本体图驱动的概念相似度算法
2016-05-14曾小芹
曾小芹

摘要:采用本体概念映射方法,研究概念间相似度计算问题并提出本体图驱动的概念相似度算法。该算法将概念映射到本体结构图上,通过计算概念的语义、结构及属性相似度得到综合相似度。其中,结构相似度通过语义辐射圆计算模型得到,属性相似度通过概念重心向量夹角余弦得到。通过实验对比证明,该算法在一定程度上提高了相似度准确性,为数据挖掘提供了一定依据。
关键词关键词:本体;相似度;语义辐射圆;数据挖掘
DOIDOI:10.11907/rjdk.161326
中图分类号:TP312文献标识码:A文章编号文章编号:16727800(2016)007005903
0引言
互联网行业之所以能创造财富,关键是通过记录和分析用户网络操作的大数据,形成用户“行为指纹”,从而洞悉用户潜在的、真实的需求,形成预判。用户的每一次浏览、评论、点播都是数据。但数据处理却是一项重要的技术挑战。使用传统的方法去描述与度量大数据的复杂性,据资源优化融合的应用性能,进行仿真实验。数据融合算法采用Matlab编程实现。在CIMS工业生产项目中进行供应链模型构建,通过ERP系统结合仿真工具(MBPST)进行供应链大数据资源融合软件开发,得到仿真平台中数据融合统计分析输出如图2所示。
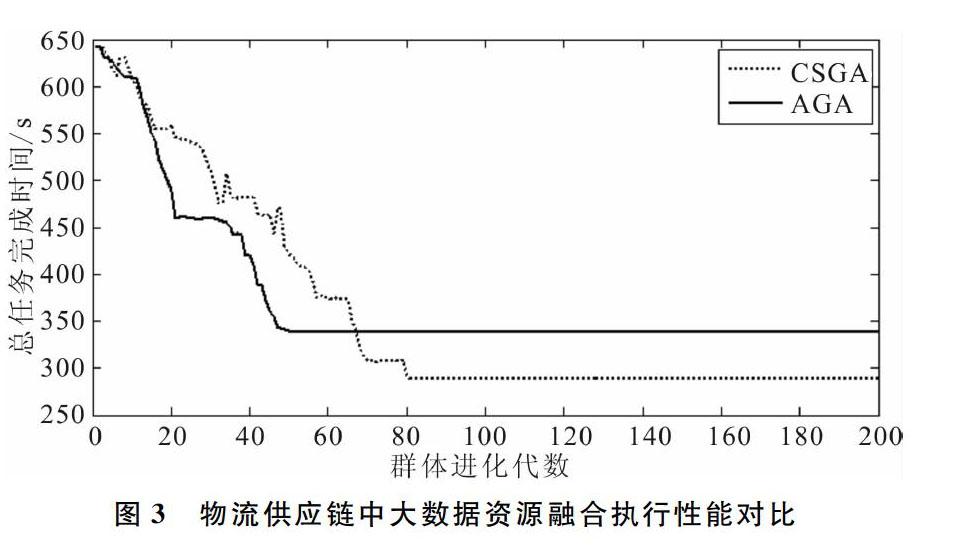
为了定量分析该算法的性能,采用本文方法和传统方法,以数据融合的执行时间为测试指标,得到对比结果如图3所示。仿真结果表明,利用该算法进行大数据资源融合的效率较高,配准性能较好,执行时较短,性能优越于传统算法。
需要对高维图像等多媒体数据进行降维度量与处理,同时分析出上下文环境的语义关联,最终从大量动态及模糊的数据中归纳概括信息,并导出可理解的内容。
本体通过对某领域概念及其关系的形式化表达来获得该领域知识,并提供对其的统一理解,确定公认词汇,从不同层次上明确定义词汇与词汇间的关系,进一步挖掘隐含在特定领域中的知识,解决各种语义障碍。1相关研究
目前已有大量关于语义相似度计算的研究。很多文章均提出了综合如结点类型、密度、深度、强度、属性、层次、边类型多种因素的计算模型,有的算法结合图理论和信息量提出了语义相似度度量方式。而邹文科、唐中林等则基于距离相似度和属性相似度来计算领域本体内部概念间的相似度。另外,也有将特征属性作为边权值来计算语义距离,并通过概念层次深度来校正计算结果。
当前基于本体的相似度算法大概存在两方面问题:①很多算法考虑尽量多的因素进行计算,但因素本身重要度不同,有的甚至无关紧要,这样反而增加了算法复杂度;②因素的重复利用不是很合理。为解决以上问题,本文提出以本体图驱动的概念相似度算法。2改进算法
本体包含概念、属性、关系、实例等,且本体结构类似有向无环图结构。因此,以本体为基础,可从语义、结构等多方面考虑相似度计算。概念相似度算法由3部分组成:语义相似度、结构相似度及属性相似度\即先将概念映射到本体树上,再综合计算概念间的3种相似度。
(1)语义相似度。在本体图结构中,结点与概念一一对应,由此可知:若结点有联系即概念相似,必然存在连接结点的通路;连接结点的通路上,经过的边数越多,概念间相似度越小;结点间关系类型不同,对相似度的影响也不同。
假设求概念CA、CB间的相似度,将CA、CB映射到本体图上,再找出两结点间的连通路径,如图1所示。
概念间语义相似度可由以下公式计算:
连通路径
0,路径不连通 (1)
其中,m指连接两结点间最短路径边数之和,ei指最短路径上第i条边,ωei指第i条边的关系权重。
(2)结构相似度——语义圆辐射计算模型。由本体结构可知,被比较的概念若存在相同或相似的邻居结点,则认为它们相似。因此,本算法采用“语义圆辐射模型”计算概念间的结构相似度。该模型以被比较概念结点为圆心,r为半径辐射出一个语义圆。在本体层次关系中,父子结点、兄弟结点占有重要位置,在此,r=1。在语义圆上的结点都是圆心结点的相似结点,如图2所示,CA、CB是被比较概念,O1是以CA为圆心的语义圆,O2是以CB为圆心的语义圆。
结构相似度计算如下:
其中,NCA(NCB)是在语义圆O1(O2)上的CA(CB)的邻居结点集合,|NCA∩NCB|是两集合交集大小,|NCA∪NCB|则是两集合并集大小。
(3)属性相似度——属性重心向量夹角计算模型。由本体概念可知,概念包含对象属性、数据类型属性及注释属性等多个属性。假设CA有n个属性,其属性集为(a1,a2,…,an),分别为各属性设定的权重值,得到概念CA的属性向量d=ω1,ω2,…,ωn,再以向量d各分量为顶点画多边形G,取G的重心M,此时,向量OM是概念CA的重心向量。同理,得到概念CB的重心向量ON,θ是向量OM、ON的夹角,如图3、图4所示。
如果两概念相同,则其对应的重心向量应是重合的,即两者夹角θ为0°;如果两概念相似,则对应的重心向量应存在一定角度,且随着概念间相似度的减小而增大。
概念相似度计算公式综合如下:
其中,α+β+γ=1,文中α=0.5,β=0.2,γ=0.3,当然3个参数的具体取值还有待修改验证。
3实验与结论
为了验证本算法的有效性,以植物本体\[14\]为依据,分别从相似度和算法时间复杂度两方面对比本文算法X、文献算法Y及文献算法Z,部分实验数据如表1所示。
综合实验数据及本文描述可知:
(1)总体上看本文算法X从相似度准确度及算法时间复杂度优于被比较算法Y和Z,因此,本算法具可行性及相应价值。
(2)算法X和Y对比说明,考虑参数越多,相似度准确度不一定越大。相反,算法的时间复杂度却随之增大,为此,在相似度计算中应理性对待各参数。
(3)算法X和Z对比说明,在利用本体计算相似度算法中,属性因素是重要的影响因素,在本文算法X中,属性重心向量夹角计算模型发挥了重要作用。
本文以本体图为驱动提出了概念相似度算法,由于算法中各种参数初始阈值的判定都依赖个人的主观思想,对相似度的精准度必定产生影响,因此,关于参数的取值还需进一步验证。
参考文献:
VIKTOR MAYER SCH,OUML,NBERGER.Big data:a revolution that will transform how we live, work, and think.盛扬燕,周涛,译.杭州:浙江人民出版社,2012.
黄果,周竹荣.基于领域本体的概念语义相似度计算研究[J].计算机工程与设计,2007,28(10):24602463.
史斌,闫健卓.基于本体的概念语义相似度度量[J].计算机工程,2009,35(19):8385.
兰美辉,夏幼明.基于本体的概念相似度计算模型研究[J].曲靖师范学院学报,2010,29(3):6770.
邹文科.基于本体技术的语义检索及其语义相似度研究.北京:北京邮电大学,2008.
陈沈焰,吴军华.基于本体的概念语义相似度计算及其应用[J].微电子学与计算机,2008,25(12):9699.
