一种多机器人的任务分配和自动协商的方法
2016-05-16皮玉珍苑全德舒英利
皮玉珍,苑全德,舒英利
(1.长春工程学院; 2.吉林省配电设备自动化产业公共技术研发中心,长春 130012)
一种多机器人的任务分配和自动协商的方法
皮玉珍1,2,苑全德1,2,舒英利1
(1.长春工程学院; 2.吉林省配电设备自动化产业公共技术研发中心,长春 130012)
摘要:提出了一种多机器人的任务分配和自动协商的方法。在进行任务分配时充分考虑机器人的真正性能;构建自动协商的模型时,改进最小二乘法支持向量回归算法(LSSVR),用于估计对手的谈判效用,并采用鲁棒控制器的输出反馈变量来限制优化实用性能指标,然后提出协商和再分配的协议来提高实时性和任务分配效率。最后,通过仿真实验来验证次方法的有效性。
关键词:多机器人;任务分配;协商
在多机器人技术中,任务分配和协商一直是研究的关键问题之一。其研究主要集中在任务分配的方法、资源能力的推理、自主合作、系统通信流量、学习和双向多问题协商等方面。例如,在参考文献[1]中刘淑华等提出的任务分配方法是基于群体智能的采用分层架构的带有宽松和紧密耦合任务的大规模多机器人系统;在参考文献[2]中提出分布式同质的多机器人系统,以实现以负载平衡为目的的任务分配方案;在参考文献[3]中Elango开发了一个仿真模型包括任务优先级和机器人的利用率,把它做为一个平衡的多机器人任务分配问题的优先级;在参考文献[4]中Jouandeau提出一个以贸易为基础的多机器人任务分配方法,这个方法模拟了买家和卖家通过使用一种机械的主动竞价方式完成动态的任务分配,等等。
本文提出的任务分配和协商方法,考虑机器人的实际能力和性能。并改进了竞争性投标效用函数,实现了快速学习。
1机器人的能力和任务分配的原则
1.1机器人能力的描述
在多机器人中,设R={R1…,Ri,…Rm},每一个机器人与其他机器人之间可以是同型的或是非异构的,但是至少保证Ri={PR,SR,BR},其中,PR是机器人的位置和方向,SR是传感器的类型,BR是处理任务的能力。
BR=g(bi,τi) 是Ri里bi的实际能力,与能力状态τi有关,0≤τi≤1。
映射perfi∨timei∨bandwidthi∨poweri→τi的意思是τi受性能、执行时间、带宽、电源等的影响。Ri完成任务的能力t用式(1)表示:
j(τi,bi,t)=τiω(bi)-u(t)
(1)
式中:ω(bi)是消耗能力;u(t)是完成时的成本t。
ComCost∨ResCost∨RisCost∨ChaCost→ω(t) 表示ω(t)受很多因素的影响,ComCost是通信成本,ResCost是资源成本,RisCost是执行任务风险成本t,ChaCost是机会成本,j(τi,bi,t)被用来判断t是否已经完成。如果j(τi,bi,t)≥0说明Ri能够完成t,否则不能完成。
1.2任务分配的原则
在理想的状态下,τi=1,遍历n任务。对于任务tj,如果(ω(b1)+…+ω(bm))/m-u(tj)≥0,说明tj通过单个机器人能够完成,所以tj被看是一个单一的任务。如果(ω(b1)+…+ω(bm))/m-u(tj)≤0,说明tj通过很多机器人能被完成,tj被视为一个团队任务。因此进行单一任务设IT={it1,…,itx,…itu},团队任务设CT={ct1,…cty,…ctv},同时∀(itx∧cty)=φ。

参考文献在[5]中祖丽楠等设计用竞争性竞标效用函数去实现机器人的任务分配,但是这个方法没有考虑当机器人加入到实际的合作时机器人实际性能的变化和对机器人的能力补偿。在此我们根据以上的分析对这种方法做了进一步的改进。
(2)式中:p(bil,itxi)是初始化Ril到处理itxi阶段的成本,它随着距离和时间的增加而增加;α和β是映射比例系数;Δb(τil)是对Ril的性能补偿;τ是补偿等级,τ∈R+。ρxi且随着p(bil,itxi)和ω(bil)的减少而增加,表明选取Ril有适合的性能去处理itxi的原理。
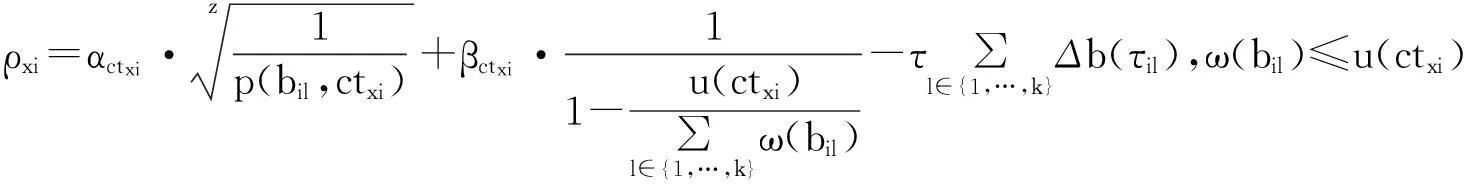
(3)
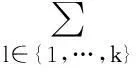
2自主协商
2.1协商模型
单一的机器人被指派去完成itxi可以实现单一任务的指派分配,在这里我们考虑多机器人的协商情况。下面将分析机器人在处理ct时如何建立它们之间的协商关系。基本步骤如下:
从自由机器人{R1,…,Rz}中选择有最小ω(bp)的机器人Rp(1≤p≤z)作为申请人;
Rp轮流选择自由机器人依据机器人的能力进行降序排列和向他们发送协商方案,在tKk和Rq协商成功后做出处理Ck,1≤q≤z,q≠p;
Rp选择tKk+1,重复步骤2直到全部任务都被分配了。
在多机器人上定义协商模型NMM={R,CT,E},其中R={R1,…,RP,…,RZ}是被许可加入协商的机器人。CT是合作任务,E是合作效用评估。

2.2协商效用的估计
尽管最小二乘法向量回归帮助解决了在理想状态下小样本的快速学习问题,但是当用在实际的协商状态下却变得不稳定,多机器人带有很多不确定的干扰信息会引起无休止的学习。为了维持最小二乘法向量回归的稳定性,在此我们选择径向基函数核函数,采用鲁棒反馈控制器抑制不确定的干扰信息以保持系统的稳定性。
vi(t+1)=fvi(t)+c1r1(Pi-xi(t))+c2r2(Pg-xi(t))
xi(t+1)=xi(t)+vi(t+1)
(5)
式中:vi(t+1)、vi(t)分别是在t+1和t时刻第i个粒子的速度;f是惯性权重;c1、c2是两个常数,r1、r2是在[0,1]之间的随机数;Pi、Pg分别是第i个粒子和全部粒子的最佳位置;xi(t+1)、xi(t)分别是第i个粒子在t+1和t时刻的位置。
为了优化在多机器人协商系统实际的性能指标,LMI被用来设计鲁棒控制器的H输出反馈。当LSSVMI有误差或者学习过程不完全收敛,鲁棒控制器输出错误路径,产生反馈信号确保协商过程的连续性和闭环系统的稳定性。
权重理解之后,对手的效用估计
EUp→q(·)=κfr+(1-κ)gr
(6)
式中:fr是LSSVMC的输出;gr是鲁棒控制器的输出,κ是鲁棒因素值。
κ=e-φEm,
(7)
式中:φ是鲁棒系数,φ∈(0,1)。
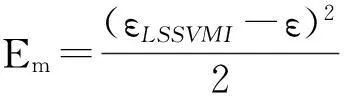
(8)
2.3协商协议和再分配
由于高实时性的要求,在协商中机器人数量的控制和协商回合应该被升级,避免在频繁的协商时通信带宽的拥挤和信号延迟。设Rp到提议通过局部广播只在relative net内和仅仅那些属于这个区域的空闲机器人可以加入到这个协商中。L(Rq)∈NRp(rp)是指Rq属于Rp的relative net ,L(Rq)是Rq的当前位置,NRp(rp)是在半径rp到Rprelative net 覆盖的区域。0≤p,q≤z′≤z,q≠p,z′是在relative net 中包括Rp的机器人数量。Rp通过局部广播网在tkk上提出协商协议。如果L(Rq)∈NRp(rp),Rq返回响应d(Rq),

(9)
在协商过程中,当ξmin≤EU(·)≤ξmax连续拒绝或停止协商。协商申请人升级协商广播网区域以寻求更多的候选人,其中ξmin和ξmax是最小效用和最大效用。协商的步骤如下:
准备阶段i=1 表示开始第一回合协商。
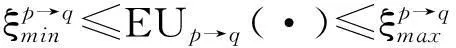


步骤4∀d(Rq)=拒绝,转到步骤1。
步骤5∃d(Rq)=等待∧∀d(Rq)≠同意。Rp在特定的等待时间δ阶段接受提议响应,且∃d(Rq)=同意,转到步骤2。如果∃d(Rq)≠同意在δ时间段转到步骤6。
步骤6如果rp>rmax,协商失败,或者Rp扩大半径到rp=rp+βΔr,β是放大比例系数,Δr是半径增加量。Rp通过局部广播在次发送广播。转到步骤1。
步骤7 在tkk上Rp同Rq建立任务分配关系Ck(tkk,Rp,Rq)。协商成功结束。
3多机器人追逐仿真实验
实验在矩形方格区域进行,在矩形方格区域内随机创建不同形状的障碍物。多机器人协商去追逐目标机器人(猎物)。如图1所示,是追逐初始化阶段图。目标机器人通过智能策略逃跑。在追逐者和猎物间的视野半径比例为1∶1。声波定位仪的范围比例为1∶2。当协商时广播是唯一的通信方式,LSSVR常常被用来评估对手的谈判效用。
图1 追逐初始化阶段
追逐过程中,算法中分别设计了没有协商的追逐和有协商的追逐两种。在没有协商的追逐过程中,追逐者追逐猎物是依靠局部的优化算法。而有协商的追逐过程,机器人之间互相协商去包围猎物。协商的条目有向前移动的距离d,向后移动的距离d,向左转的角度θ,向右转过的角度θ。他们的权重因子是(0.25,0.25,0.25,0.25)。机器人预测猎物的移动方向,提供计数提议。协商的记录储存在协商历史数据库里作为协商双方效用评估样本。
表1表示的是60个没有协商的追逐过程的时间数据。表2表示的是60个有协商的追逐过程时间数据。其中,vp和ve分别是追逐者和猎物的速度,它明显地表明有协商的追逐过程的成功率要高于没协商的追逐过程。表中,SR是成功比率,F表示失败。

表1 没有协商的追逐过程的时间数据

表2 有协商的追逐过程的时间数据
4 结语
在多机器人任务分配中,传统的竞争性招标效用函数仅考虑机器人的理想性能而不能补偿机器人的实际性能,忽略了由外部不确定干扰因素引起的协商系统稳定性问题。本文提出的基于机器人的真实性能的多机器人任务分配和协商的方法,改进了竞争性投标效用函数。改进的LSSVR实现了快速学习,鲁棒控制器实现了维持系统稳定性。本方法的有效性已经在实验中得到证明,实验表明这个方法改进了任务分配的效率。
[1] 刘淑华,张嵛,吴洪岩,等. 基于群体智能的多机器人任务分配[J].吉林大学学报:工学版本,2010(1): 123-129.
[2] 周菁,慕德俊. 多机器人系统任务分配研究[J].西北大学学报:自然科学版,2014(6): 403-410.
[3] Elango M,Nachiappan S P.Balancing multi-robot prioritized task allocation: A simulation ap-proach[C]//2011 IEEE International Conference on In-dustrial Engineering and Engineering Management. Singapore:IEEE, 2011: 1725-1729.
[4] Jouandeau N, Yan Zhi. Improved trade-based multi-robot coordination[C]//2011 6th IEEE Joint International Information Technology and Artificial Intelligence Conference (ITAIC),Chongqing, China:ITAIC, 2011:500-503。
[5] 祖丽楠,田彦涛,梅昊.大规模多移动机器人合作任务的分布自主协作系统[J].机器人,2006,28(5):470-477.
A Method of Task Allocation and Automated Negotiation for Multi-robots
PI Yu-zhen, etc.
(ChangchunInstituteofTechnology,Changchun130012,China)
Abstract:A method of task allocation and automated negotiation for multi-robots has been proposed. In the paper, the principles of task allocation are described based on the real capability of robot. During the construction of automated negotiation model, Least-Squares Support Vector Regression (LSSVR) has been improved to estimate the opponent's negotiation utility, and the robust controller of output feedback has been employed to optimize the utility performance indicators. Then, the protocol of negotiation and reallocation has been proposed to improve the real-time capability and task allocation. Finally, the validity of method is proved through experiments.
Key words:multi-robot; task allocation; consultation
文献标志码:A
文章编号:1009-8984(2016)01-0053-04
中图分类号:TP242.6
作者简介:皮玉珍(1981-),女(汉),长春,讲师
基金项目:吉林省科技厅项目(20150204008SF,20130206049GX,201301010052JC)吉林省教育厅项目(2013296,2014324,2014339,2014327,2014309)
收稿日期:2015-11-04
doi:10.3969/j.issn.1009-8984.2016.01.012
主要研究多智能体、智能电网。
