Laplacian pyramid algorithm performs dozens of times of speedup.The effective image fusion and the detailmanipulation further demonstrate the feasibility and necessity of the parallel Laplacian pyramid algorithm.
Key words:CUDA;Laplacian pyramid;GPU;parallel computing
作者简介:
收稿日期:(2016-01-18)
*基金项目:温州大学大学生创新创业训练计划项目(DC2015037);浙江省自然科学基金(LQ14F020006)
中图分类号:TP301.6
文献标识码:A
DOI:10.19358 /j.issn.1674-7720.2016.09.014
