模拟退火结合Logistic算法在分类中的应用
2016-05-30陈芝
陈芝
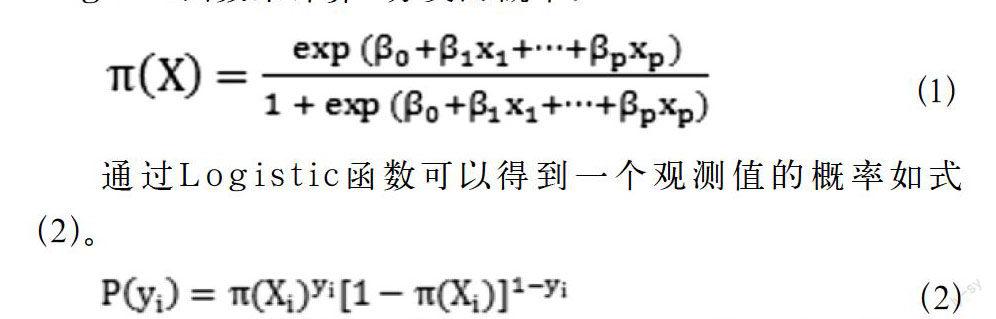


摘 要:Logistic线性回归算法是一种简单而高效的二分类器,它能够针对每个参数生成对应的分类系数,最后结合系数计算出所在类别的概率;同时模拟退火算法是一种较好的全局寻优算法。在门店分类中考虑到各个参数的不同权重,因此使用模拟退火算法来寻找适当的参数权重以期望得到最好Logistic分类结果。最后通过实验来验证算法的准确率。
关键词:Logistic线性回归 模拟退火 门店分类
中图分类号:TP301.6 文献标识码:A 文章编号:1674-098X(2016)06(b)-0092-02
分类算法属于预测式数据挖掘的一种数据分析方法,其目的是根据重要样本数据集找出能准确描述并区分数据类或概念的模型,以便依据实体的属性值及约束条件将其划分到某个数据类别中去。Logistic回归分析主要用在社会科学中,目前有将粗糙集与Logistic回归进行结合构造分类模型如文献[2],文献[3]中提出的集成Logistic和SVM的分类模等。而模拟退火则作为一种有效的全局寻优算法,目前主要是将其和其他算法结合以改进寻优的质量或者将模拟退火算法使用的特定的领域进行参数优化。
在现在的商业系统中,门店分类是一个比较新的研究领域。在厂家的销售过程中,经常会将门店划分为不同的等级,例如汽车行业的旗舰店,4S店等的区别。当店面数量较少时可以采用人工划分,但具有很强的主观因素。因此考虑到在已有正确划分的店面的基础上运用一种好的分类方法,设计出分类器后在对未划分的店面进行自动划分。
1 基本知识
1.1 Logistic线性回归
Logistic回归延伸了多元线性回归思想,即因变量yi是二值(为了方便起见通常设这些值为0和1)的情形。和在多元线性回归中一样,自变量X=[x1,x2, …,xk ]可以是类别变量或连续变量或是两种类型的混合。在该文中我们主要使用Logistic进行二分类。Logistic函数公式如式(1),通过似然概率估计就可以计算出β=[β0,β1,…,βp ],最后使用Logistic函数来计算X分类的概率:
求解β的具体过程如下:
(1)随机初始化β0值和迭代的次数M;
(2)使用式(7)进行迭代得到βt+1;
(3)如果β值在一定步数内不变或者迭代次数达到M就跳出否则跳转到(2)。
当求得β后则可以使用式(1)来对已知的数据X进行分类概率的计算,当计算出来的概率π(X) < 0.5时将X分到第0类中,否则X为第1类。
1.2 模拟退火算法
模拟退火(Simulated Annealing)算法经常被用来求解全局最优解。SA算法其实是一种贪心算法,但是它的搜索过程引入了随机因素。模拟退火算法以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解,而求得全局的最优解。模拟退火算法的伪代码如下:
(1)随机产生一个初始解X0,令Xbest = X0,并计算目标函数值E(X0);
(2)设置初始温度T(0) = T0,迭代次数i= 1;
(3)Do while T(i) > Tmin
①for j = 1~k
②对当前最优解Xbest按照某一领域函数,产生一个新的解Xnew。计算新的目标函数值E(Xnew),并计算目标函数值的增量ΔE = E(Xnew) – E(Xbest)。
③如果ΔE < 0,则Xbest = Xnew;
④如果ΔE >0,则p = exp(-ΔE/T(i));
i.如果 c = random[0,1] < p,Xbest = Xnew;否则Xbest = Xbest。
⑤End for
(4)i = i +1;
(5)End while;
(6)输出当前最优点,计算结束。
2 实验设计
2.1 实验描述
本实验根据某鞋企的店面销售数据来对店面进行评级,店面的销售数据信息格式如(D1,D2,D3,…,Dn,C)。Di表示第i种鞋子的销售数据,Di的取值范围变化比较大,从零到几千的范围都有可能。C表示此店面的等级,C的取值为0,1两种。实验给出38条已分类的门店数据,实验的最终目的是通过这些数据来训练出一个分类模型。
2.2 算法设计
根据实际情况考虑给不同种类鞋子赋予不同的权重值,训练时先将每种鞋类的数量乘以数据权重值,再将修正后的数据用来训练Logistic线性回归模型用来评定未知门店的等级。因此使用模拟退火算法来找到一组好的权重值是本实验中最关键的步骤。
2.3 数据预处理
在训练数据时先将原始数据进行归一化,通过归一化可以把需要处理的数据限制在一定范围。以保证程序在运行Logistic线性回归算法时加快收敛。
该文将每种鞋子的销售数量采用式进行归一化。其中Dmin表示一种鞋的最小销量,Dmax表示鞋的最大销量,Dmin表示归一化前鞋的销量。归一化后的销售数量Dnew分布在0~10之间。
考虑到实验的数据数目比较小,实验中需要将数据按照2∶1的比例划分出训练集和测试集,且采用多次验证求均值的方法,排除随机分配出现的偶然性以保证验证时的准确性。
2.4 算法流程
在数据预处理后,接下来就需要使用模拟退火算法结合Logistic线性回归来寻找一组合适的数据权重值。
用一组包含n个数据的数据组i,初始的数据组是通过随机函数来生成的。元组j是在它的前一个数据组的基础上通过随机函数选择它中间的一个数据进行+0.01或者-0.01的操作得到的。
适应度的计算则是采用前面介绍的Logistic线性回归来计算。将新产生的权重数据与源数据相乘后得到新的新数据,然后利用新数据中的2/3来训练Logistic线性回归,得到一个分类器。用剩下1/3的新数据来验证分类器的正确率。最终的正确率采用测试十次求平均值的方法求得。
经过计算,最后得到一组包含n个数据的权重数据组和一组包含n+1个数据的Logistic函数参数的数据组。
3 实验分析
在实验中发现使用实验中的训练数据得出的分类模型能够将验证数据进行100%正确的分类。出现这样的原因可能有如下几点:(1)数据规模太小,使得验证数据不能很好地测试到数据可能的分布;(2)数据属性太少,导致较少的测试数据就能很好地拟合到线性回归的参数。
针对上面的情况,在试验中将训练数据设置为数据集的45%,这样就有更多的验证数据。同时通过调节初始温度、温度下降速度和内层循环的次数来验证试验结果。在初始温度较高,温度下降速度较慢和内存循环大于20的情况下,最后得到的权重数据组趋向一个比较稳定的数据,与刚开始随机生成的数据权重数据的关系更小。最后利用模拟退火得到的权重值对源数据进行调整。通过比较发现,调整后的模型在准确率上有一定程度的提高。
4 结语
通过该文的工作,得到了一个利用Logistic线性回归改进的模拟退火算法。利用此算法以期望寻找一组权重值,使得Logistic线性回归的在门店分类中的准确率得到提升。门店的分类作为商业运作中重要的一种智能算法,以后可能得到更广泛的应用。
参考文献
[1] 张军,詹志辉.计算智能[M].北京:清华大学出版社,2009:195-201.
[2] 叶明全,伍长荣,胡学钢.一种集成粗糙集与Logistic回归的分类模型[C].中国仪器仪表学会微型计算机应用学会,2009.
[3] 谢玲.集成Logistic和SVM的分类算法研究[D].重庆:重庆大学,2011:39.
[4] WangZhi. Computing Maximun Likelihood Estimates for Logistic Regression Coefficients[J].Mathematical Theory and Applications,2009(4):86-90.
[5] Ronghua Luo, Hansheng Wang.A Composite Logistic Regression Approach for Ordinal Panel Data Regresson[J].Data Analysis and Strategies,2008,1(1):29-43.
[6] David W.Hosmer, Stanley Lemeshow. Applied Logistic regression[M].AWiley-Interscience Publication,2000.
[7] W Ben-Ameur.Computing the initial temperature of simulated annealing[J]. Computational Optimization and Applications,2004,29(3):369-385.
