基于喜好标签的移动互联网用户行为分类研究
2016-05-14钟庆
钟庆
【摘 要】提出一种基于移动互联网个体用户的实际行为得出其喜好标签,据此将同类信息推送给个体用户的方法,该方法能够实现精确推送,因此推送的内容更加容易被用户接受,从而商业价值性价比更高。首先阐述了个体用户实际行为数据的提取方法,比较了各方法的优缺点;其次提出了一种固定质心的k-means文本聚类方法,能够快速、准确地实现用户喜好标签分类;最后分析了精确营销模式以及后续的研究方向。
【关键词】喜好标签 移动互联网 用户行为分析 文本聚类 精确营销
中图分类号:TP301.6 文献标志码:A 文章编号:1006-1010(2016)09-0093-04
1 引言
近年来,随着智能移动终端的基本普及,移动互联网[1]发展迅猛,在人们的衣食住行中无时无刻不扮演着重要角色,可以说移动互联网正在或者已经改变了人们的生活方式。移动互联网有两个特点:一是移动通信与互联网二者融合,即用户可以通过移动终端和互联网实现随时互联;二是大批应用伴随移动互联网而产生,这些应用与移动终端的可移动性、可便携性相结合,随时为用户提供个性化服务[2]。用户可以通过移动互联网实现实时的信息接收、发送和交互等。运营商和各大电商们也充分抓住这个机会,利用移动互联网通道,将大量的信息资源推送给群体用户,而对于个体用户而言,由于这种信息推送没有针对性,在反复收到海量信息后,心理上会造成疲劳甚至是反感。另一方面,个体用户在寻找自己喜欢或者希望获得的信息资源时又很困难。因此,根据移动互联网个体用户的实际行为,分析出其喜好标签,从而实现信息精确推送,可以有效地解决这一问题,这既能为运营商和电商们发掘潜在用户,又能改善个体用户的体验,最终实现双赢。
早期对互联网用户行为的分析[3]比较多,方法也比较成熟,已经形成基本的网络特性,这种用户行为研究偏向于探究个体用户的上网意图,比如:浏览网页的频率、停留的时间、网页的分类等。但是目前对于移动互联网用户行为的分析方法还不够成熟,尤其是国内,对在该方面的研究成果非常有限。本文主要阐述了一种基于喜好标签的移动互联网用户行为分类方法,该方法从微观角度,根据个体用户对于移动互联网的实际使用数据,得到用户的喜好标签,从而达到用户分类的目的。在这个过程中,列举了几种典型的移动互联网原始数据获取方法,分析了各方法的优缺点,进而通过聚类算法,将原始数据进行文本聚类,从而得到用户分类的结果。最后还阐述了该方法的应用远景以及对其商业价值的预判。
2 数据获取
移动互联网体系包括3个层面:移动终端、移动网络和应用服务。首先针对移动互联网的应用服务层进行原始数据收集。移动互联网的数据获取方式大致分为两种,一种是基于WAP(Wireless Application Protocol,无线应用通讯协议)网关的采集,另一种是基于网络交换机数据包的采集。
WAP网关是承载移动数据业务的关键网元,起到了数据业务统一接入的作用,因此WAP网关是移动终端连接移动互联网的重要枢纽[4]。基于WAP网关进行移动互联网数据采集是通过WAP网关的自带功能,将WAP协议下的数据分成多个详细字段,将这些字段数据信息进行一次日志化。由于这些都是原始数据,包含很多冗余信息,这样会使用户行为的分类不够准确,从而导致最终分类错误,因此需要利用信息过滤程序对原始数据进行信息过滤,形成最终具有固定模式的有效数据集,最后再将这些真正有价值的信息写进日志文件,即可完成数据采集。这种数据获取方法的优点是简单方便,利用WAP网关自带功能即可完成对原始数据的采集;另一方面,这种采集方式也是基于用户请求的应用层协议,不会把底层的数据全部采集过来,简化了过滤过程。由于此处数据获取是为最终的用户行为分类做准备,因此需要尽量多地获取数据,但无需全部获取,对于加密型WAP协议等,可以只获取通道途径,无需获取实际内容。
网络交换机是一种用于扩大网络的器材,能够为子网络提供连接的通道。随着互联网逐渐成为当今越来越重要的局域网组网技术,网络交换机也成为了最普及的交换机[5]。基于网络交换机数据包的采集方法是利用网络数据包捕获应用,将需要的网络数据捕获、过滤,从而完成数据采集。具体过程是在网络交换机上放置一种数据包采集应用,将流过该网络交换机的所有数据中属于个体用户的数据包识别并捕获,构成原始数据集,然后经过信息过滤程序、文件重组等过程,形成最终的有效数据集。这种方法的缺点是设置过滤条件比较困难,需要调用一些库函数等工具,并且设置过程也比较复杂。
3 数据分析
在数据获取的基础上,利用文本聚类的方法,对有效数据进行分析,最终达到用户分类的目的。
计算机处理无结构的词语文本比较困难,通常采用的方法是利用VSM(Vector Space Model,向量空间模型)在预处理的基础上,将词语文本描述成为一个N维特征空间中的一个N维向量,进而通过对向量的科学计算实现词语文本的分类。文本聚类[6]的主要依据是认为同类的文本相似度大,不同类的文本相似度小,进而将同类文本聚集到一起,得到聚类结果。目前比较主流的文本聚类算法包括基于划分法、基于层次法、基于密度法、基于网格法和基于模型法等。文本聚类被广泛地应用于搜索引擎、信息处理等领域[7]。
针对移动互联网个体用户喜好标签的文本分类,可以先设定K个喜好标签(比如社交、购物、读书、游戏等),以这些标签作为聚类核心,将采集到的用户数据进行聚类,得到个体用户的分类结果。本文在K-means经典算法的基础上,增加对移动互联网个体用户喜好分类的特性,提出一种固定质心的文本聚类数据分析方法。K-means算法[8]是一种典型的基于划分的方法,属于一种基于质心的聚类技术,其基本原理是从n个数据对象中任意选择k个对象作为初始的聚类点,对于其他对象,根据他们与这些聚类点的相似度(距离),将他们分配给与其最相似的簇,然后重新计算簇的平均值,更新聚类点,重复这一过程,直到簇的划分不再发生变化。这种文本聚类方法的优点是简单易行并且能够处理大规模的数据集。但同时该算法的缺点也比较明显,即容易陷入局部最小,很难保证全局最优,而且初始聚类点的选择和k值的设定会在很大程度上影响最终的聚类效果。因此针对个体用户喜好分类的特性,采用固定质心的方式,即将最终的喜好分类标签指定为初始的聚类点和k值,然后进行聚类,这样不仅可以实现分类最优,而且简化了算法、提高了效率。
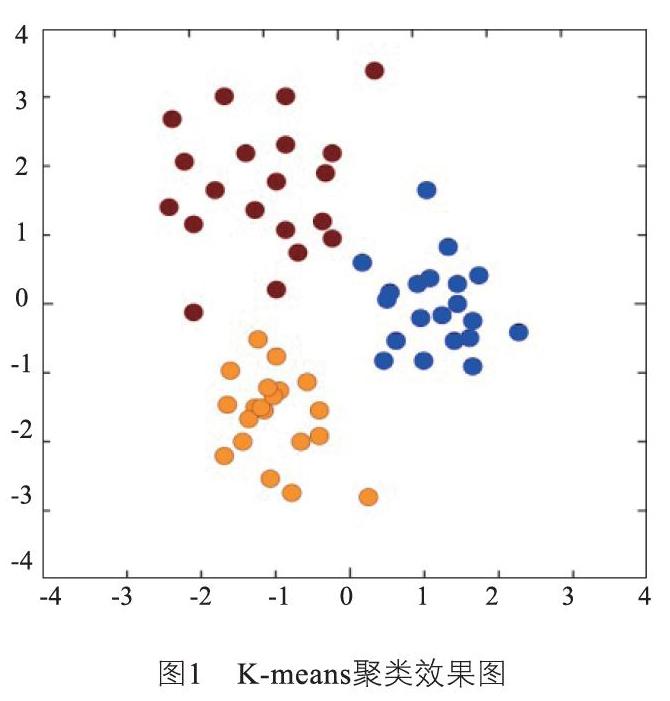
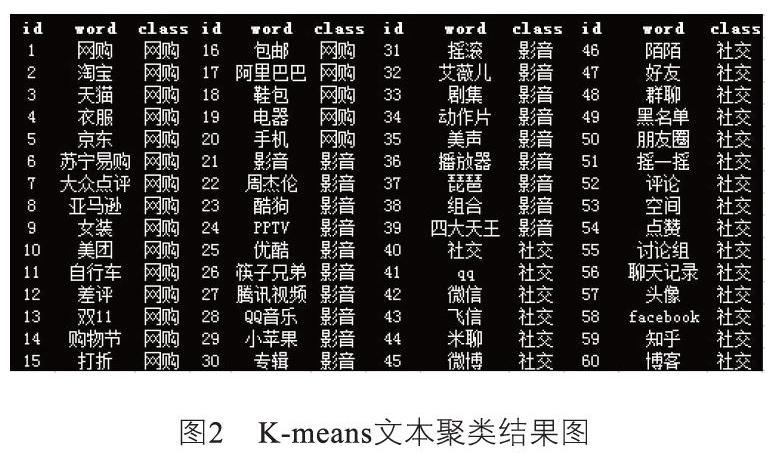
为验证算法效果,采用60个原始文本集(优酷、群聊、淘宝等),以“网购、影音和社交”作为初始聚类点(k值取3),利用K-means算法进行文本聚类,效果如图1、图2所示:
由上述示例可以看出,本文提出的简化K-means算法能够较好地实现文本分类。
4 商业模式
人可以控制自己的消费意图,但是极易受到外部的影响,所以商家通过推送大量的信息来尽量引导用户消费。而通过对用户的实际行为进行标签分类,推送用户最可能喜欢或者最想得到的信息,更容易被用户所接受,可以更高效地产生商业价值。对于个体用户的区分,实际上是精确营销[9]的理念,精确营销是相对于大众营销而言的,大众营销是典型的产品导向方式,就是使用同样的营销组合,含糊不清地针对每一个顾客。大众营销假设每一个人都是相同的,并且认为每一个人都是潜在顾客,试图把产品卖给每一个人。在移动互联网时代,这种大众营销集中体现在群推信息,但由于没有针对性,前期投入很大,效果却达不到预期。而精确营销是在充分了解顾客信息的基础上,针对顾客偏好,有针对性地进行一对一的营销。精确营销是由直复营销、数据库营销等多种手段相互结合[10],但前提是掌握精确的营销信息。因此,本文中阐述的利用个体用户的具体实际行为数据进行收集,针对这些数据进行喜好标签的分类分析,得到用户最喜欢或最有可能需要的信息进行推送的方式,实现了精确营销。这不仅可以帮助商家节省推广成本,更能改善用户体验,帮助用户摆脱海量信息轰炸的烦恼,可轻松快速地找到自己需要的信息,最终实现双赢。
后续工作可以在用户喜好分类的基础上,打破单一的分类模式,对喜好标签做权重分配排序,得到个体用户的喜好标签序列,按照权重推送用户可能需要的信息。同时可以将信息进行分类,用户可以根据自身需求,自主选择需要的信息类别,然后查找具体的信息内容,从而充分发挥用户的主观能动性,提高信息采用率。
5 结束语
在移动互联网时代,实现信息的有效推送,既可以提高用户感知,又能够缩减商家的推销成本。本文通过有效的数据采集方法,获取个体用户的实际行为数据,在此基础上,对数据进行聚类分析,得到用户的喜好标签分类。后续引入精确营销的概念,针对喜好标签的分类结果进行相关信息的准确推送。最后提出优化方案,将喜好标签做权重分配排序,按照权重进行信息的层次化推送,或在信息分类的基础上,帮助用户实现自主选择。
参考文献:
[1] 吴吉义,李文娟,黄剑平,等. 移动互联网研究综述[J]. 中国科学: 信息科学, 2015,45(1): 30-36.
[2] 中国工业和信息化部电信研究院. 移动互联网白皮书[EB/OL]. [2016-01-24]. http://wenku.baidu.com/link?url=sn5w0sXSannzh3hYnxKJoAhz7uZOpdFinanla_j26c2cpjt0ASZ3ESHCfkmWJ0mlFDBIcMrY7hs6tWHuVDKgur9NaPgJU4OqMdnvD5sueVO.
[3] 董富强. 网络用户行为分析研究及其应用[D]. 西安: 西安电子科技大学, 2005.
[4] 钟磊,张健. WAP网关在移动网络业务中的应用分析[J]. 广西通信技术, 2012(1): 6-9.
[5] 王璐. 移动互联网用户行为分析[D]. 重庆: 重庆邮电大学, 2012.
[6] 吴启明,易云飞. 文本聚类综述[J]. 河池学院学报, 2008,28(2): 86-91.
[7] 李春青. 文本聚类算法研究[J]. 软件导刊, 2015(1): 74-76.
[8] Anil K J. Data clustering: 50 years beyond K-Means[J]. Pattern Recognition Letters, 2010,31(8): 651-666.
[9] Zabin J, Brebach G. Precision Marketing[M]. Mass Marketing, 2004.
[10] 吕巍. 精确营销[M]. 北京: 机械工业出版社, 2008.
