基于移动Agent的分布式Web搜索模型的设计与实现
2016-05-09李明唐轶
李 明 唐 轶
基于移动Agent的分布式Web搜索模型的设计与实现
李 明1唐 轶2
1(国家电网开封供电公司 河南 开封 475004)
2(中国建设银行武汉数据中心 湖北 武汉 430022)
传统基于C/S模式的Web 搜索方法对网络带宽和网络通畅性的要求都比较高,因此在当今互联网的海量数据中的检索效率比较低。在分析移动Agent技术特点的基础上,提出一种基于移动Agent的分布式Web搜索模型。该模型根据中文信息搜索的特殊性,将移动Agent技术与分类算法相结合,在搜索过程中引入了用户输入信息的预处理过程来进行信息分类,然后根据分类结果形成基于用户兴趣度的移动Agent搜索路径选择策略以及并发方法,由此来提高Web搜索的效率。详细介绍框架的组成和所采用的关键技术,并通过一个移动Agent的开发平台——Aglet平台对模型进行实现和实验。实验结果表明,采用该模型进行Web检索,比传统的C/S检索方式减少50%以上的搜索时间,而在各资源服务器存储的文件资源类别和资源数量差异较大情况下的搜索效率比非并发的其他移动Agent搜索模型搜索时间要减少70%以上。
移动Agent 分类算法 路由策略 并行方法
0 引 言
随着互联网信息资源爆炸式地增长,网络信息搜索面临着庞大的信息量和有限带宽之间、单一搜索请求和大量相关站点之间、用户个性化需求和搜索方式单一之间的种种矛盾[1]。而传统的、基于C/S模式的搜索引擎通过在客户和服务器之间建立一条逻辑信道来实现对需要检索的远程资源的本地文件索引,因此对网络带宽和网络通畅性的要求都很高,且降低了检索效率。而基于BDI(Belief、Desire、Intention)[2]理论模型的,集软件、通讯、分布式技术于一体的移动Agent技术[3,4]可以有效运用网络带宽来进行高效的分布式计算。它将代码迁移到资源所在地进行远程检索,只返回检索结果,因此能很好地解决传统搜索方式的不足。
1 移动Agent技术简介
移动Agent是一个具有一定智能性的代替人或其他程序执行某种任务的程序。它能自主地从一台主机迁移到另一台主机,当任务完成后,自动返回结果和消息。它主要分为2个部分:移动Agent和移动Agent环境[5]。当移动Agent迁移到资源所在地主机后,会在本地调用主机资源,进行相应的访问和运算。由于移动Agent自身的特性,其在分布式信息检索的优势主要体现在如下几个方面[6,7]:
(1) 降低网络负载 传统的分布式信息搜索需要建立逻辑信道,以保持网络通信正常,长时间的网络连接必导致网络阻塞。而移动Agent携带代码迁移到资源所在地,避免了大量数据资源的传输,同时不需要网络长时间保持连接状态,从而大幅度降低了网络负载。
(2) 平台无关 移动Agent的运行只依赖于是否有移动Agent环境,与网络平台无关。
(3) 自主性 移动Agent可以根据实时网络状况和自身任务特点自主的选择移动路线。使得移动Agent具有一定的智能性和应变能力。
(4) 并行性 用户可以针对一个任务或多个任务同时创建多个移动Agent,使其并行工作,快速高效地完成用户任务。
2 基于移动Agent的分布式搜索系统的系统架构
为了提高远程资源的搜索效率,本文设计了一个基于特征信息和移动Agent的分布式搜索系统(IMADS)框架,该框架主要包含如下几个部分:用户本地Agent系统(ULAS)、远程资源管理系统(RRMS)、Agent转接系统(AD),如图1所示。
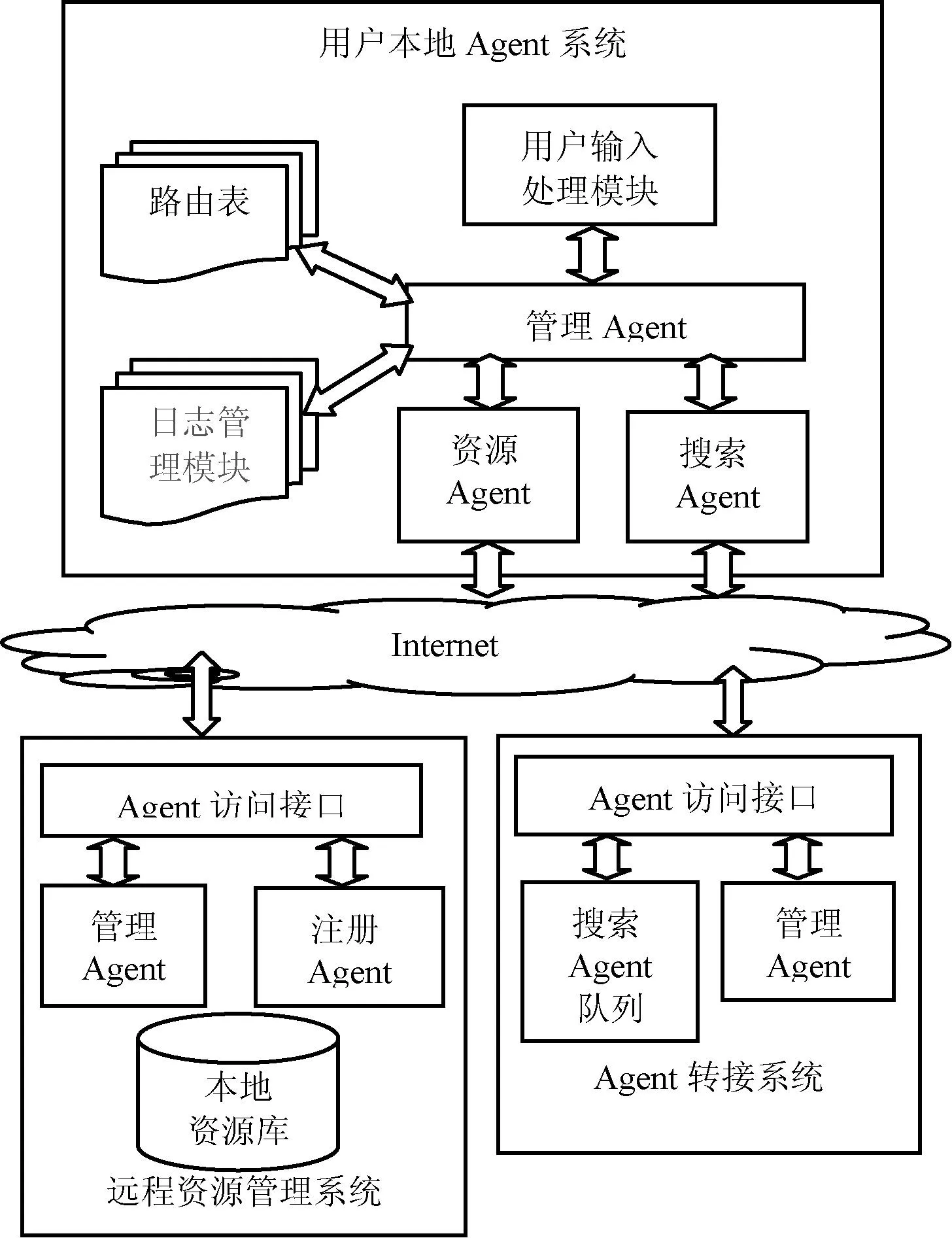
图1 基于移动Agent的分布式Web搜索系统架构
下面详细介绍该框架的三个主要组成部分:
(1) 用户本地Agent系统 由用户输入处理模块、日志管理模块、资源Agent、搜索Agent、管理Agent和路由表构成。其中:
a. 输入处理模块:其主要任务为在进行信息搜索前,对创建的Agent进行状态、知识库、约束条件等的初始化;对用户的输入信息进行分词、去除停用词等预处理;将代表用户兴趣目标的特征词写入知识库;设置返回时间、站点停留时间、任务完成度、搜索范围等。
b. 资源Agent:是一类移动Agent,当用户提出查询请求后,资源Agent查询日志中存储的可移动的远程资源节点,然后根据具体信息生成路由表。返回给管理Agent,管理Agent设置搜索Agent迁移的路径等。
c. 管理Agent:是用户Agent的控制中心,它主要负责创建资源Agent,并派遣到远程资源服务器上查询可用的服务列表,并将目标URL地址、资源种类、数量等远程资源信息反馈给用户管理Agent;接收从用户输入接口输入的查询、约束条件、路由表等初始化信息,并打包成搜索Agent可携带的执行格式;接收搜索Agent携带回来的数据,并转换成本地需要的数据格式在GUI上显示。
d. 搜索Agent:是另一类移动Agent,它们携带用户的查询信息、迁移地址URL、路由表、迁移时间等在各资源所在地主机之间移动。搜索Agent迁移到远程资源服务器,通过远程资源服务器的管理Agent接口访问远程资源。结束搜索后,根据路由表信息决定下一步迁移目的地。搜索Agent在返回到用户端或者迁移到下一个站点之前,先调用Ping命令判断网络的连通性。若连通则表示目的地的Agent环境已经启动,搜索Agent可直接迁移到对方主机。若不连通,则搜索Agent到AD中等候,AD将搜索Agent保存在硬盘上,并监视目标主机,一旦连通,将激活搜索Agent让其传送到目标主机。
(2) 远程资源管理系统 由注册Agent和管理Agent等非移动的静态Agent组成,负责给搜素Agent提供运行环境,每个资源所在地需要部署这样的环境。当启动该搜索Agent环境后,会向ULAS发送一个携带有该环境URL地址的注册Agent,当管理Agent成功接收后,会将该URL地址保存起来,更新日志文件,以便于资源Agent进行实时访问。它的另一个管理Agent为迁移到此环境的搜索Agent提供服务,保存历史记录以及向搜索Agent的下一个迁移目标发送Ping命令,测试其连通性。
(3) Agent转接系统 主要功能是解决迁移失效问题。当一个搜索Agent迁移到某个用户服务器上时,如果遇到服务器关闭或网络阻塞等情况时,它将自动迁移到该服务器所在的Dock服务器上。当移动Agent到达Dock服务器后就不再运行,而在Dock服务器上的固定Agent控制下存储到硬盘,固定Agent代替移动Agent监视服务器状态。当检查到服务器恢复连接后,唤醒等待迁移到服务器上的搜索Agent,使得所有在Dock服务器上等待迁移到目标服务器的移动Agent能迁移过去。
3 系统实现的关键技术
3.1 基于朴素贝叶斯分类算法的用户输入预处理过程
用户输入处理模块包括:用户输入预处理、关键词语义扩展和关键词分类三个部分。
(1) 用户输入预处理模块
用户输入预处理模块主要包含用户输入信息的分词和去除停用词。对于分词,采用现有的分词工具MManalyzie[6]。它基于字符串的最大长度匹配,分词效果好,可靠性较高,速度也比较快。由于分词后,会出现许多没有实际意义的语气助词或没有代表性的惯用词语。为了提高运行效率,减少无谓的系统开销,提高精确度,需要将分词后的词语与常用词表进行比对,去除没有特殊意义、分类效果不明显的单词,最后得到最能代表用户搜索需求的若干关键词。例如:今天进行的NBA比赛结果统计经分词、去除停用词后就会变成“NBA/比赛/结果/统计”这样的代表用户真实搜索意图的简明、扼要的关键词组。
(2) 关键词语义扩展模块
关键词语义扩展的主要用途是为了更好地识别用户的兴趣度。通过对关键词进行扩展,扩展出多个同义词则可以使得后面关键词分类的结果更准确。在这里调用较为广泛使用的语义扩展系统WordNet[7]来获取关键词的同义词。
(3) 关键词分类模块
在对关键词分类上,首先需要大量的数据集作为训练级,本文的训练集由资源所在地的索引文档提供。索引文档是经过预处理和TF-IDF[8]算法统计的所有待搜索文档,按关键词TF-IDF值从大到小排列构成,然后利用朴素贝叶斯算法对其进行分类。
TF-IDF是一种用于资讯检索与资讯探勘的常用加权技术。其主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
在形成了用户输入关键词分类的训练集后,就可以开始挖掘用户的搜索兴趣倾向了。本文采用简单的朴素贝叶斯算法来实现对用户关键字的分类。
朴素贝叶斯分类算法发源于古典数学理论,有着坚实的数学基础以及稳定的分类效率。同时,朴素贝叶斯分类算法模型所需的参数很少,对缺失数据不太敏感,算法也比较简单,理论上与其他分类方法相比具有最小的误差率。
朴素贝叶斯分类算法的思想基础是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类属于哪个类别。用户输入处理模块流程如图2所示。
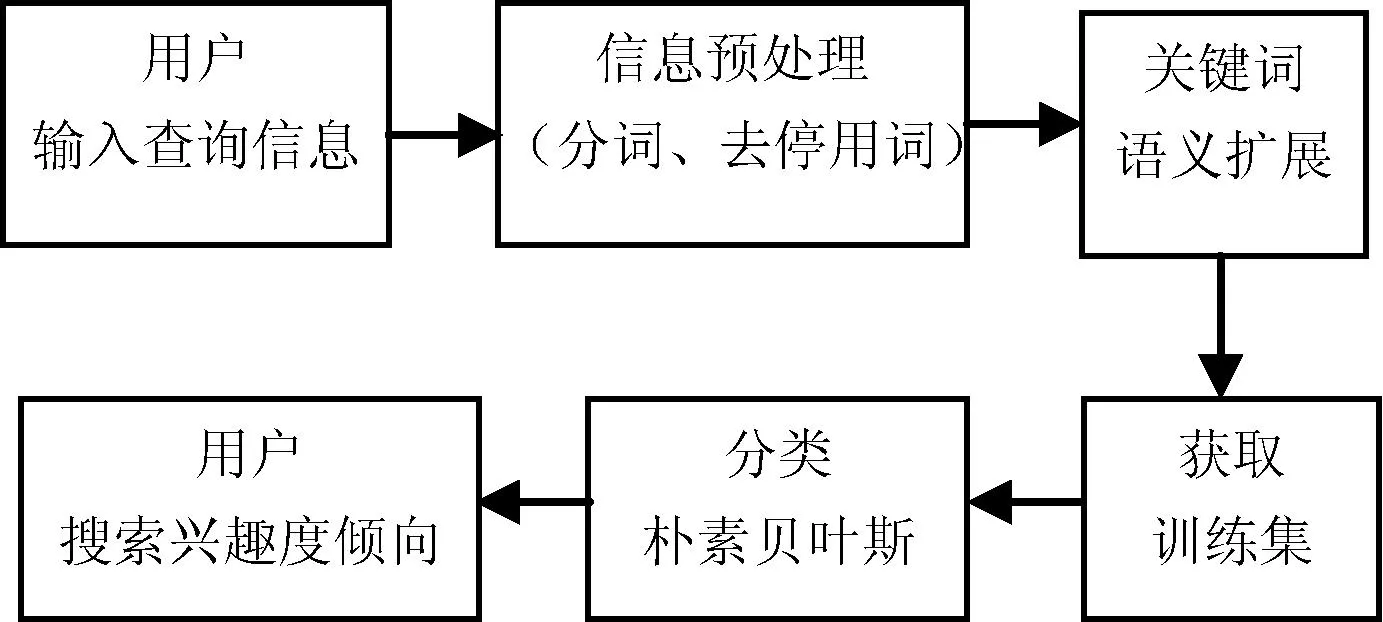
图2 用户处理模块流程
图2中训练集的获取需要由搜索Agent定时遍历远程资源服务器的资源信息,以保证训练集的全面性。这个过程优先级不高、花费时间较长且对朴素贝叶斯算法的准确度影响不大。日常的用户输入处理可直接调用本地的训练集数据,该模块是一个独立的数据挖掘子程序,在用户点击搜索按钮后触发,为创建用户个性化搜索路由表提供条件。
3.2 移动Agent的路由策略
在搜索Agent迁移过程中,为了实现更优的搜索效果,本文为移动类型的资源Agent和搜索Agent设计了不同的路由策略,其中资源Agent的迁移采用最小生成树的路由策略,而搜索Agent则采用基于用户兴趣度的个性化搜索路由策略。
(1) 最小生成树资源路由策略
按如下步骤定义最小生成树路由算法:
a. 设集合S={未访问过的远程资源服务器},N={已经访问过的远程资源服务器}。初始值S={S1,S2,…,Sn},N={S0}。
b. 对任意的Si∈N,计算它到服务器Sj∈S,发送Ping命令的时间Tij,选取minTij。
c. 修改路由表,让i服务器上的移动Agent迁移到j服务器上。若i服务器没有驻留的资源Agent则由管理Agent新产生一个资源Agent访问j服务器。
d. 将Sj加入到N。
e. 重复步骤b ,直到所有的远程资源服务器都被访问,资源Agent传递资源信息给管理Agent后,销毁。
(2) 个性化搜索路由策略
基于用户兴趣度的个性化搜索路由策略描述如下:
a. 管理Agent根据用户输入处理模块的用户兴趣度挖掘结果,从日志文件中将包含用户最感兴趣类别的远程资源服务器信息提取出来。
b. 管理Agent按远程资源服务器中关键类别资源数量多少,按照由多到少的次序对资源服务器进行排序。
c. 管理Agent对每一条资源服务器信息添加一个读写状态系数,初始化参数为0,形成初始化搜索Agent路由信息表。
d. 当管理Agent派遣一个搜索子Agent进行搜索时,管理Agent将路由表中与该搜索Agent迁移目的地相同的路由信息读写状态参数修改为1,表示正有搜索Agent对该远程资源服务器进行搜索任务。
e. 当一个搜索Agent完成了它所在的远程资源服务器位置的搜索任务后,通过消息机制,管理Agent捕获到搜索子Agent的状态。再一次互斥读写搜索路由表,将当前搜索Agent停留的远程资源服务器的状态参数改为2,表示该远程资源服务器已经被成功访问。
f. 管理Agent访问搜索Agent路由表的下一条路由。并与之前的资源路由表比对,判断现有的搜索Agent到达下一条路由的路线是否与资源Agent相同。若相同,则在搜索Agent完成搜索任务后,搜索Agent会携带管理Agent赋予的新的路由信息,继续迁移到下一个远程资源站点;若不相同,则管理Agent会创建一个新的搜索子Agent,迁移到下一条路由的路线。
g. 搜索Agent在完成搜索任务后,若管理Agent未赋予其新的迁移地址,搜索Agent自动返回管理Agent。
h. 当搜索Agent路由表中所有的路由读写状态参数均为2时,完成搜索。
搜索路由表的格式如表1所示。

表1 搜索路由表
3.3 搜索的并行化
针对一个资源遍历任务或文本搜索任务,往往需要多个Agent并行执行,提高速度和效率。资源Agent的并行性主要通过最小生成树的路由协议控制,搜索Agent的并行化则通过对搜索路由表参数的互斥读写并与资源Agent的比对来控制。
因此基于以上策略,用户无需在搜索前人为规定需要几个Agent并行执行。而是将Agent的并发程度交给系统判断,管理Agent根据路由表的访问情况动态的添加、销毁Agent。体现了移动Agent的并发智能性。
Agent的并发个数并不是越多越好。理论上同时并发的Agent数目不应该超过远程资源服务器的数量。否则,频繁的搜索Agent、资源Agent与管理Agent交互的输入输出,将影响Agent处理任务的速度。
4 系统实现与实验
本文基于Aglet[9]平台对以上框架进行了实现。Aglet是日本IBM公司基于Java技术研发成的Mobile Agent技术,通过Aglet Workbench供人们开发和实施Agent系统。它提供了一个简单和全面的编程模型,可以实现在代理之间建立动态和有效的编程机制,同时具有易用的安全机制。Aglet同时传送代码及其状态,以线程的形式驻留在计算机上,可暂停正在执行的工作,并允许将整个Aglet分派到一台计算机上,再重新启动执行任务。
本系统主要通过建立3个Agent类来实现,其中AgletFrame继承Frame类,提供了用户交互界面;SplitWord类提供了对文本分词和去停用词等预处理工作;SearchFile类是系统的关键,它是一个具有搜索功能的移动Agent,与AgletFrame交互,携带用户的查询关键字到文本所在地进行查询。当查询结束或者最大Agent生存时间到点后将结果返回用户。
本系统采用IBM的Aglet-2.0.2版本,并安装了jdk1.6。在局域网中选择4台电脑,其中一台为客户端的查询主机安装WindowXP操作系统,另外3台存有搜索资源的目标主机安装Win7系统,3台目标主机中存放有利用爬虫技术从网页抓取下来的各类信息资源。以文本形式按新闻、体育、科技、财经、娱乐5种类别进行分类存储,信息资源在3台目标主机上均匀分布。
在实验之前,需要先装好JDK并设置好环境变量,然后将Aglets-2.0.2.jar解压到JDK路径中并完成相关配置便可以启动Aglets移动Agent平台。当四台主机都运行了移动Agent环境后,便完成了实验环境的搭建。
4.1 与传统分布式搜索对比
本文分别采用传统的搜索方法和基于移动Agent的分布式搜索方法进行了某些主题的搜索,由于采用移动Agent的优势是并发性和个性化搜索,因此下面给出实验的主要测试内容与结果。
图3显示了本系统和传统的分布式搜索模型的对比结果。

图3 搜索耗费时间对比结果
通过图3可以看出。随着文本数目的增加,传统分布式技术的效果越差,移动Agent技术支持的搜索越能体现出其优越性。移动Agent携带搜索代码迁移到资源所在地实行本地执行,有效地降低了运行时间。这一点在文本资源很庞大的情况下尤为突出。
4.2 与普通Agent搜索系统对比
图4显示了测试3台远程资源站点的资源类别相同、各类别的资源的个数也基本一致情况下的普通移动Agent模型和本文提出的模型的搜索时间对比情况。3台资源站点的资源各为1000个,共测试50次。普通Agent模型为3个搜索Agent遍历所有远程资源服务器;本文模型为具有智能并发性的个性化Agent模型。

图4 远程资源服务器含资源类别相同的搜索时间对比
图5显示了测试3台资源站点的资源类别完全不同,且待搜索资源的个数差距较大情况下的普通移动Agent模型和本文提出的模型的搜索时间对比情况。其中3台资源站点各有不同类别的资源1000个,共测试50次。

图5 远程资源服务器含资源类别不同的搜索时间对比
由上面的分析结果可以看出,本文提出的模型适用于资源分布差异化较大的一系列站点。若在资源分布相似度较高的环境下,由于涉及到用户输入的处理运算,搜索效果并不明显。而将本文模型运用在差异化较大的远程资源服务器时,根据前期的路由选择可有效地避免对一些无效远程资源服务器的访问,大幅度提高搜索速度。
若扩展到多远程资源服务器的网络中,可以预见由于分类算法预测的不确定性必然会导致搜索结果精确度降低,故本框架不利于对资源相似度较高的多站点进行全面检索。而对于规定有限搜索结果返回的资源类别差异性较大的环境中,则能最好的发挥效果。
4.3 Agent并行化对比
对资源Agent的并行化进行测试,表2分别为一个资源Agent访问3个远程资源服务器。规定3个资源Agent同时访问3个资源服务器,本系统模型的管理Agent自主分配若干资源Agent。
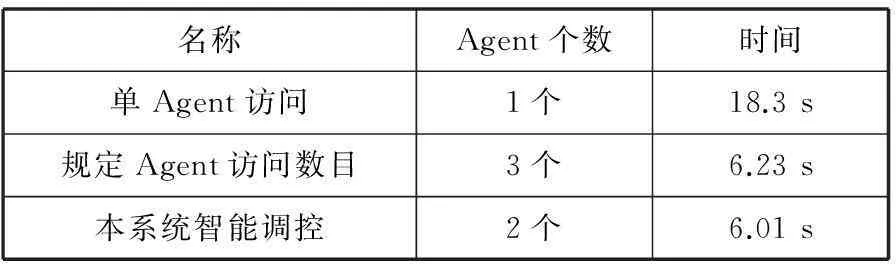
表2 Agent并行化结果
根据表2中的数据分析可以得出,多Agent并行访问可显著提高资源Agent的遍历速度。与规定访问数目的Agent进行遍历相比,本系统对移动Agent智能调控,减少了一个资源Agent的创建,从而避免了资源不必要的浪费,减轻了系统压力。同时,基于动态最小生成树的路由策略,可以让一部分资源Agent
完成任务后不必返回管理Agent,而是携带新的迁移地址,迁移到新的远程资源服务器,提高了检索效率。
通过以上实验,将本文所提出的IMADS模型分别与传统的分布式模型以及无并发的移动Agent模型进行比较,验证了IMADS模型在差异化程度较大的远程资源搜索上具有较大的优势。智能性的移动Agent并行化能在一定程度上提高搜索速度,减轻系统压力。
5 结 语
通过以上分析可以得出,将移动Agent技术运用在分布式信息搜索上可以解决网络信息服务在实际过程中的很多难点和资源限制问题,优化了程序的执行速度,降低了网络资源的占用率。可以预见,移动Agent技术在分布式搜索上的应用将成为未来信息搜索技术的一个发展方向。随着移动Agent技术的不断发展和成熟,基于移动Agent的分布式搜索必将成为搜索领域的潮流。
[1] 张云勇.移动Agent技术[M].北京:清华大学出版社,2001.
[2] 何炎祥,陈萃萌.Agent和多Agent系统的设计和应用[M].武汉:武汉大学出版社,2001.
[3] 黄佳进,邱洪君,钟宁.基于移动Agent的非结构化P2P网络搜索方法[J].北京大学学报,2012,38(1):96-100.
[4] 王素贞,杜治娟.基于移动Agent的移动云计算系统构建方法[J].计算机应用,2013,33(5):1276-1280.
[5] 宋宝贵.基于过程特性的网络信息重复检索策略研究[J].计算机应用与软件,2013,30(5):223-225,232.
[6] 潘金贵.一个个性化的信息搜索集Agent的设计和实现[J].软件学报,2001,12(7):33-38.
[7] 文军.面向查询意图的搜索引擎设计和实现[J].计算机应用研究,2012,29(10):157-162.
[8] 罗伟.基于移动Agent的主题搜索引擎研究[D].武汉:中南民族大学,2005.
[9] 徐朝辉,秦杰,甄彤.基于Agent-Aglet的Web信息检索方法[J].微电子学与计算机,2012,29(1):60-65.
DESIGN AND IMPLEMENTATION OF MOBILE AGENT-BASED DISTRIBUTED WEB SEARCH MODEL
Li Ming1Tang Yi2
1(StateGridKaifengElectricPowerCo.,Ltd.,Kaifeng475004,Henan,China)2(WuhanDataCenter,ChinaConstructionBank,Wuhan430022,Hubei,China)
Traditional Web search methods based on C/S mode have higher requirements in bandwidths and smoothness of network, therefore their retrieval efficiency of mass data in current Internet are rather low. On the basis of analysing the features of mobile Agent technology, we proposed a mobile Agent-based distributed Web search model. According to the particularity of Chinese information search, the model combines the mobile Agent technology with classification algorithms, and introduces the pre-processing process of user inputted information into search process to classify the information, then forms the users interest degree-based route selection strategy of mobile Agent and concurrent method according to classification results, and so as to improve the efficiency of Web search. In the paper we expound the constitution of the framework and the key technologies adopted, as well as the implementation and experiments of the model on Aglet platform, a development platform for mobile Agent. Experimental results indicated that, to carry out Web search using the model could reduce the search time by 50% or lesser than the traditional C/S retrieval mode, and under the condition that there are quite big difference in categories and amounts of documents resources stored in various resource servers, its search efficiency reduced by 70% or higher than the search time of other non-concurrent mobile Agent search model.
Mobile Agent Classification algorithm Route policy Parallel method
2014-08-15。广东省省部产学研项目(2012B0911004 90)。李明,工程师,主研领域:Wed信息搜索,调度自动化。唐轶,工程师。
TP18
A
10.3969/j.issn.1000-386x.2016.04.005
