某广电单位大数据平台架构设计
2016-05-14孟莲蓉
孟莲蓉
摘 要:某局的大数据平台架构设计中,共有12个组件。计算框架采用Lambda架构,同时管理实时计算框架和离线计算框架,数据经过数据采集服务初步验证过滤,记录到消息队列Kafka中,之后,同时进入到Hadoop和storm中分别用于离线和实时计算。
关键词:大数据平台 离线计算 Hadoop 实时计算 Storm Kafka Mongodb
中图分类号:TP27 文献标识码:A 文章编号:1672-3791(2016)03(a)-0006-03
某局期望实现设备运行数据、业务管理数据和各业务系统数据的规范传送、标准化整理和存储,建立全局统一的数据关系明确的主题数据库或数据仓库,为全局各应用系统提供规范的数据交换服务以及对基础数据的管理。主要任务是:建立全局数据中心,基于大数据云平台和两级数据交换中心,实现各级业务系统基础数据的统一规范化管理;初步实现全局设备及其状态以及运行质量、趋势、故障等的可视化分析建模及展示。该文主要阐述平台的架构设计。
1 大数据平台架构
BDM(Big Data Management,大数据管理平台)整体架构由下向上,从底层硬件逐步构建。
(1)硬件设施层:提供最基础的硬件系统。
(2)虚拟化层:在硬件设施层之上,将硬件资源虚拟化,将服务器集群资源统筹管理。
(3)数据存储层:完成海量数据的分布式存储。提供数据备份和容灾,采用Hadoop框架的HDFS分布式存储引擎、分布式消息队列Kafka、分布式文档型内存数据库和关系型数据库。
(4)数据服务层:包括,数据装载读写、数据分析处理编程框架和数据查询等。数据处理工具完成服务层与数据存储层间的数据交互,提供友好的数据操作界面。
(5)数据接口层:对外提供操作的相关接口。
2 BDM组件关系
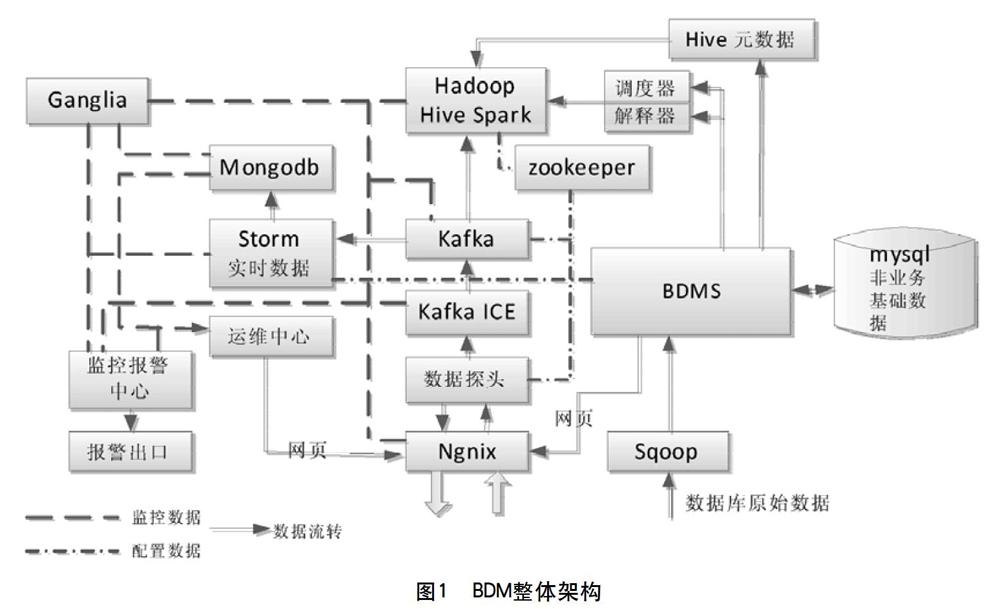
图1为该局BDM的整体架构,采用SOA(Service-Oriented Architecture)架构,其将具体功能以服务的形式部署在服务器集群上,每个服务以分布式方式部署,提供单独的高可用的服务,平台中的各系统都可以任意访问服务。BDM平台支持结构化数据(数据库表、结构化文本)、半结构化数据和非结构化数据。
数据经由Kafka写入到Hadoop HDFS,永久存储,进行离线计算;经由Kafka到达Storm流计算平台,进行实时计算和处理。
2.1 Nginx
Nginx是一个高性能的HTTP和反向代理服务器,是BDM中统一的HTTP请求的转发入口,需两台服务器集群互为备份和负载均衡。它接收用户的HTTP接口调用浏览器访问,将请求转发到OMCenter网页、BDMS网页、数据查询、REST接口和数据探头等。
2.2 分布式集群协作管理Zookeeper
Zookeeper是集群协作管理中心,提供集群协调功能,保存集群运行状态和配置信息并同步到集群各个系统,组件包括:数据采集服务、Storm、 Hadoop和Kafka等。Zookeeper作为集群的配置中心,在多台zookeeper服务器之间,保证数据强一致性,实现了Paxos算法,完成数据在节点之间存储一致的状态,在部署zookeeper集群的时候,一般使用3台集群或5台集群。 Zookeeper在部署完成后即拥有高容错功能,一个zookeeper节点故障,并不影响整体集群的服务功能,这个节点重启就可以恢复数据,并恢复正常状态。集群协作管理的方式有如下几种。
(1)在zookeeper中保存集群中每个服务器地址及其提供的对应服务。
(2)客户端从zookeeper中获取集群中提供服务的具体实例地址和具体服务通信。
(3)集群状态发生变化时,更新zookeeper内容,即时通知客户端。
(4) zookeeper保存并分析服务的运行状态,发送监控信息和报警信息。
2.3 Kafka
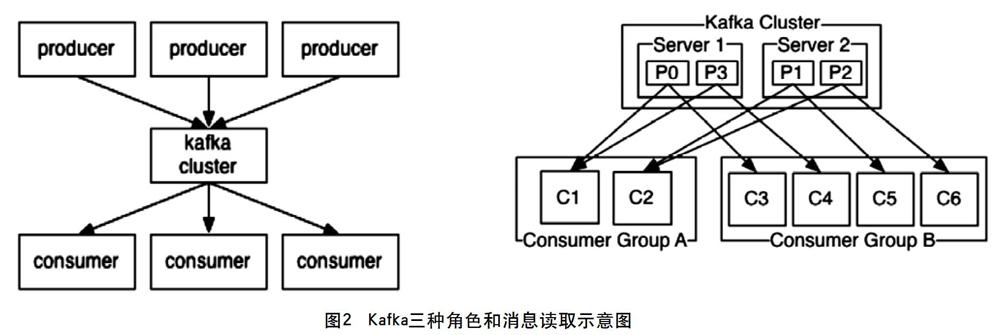
Kafka集群有三种角色(如图2):Producer是数据的发布者,向消息队列推送数据;Consumer是数据的订阅者,从消息队列订阅数据并消费;Broker是消息队列实体和集群中的Server。Kafka指定各个分区到对应的读取进程,因此保证每个进程读取数据的顺序性和负载均衡。
Kafka消息读取的方式如图2。它可以同时处理多个逻辑队列,每个队列用一个Topic名称进行唯一标识,即一个Topic确定一个逻辑队列。每个逻辑队列分成多个分区(Partition),图中为Kafka Cluster的P0~P2,每个分区分散存储于服务器上,数据写入kafka时,轮询写入每个分区。数据的消费者,分多组(Consumer Group)同时读取数据,每组都可读取到队列中完整的数据,两组之间不会相互影响。
2.4 Kafka ICE服务
ICE(Internet Communications Engine),是一个分布式计算框架和RPC框架,方便各服务读写kafka数据。ICE Grid服务端包含Registry,Registry Replica,Node和服务:
(1)Registry:ICE Grid的服务注册中心、配置中心,其中保存了所有节点状态、服务状态、服务地址和端口及服务RPC API的元数据等。
(2)Registry Replica是Registry的热备服务。
(3)Node:ICE Grid通过Node服务管理节点上运行的服务的启停,一个服务可注册在一个或多个节点运行,服务进程通过Node进程创建。
(4)服务:通过ICE Grid框架定义。在BDM中,数据探头和Kafka ICE都是通过ICE实现的。一个节点可启动多个服务进程,每个服务进程可以配置成多线程方式。
(5)客户端:客户端通过服务定义的slice文件,通过RPC的方式和服务端通信,完成API调用。Registry根据一定的规则,将服务地址分配给客户端,分配策略有轮询、随机和根据负载分配的方式。
2.5 数据探头
数据探头服务采集和接收推送数据,并发送到Kafka,数据经过Nginx,uwsgi,Input ICE,Kafka ICE到达Kafka。Input ICE服务提供了动态API配置的功能。
2.6 Mysql
Mysql作为BDMS的后台数据库,也作为基础数据管理和关系型数据库部分数据的存储。 BDM中Mysql集群,使用主备方式部署(Master-Slave),备机提供数据的只读服务,主机提供数据的读写服务。
2.7 Storm
Storm是BDM中的实时处理平台,完成实时统计、计算和数据处理等。Storm集群分为主控节点Nimbus和工作节点Supervisor,Nimbus负责任务的总控,管理所有工作节点的状态;Supervisor负责接受并执行任务。
Storm会保证数据在计算任务中都被处理过一次(至少一次),如果处理发生异常,这条数据会被重新发送,保证每条数据都会被正确处理。Storm在记录消息处理情况的时候,只有数据完全经过所有节点的时候,数据才会被认为正常处理完成。该项目中,可使用Storm完成实时指标计算,如,全局设备实时运行时长统计、设备实时状态分析等。
2.8 分布式文档型数据库Mongodb
Mongodb是文档对象数据库,是一种NoSQL数据库,每一条数据是一个“文档”,一个文档是一个json格式的数据,由于json格式数据的特点,Mongodb没有关系型数据库的外键和关联等概念,对于有嵌套关系的数据,可以直接存储到一条记录中。Mongodb支持集群部署方式和自动故障恢复。Mongodb高可用部署方式为Replica Set(副本集),其中Primary为主节点,数据的读写操作都在Primary上执行,两个Secondary服务器从Primary同步数据并作为热备,这3个节点之间通过心跳信号通信,确认彼此服务处于存活状态。
当Primary出现故障时,主的心跳信号丢失,此时,两个Secondary节点中的一个节点作为Primary,客户端和新的Primary节点进行操作。故障节点恢复后,重新加入集群,并作为新的备节点,开始数据同步。
在BDM中,Storm从Kafka读取实时采集的数据,完成计算后,将计算结果输出到Mongodb存储,使用方读取Mongodb结果获取实时计算报表。
2.9 BDMS大数据建模平台
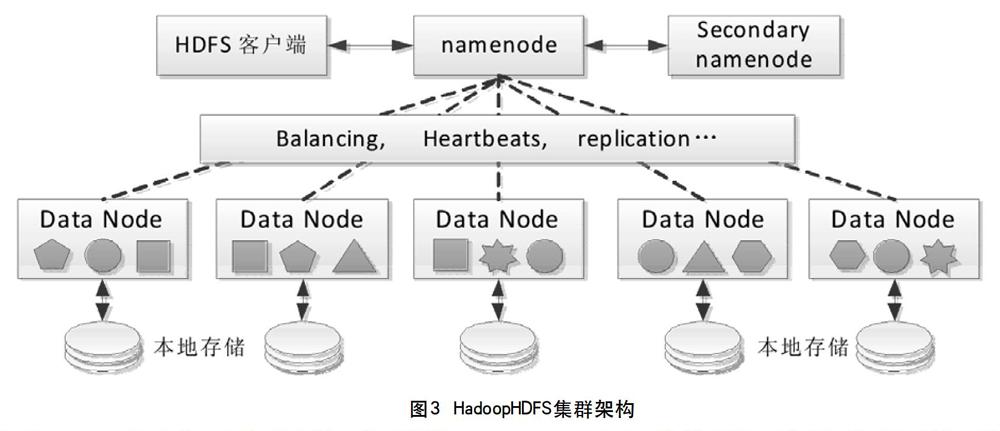
BDMS大数据建模平台是基于Hadoop、Hive、sqoop等hadoop生态系统中的工具整合开发的可视化大数据离线计算、数据分析和建模平台。基础的Hadoop平台提供HDFS分布式数据存储和MapReduce计算框架,使得大量数据的分布式计算成为可能。存储文件分成多个Block(块),默认大小是64M。通过块的Replica的方式,保证数据可靠性,读取速度和吞吐量。一般每个块至少分布到3个DataNode节点上。如图3,NameNode负责维护集群的元数据,DataNode用来存放数据块,每个数据块都有3个备份,分散存储于各个DataNode上,任意一个DataNode故障,数据块的副本不会丢失;同时,为防止NameNode单点故障,引入了Secondary NameNode的备份节点。Hadoop HDFS上的数据读写,始终都采用就近原则,优先使用本地的数据块,以提升数据读取的速度。
Hadoop平台为BDMS提供基础的数据存储和计算框架,单纯MapReduce框架应用复杂,因此Hive平台提供了结构化数据的管理和查询功能。Hive使用类SQL语言,完成对Hadoop上存储的数据进行查询。Hive将SQL语言解析成为MapReduce任务在Hadoop平台上执行,更适合于海量数据的SQL查询。BDMS还提供了Hadoop平台上的其它功能,如,SparkMLL机器学习库,sqoop数据装载工具等,为数据的采集、清洗、格式化、查询、建模、计算、分析、报表产出等一系列流程提供可视化工作界面。
2.10 集群监控中心ganglia
Ganglia是BDM的服务器集群监控中心,它收集每个节点的服务器运行状态和服务运行状态,完成运行状态的实时监控图标绘制,图标的数据保存为rrd格式,可在使用较小磁盘容量的情况下,记录多年的历史数据。
3 结语
除了上述的各个组件,大数据平台还配备报警中心和运维管理中心,报警中心完成对BDM中关键服务组件运行状态的监控报警和对数据处理任务的监控报警;运维中心OMCenter为BDM提供一站式私有云管理软件、集成设备管理、服务管理、监控、实时报表和配置中心等。目前,BDM已经运行了一年左右,体现了其应有的作用。
参考文献
[1] 张戈.浅谈广电网络的信息化建设[J].科技致富向导,2014(26):80,172.
[2] 任磊,杜一,马帅,等.大数据可视分析综述[J].软件学报,2014(9):1909-1936.
