文件秒传系统在云存储环境下的设计与实现
2016-05-09胡渝苹
胡 渝 苹
文件秒传系统在云存储环境下的设计与实现
胡 渝 苹
(重庆水利电力职业技术学院 重庆 402160)
针对云存储环境下用户数据上传速度慢的问题,设计一个文件秒传系统FSTS(File Second Transmission System)。该系统基于云存储服务器充足的数据资源,建立元数据资源库,通过将文件设计为资源共享的方式实现数据秒传,元数据资源库将云存储服务器上的数据通过唯一标识数据内容的字段组织起来, 以此来保证该资源库中没有重复的数据。用户在上传数据到云存储服务器时,如果该数据的唯一标识已经存在于元数据资源库,那么只需要增加该记录的引用计数即可完成用户数据的上传,而无需通过网络传输数据的任何内容,即实现了文件的逻辑上传,并且保证了对数据的后续操作都是正常的。实验结果表明,该文件秒传系统可以很好地提高数据的上传速度以及提高云存储服务器存储空间的利用率,该方案在云存储环境下是可行的、有效的。
文件秒传 云存储 元数据 引用计数
0 引 言
云计算已经广泛地应用到了各行各业,云存储也随之得到了更加广泛的关注与应用[1]。用户在使用云存储服务时,不仅关注数据的安全性、可靠性、容灾备份、可用性等,而且对数据的上传速度以及数据的下载速度也有一定的要求[2],当然是数据上传速度越快越好。每个用户都希望自己的数据可以更快更安全地上传到云端存储服务器,但是,限于网络传输速度、带宽、磁盘读取速度、云端存储速度等限制,使得用户的数据迟迟无法完成上传功能[3,4]。如果网络环境较差的话,对于几百MB大小的文件来说,都有可能消耗几个小时甚至几十个小时的传输时间,这对用户来说,是无法接受的。如何提高在现有的使用环境下用户数据的上传速度,是一个十分棘手的问题[5]。
文件秒传系统就是为了最大限度地解决数据上传速度慢的问题,它采用各种手段来实现数据的快速上传。现有的解决方案主要是通过数据分割、数据内部复制、多线程并行处理等手段实现文件快速上传的。文献[6]通过将文件分成多个不相交的数据段,采用多进程实现文件的并行上传;文献[7]采用了按照固定长度分割文件,然后依次判断每个长度区间在服务器是否已经存在,如果存在则通过服务器内部实现数据复制,如果不存在,则通过单进程实现该数据块的上传;文献[8]采用通过设计分布式服务器,将文件分割成多个数据块,分别上传至不同的服务器上;文献[9]实现了数据块的判重功能,将重复的数据块由服务器内部实现复制以模拟上传功能,对于不重复的数据块,采用多线程完成上传。这些解决方案在一定程度上可以加速文件上传的速度,但是,并不能从根本上解决问题,它仍极大地依赖于磁盘转速、网络速度、带宽等因素[10]。在这些方案中,无法排除服务器端重复的文件,在海量数据情况下,服务器端的文件大量重复,会造成大量的空间浪费[11]。
为了解决用户上传文件速度受限的问题,提高用户上传文件的速度。本文充分利用云存储的优势,即大数据,设计了一个快速存储系统,让用户的某些数据可以在极短的时间内完成上传工作,本文称这种设计为基于大数据的文件秒传系统FSTS。
1 FSTS的设计与实现
FSTS是本文设计的一种实现文件秒传功能的系统,这种系统可以让用户在极短的时间内完成数据上传的功能。这种系统的实现需要有海量的数据为基础,这些数据将用来作为用户的数据备用库。
本文设计的FSTS是基于云存储的大数据而存在的,它依赖于云存储环境,并且该系统的效率与云存储的数据存在有很大的关系。用户上传数据的操作能否在极短的时间内完成,取决于该数据在云存储系统中是否存在。
本文将对FSTS系统的设计与实现作详细介绍,具体包括:总体的设计方案、元数据的存储设计方案、文件上传流程设计、文件下载流程设计、文件删除流程设计以及文件清理方案设计等。
1.1 总体架构设计
FSTS的总体设计方案如图1所示。从图1可以看出,FSTS主要组成部分有Client、MySQL-View Cluster、MySQL-Metadata Cluster、负载均衡系统、Cache存储服务器、分布式存储HDFS(Hadoop Distributed File System)六部分构成。

图1 FSTS总体架构设计
其中Client是客户端部分,用户通过Client提供的接口完成数据的上传、下载、删除等功能,通过TCP/IP协议与服务器进行安全可靠的交互工作,是服务器提供给用户的唯一接口;MySQL-View Cluster是用户视图存储服务器集群,该集群使用MySQL数据库存储数据,该集群通过负载均衡系统统一调度,用来存储用户数据的元数据;MySQL-Metadata Cluster是云存储系统存储服务器集群,该集群使用MySQL数据库存储数据,该集群通过负载均衡系统统一调度,用来存储云存储端的所有数据的元数据;负载均衡系统用来统一调度用户请求,将用户请求调配到对应的服务器上;Cache存储服务器用来缓存HDFS中的数据,加速响应用户请求,为用户请求提供更快的读写效率;分布式存储HDFS是分布式文件系统,用来备份数据,保证数据的多副本备份,提高数据安全性,并用来集中管理海量的数据文件,为系统功能的实现提供有力的数据资源保障。
1.2 元数据存储方案设计
用户上传数据到云存储服务器,云存储服务器就要保证用户可以随时从云存储服务器读取数据,元数据就起到了这个作用。它需要保存用户数据在云存储服务器中的位置,通过这个位置可以读取对应的数据,元数据的设计如图2所示。该元数据存储方案涉及到两个元数据的存储,用户元数据以及云存储端元数据,都以集群的形式存储。

图2 元数据存储设计
MySQL-View Cluster是用来保存用户数据元数据的一个MySQL集群,它将用户数据的众多属性保存在MySQL数据库中。为了保证系统的高可扩展性,MySQL以集群的形式存在。在该数据库中,有两个主要的字段跟用户数据的秒传功能实现有着重要的联系,即用户上传的文件名file_name、用户数据在云存储服务器中的唯一标识符id_symbol。用户请求自己的文件file_name时,系统就将id_symbol转换为file_path,file_path就可将所指的文件返回给用户。
MySQL-Metadata Cluster是用来存储HDFS中的每个文件信息的数据库集群。同样使用MySQL集群的形式,也是为了系统的高可扩展性,在该数据库中有三个主要的字段,即数据在云存储服务器中的唯一标识符id_symbol、云存储服务器中的真实路径file_path、文件被引用的次数referenced_count。这个数据库会记录每个文件被所有的用户引用的次数,以模拟被多个用户使用。
MySQL-Metadata Cluster中的id_symbol和file _path字段都是系统中数据的唯一存在。id_symbol被设计为MySQL-View Cluster中数据库的外码,是两个数据库集群的联系所在。
1.3 文件上传方案设计
FSTS系统的优势就在于可以将对应的用户数据极速地上传到云存储服务器上,并且相同的文件在云存储服务器端只有一份,大大节省了云存储服务器的存储空间。文件上传流程的设计如图3所示。从图3可以知道,如果一个文件已经存在于云存储服务器上,那么这个文件将可以瞬间完成上传功能。并且云存储服务器只需要增加一个MySQL-Metadata Cluster中的一个引用计数就可以了,无需重复读写数据。
文件上传的步骤设计为:
(2) 服务器从MySQL-Metadata Cluster中查找该标识符;如果找到,则转(3),否则,转(4);
(3) 将MySQL-Metadata Cluster中对应记录的引用计数加1,转(9);
(4) 负载均衡服务器找到该文件应该上传至的Cache服务器信息,将该Cache服务器的信息返回给用户;
(5) 用户与对应的Cache服务器建立连接,请求将文件上传至该服务器上;
(6) 文件传输过程,将用户数据完整的上传到对应的Cache服务器;
(7) 将Cache服务器上的用户数据持久化上传到HDFS上,以保证数据安全;
(8) 将用户数据的元数据记录至MySQL-Metadata Cluster;
(9) 将用户数据的元数据记录至MySQL-View Cluster;
(10) 用户数据秒传成功。
从上传流程上可以看出,只要用户上传的数据文件已经存在于云存储服务器端,那么用户数据就可以瞬间完成上传任务。只有该文件不存在于云存储服务器端时,才需要经过网络传输将数据逐渐地上传至云存储服务器端。
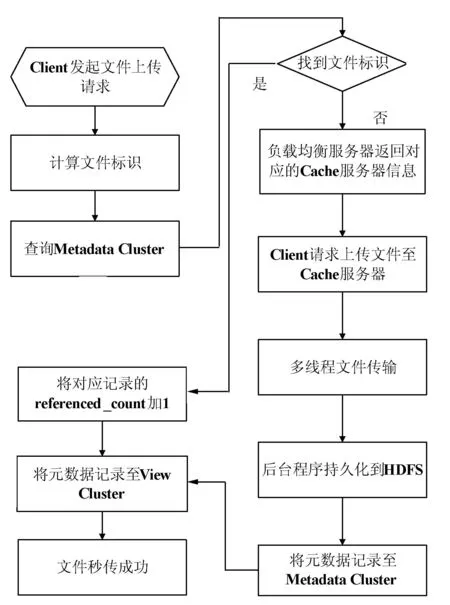
图3 文件上传流程设计
1.4 文件下载方案设计
FSTS的最大优势在于将数据快速上传,对于数据下载并没有太大的优势,但是,FSTS系统并不会因此就增加数据下载的负担。实际上,由于数据在云存储服务器上没有重复的存在,所以减轻了云存储服务器上数据存储负担,可以在一定程度上加快数据的传输速度。文件下载方案的设计如图4所示。

图4 文件下载流程设计
文件下载的步骤设计如下:
(1) 客户端发起文件下载请求;
(2) 负载均衡服务器找到对应的Cache服务器;
(3) 判断文件是否存在于该Cache服务器,如果存在,则转(7),如果不存在,则转(4);
(4) 查找View Cluster元数据服务器,从而找到对应的id_symbol;
(5) 根据id_symbol,查找Metadata Cluster,找到对应的file_path;
(6) 根据file_path从HDFS中将数据copy到该Cache服务器;
(7) 返回给客户端该Cache服务器信息;
(8) 客户端从Cache读取需要的文件;
(9) 文件下载完成。
从文件下载流程看,文件下载需要按照用户请求,逐步地完成数据传输,并没有什么有效的方法可以大大减少下载时间。但是,由于Cache服务器的存在,用户比直接从HDFS读取数据要快很多,在一定程度上提高了用户读取数据的速度。
1.5 文件删除方案设计

图5 文件删除流程设计
文件删除发生在用户不想在云存储服务器上保存自己的数据时,为了及时地响应用户请求,本文将数据删除设计为逻辑删除,即只需要在用户数据记录上标记为已删除即可,并不会实际删除数据元数据记录以及实际存储在服务器上的数据。实际的删除操作由系统后台进程执行,对用户透明。文件删除流程的设计如图5所示。从图5可以看出,删除流程相当简单,相应的操作都效率极高,可以说,用户在瞬间即可完成删除操作,不需要任何等待。
文件删除流程步骤设计如下:
(1) 客户端发起文件删除的请求;
(2) 服务器将View Cluster中对应的记录标记为已删除;
(3) 服务器将Metadata Cluster中对应的记录的引用计数减少1;
(4) 对客户端来说,文件删除成功。
从文件的删除流程可以看出,服务器并没有做任何删除操作,只是将相应的记录标记为已删除和减少引用计数。
1.6 文件清理方案设计
本文将用户的数据删除方案设计为了逻辑删除,即实际的数据元数据和实际的数据并没有从服务器删除。对系统而言,有些数据已经没有任何必要存储在服务器上,如已经被标记为已删除的记录。当系统容量达到一定程度时,我们就需要清理系统,以便可以响应其他的用户请求,即还需要清理长久没有使用并且没人占用的数据,以给系统腾出足够的空间。文件清理方案设计如图6所示。
从图6可以看出,已经被标记为已删除的记录一定会被物理删除。引用计数0的记录,只有在最近一段时间未被访问并且系统空间不足时,才会被物理删除。这种设计方案可以在不损耗系统秒传性能的前提下完成系统节省空间的功能。

图6 文件清理方案设计
文件清理方案流程步骤设计如下:
(1) 周期性的启动后台清理程序;
(2) 遍历View Cluster数据库中被标记为已删除的记录;
(3) 清理对应的缓存文件;
(4) 删除对应的记录;
(5) 遍历Metadata Cluster数据库中引用计数为0的记录;
(6) 如果该记录对应的文件最近访问时间大于N,并且系统的存储空间被使用的比例大于M,则删除文件,否则,不做物理删除操作;
(7) 结束。
从文件清理的步骤设计上看,只有文件的引用计数为0,并且最近一段时间N时间内没有被访问过,才有资格被物理删除。为了保证云存储空间中数据的多样性,只有当物理空间被使用的比例大于M时,才会实际删除物理文件,否则,不做物理删除。
这样设计物理文件的删除是因为被用户删除的文件,在View Cluster中的记录已经没有任何价值,所以直接物理删除;在Metadata Cluster中的记录如果引用计数不为0,则表示有用户在使用该文件,不能删除;当引用计数为0时,如果最近一段时间被访问过,那么表示在将来还有可能被访问,为了实现用户更多的秒传,该文件继续保留在系统中;如果云存储系统被使用的比例比较低,则该文件也继续保留在系统中,因为删除该文件只能让系统的利用率更加低下,留着该文件,还有可能为以后用户上传文件提供高效的秒传功能。
2 实验与分析
为了验证本文设计的秒传系统的可用性与高效性,本实验在开启秒传与关闭秒传功能的前提下,分别统计上传、下载、删除等操作的操作时间以及系统中元数据记录情况。
2.1 实验设计
本实验模拟三个用户分别对同一个文件进行操作,让云存储服务器上的数据经历从无到有,在无数据以及有数据的情况下,统计各自的操作时间。
2.1.1 实验环境
为了简化实验环境,但尽可能模拟真实的应用环境,本实验搭建了HDFS集群,并部署了两台Cache服务器,搭建了两个MySQL集群,分别用来模拟MySQL-Metadata Cluster以及MySQL-View Cluster。在同台设备上,通过修改客户端ID,先后启动多次客户端,用来模拟三个客户,进行不同的文件操作。
2.1.2 实验步骤
搭建完毕实验环境,本实验将实验步骤设计如下:
(1) 开启秒传功能;
(2) 配置客户端ID为1,启动客户端;
(3) 将文件file上传至云存储服务器,记录上传时间;
(4) 从云存储服务器下载该文件,记录下载时间;
(5) 将文件从云存储服务器删除,记录删除时间;
(6) 查看服务器上的文件数目,并连同上述记录的时间一起填入表1的第一行记录中;
(7) 配置客户端ID为2,启动客户端;
(8) 重复执行步骤(2)-步骤(4);
(9) 将记录的时间填入表1的第二行记录中;
(10) 配置客户端ID为3,启动客户端;
(11) 将文件重命名;
(12) 重复执行步骤(3)-步骤(5);
(13) 将记录的时间填入表1的第三行记录中;
(14) 关闭秒传功能;
(15) 重复执行步骤(2)-步骤(13),只是将所有的数据记录在表2中,而不是表1中。
2.2 实验结果与分析
执行上述实验步骤,得到的实验数据如表1和表2所示。其中,在每个表中,记录1是客户端1的操作时间记录,记录2是客户端2的操作时间记录,记录3是客户端3的操作时间记录。

表1 开启秒传功能时操作时间记录(单位:min)

表2 关闭秒传功能时操作时间记录(单位:min)
从表1可以看出,记录1的上传时间为39 min,而记录2和记录3的上传时间只有2 min,记录1的上传时间远远大于记录2和记录3的上传时间;记录1和记录2、记录3的文件下载时间分别为33、36和34 min,时间大小差距不大,可以认为是效率相当;记录1、记录2和记录3的文件删除时间都小于1 min,删除效率都差不多,效率都很高。
表1中,记录1的上传时间远大于记录2的上传时间,是因为客户端1在上传文件时,该文件在服务器中并没有相同的文件存在,数据必须逐渐地上传至服务器上;而记录2时间很短是因为客户端1上传的文件在服务器上还没有被物理删除,对应的Metadata Cluster中还有记录存在,所以客户端的物理文件就不用再上传至服务器端,而只需要增加Metadata Cluster中对应记录的引用计数即可。
表1中,客户端3操作的是重命名后的文件,它的操作时间与客户端2的操作时间没有较大差别,几乎相同。这说明,单纯地修改文件名,只要文件内容相同,也是可以做到秒传的。这与系统对文件判别的方式相关,本实验采取MD5值作为文件是否唯一的标准来衡量的。虽然MD5值需要一些计算时间,但是,比起较长时间的文件传输,这点时间还是值得的。
从表2可以看出,三个客户端的上传、下载、删除数据时间几乎是相同的。并且,其服务器上的文件数目每上传一次都会增加1,导致云存储服务器上大量的重复数据存在。
由表1和表2可知,本文设计的云存储环境下的文件秒传系统是可行的。对于服务器端已经存在的文件,它可以完成快速的上传功能,并且不影响用户对数据文件的其他操作。这种设计可以避免服务器端的文件重复存储,大大减轻了服务器的存储压力。
3 结 语
云计算的发展带动了云存储的快速发展,使得云存储在越来越多的领域得到应用。云存储为越来越多为人所熟知,并且为越来越多的互联网用户所使用。但是,云存储环境是基于互联网而存在的,离不开网络的支持,网络有自身的限制,数据的传输速度受限于很多因素,如网络带宽、网络当时的拥挤程度等。而用户一般都想让自己的数据快速地上传至云存储服务器以完成数据的备份。用户的需求使得云存储提速显得格外重要。本文设计的文件秒传系统可以在很大程度上满足用户的需求,该系统基于云存储服务器端丰富的数据资源,建立元数据资源库,为用户的上传数据服务额外的对比功能,使得已经存在的文件不再上传至服务器,而是增加引用计数,使得多用户共享同一个文件。这种设计方案不但可以大大加速用户上传文件的平均速度,而且可以节省云存储服务器的存储空间。下一步就是对如何判别同一个文件的条件做深入研究,使秒传系统以更快更好的效率服务于用户。
[1] Luo Y,Luo S,Guan J,et al.A RAMCloud Storage System based on HDFS:Architecture,implementation and evaluation[J].Journal of Systems and Software,2013,86(3):744-750.
[2] 刘渊,杨泽林.基于模拟信息转换器的物联网海量数据处理研究[J].计算机应用研究,2013,30(12):3694-3697.
[3] Wang C,Chow S S M,Wang Q,et al.Privacy-preserving public auditing for secure cloud storage[J].Computers,IEEE Transactions on,2013,62(2):362-375.
[4] 张桂刚,李超,张勇.一种基于海量信息处理的云存储模型研究[J].计算机研究与发展,2012,49(7):32-36.
[5] 覃雄派,王会举,杜小勇.大数据分析-RDBMS与MapReduce的竞争与共生[J].软件学报,2012,23(1):32-45.
[6] 张鸿辉,刘伟,李永强.应用于电网企业的云存储访问控制增强策略[J].计算机应用与软件,2014,31(2):17-20.
[7] Zeng W,Zhao Y,Ou K,et al.Research on cloud storage architecture and key technologies[C]//Proceedings of the 2nd International Conference on Interaction Sciences: Information Technology,Culture and Human.ACM,2009:1044-1048.
[8] 周江,王伟平,孟丹.面向大数据分析的分布式文件系统关键技术[J].计算机研究与发展,2014,51(2):382-394.
[9] Yang K,Jia X,Ren K.Attribute-based fine-grained access control with efficient revocation in cloud storage systems[C]//Proceedings of the 8th ACM SIGSAC symposium on Information, computer and communications security.ACM,2013:523-528.
[10] Iacono L L,Torkian D.A System-Oriented Approach to Full-Text Search on Encrypted Cloud Storage[C]//Cloud and Service Computing (CSC),2013 International Conference on.IEEE,2013:24-29.
[11] 翟岩龙,罗壮,杨凯,等.基于Hadoop的高性能海量数据处理平台研究[J].计算机科学,2013,40(3):100-103.
DESIGN AND IMPLEMENTATION OF FILE SECOND TRANSMISSION SYSTEM IN CLOUD STORAGE ENVIRONMENT
Hu Yuping
(ChongqingWaterResourcesandElectricEngineeringCollege,Chongqing402160,China)
To solve the problem of slow speed in uploading user’s data to server in cloud storage environment, this paper designs a file second transmission system. The system sets up the metadata resource library based on sufficient data resource in cloud storage servers, and implements data second transmission by designing the files to a mode of resource sharing. The metadata resource library organises the data in cloud storage server by the unique field which marks the content of data so as to ensure in the resource library there are no duplicate data. When user upload data to cloud storage server, if the unique identity of this data can be found in metadata resource system, then the system can complete user’s upload operations by just increasing the reference count of the record, but not transmitting any data through internet. That is to say, it implements the logical files upload, and ensures that the following operations on the data are all normal. Experimental result indicates that the file second transmission system designed in the paper can improve the data upload speed well, and can improve the use ratio of cloud storage server space, the scheme is feasible and effective in cloud storage environment.
File second transmission Cloud storage Metadata Reference count
2014-09-30。胡渝苹,讲师,主研领域:计算机软件应用,计算机教育。
TP311
A
10.3969/j.issn.1000-386x.2016.04.076
(1) 用户发起文件上传的请求;请求数据中包括
符等一些系统需要的信息;
