业务流程挖掘算法研究
2016-05-09杨丽琴康国胜蔡伟刚
杨丽琴 康国胜 蔡伟刚 周 强
业务流程挖掘算法研究
杨丽琴1,2康国胜2蔡伟刚1周 强1
1(上海中医药大学图书信息中心 上海 201203)
2(复旦大学计算机科学技术学院 上海 201203)
流程挖掘能够根据流程的执行日志重构出流程模型,有助于实现业务流程的优化和智能管理。首先,指出目前流程挖掘技术需要解决的关键问题。然后,介绍几种具有代表性的流程挖掘算法,并指出每种算法解决的问题和存在的不足。接着,从日志完整性、控制流结构、噪声处理和模型质量控制等方面对流程挖掘算法进行分析和比较。最后,指出流程挖掘技术未来的研究方向。
流程挖掘 α算法 启发式算法 遗传算法 日志分类
0 引 言
目前,大多数企业使用信息系统来支持业务流程的执行,如工作流管理系统(WFMS)、企业资源规划系统(ERP)、客户关系管理系统等。这些信息系统可能包含显式的流程模型,也可能仅支持流程所涉及的任务而无需定义显式的流程模型,或仅仅保留了执行任务的轨迹。然而,这些信息系统都可以自动生成执行日志来记录业务流程的实际执行情况。流程挖掘的目标就是从这些执行日志中自动发现和流程有关的信息。挖掘结果可用于设计一个新的业务流程,或者作为反馈工具审计、分析和改进现有的业务流程。因此,流程挖掘对实现业务流程的优化和智能管理有着十分重要的意义[1]。
流程挖掘分为三个视图[2]:控制流视图、组织视图和实例视图。其中,控制流视图关注流程中活动的执行顺序和控制流结构,常用的建模语言[2,3]有WF-net、C-net、EPCs、BPMN和YAWL等。组织视图关注流程的资源信息,如哪个活动由哪个执行者实施以及它们之间的关系。目标是发现和展示人之间的关系,即建立一个社会关系网。实例视图关注与流程实例相关的属性,既可用活动表示,也可用实例中的执行者表示,还可以用流程处理的数据对象来表示。本文仅从控制流角度论述流程挖掘技术的关键问题和研究现状。文献[1]仅介绍了较早期的部分工作流挖掘算法。针对近几年国内在流程挖掘综述方面的文章较少,本文较全面地介绍了具有代表性的流程挖掘算法,包括基于遗传算法的流程挖掘、基于日志分类的挖掘算法和基于执行模式的挖掘算法。从日志完整性、控制流结构、噪声处理和模型质量控制等方面对它们进行了分析和比较。
1 流程挖掘的基本概念
1.1 日 志
流程挖掘的输入是执行日志,表1是一个会议流程的执行日志。每一行表示一个事件,记录了与事件有关的各种信息,如:该事件对应的活动,事件发生的时间等,用事件ID标识。实例是流程的一次执行过程,用实例ID标识,每个事件属于某一实例。如果只关注流程的控制流视图,一个实例可用其所有事件所对应的活动序列来表示。因此,可对表1中的日志进行化简,化简后的日志如表2所示。表中共包含6个流程实例,14个活动。

表1 会议流程的部分日志

表2 会议流程日志的化简形式
日志的形式化定义[3]如下:
定义1 设T是活动的有限集合,σ∈T*是一条活动序列,L∈(T*)是一个流程执行日志。其中,T*表示集合T的Kleene闭包。
例如:T={a,b,c,d},L=[
1.2 流程模型表示方法
流程的控制流结构可用不同的建模语言[2]来描述,如:WF-net、C-net、Process Tree等。不同挖掘算法使用的流程模型表示方法也不同,例如:α系列算法使用的是WF-net,启发式算法使用的是C-net,而基于遗传算法的流程挖掘使用的是Petri网或Process Tree。因此,算法具有各自的表达偏好。这些建模语言之间可以相互转换,也可以转换成语义表达能力更强的高级流程建模语言,如YAWL、BPMN、EPCs等。高级建模语言一般提供给业务人员建模使用,本文不做介绍。下面介绍几种常用的流程模型表示方法。
1.2.1 工作流网WF-net(Workflow Net)
首先,介绍经典的Petri net[4],它是由库所和变迁这两类节点组成的二部图,节点之间通过有向弧连接。形式化定义如下:
定义2 一个Petri网是一个三元组(P,T,F),其中:
(a) P是一个有限的库所集;
(b) T是一个有限的变迁集(P∩T=∅);
(c) F⊆(P×T)∪(T×P)是弧的集合。
Petri网的状态通常被称为标记,是token在各库所的分布情况的描述。Petri网在执行过程中,变迁根据触发规则[31]改变Petri网的状态。
标签化的Petri网是一个五元组(P,T,F,A,l),其中(P,T,F)同定义2,A是一组活动的集合,l∈T→A是Petri网中变迁到活动的映射。直观地,就是为Petri网中的变迁打上活动的标签,变迁一旦被触发则说明对应的活动也被执行。
定义3 一个标签化的Petri网PN=(P,T,F,A,l)是一个工作流网WF-net[2],当且仅当:
(a) 存在一个起始库所i∈P使得·i=∅;
(b) 存在一个终止库所o∈P使得o·=∅;
(c) 每个节点都位于从i到o的一条路径上。
若对会议流程日志(表2)使用合适的挖掘算法,得到的流程模型如图1所示。

图1 会议流程的WF-net模型
图1中,矩形表示变迁,圆圈表示库所,变迁和库所之间使用有向弧连接。每个库所上都标有活动的名称,当触发库所时,相应的活动被执行。根据定义3,该流程是一个WF-net。
定义4 一个WF-net N=(P,T,F,A,l)是一个SWF-net[2],当且仅当:
(a) 对于所有的p∈P,t∈T,(p,t)∈F,若|p·|>1,则|·t|=1;
(b) 对于所有的p∈P,t∈T,(t,p)∈F,若|·t|>1,则|·p|=1;
(c) 不存在隐式库所。
1.2.2 Causal net (C-net)
Causal net表达流程中活动和活动之间的依赖关系。每个活动有一组输入约束和输出约束。如图2 (a)所示,活动a是开始活动,因此,没有输入约束,输出约束是{b,d}和{c,d},表示执行活动a后,执行b和d,或者c和d。活动e是结束活动,没有输出约束,输入约束为{b,d}和{c,d},说明在执行活动e之前,执行了b和d,或者c和d。
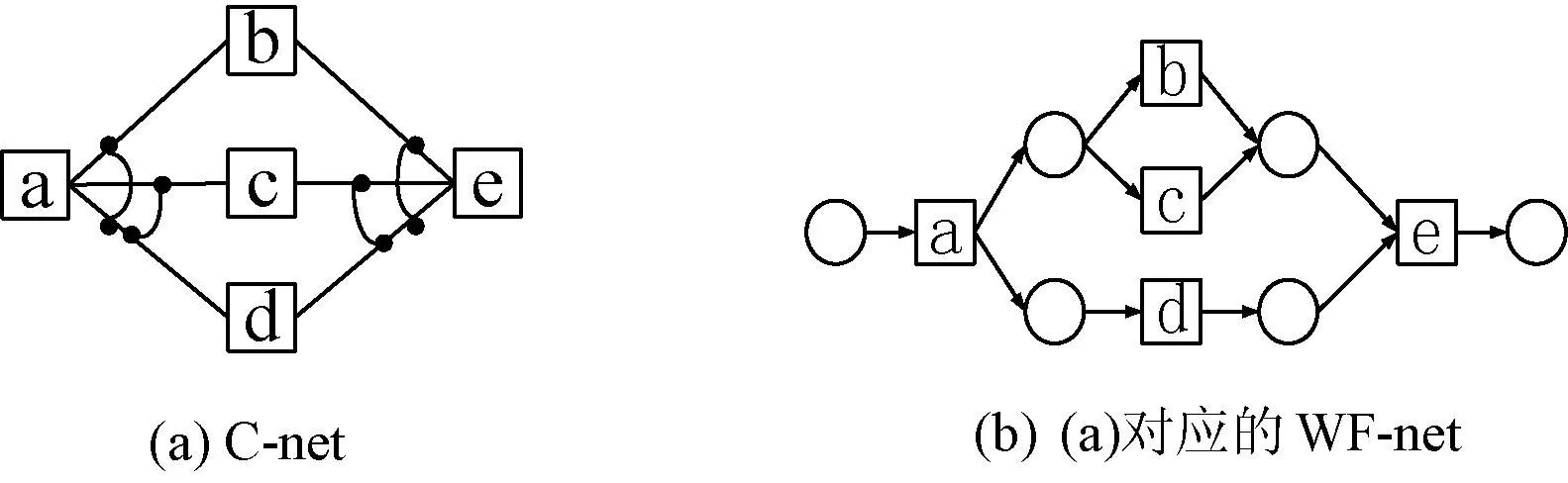
图2 一个C-net例子
与图2(a)中的C-net等价的WF-net模型如图2(b)所示。它们所有的可执行流程实例相同,有
定义5 Causal net[2]是一个六元组(A,ai,ao,D,I,O)。
其中:
A是活动的有限集合;
{ai}={a∈A|I(a)={∅}}是开始活动;
{ao}={a∈A|O(a)={∅}}是结束活动;
D={(a1,a2)∈A×A|a1∈∪as∈I(a2)as∧a2∈∪as∈O(a1)as}是依赖关系;
I∈A→AS是活动的输入约束;
O∈A→AS是活动的输出约束;
AS={X⊆ρ(A)|X={∅}∨∅∉X}2。
例如,图2(a)所示的Causal net,A={a,b,c,d,e},ai=a,ao=e,D={(a,b),(a,c),(a,d),(b,e),(c,e),(d,e)},I(a)={∅},O(a)={{b,d},(c,d)},I(b)={{a}},O(b)={{e}},I(c)={{a}},O(c)={{e}},I(d)={{a}},O(d)={{e}},I(e)={{b,d},{c,d}},O(e)={∅}。
1.2.3 流程树
流程树[5]也可作为流程模型的表示方式。其中,节点分为叶子节点和非叶子节点。叶子节点(也称为活动节点)表示活动。非叶子节点(也称为操作节点)表示流程的控制流结构。四种控制流结构的流程树表示方法如图3所示。→×∧分别表示顺序、选择、并行和循环结构。
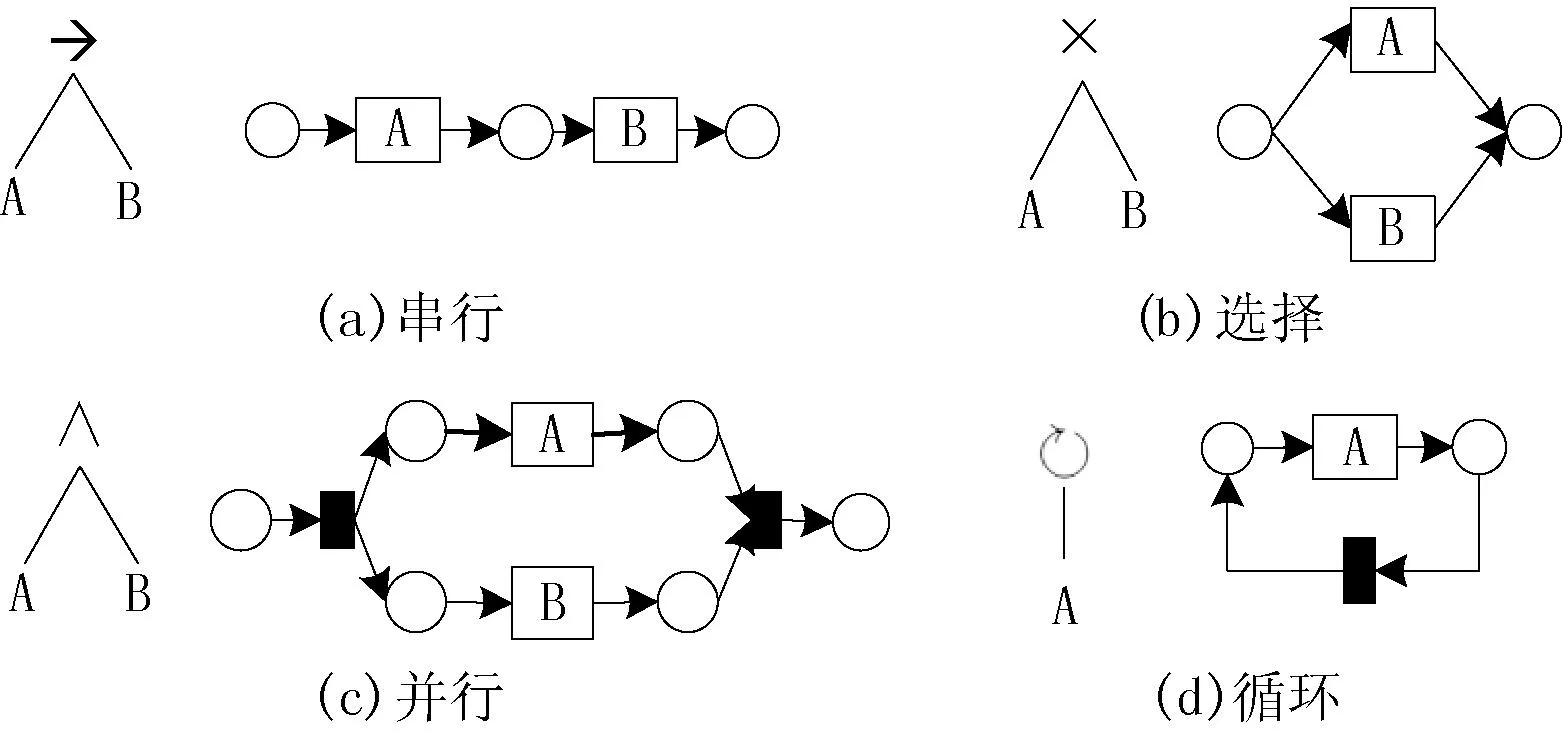
图3 四种控制流结构的流程树表示
使用流程树表示的流程模型是一种“块结构”的流程模型,其最大的好处是流程可避免死锁。
2 流程挖掘中的关键问题
2.1 控制流结构
以WF-net为例,常用的控制流结构包括:顺序结构、并行结构、选择结构、循环结构、非自由选择结构[6]、隐式活动和重复活动。会议流程的WF-net模型(图1)包含了上述所有的控制流结构。观察执行日志(表2),若参会者坐火车前往开会,则同样坐火车返回;若开车前往,则同样开车返回。可见,返程的方式取决于前去开会的方式。在图1中,库所i后面的选择不是由前面的“返程”活动决定,而是由库所c后面的活动决定。若库所c后选择的是坐火车,则库所i后选择的也是坐火车;若库所c后选择的是开汽车,则库所i后选择的也是开汽车,这称为是非自由选择结构。另外,流程中两个活动的名称相同,导致了重复活动。在日志中,有的参会者在会上没有发表演讲,这通过隐式活动实现。隐式活动是WF-net模型中黑色的矩形,常用来辅助实现某些控制流结构。在日志中,有的参会者没有提问,而有的提问多次,这通过循环结构实现。
流程挖掘算法应当尽可能多的支持各种控制流结构。但由于各种因素,如:日志信息不完整、建模语言表达能力有限,算法本身的局限性等,算法可能无法处理某些控制流结构。
2.2 日志噪声和不完整性
大多数挖掘算法假设日志数据是正确的。但实际上,由于流程执行异常或日志记录错误,日志数据往往存在一些噪声。噪声的特点是出现频率低。利用这个特点,一种方法是对日志进行预处理,或对结果模型进行“剪枝”。但这种方法没有体现算法本身的健壮性,而有些挖掘算法本身能够处理日志噪声,如启发式算法、遗传挖掘算法等。
日志的完整性对挖掘结果也起到重要的作用。但实际上,某些合法的流程实例可能没有记录在日志中。例如,流程模型中有10个可并发执行的活动,要满足日志完整性,则至少包含10!条流程实例,但实际上可能只有其中1000条流程实例被记录在日志中。如果模型中存在循环结构,则可执行的流程实例无穷多,显然不可能全部记录在日志中。日志完整性可分成不同级别[7],不同的挖掘算法对日志有不同的完整性要求。
(1) 全局完整性GC:流程模型描述的所有可能的流程实例都至少在日志中出现一次。通常情况下,全局完整性是一种理想情况,很多情况下日志信息是不完整的或者不可能做到完整,例如流程中有循环结构时。
(2) 继发完整性DS:任何两个允许相继执行的任务,它们相继执行的流程实例至少在日志中出现一次。
(3) 2元短循环完整性DS+:若活动a和b组成长度为2的循环结构,则序列
(4) 长循环完整性DS++:长循环指流程中包含长度大于2的循环结构。长循环的实例必须至少在日志中出现一次。
(5) 频率完整性FS:日志中记录流程实例发生的次数。因此,通过日志可以得出哪些活动经常相继发生。
2.3 日志多样性
日志多样性指由于流程本身错综复杂而导致日志中的实例也呈现出复杂多样的特征。例如,医疗系统的执行日志就存在多样性的特点。因为每位患者的病情、体质或者经济状况都不同,采取的治疗手段也互不相同。如果使用传统的流程挖掘算法,得到的流程模型结构非常复杂、难以理解。
一种解决方法是采用聚类方法对日志中的执行实例进行聚类从而产生多个子日志,降低日志的多样性。然后对每个子日志分别实施已有的挖掘算法。这种方法得到的模型结构大大简化,但得到的不是完整的流程模型。另一种方法是抽取日志中的通用执行模式(活动序列片段),根据模式对日志进行迭代化简,然后对化简后的日志和执行模式分别施用已有的挖掘算法得到层次流程模型。
2.4 流程模型质量评价
通常从四个方面[8-10]来评价流程模型的质量:重现度、精确度、通用性和简单性。
重现度:指流程模型对日志中执行实例的可重现程度。给定一个流程模型和一个执行实例,如果执行实例可通过执行该流程获得,则称该流程可重现该实例。流程模型可重现的执行实例越多,对日志的重现度就越高。
精确度:如果通过执行流程模型可以产生许多日志中不包含的实例,那么该流程模型的精确度就较低,称为弱拟合。
通用性:与精确度相反,通用性指流程模型不仅反映日志中的行为,还允许日志以外的正确行为。这是因为实际应用中,日志通常是不完整的。好的流程模型应当有这样的“预见性”使得新的执行实例符合流程模型的规范。如果通用性过低,称流程模型过拟合。
简单性:在保证其他三个指标的情况下,流程模型越简单越好。可从模型中节点的数量或节点的出入度等方面来评价。
精确度和通用性存在一定程度的对立,精确度较高的流程模型,通用性往往较差,反之亦然。简单性与精确性和通用性也有一定的关系,通常通用性较高的模型结构较简单,而精确性较高的模型结构较复杂。如何使流程模型质量在这四个方面达到一种平衡,或者能够控制这四个方面的不同需求也是流程算法应该解决的问题。
3 流程挖掘算法
3.1 直接算法
这类算法的基本思想是:首先,扫描日志中的所有实例,抽象出活动之间的基本关系。然后,根据基本关系的类型,直接构造流程的控制流结构。这类算法的代表是α及其扩展算法[6,11-14],包括α、α+、α++、α#、α*等。
以α算法[13]为例,活动之间的基本关系有:
a>Lb(伴随):∃α∈L,α=
a→Lb(因果):∀α∈L,α=
a||Lb(并行):∀α∈L,α=
a#Lb(无关):∀α∈L,α=
根据四种基本关系,构造控制流结构。构造方法为:a→b:顺序结构;a>Lb,a>Lc,b#Lc:选择分叉;a>Lc,b>Lc,a#Lb:选择合并;a>Lb,a>Lc,b‖Lc:并行分叉;a>Lc,b>Lc,a‖Lb:并行合并。
α算法无法处理长度为2的短循环结构。因为对
α+算法[11]是对α算法的第一次扩展,它能够处理α算法不能处理的长度为1或2的短循环结构。为了识别长度为2的循环活动序列,α+算法首先扩展了活动之间的基本关系:
a△Wb:当且仅当存在一个流程实例σ=t1,t2,…,tn,i∈{1,…,n-2},ti=ti+2且ti=1=b;
a◇Wb:当且仅当a△Wb且b△Wa。
然后对原来的三个基本关系a→Lb,a‖Lb,a#Lb也作了相应的改进。α+算法的具体过程是:先识别日志中长度为1的循环活动序列,将它们暂时从日志中过滤掉。对过滤后的日志,使用与α算法相同的方法得到中间模型。然后,将长度为1的循环结构添加到相应的位置。α+算法的结果流程模型是不带隐式活动和重复活动的SWF-net。
α与α+算法关注的是活动之间的直接(显式)依赖关系。而在有些流程中,两个非直接相邻的活动之间也可能存在依赖关系,即隐式依赖。α++算法[6]考虑了依赖距离大于1的隐式依赖关系,因此能够处理非自由选择结构。α++算法的关键是快速有效地发现任意两个活动之间的隐式依赖。
α#算法[12]是对α+算法的扩展,能够处理隐式变迁。如图1所示,一个黑色的变迁上没有标识对应的活动,该变迁称为隐式变迁。通常,隐式变迁是为了保证WF-net的正确性,或构造复杂控制流结构而加入的。隐式变迁分为SIDE,SKIP和SWITCH三种类型。α#算法先抽象活动之间的虚假依赖关系,再根据构造规则,构造出三种不同类型的隐式变迁。
α*算法[14]用于处理重复活动。在WF-net中,如果变迁T到活动A的映射是1对1关系,即不存在多个变迁映射到一个活动的情况,则流程不存在重复活动。α、α+、α++、α#算法均不能处理重复活动。如表2中的第1个实例:<开始,准备,坐火车,开会,提问,参观,晚宴,返程,坐火车,结束>,当扫描到第3个活动“坐火车”时,不能确定该活动是对应模型(图3)中的哪个“坐火车”变迁。α*算法是对α算法的扩展,在抽象活动之间关系的同时,记录了活动的上下文活动。因此,可通过上下文环境判断日志中的活动对应WF-net中的哪个变迁。
3.2 启发式算法
α及其扩展算法虽然分别能够处理各种控制流结构,但却不能处理日志中的噪声。而在实际应用中,日志中的噪声是不可避免的。噪声出现的原因可能是日志记录错误或流程执行异常等,日志噪声的存在将影响算法最终的挖掘结果。启发式算法[15,16]考虑流程实例在日志中出现的频率,可用于挖掘流程的主要行为,忽略各种细节或异常处理,也可用于处理日志噪声。启发式挖掘算法可处理的常用控制流结构:顺序、并行、选择、循环和非自由选择结构。启发式算法的流程表示是C-net(A,ai,ao,D,I,O)。
第一步 计算活动之间的依赖度,计算公式如下:
(1)
其中,|a>Lb|表示a>Lb在所有流程实例中出现的总次数。
长度为2的循环结构的依赖度的计算公式如下:
(2)
其中,|a≫Lb|表示序列
第二步 设定阈值,构造依赖图。假设包含五个活动a,b,c,d,e的执行日志L=[
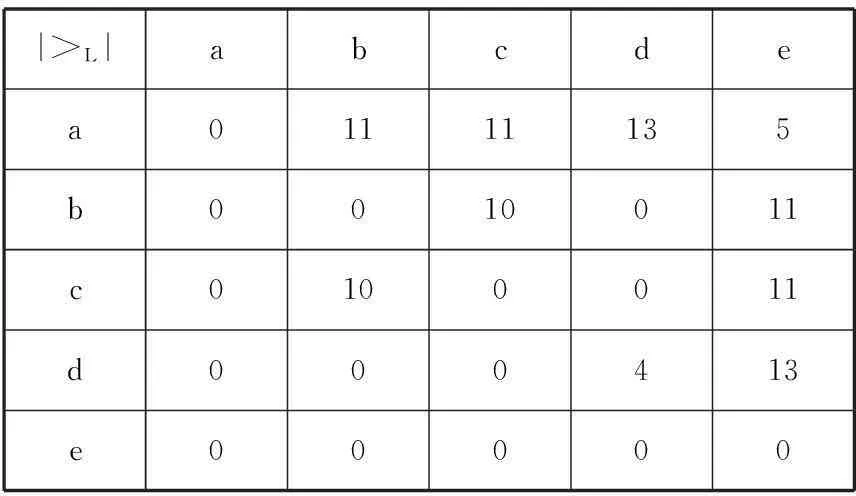
表3 活动直接相继执行的次数
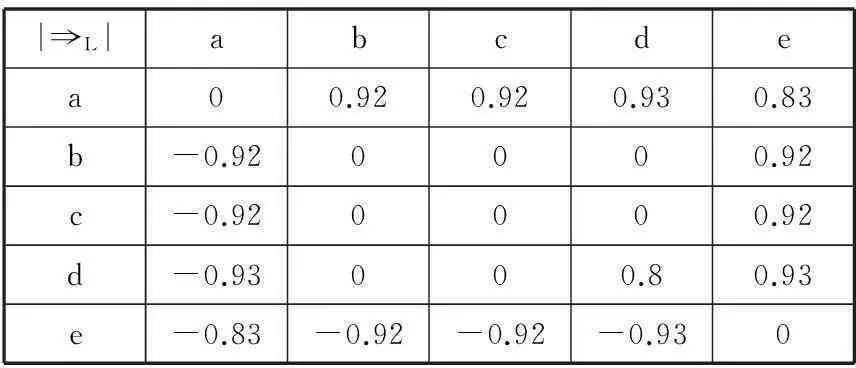
表4 各活动之间的依赖度

图4 C-net构造过程
第三步 在依赖图基础上进一步确定并行和选择分支。假设依赖图中活动a有三个输出b、c和e。如果b和e是并行结构,则序列
(3)

3.3 遗传算法
遗传算法[5,17]是一种模拟生物进化过程的搜索技术。首先,随机产生一组初始种群,利用适应值函数计算个体的质量,对质量优良的个体做杂交变异操作形成新一代种群。重复这一过程,直到满足终止条件。由于搜索空间不受限制,所以遗传算法可以同时处理各种控制流结构。基于遗传算法的流程挖掘的关键是:(1) 流程模型的表示方式;(2) 评价流程模型的适应值函数;(3) 遗传算子(杂交、变异)。
可用流程树[5]作为流程模型表示方式。遗传算法适应值函数将四个质量指标(见2.4节)综合起来,使得产生的结果模型具有较高的综合质量,适应值函数的计算公式为:
fitness=w1×Fr+w2×Pe+w3×Gv+w4×Sm
(4)
其中,Fr、Pe、Gv和Sm分别为流程模型在重现度、精确度、通用性和简单性四方面的计算值。w1、 w2、w3和w4分别是四个质量指标的权重。用户可以根据自己的偏好设置流程模型在这四方面的权重。利用适应值函数计算当前流程模型的适应值,按照一定比例将适应值最高的多个流程模型直接保留到下一代。其余的流程使用锦标赛方法选出并通过杂交变异产生。具体方法如下:
(1) 杂交
参与杂交的两棵流程树随机选择各自的子树进行交换。已知两棵流程树P1、P2,随机选中各自的一棵子树,如图5所示, P1选中子树st1, P2选中子树st2。将两棵子树交换后,得到两棵新的流程树P1′和P2′。
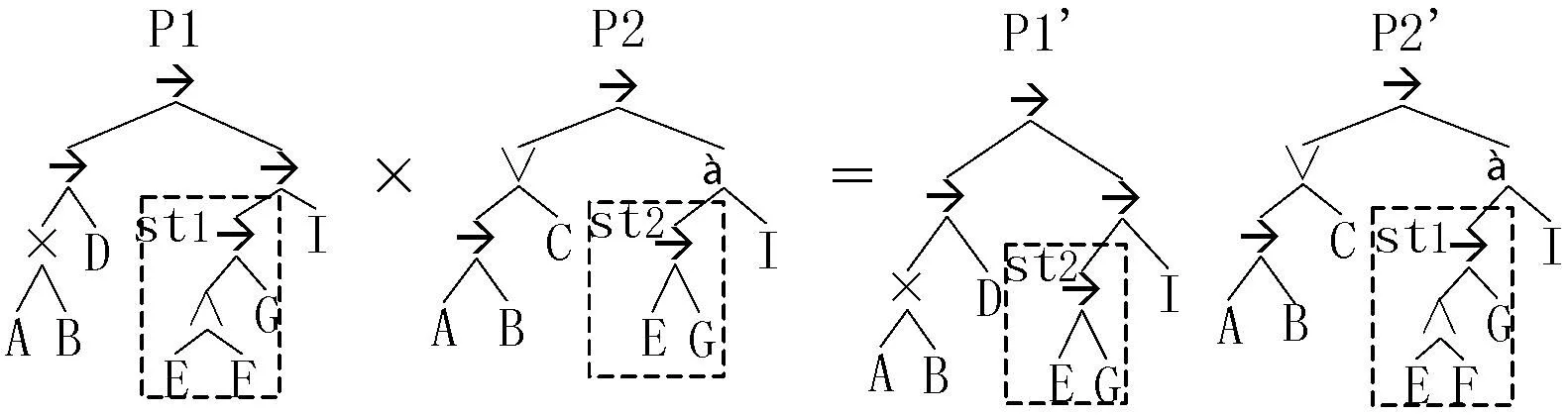
图5 流程树的杂交示意图
(2) 变异
变异分为以下三种情况:节点变异、删除活动节点、添加活动节点。
节点变异包括操作节点(非叶子节点)变异和活动节点变异。对于操作节点,改变其控制流结构类型;对于活动节点,改变其代表的活动类型。例如,将流程树P1中的代表并行结构的操作节点(节点E的父节点)变成顺序结构,变异结果如图6(b)所示;将P1中活动节点D的活动类型变成C,变异结果如图6(c)所示。
删除活动节点时,为了保证流程树的正确结构,有时需要同时删除其父节点。例如,要将流程树P1中的活动节点E删除,需要同时删除它的父节点,并将节点F变成节点G的兄弟节点,变异结果如图6(d)所示。
添加活动节点指随机产生一个活动节点,将它添加到任意一个操作节点下。为了保证流程树的正确结构,有时需要同时添加父节点。例如,在流程树P1中,将活动节点C添加到活动节点D的父节点下。在该父节点下创建一个同样代表顺序结构的操作节点,将节点C和D添加到该操作节点下,变异结果如图6(e)所示。
遗传算法虽然能够处理各种控制流结构和日志噪声,但由于初始种群是随机产生的,因此结果流程也具有随机性,可能得不到最优的流程模型。
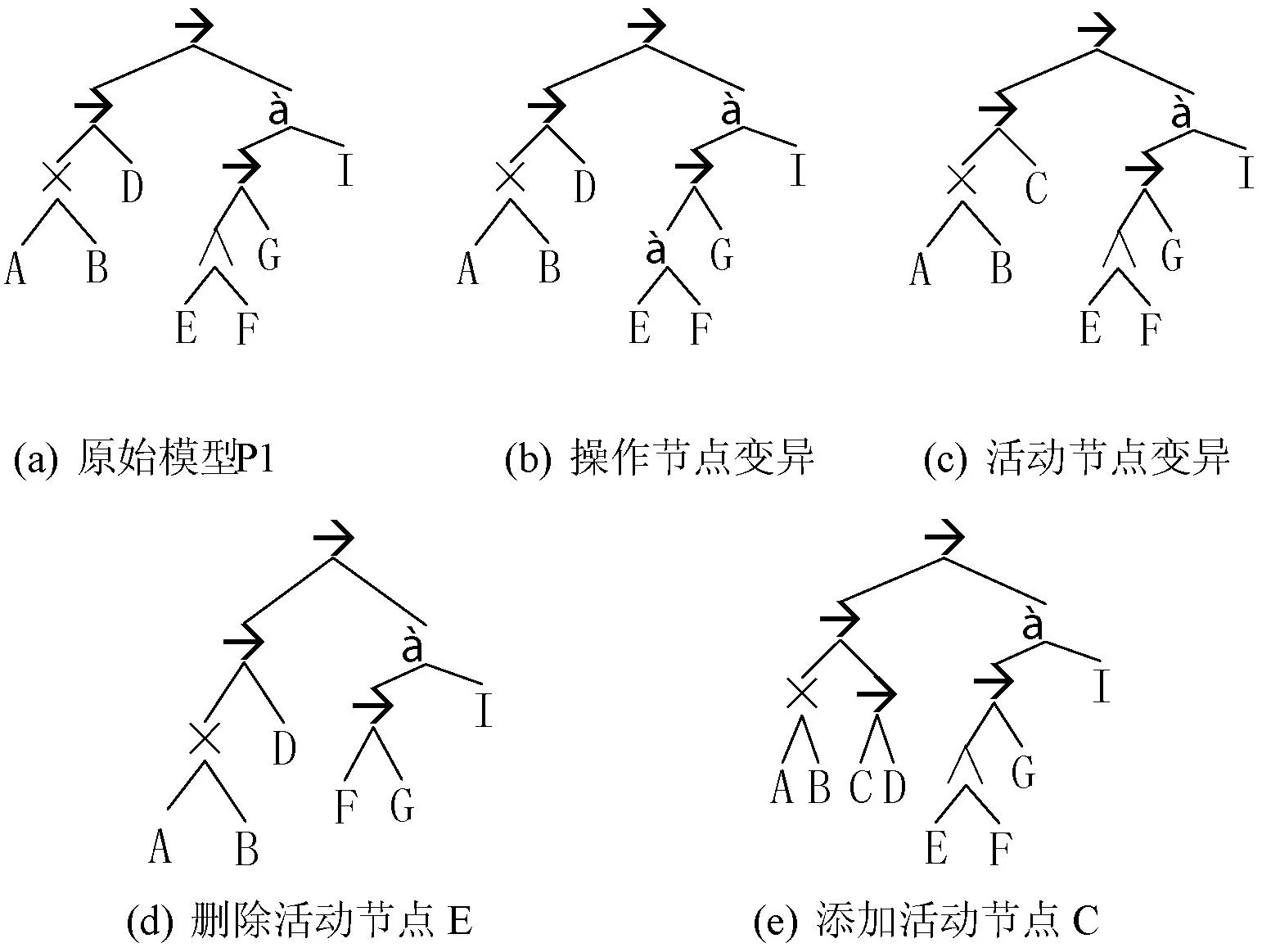
图6 流程树的变异示意图
3.4 基于日志分类的算法
日志的多样性导致已有的流程挖掘算法得到的流程结构错综复杂,难以理解。为了解决这个问题,一种方法是对日志中的执行实例进行聚类,将其划分成多个子日志,然后对各子日志施用已有的挖掘算法。这种方法的关键在于如何对执行实例进行聚类。聚类的好坏将影响最终的挖掘结果。
聚类的基本方法[8,18]是:根据某种规则构造执行实例的特征向量,如:实例中各活动(或一组活动)出现的次数、处理的数据对象或性能参数等。假设日志L=[

表5 执行实例的特征向量
利用已有的相似度计算方法,如:欧几里得距离、汉明距离、Jaccard距离等,计算各特征向量之间的相似度。利用已有的聚类算法对这些执行实例进行聚类,形成多个子日志。
采用以上方法对聚类后的子日志施用已有的挖掘算法得到的是局部流程。要得到完整的流程模型,可使用3.5节的方法挖掘层次流程模型。
3.5 基于执行模式的算法
解决日志多样性问题,还有一种方法是挖掘层次模型[19],挖掘步骤如图7所示。首先,通过分析日志中的所有执行实例,发现所有最大重复活动序列片段,即通用执行模式[20]。然后,通过活动映射得到通用执行模式的等价类[21]。利用Hasse图构造等价类之间的偏序关系。Hasse图的顶端节点即为模式摘要。
重新扫描日志,将所有执行实例中属于某摘要的通用执行模式用一个抽象活动代替。对处理后的日志施用已有的挖掘算法,得到完整的流程模型。其中,某些活动是抽象活动,代表子流程的位置。对属于同一模式摘要的所有通用执行模式施用挖掘算法得到子流程。

图7 层次模型挖掘示意图
已知通用执行模式有{ab,ac,bc,aad,add,aba,abc,acb,acd}。按照活动将它们映射成等价类[21]:[{a,b}]={ab,aba},[{a,c}]={ac},[{b,c}]={bc},[{a,d}]={aad,add},[{a,b,c}]={abc,acb},[{a,c,d}]={acd}。利用等价类之间的包含偏序关系构造Hasse图,如图8所示。
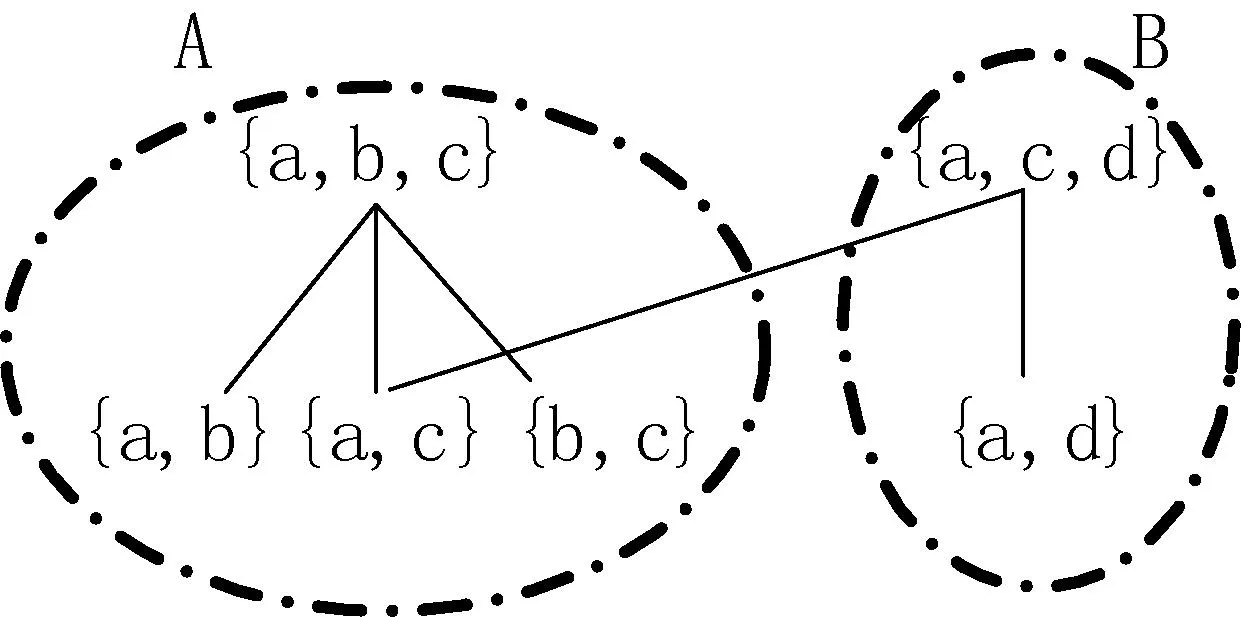
图8 等价类包含关系Hasse图
图8中,{a,b,c}和{a,c,d}是Hasse图中最上层的顶点,因此作为模式摘要。处理日志实例时,顶点{a,b,c}及其所覆盖的所有子节点{a,b},{a,c},{b,c}所对应的通用执行模式用抽象活动A表示;顶点{a,c,d}及其所覆盖的子节点{a,d}所对应的通用执行模式用抽象活动B表示。节点{a,c}同时被{a,b,c}和{a,c,d}包含,可人为规定{a,c}属于{a,b,c}。对抽象处理后的日志可进一步抽取模式摘要,用它对当前日志进一步处理得到新的抽象日志。不断重复以上操作,可获得各层次的抽象日志。对顶层日志施用已有的挖掘算法得到全局流程模型。对各层次的模式摘要所对应的通用执行模式施用挖掘算法得到各层次的子流程。
4 算法比较
第3节介绍了经典的流程挖掘算法的实现原理,以及它们各自的适用范围和局限性。本节将从日志完整性 (cmp),控制流结构,如:顺序结构(seq)、选择结构(cho)、并行结构(par)、循环结构(loo)、非自由选择结构(nfc)、重复活动(dup),以及噪声处理等方面对这些算法进行分析和比较,比较结果如表6所示。基于日志分类和执行模式的算法都是对日志进行预处理,挖掘阶段仍使用现有的流程挖掘算法,因此处理控制流结构的能力与选用的具体挖掘算法有关。
α算法只能处理长度大于2的长循环结构,而不能处理长度为1或2的短循环结构。因此,在表6中,α算法的“loo”项为“√/×”,表示只能处理部分循环结构。

表6 日志完整性要求和控制流结构比较
表7对从处理日志噪声、日志多样性和模型质量控制等方面对算法进行了比较。启发式算法和遗传算法能够处理日志噪声。模型质量方面,一般的流程挖掘算法得到结果流程模型后,可通过一致性检查计算四个维度的模型质量。而遗传算法可通过调节适应值函数中的权重控制结果模型在四个质量维度上的表现。基于日志分类和执行模式的算法能够很好地处理日志多样性问题。
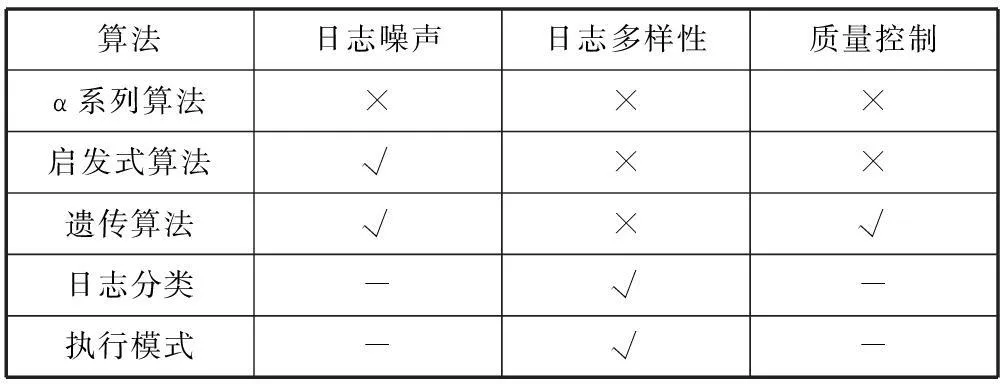
表7 日志噪声、多样性和质量控制比较
5 结 语
流程挖掘技术作为流程再设计和分析的一项关键技术,为流程变化管理和诊断提供了良好的解决方案。本文总结了流程挖掘中遇到的关键问题,介绍了5种流程挖掘算法,并从日志完整性、控制流结构、处理噪声、模型质量控制等方面对它们进行了分析和比较。
纵观全文,目前各种流程挖掘算法都有其各自的特色和适用范围。针对不同特征的日志,如何选择最佳的挖掘算法仍然是一项挑战。尤其是在处理复杂流程的多样性日志时,研究一种普适性的挖掘算法是未来的一个研究方向。除此之外,日志数据处理、解决特殊控制流结构和挖掘结果的可视化等将仍然是未来流程挖掘研究的发展方向。
[1] 赵卫东,范力.工作流挖掘研究的现状与发展[J].计算机集成制造系统,2009,14(12):2289-2296.
[2] Aalst W.Process mining:discovery,conformance and enhancement of business processes[M].Springer,2011.
[3] Demedeiros A,Alves K.Genetic Process Mining[D].Eindhoven:Technische Universiteit Eindhoven,2006.
[4] Aalst W.Petri-net-based workflow management software[C]//Proceedings of the NFS Workshop on Workflow and Process Automation in Information Systems,1996:114-118.
[5] Buijs J,Dongen B,Aalst W.A genetic algorithm for discovering process trees[C]//Proceedings of 2012 IEEE Congress on Evolutionary Computation,2012:1-8.
[6] Wen L,Aalst W,Wang J,et al.Mining process models with non-free-choice constructs[J].Data Mining and Knowledge Discovery,2007,15(2):145-180.
[7] Dongen B,Medeiros A,Wen L.Process mining:overview and outlook of petri net discovery algorithms[J].Transactions on Petri Nets and Other Models of Concurrency II,2009,5460:225-242.
[8] Song M,Christian W,Aalst W.Trace clustering in process mining[C]//Proceedings of Business Process Management Workshops,2009:109-120.
[9] Buijs J,Dongen B,Aalst W.On the role of fitness,precision,generalization and simplicity in process discovery[C]//On the Move to Meaningful Internet Systems (OTM 2012),2012:305-322.
[10] Aalst W,Adriansyah A,Dongen B.Replaying history on process models for conformance checking and performance analysis[J].Wiley Interdisciplinary Reviews:Data Mining and Knowledge Discovery,2012,2(2):182-192.
[11] Medeiros A,Dongen B,Aalst W,et al.Process mining for ubiquitous mobile systems:an overview and a concrete algorithm[C]//Ubiquitous Mobile Information and Collaboration Systems.Springer,2005:151-165.
[12] Wen L,Wang J,Sun J.Mining invisible tasks from event logs[C]//Advances in Data and Web Management.Springer,2007:358-365.
[13] Aalst W,Weijters T,Maruster L.Workflow mining:Discovering process models from event logs[J].IEEE Transactions on Knowledge and Data Engineering,2004,16(9):1128-1142.
[14] Li J,Liu D,Yang B.Process mining:Extending α-algorithm to mine duplicate tasks in process logs[C]//Advances in Web and Network Technologies,and Information Management.Springer,2007:396-407.
[15] Weijters A,Aalst W.Rediscovering workflow models from event-based data using little thumb[J].Integrated Computer Aided Engineering,2003,10(2):151-162.
[16] Weijters A,Aalst W,Medeiros A.Process mining with the heuristics miner-algorithm[J].Technische Universiteit Eindhoven,Tech.Rep.WP,2006,166:1-34.
[17] Bratosin C,Sidorova N,Aalst W.Discovering process models with genetic algorithms using sampling[J].Knowledge-Based and Intelligent Information and Engineering Systems,2010,6276:41-50.
[18] Bose R,Aalst W.Context aware trace clustering:towards improving process mining results[C]//Proceedings of SDM,2009:401-412.
[19] Bose R,Verbeek E,Aalst W.Discovering hierarchical process models using ProM[C]//IS Olympics: Information Systems in a Diverse World,Springer,2012:33-48.
[20] Bose R,Aalst W.Trace clustering based on conserved patterns:towards achieving better process models[C]//Proceedings of Business Process Management Workshops,2010:170-181.
[21] Bose R,Aalst W.Abstractions in process mining:a taxonomy of patterns[C]//Business Process Management,Springer,2009:159-175.
ON BUSINESS PROCESS MINING ALGORITHMS
Yang Liqin1,2Kang Guosheng2Cai Weigang1Zhou Qiang1
1(LibraryandInformationCenter,ShanghaiUniversityofTraditionalChineseMedicine,Shanghai201203,China)2(SchoolofComputerScience,FudanUniversity,Shanghai201203,China)
Process mining can reconstruct a process model according to the execution log of process, which conduces to the realisation of business process optimisation and intelligent management. This paper first presents the key problems of current process mining technologies to be solved. Then it encompasses a couple of typical process mining algorithms, by which the problems each one tackled and the shortcomings of each are indicated. This paper also gives analysis and comparison on these algorithms in terms of log integrity, control-flow structure, noise processing and quality control. Finally, a set of directions for future research in process mining technology is pointed out.
Process mining α algorithm Heuristic algorithm Genetic algorithm Log classification
2014-10-20。上海中医药大学预算内项目(2013JW 30)。杨丽琴,讲师,主研领域:业务流程管理,服务计算,医学信息。康国胜,硕士。蔡伟刚,讲师。周强,研究员。
TP3
A
10.3969/j.issn.1000-386x.2016.04.011
