基于FSFDP-BoV模型的遥感影像检索
2016-05-25沈忱,祁昆仑,刘文轩,吴华意
沈 忱,祁 昆 仑,刘 文 轩,吴 华 意
(武汉大学测绘遥感信息工程国家重点实验室,湖北 武汉 430079)
基于FSFDP-BoV模型的遥感影像检索
沈 忱,祁 昆 仑,刘 文 轩,吴 华 意
(武汉大学测绘遥感信息工程国家重点实验室,湖北 武汉 430079)
为提高遥感影像检索的精度,提出一种基于快速查找密度峰值聚类(Fast Search and Find of Density Peaks,FSFDP)的改进视觉词袋(Bag of Visual word,BoV)模型,该方法充分利用FSFDP聚类算法分类精度高和聚类参数易于选择等优点,增强BoV模型特征量化的稳定性和可靠性。实验表明,与经典BoV模型相比,FSFDP-BoV模型能够得到更高的检索精度。
遥感影像;检索;BoV;密度峰值聚类
0 引言
随着遥感影像的数据源和数据量的快速增长[2],基于内容的图像检索[2]成为当前遥感影像检索的一个研究热点和难点[3,4],提高遥感影像检索精度已成为基于内容的影像检索研究的必经之路。
视觉词袋(Bag of Visual word,BoV)模型是基于内容的图像检索中最热门的方法之一[5]。BoV模型源于信息领域的词袋(Bag of Words,BoW)模型。对于一个文本,BoW模型忽略其词序和语法句法,仅仅将其看作是一个词集合,文本中每个词的出现都是独立的,不依赖于其他词是否出现,即在任意位置选择一个词汇都不受前面句子的影响。由于BoW模型在特征描述方面有着独特的优势,因此将BoW模型的思想应用于图像的特征描述中,即BoV模型,当前已经广泛地应用于图像和视频的检索方面[6,7]。
为提升BoV模型在遥感影像检索中的精度和效率,研究者对BoV模型做出了改进[6-11],改进后方法能够有效地提高检索的精度,但在特征量化时均没有考虑密度信息,无法满足地物繁多且目标复杂的高分辨率遥感影像检索的需求。
2014年Rodriguez等提出了快速查找密度峰值聚类 (Clustering by Fast Search and Find of Density Peaks,FSFDP)[12]算法,该聚类方法具有灵活性高、稳定性强、效率高等特点。基于此算法,本文提出了BoV改进模型——FSFDP-BoV模型,并将其应用于遥感影像检索中。
1 基于BoV模型的特征描述
BoV模型在遥感影像检索中主要用于影像特征描述向量的生成[13]。假设有一组图像,从中选出测试样本和训练样本。首先,分别提取训练样本和测试样本的底层特征,如SIFT(Scale-Invariant Feature Transform)特征[14]、将图像刚性分割成多个块提取的颜色特征、纹理特征等,则每个图像就由很多个底层的局部特征表示,这些特征就是视觉词汇向量。然后利用K-Means算法对训练样本的视觉词汇向量进行聚类,选择聚类中心作为视觉字典的基础词汇。再利用欧式距离计算测试样本的视觉词汇向量与基础词汇的相似度,并用基础词汇表中的单词代替图像中的视觉词汇向量,统计出每一幅测试样本中基础词汇出现的次数,即统计直方图并作归一化处理,得到每一幅影像的特征向量,最终应用于影像的分类、检索等[15,16]。
BoV模型描述遥感影像的流程主要包含特征提取、字典训练和特征量化3个阶段。传统BoV模型的字典训练是采用K-Means聚类算法。为提高传统基于K-Means的BoV模型描述影像特征的精度。Zhong等[17]提出球形K-Means聚类算法(Spherical K-Means)来减弱局部特征高纬度和稀疏性对K-Means聚类效果的影响。Bolovinou等[18]进一步验证了该方法生成的聚类词典在表达能力上得到增强。Philbin[19]提出了近似K-Means(Approximate K-Means,AKM),并将其应用于目标区域检索。Wang等[20]提出了快速近似K-Means聚类算法(Fast Approximate K-Means,F-AKM)用于有效识别类簇之间交界处的数据点,减少了每轮迭代的计算量,进一步加快了聚类收敛的塑封,提高了生成视觉词典的效率。此外,为提高高维直方图相似性度量的有效性,Wu等[21]提出了一种基于直方图相交核(Histogram Intersection Kernel,HIK)[22]的K-Means聚类方法生成视觉词典,并在目标识别实验中验证了该视觉词典的良好性能。文献[23]主要针对视觉词汇表的改进进行了研究,并对近似K-Means和分层K-Means两种方法进行了对比分析。
上述方法仅通过改进K-Means聚类来提升BoV模型在字典训练的精度和效率,且没有考虑到视觉词汇空间下视觉单词的分布和密度因素,得到的视觉字典无法很好地表达影像中的视觉单词,造成较大的量化误差。FSFDP聚类能够通过查找密度峰值确定聚类中心,不仅有效地保证规则分布点簇的完整性,而且与K-Means聚类算法相比,FSFDP算法有聚类结果稳定、算法效率高等优点。本文将基于FSFDP聚类算法改进BoV模型,以期提高字典训练的精度和改进BoV模型的影像特征量化方法。
2 基于FSFDP-BoV模型的遥感影像检索
2.1 FSFDP聚类
FSFDP聚类方法是基于局部密度分布判别各个点类别的方法,该算法假设聚类中心由一些局部密度比较低的点围绕,并且这些点距离其他高局部密度的点的距离都较远,以保证聚类中心之间不属于同一点集。找到聚类中心后,通过查找每个点临近的高密度点来判断该点的类别,以保证算法对呈规律分布的点群分类后的完整性。FSFDP算法的主要步骤如下:
(1)计算局部密度ρ。点i的局部密度为到点i的距离小于截断距离dc的点的个数。
其中,若x<0,则χ(x)<0;若x>0,则χ(x)=1。
(2)计算δ。δ是指点i到比自身局部密度大的点的最小距离。如果点i已经是局部密度最大的,则δ赋值为点i到距自身最远的点的距离。即:
(3)寻找聚类中心。由于成为聚类中心的点需要ρ和δ都优于其他点,也就是Density Peaks。本文用作为选取聚类中心的标准。对所有点按ρ*δ由大到小排序,前K个点作为聚类中心,其中K为聚类中心个数。
(4)确定各个点的类别。聚类中心选好后,每个点属于距其最近的且比自身密度高的点所在的类别,直至所有点都能划归到某一个类别。
与K-Means相比,FSFDP算法有如下优点:1)灵活性:算法可根据ρ*δ的分布决定聚类中心个数K。2)稳定性:在相同数据源和参数的条件下,聚类结果完全一致,不会出现多次聚类得到不同的结果的情况。3)高效性:聚类流程只需一次即可完成,不需要重复迭代。4)完整性:结果中呈规则分布的点群能划分到同一类别,保证分类精度。
2.2 FSFDP-BoV模型
基于FSFDP聚类算法提出FSFDP-BoV遥感影像检索模型,利用FSFDP算法搜索密度峰值找到聚类中心并训练字典,在BoV模型的特征量化上根据局部密度逐点归类。该方法不仅在BoV模型生成字典的过程中充分考虑了点群密度分布情况,保证聚类中心是高密度的点,而且在BoV模型特征量化的过程中利用局部密度归类量化生成直方图。 FSFDP-BoV模型具体流程如图1。
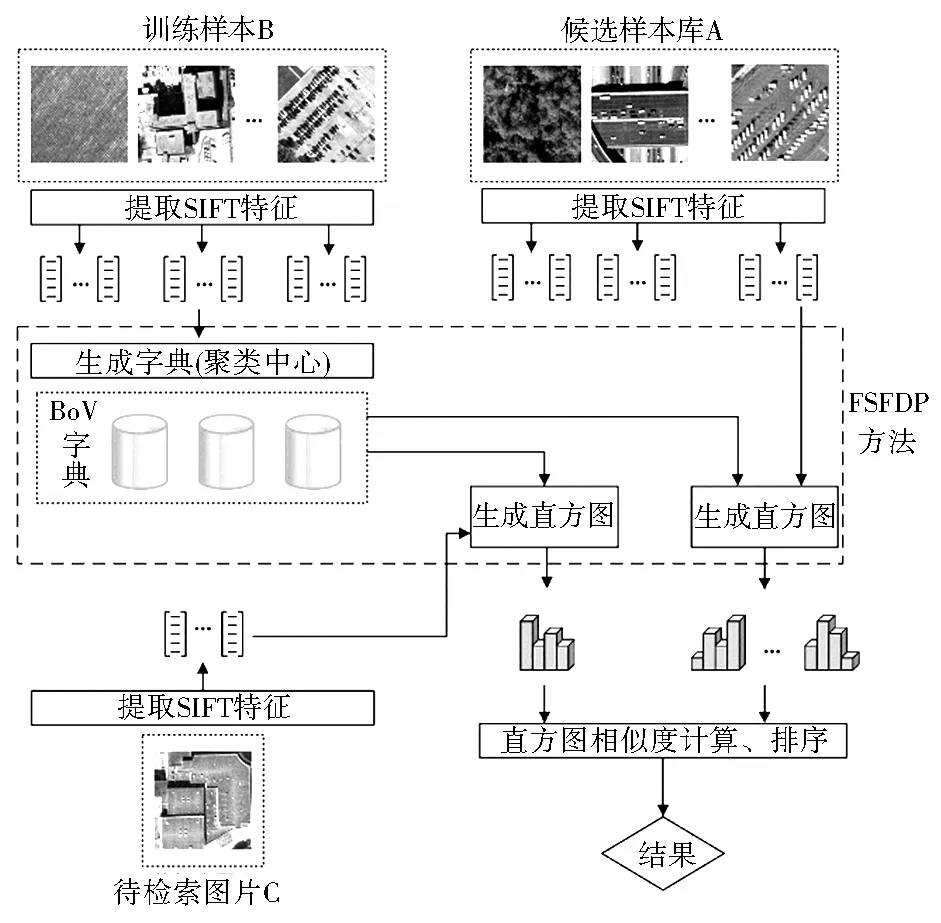
图1 FSFDP-BoV模型
Fig.1 The FSFDP-BoV model
(1)局部特征提取。提取训练样本和候选样本影像的SIFT特征作为BoV模型的局部特征。每张影像得到n个128维SIFT向量,其中n为SIFT点数目,向量组成n*128的矩阵称为样本的特征。
(2)基于FSFDP聚类算法构建BoV字典。分别计算每个特征点的ρ和δ,并对所有特征点按ρ*δ从大到小排序,取前K个特征点作为聚类中心(K为聚类个数),即字典中的基础词汇。
(3)生成统计直方图。生成待检索影像和候选样本库中的每张影像的统计直方图。经典的基于K-Means的BoV模型是利用欧氏距离度量测试样本的特征向量和字典中基础词汇(聚类中心)之间相似度,而FSFDP-BoV模型是用特征向量的局部密度进行度量。首先将测试样本的特征向量置于训练样本的向量集空间中,然后计算特征向量的局部密度,找最近并且比自身密度高的训练样本特征,若该训练样本不是聚类中心,则继续找比该训练样本最近的且比自身密度高的特征,直到找到聚类中心。最后统计每个样本基础词汇出现的次数,得到统计直方图并进行归一化,得到的向量即为每幅影像的FSFDP-BoV模型特征向量。
(4)相似度对比。计算待检索影像特征向量与候选影像库的特征向量的余弦相似度,通过测量两个向量内积空间的夹角的余弦值来度量其间的相似性。0°角的余弦值是1,而其他任何角度的余弦值都不大于1,并且其最小值是-1,由于向量直方图中数值都不小于0,故实际最小值为0。方法如下(其中H1、H2为两个直方图向量):
最后据相似度大小对候选影像排序并输出结果。
3 实验与结果
3.1 实验数据
本实验的数据来源于USGS的UCMerced_LandUse数据中的10类典型地物样本,每类各100张影像,影像大小为256*256,分辨率为0.3048 m。样本示例如图2所示。

图2 样本示例
Fig.2 Illustration of the samples
(1)所有10类样本作为候选样本库A=(A1,A2,…,A10),其中A1有100张影像。候选样本库共有1 000张影像。
(2)从中随机抽取的10张影像的集合为Bi,10类Bi构成训练样本B=(B1,B2,…,B10)。训练样本B共有100张影像。
(3)待检索影像集C=(C1,C2,…,C10),其中C1是从候选样本库中随机抽取的10张影像,待检索影像C共有100张影像。
实验首先用训练样本B训练BoV模型的字典,通过字典量化待检索影像C和候选样本库A的特征向量;然后计算待检索影像C与候选样本库A的相似度并排序;最后统计检索影像集C中所有影像检索结果的准确率和召回率。
3.2 参数选择
(1)截断距离dc的选取。最佳dc应使得特征集合中平均每个点的邻居数为所有点数目的1%~2%。首先取一个随机值d,统计所有点的邻居数之和,除以点的数目得到平均每个点的邻居数,再除以所有点的数目。如果结果小于1%,则扩大d的值,如果结果大于2%,则减小d的值,当结果处于1%~2%的范围内时,取d作为截断距离。
(2)聚类个数K的选取。聚类中心应是ρ和δ都比较大的点。为确定聚类个数K,需通过分析经过排序的ρ*δ曲线,找出曲线的拐点作为K的值。步骤如下:1)统计每个点的ρ和δ并计算ρ*δ。2)对所有点按ρ*δ值从大到小的顺序排序。3)根据ρ*δ值生成二维线性图表(图3),其中纵坐标为ρ*δ,横坐标为点的序号。4)根据特征点ρ*δ的分布,找出ρ*δ值与大部分点ρ*δ值相差较大的点集作为聚类中心。如图3,第一个点和第二个点之间ρ*δ间隔最大(由于原始点数量过大,将原始ρ*δ线形图按500间隔采样,即每个点代表500个点),即前500个点的ρ*δ值与后面的点差距较大,故聚类中心数目K应取500。
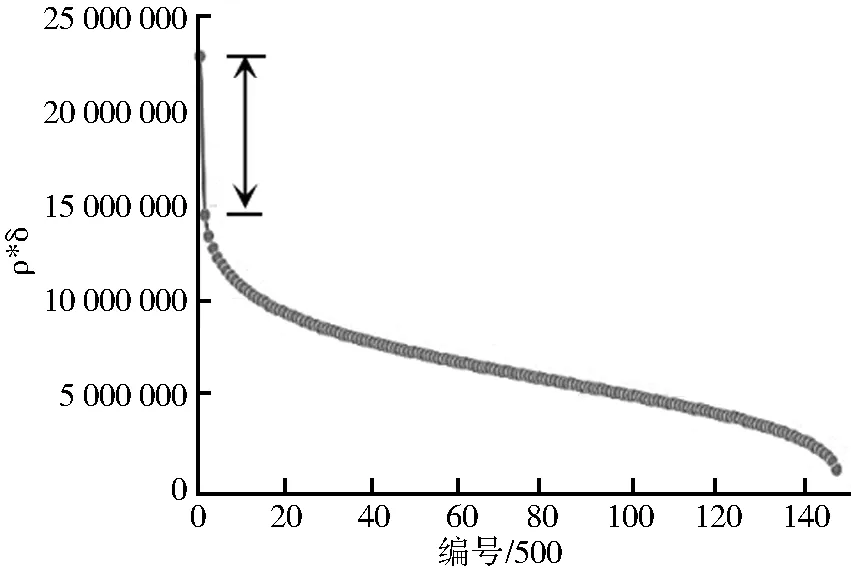
图3 选取最佳K值
Fig.3 The best choice ofKvalue
3.3 实验结果
用K-Means聚类的经典BoV模型作对比实验。图4为10类地物的待检测样本召回率的平均值,由此得到FSFDP-BoV模型和经典K-Means-BoV模型的准确率-召回率对比图。在遥感影像检索中FSFDP-BoV模型的准确率整体上要比经典BoV模型高,尤其是在召回率为10%的情况下更为明显。
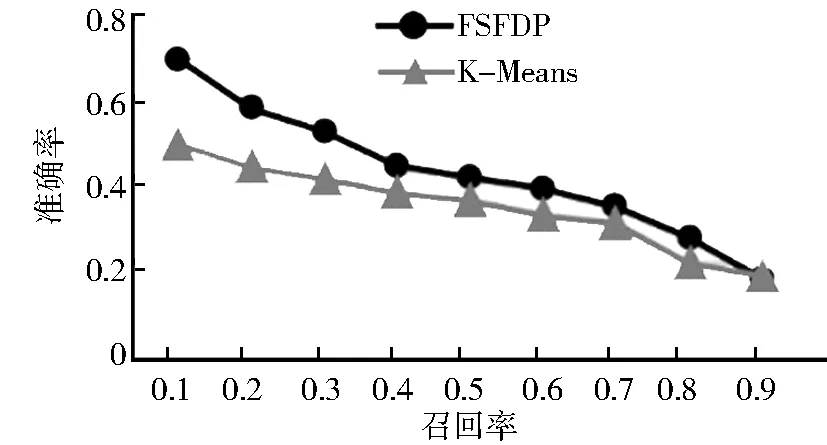
图4 总体结果
Fig.4 The overall result
表1为10类地物在FSFDP-BoV模型和经典K-Means-BoV模型检索结果的对比。可以看出,基于FSFDP-BoV模型在很多类别中检索精度均强于经典BoV模型,尤其是高速公路、森林、中型住宅区、天桥,检索结果优势较为明显。在高速公路类别,当召回率为10%时,FSFDP-BoV模型的准确率要相对经典BoV模型高。中型住宅区、森林、天桥类别中,相同召回率的条件下,FSFDP-BoV模型的检索结果准确率优于经典BoV模型。
表1 各类别准确率-召回率
Table 1 Accuracy-recall of each category

召回率类别 10.0% 20.0% 30.0% 40.0% 50.0% 60.0%70.0%80.0%90.0% 农业用地建筑物灌木丛森林高速公路港口中型住宅区天桥停车场机场跑道FSFDPK-means100.0%100.0%100.0%100.0%100.0%100.0%100.0%100.0%100.0%100.0%100.0% 98.4%87.5%93.3%45.2%16.0%5.9%5.8%FSFDPK-means20.8%15.9%19.2%15.5%16.4%15.2%18.0%14.3%16.8%12.3%15.3%12.1%14.9%10.7%13.8%9.2%10.9% 8.0%FSFDPK-means100.0%100.0%100.0%100.0%100.0%100.0%100.0%100.0%100.0%98.0%98.4%98.4%98.6%98.6%92.0%97.6%64.7%95.7%FSFDPK-means100.0% 52.6%100.0% 64.5%88.2%55.6%66.7%45.5%58.1%46.3%50.0%31.1%31.5%26.6%26.1%16.6%16.0%10.7%FSFDPK-means90.9%20.0%19.6%18.0%21.1%16.5%22.1%11.2%21.9%10.4%18.8% 8.9%17.5%8.4%16.0%7.9%11.3% 7.0%FSFDPK-means100.0%100.0%100.0% 54.1%71.4%47.6%28.4%36.4%14.7%25.6%12.8%14.7%10.9%11.8%10.8%8.9%9.6%6.5%FSFDPK-means76.9%45.5%52.6%29.4%38.5%25.2%26.7%27.2%24.5%24.2%21.9%23.3%18.6%21.4%16.5%21.4%12.7%17.2%FSFDPK-means45.5%13.7%43.5%14.6%46.2%13.7%41.7%12.6%37.9%11.7%32.6%11.3%29.5%11.3%20.3%8.9%18.5% 7.8%FSFDPK-means30.3%21.7%26.0%22.0%18.8%19.1%12.8%14.7%10.6%12.3%9.1%8.9%6.6%6.6%6.5%5.9%6.0%5.5%FSFDPK-means27.8%17.2%14.6%14.1%18.2%11.0%21.6%10.0%24.3%10.4%23.5% 9.0%23.0%8.4%15.9%7.4%9.4%6.1%
4 结语
本文基于FSFDP聚类算法对经典BoV模型进行了改进,提出FSFDP-BoV模型并应用于遥感影像检索。实验表明,该方法在遥感影像的分类检索中能取得不错的检索精度,尤其在农业用地、灌木丛、港口类别中效果较好。FSFDP-BoV模型检索精度普遍优于经典BoV模型,特别是在高速公路、森林、中型住宅区、天桥类别下,FSFDP-BoV模型的检索精度具有明显优势。
[1] SMEULDERS A W M,WORRING M,SANTINI S,et al.Content-based image retrieval at the end of the early years[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2000,22(12):1349-1380.
[2] HIRATA K,KATO T.Query by Visual Example,Content Based Image Retrieval[C].Advances in Database Technology,EDBT 92,Vienna,1992
[3] 程起敏.基于内容的遥感影像库检索关键技术研究[D].北京:中国科学院研究生院,2004
[4] 李德仁,宁晓刚.一种新的基于内容遥感影像检索的图像分块策略[J].武汉大学学报(信息科学版),2006,31(8):659-663.
[5] SIVIC J,ZISSERMAN A.Video google:A text retrieval approach to object matching in videos[J].ICCV,2003(2):1470-1477.
[6] 周文罡.基于局部特征的视觉上下文分析及其应用[D].合肥:中国科学技术大学,2011.
[7] 李远宁,刘汀,蒋树强,等.基于“bag of words”的视频匹配方法[J].通信学报,2007(12):147-151.
[8] ZHANG Y M,JIA Z Y,CHEN T.Image retrieval with geometry-preserving visual phrases[A].CVPR,2011.809-816.
[9] PHILBIN J,CHUM O,ISARD M,et al.Object retrieval with large vocabularies and fast spatial matching[A].CVPR,2007.
[10] 杨进,刘建波,戴芹.一种改进包模型的遥感影像检索方法[J].武汉大学学报(信息科学版),2014(9):1109-1113.
[11] WU J,CUI Z,ZHAO P,et al.Visual vocabulary tree construction research using adaptive Fuzzy K-Means Clustering[J].Advanced Science Letters,2012,11(1):258-262.
[12] RODRIGUEZ A,LAIO A.Clustering by fast search and find of density peaks[J].Science, 2014,344(6191):1492-1496.
[13] 柴玉梅,王宇.基于TFIDF的文本特征选择方法[J].微计算机信息,2006,24:24-26.
[14] LOWE D G.Distinctive image features from scale-invariant key points[J].International Journal of Computer Vision,2004,60(2):91-110.
[15] MOLINIER M,LAAKSONEN J,HAME T.Detecting man-made structures and changes in satellite imagery with a content-based information retrieval system built on self-organizing maps[J].Transaction on Geosciences and Remote Sensing,2007,45(4):861-874.
[16] 李士进,仇建斌,於慧.基于视觉单词选择的高分辨率遥感影像飞机目标检测[J].数据采集与处理,2014,29(1):60-65.
[17] ZHONG S.Efficient online spherical K-means clustering[A].Proc.of the 2005 IEEE International Joint Conference on Neural Networks[C].Montreal,Canada,2005.3180-3185.
[18] BOLOVINOU A,PRATIKAKIS I, PERANTONIS S.Bag of spatio-visual words for context inference in scene classification[J]. Pattern Recognition,2013,46(3):1039-1053.
[19] PHILBIN J.Scalable Object Retrieval in Very Large Image Collections[D].University of Oxford,2010.
[20] WANG J,WANG J,KE Q,et al.Fast approximate K-means via cluster closures[A].Multimedia Data Mining and Analytics[M].Springer International Publishing,2015.373-395.
[21] WU J,REHG J M.Beyond the Euclidean distance:Creating effective visual codebooks using the histogram intersection kernel[J].Computer Vision IEEE International Conference on,2009,30(2):630-637.
[22] ODONE F,BARLA A,VERRI A.Building kernels from binary strings for image matching[J].Image Processing,IEEE Transactions on,2005,14(2):169-180.
[23] ZHENG Y T,ZHAO M,NEO S Y,et al.Visual synset:Towards a higher-level visual representation[A].Computer Vision and Pattern Recognition,2008[C].CVPR 2008,2008.1-8.
Remote Sensing Image Retrieval Research Based on FSFDP-BoV Model
SHEN Chen,QI Kun-lun,LIU Wen-xuan,WU Hua-yi
(State Key Laboratory of Information Engineering in Surveying,Mapping and Remote Sensing,Wuhan University,Wuhan 430079,China)
In order to improve the accuracy of retrieval of high-resolution remote sensing images,this paper proposes an improved Bag of Visual Word (BoV) model based on clustering by Fast Search and Find of Density Peaks (FSFDP).Taking the advantages that the result of clustering by FSFDP is highly accurate and that the clustering parameters are easy to choose,this model enhances the stability and reliability of feature quantification in BoV.
remote sensing images;retrieval;Bag of Visual words;density peaks clustering
2015-06-10;
2015-10-14
国家973计划项目(2012CB719906)
沈忱(1991-),男,硕士,主要从事高分辨率遥感影像检索研究。E-mail:ShenChen0425@whu.edu.cn
10.3969/j.issn.1672-0504.2016.01.011
TP79
A
1672-0504(2016)01-0055-05
