基于混合本体的文献分类研究
——以计算机学科为例
2016-05-26陈丽娜商丘师范学院计算机与信息技术学院中国农业科学院作物科学研究所
陈丽娜(1.商丘师范学院计算机与信息技术学院;2.中国农业科学院作物科学研究所)
基于混合本体的文献分类研究
——以计算机学科为例
陈丽娜1,2(1.商丘师范学院计算机与信息技术学院;2.中国农业科学院作物科学研究所)
摘要:传统的文献分类方法已经无法很好地适应文献组织和用户的需求。本文以计算机学科为例,对传统文献分类和Folksonomy进行对比研究,分析两者的优缺点,提出传统分类和基于Folksonomy的混合本体构建方法,研究了基于Folksonomy的标签抽取和语义映射方法。并以豆瓣读书为参考,尝试构建计算机文献本体,验证了该分类方法可有效地组织文献资源、满足用户需求,对规范文献分类具有实际意义。
关键词:本体;文献分类;Folksonomy;标签;计算机
传统的文献分类是用科学、严谨的方法把文献组织成层次状的体系结构,但随着文献数量的不断增长,新知识层出不穷,原来的分类体系逐渐暴露出弊端。而且,在现代信息化手段下,人们在通过网络终端查询文献时,总是根据自己的习惯输入待查关键字,这些关键字和传统的文献分类有很大不同。因此,迫切需要合适的文献分类方法来组织文献,满足用户需求。
近年来,有对传统分类法的改进研究,[1]传统文献分类法与网络信息分类法的比较研究,[2,3]文献分类与本体结合的研究,[4,5]对计算机文献分类的研究,[6,7]这些研究对文献合理分类提供了参考,但没能很好地将文献组织和用户需求结合起来。在Web 2.0环境下,用户可以自由地标注文献,分众分类——Folksonomy的方法聚集了大众智慧,为传统文献分类提供了补充。近几年,也有基于Folksonomy的文献分类研究,[8,9]但这些研究或者是综述,或者是理论性的分析,很少有具体的实践。本研究提出结合传统文献分类和Folksonomy构建本体的方法来进行文献分类,并以计算机学科为例,构建计算机文献本体。期望能提供合适的文献分类和组织方法,提高文献的组织管理水平,更好地满足用户需求。
1 传统文献分类
文献分类法是图书情报部门进行文献分类、组织藏书的工具,它使用符号来代表各级类目,规定其先后顺序。当前常用的文献分类法是《中国图书馆分类法》,简称《中国法》,总共分5个基本部类,下分22个大类。《中国法》以学科类别为基础,使用字母与数字混合编码,用字母代表大类,大类下用阿拉伯数字来细分具体的学科。
1.1计算机学科文献分类
根据《中图法》(第五版),计算机类文献可分为11大类:TP3-0计算机理论与方法、TP30一般性问题、TP31计算机软件、TP32一般计算器和计算机、TP33电子数字计算机、TP34电子模拟计算机、TP35混合电子计算机、TP36微型计算机、TP37多媒体技术与多媒体计算机、TP38其他计算机、TP39计算机的应用。每一类下又分小类,比如TP31计算机软件又分为TP311程序设计、软件工程、TP312程序语言、算法语言等,而TP311程序设计、软件工程又可分为TP311.1程序设计和TP311.5软件工程,TP311.1程序设计再细分为TP311.12数据结构、TP311.11程序设计方法、TP311.13数据库理论与系统,数据库理论与系统还可再进一步细分。计算机类文献总共分为227个子类。传统计算机文献是严格按照一定的体系结构来划分的,比如TP33-TP38是按照计算机类型划分的,而TP31和TP39是根据文献性质划分的。
1.2计算机学科文献分类的优点和不足
传统的计算机文献分类体系,按照从总到分,从一般到具体的原则编制。严谨科学,涵盖了计算机的所有领域,覆盖面广;各类目排列规范,类目之间呈明显的层次结构;概念表述清晰,检索效率较高。但传统文献分类法也存在很多不足。
(1)分类设置不均衡。有些分类过于复杂,导致实施成本太高。TP31和TP39两类占了总类数目的一半以上,其他9类所占类数还不到一半,分类不均衡。TP31和TP39中的有些分得太细,实施起来不方便。
(2)有些概念无文献保障。如TP321非电子计算机、TP322分析计算机(穿孔卡片计算机)等,由于时代的发展,所设类目已过时,很少有新文献来支持。
(3)反映新事物的概念没有出现。如TP316操作系统类别下,没有Android操作系统、iphone操作系统等比较新而用户又常用到的概念。
(4)分类的层次关系与实际情况不符。使用分类法得到的是层次结构,而实际上概念之间不单纯是层次关系,会有交叉。比如在软件开发过程中,会涉及程序设计方法、数据库和编程语言,而程序设计是借助于某种编程语言来实现的,这样TP311.52软件开发、TP311.11程序设计方法、TP311.13数据库理论与系统和TP312程序语言、算法语言就不再是单纯的层次关系。
综上可知,传统的计算机文献分类方法不能很好地满足文献组织的需要,与用户的实际需求也有差别,因此希望寻求新的方法,使分类更加合理。
2 Folksonomy
Folksonomy是在Web 2.0环境下,随着语义Web的不断成熟而迅速兴起的以用户分类为基础的新型网络信息组织方式。它由网络用户自发定义一组标签对某类信息进行描述,并根据标签被使用的频次,选用高频标签作为该类信息类名的一种为网络信息分类方法。[10]随着社会性软件的发展,Folksonomy被应用到越来越多的网络系统中,用户自发地对感兴趣的信息标注,并与其他用户分享,每个用户都可以贡献自己的智慧构建知识库。[11,12]
2.1基于Folksonomy的计算机文献分类
网上关于计算机资源的分类有很多种,豆瓣读书最能体现分众分类的特色。豆瓣网是Web 2.0网站中较具特色的一个网站,豆瓣读书是其一个子栏目,网站中关于书的描述和评论都由用户提供,用户给任何一本书添加自己喜欢的标签,并与他人分享。
在豆瓣读书中,计算机类图书被以“科技”命名,分为科普、互联网、编程、科学、交互设计、算法、程序、神经网络和web等十几个大类。其中,互联网又被用户冠以运营、产品、网站、IT、创业、手机等标签。如豆瓣评分9.2的计算机类书籍《编程珠玑》,由1500多人参与评分,用户给出340多个标签,比如:计算机、算法、程序设计、编程、编程艺术、programming、艺术、算法与数据结构、计算机科学等。展开每一个标签,还可以找到与此标签相关的其他图书。并且每本书都有用户对该书的评价,供他人参考。
2.2 Folksonomy的优点和不足
基于Folksonomy的分类非常灵活,它由用户自发定义,根据个人使用习惯对资源进行标注和分类,易于被大众接受;由于标签可以动态修改,能够动态地更新网络信息;通过参考其他用户的标签,有助于发现以前未知的资源;有利于集中群体智慧,可以多角度多方位地标识信息。[13]但基于Folksonomy的分类也存在不足。
(1)缺乏层次性。Folksonomy是一种平级的分类方式,很难使用它来揭示复杂的关系。如程序、IT、算法和互联网,很难说清它们的上下级关系。
(2)表达概念模糊。由于用户对标签含义的理解各异,在同一标签下,有可能会出现与主题完全无关的内容。如《编程珠玑》中,有用户标注“艺术”、“2008”,表达的概念非常模糊,产生了一些垃圾信息,影响了标签含义的表达。
(3)缺乏同义词控制。由于用户用词习惯的不同,会出现大量的同义词表达同一个概念。如用户可能会使用“编程”、“program”、“programming”或“程序设计”等来表示编程这个概念。
(4)低检索效率。由于Folksonomy使用的是非受控词,大量相似的标签使用导致用户无法检索到所有结果。比如,当检索“互联网”时,“web”、“internet”等一些标引的内容则检测不到。
由此可见,Folksonomy必须与传统分类结合方能更好地发挥作用。
3 传统分类和Folksonomy结合的本体构建方法
3.1构建思想
传统分类法在体系组织、概念描述上有优势,而Folksonomy则灵活、适应性强,有利于表达用户需求。另外,希望新的分类方法不仅仅能表达概念的关系,还能够更好地表达概念的语义,因此提出构建本体来实现两者的融合。
第一步,参考传统分类法对计算机文献的初级分类:保持一级分类不变,保证学科的完整性和系统性。对子分类进行删减优化,对层次较多的类目减少其层次,对较少文献支持的类目进行合并,增加能体现用户需求和新知识的类目。第二步,基于Folksonomy对初级分类进行优化:进行标签抽取、清洗、合并、过滤,清洗掉垃圾标签,合并同义词,过滤低频标签,得到反映用户需求的新概念集合,并通过语义映射确定概念的层次关系,对概念集合分类构建本体,形成新的计算机文献分类方法。
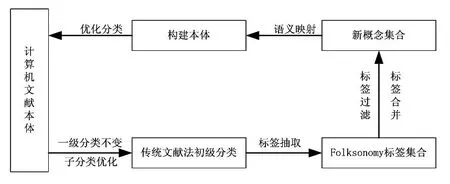
图1 本体构建示意图
3.2标签抽取及语义映射
在传统分类法和Folksonomy构建本体的过程中,新概念及语义关系的确定是关键。网络标签抽取可编写代码自动抽取,也可手工抽取。另外,标签间缺乏层次性,上下级关系很难确定,这和传统分类法是冲突的。因此,还需要进行标签语义映射,确定标签间的关系及标签的语义。

图2 标签抽取及语义映射过程示意图
(1)抽取网络资源中的标签进行预处理。标签清洗去除垃圾标签、相似标签合并去除冗余、过滤掉低频标签等,形成标签集M。还可以借助Google矫正拼写错误。
(2)将标签集M与初始概念集N(传统分类的概念集)进行比对,对于N中已经存在的概念,不做处理,其余的归于新标签集M’。将M’与在线词典进行比对,将标签分为可映射的标签集A和不可映射的标签集B。
(3)将标签集A与在线词典进行映射并进行语义关联,再通过网络语义资源如Wikipedia确定与这些概念相关的页面集。根据页面集中出现最频繁的术语确定与标签最相似的Wikipedia页面,通过该页面找到与标签对应的概念,使用Wiki的词条进一步丰富标签的语义。经过处理后,形成带语义的标签集A’,加入到初始概念集N中。
(4)分析标签集合B中的概念是否和A有关系,通过聚类、关联分析之后,将和A有关联的概念加入到A’中,丰富标签的语义。
(5)对标签集B中和A没有关联的标签,从中筛选出高频标签,这些标签是原有分类体系中没有而用户使用频率高的,也将其加入到概念集中,形成新的概念集N’。
将标签分类,对应于本体的概念,并将标签的语义关系转化为本体中概念的关系,标签概念和本体概念的对应关系如表所示。

表 标签概念和本体概念的对应关系
4 计算机文献本体构建
4.1初级分类
根据上述分析,计算机本体初级分类仍然保持传统文献一级分类的结构,共11大类。对于子分类,TP31计算机软件和TP39计算机应用重新优化分类,对其他子分类的处理的思路就是减少类的层次,尤其是减少无文献保障(即新出版文献数目较少)的分类。比如TP32-TP35,得到初级分类的结构图,如图3所示。
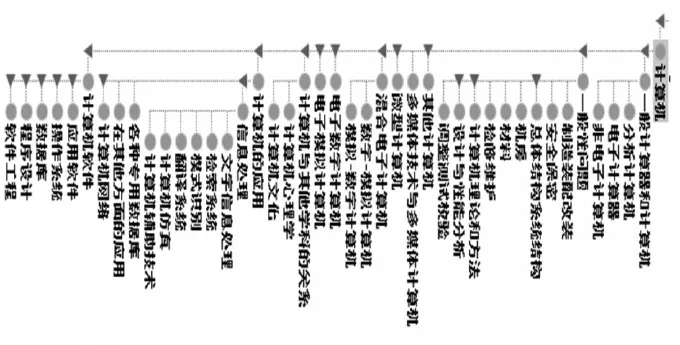
图3 初级分类结构图
4.2基于Folksonomy的优化
计算机本体涉及的内容比较多,为了清晰起见,以计算机软件类本体构建为例进行说明。在豆瓣读书上对“编程”、“算法”和“程序”分类抽取部分标签(见图4)。

图4 豆瓣读书部分标签
从图4可以看出,这些标签中有大量相同或类似的现象。如“计算机”、“计算机科学”、“计算机原理”;有些是相同意义不同表达形式,如“编程”和“programming”、“算法”和“Algorithms”等;有些是垃圾标签,和文献内容关联不大,如“入门”、“艺术”等。
首先,对标签进行预处理:清洗、合并、过滤、规范等,得到部分高频标签集合{计算机,编程,算法,程序设计,数据结构,数据分析,数据库……}。然后结合传统分类方法,将计算机软件领域分为操作系统、软件工程、应用软件、数据库和程序设计5大类。操作系统包括主流操作系统windows,unix,兼顾DOS,并新增加移动操作系统,包括Android、iOS、BlackBerry和Symbian等;软件工程包括软件设计、软件测试和软件工具等;应用软件包括文字处理软件、表处理软件、图像处理软件等;数据库包括Oracle、SQL Server、DB2、Sybase等主流数据库;程序设计包括数据结构、编程语言、算法和编译程序,编程语言又包括C语言、JAVA语言、汇编语言和其他语言。
4.3本体模型
根据上述得到的概念集及语义关系,采用本体建构工具Protégé4.3构建了一个计算机软件类本体模型(见图5)。
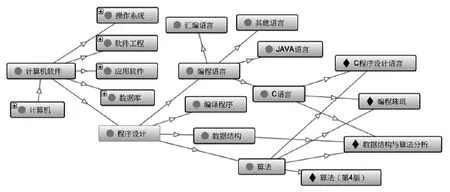
图5 计算机软件类本体模型
从模型可以看出,本体可以表达更丰富的语义。如《C程序设计语言》既可以归为C语言,又可归为算法;《数据结构与算法分析》可以同时归于C语言、算法和数据结构。从豆瓣读书上分别查看这两本书的标签,《C程序设计语言》的高频标签是{C编程c语言计算机程序设计经典programming编程语言},《数据结构与算法分析》的高频标签是{数据结构算法计算机C编程数据结构与算法分析算法、数据结构C语言}。很显然,该本体的文献分类和用户的高频标签是一致的,而高频标签代表了大多数用户对资源的理解,这也说明了该分类方法是符合大多数用户认知的。
5 总结
本研究提出了基于传统分类和Folksonomy结合的本体构建方法进行的文献分类,并构建了计算机文献本体模型,研究了Folksonomy对传统分类的补充作用。该方法既保证了传统分类的科学性,又体现了用户需求。由于Folksonomy的自由性、开放性,用户对标签的标注更是五花八门,所以要想更好地发挥网络标注的作用,标签的自动抽取和充分的语义映射是一个具有挑战性的问题。
[参考文献]
[1]周霞,周俊.传统文献分类法的改进研究[J].高校图书馆工作, 2013, 33(3): 74-76.
[2]邱陆英.传统文献分类法与网络信息分类系统的比较分析[J].图书馆学刊,2008(6):130-132.
[3]龙卫东,等.文献分类法,信息分类法和分众分类法探究[J].情报探索,2010(4): 6-8.
[4]欧阳宁,胡飞燕.基于本体的《中图法》类目可视化查询系统的设计[J].图书情报工作, 2009, 53(5): 43,46-86.
[5]吴琼,袁曦临.基于Folksonomy的网络文学书目资源本体构建[J].图书馆杂志, 2013(7):4.
[6]戴建陆.计算机技术图书分类若干问题的探讨[J].图书馆建设, 2007(3):69-71.
[7]李锋.计算机软件类图书分类标引存在的问题及对策研究[J].图书馆论坛,2009(1):108-110.
[8]官凤婷.基于文献计量的国内Folksonomy研究现状分析[J].图书馆论坛,2012,32(4):94-100.
[9]金岳晴,寿曼丽.中外大众分类法研究的比较分析[J].新世纪图书馆, 2012(9):21-24.
[10]薛涵,等.基于Folksonomy的本体构建综述[J].电子学报,2014,42(4):791-797.
[11]Spiteri L F.The structure and form of folksonomy tags: The road to the public library catalog[J].Information technologyandlibraries,2013,26(3):13-25.
[12]Cantador I,et al.Categorising social tags to improve folksonomy-basedrecommendations[J].Web Semantics:Science,Services and Agents on the World Wide Web,2011,9(1):1-15.
[13]陈洁,司莉.社会分类法(Folksonomy)特点及其应用研究[J].图书与情报,2008,152(3): 27-30.
Literature Classification Study Based on Combined Ontology——Illustrated by the Case of Computer Science
Chen Li-na
Abstract:Traditional literature classification can't satisfy the requirements of literature organization and user demand. The article, taking computer science discipline as an example, makes a comparative study on traditional literature classification and Folksonomy to analyzes their advantages and disadvantages respectively, and proposes an ontology construction method combining traditional literature classification and Folksonomy to classify literature. The article studies tag extraction and semantic mapping approach based on Folksonomy, and tries to build computer literature ontology by taking "Douban" reading as a reference, so as to verify the classification. The experiment shows the method can organize literature resources effectively, and can meet users demand with practical significance for literature classification.
Keywords:Ontology;Literature Classification;Folksonomy;Tag;Computer
[收稿日期]2015-09-20[责任编辑]刘丹
[作者简介]陈丽娜(1977-),女,博士,副教授,研究方向:信息系统管理、科学计算可视化等。
[基金项目]本文系国家科技基础条件平台项目(项目编号:2005DKA21001),河南省科技厅基础与前沿项目(项目编号:142300410395)的研究成果。
中图分类号:G254.11
文献标志码:A
文章编号:1005-8214(2016)03-0052-05
