一种新的维吾尔文文本分类特征选择方法
2016-05-05哈力旦阿布都热依木阿丽亚艾尔肯吴冰冰
何 燕,哈力旦·阿布都热依木,阿丽亚·艾尔肯,吴冰冰
(新疆大学 电气工程学院,新疆 乌鲁木齐 830047)
一种新的维吾尔文文本分类特征选择方法
何燕,哈力旦·阿布都热依木,阿丽亚·艾尔肯,吴冰冰
(新疆大学 电气工程学院,新疆 乌鲁木齐 830047)
摘要:针对传统卡方统计量方法对特征项的频数和类别分布考虑不足的缺陷,提出了一种结合余弦相似度的卡方统计量特征选择方法。该方法首先使用均值词频-逆文档频率表示特征项,通过引入一个调整公式来平衡类间选取的特征项数,从而对传统卡方统计量方法进行修正,然后结合余弦相似度进一步消除噪声文本。在收集的维吾尔文数据集上进行实验论证。实验结果表明:改进的卡方统计量方法具有较好的鲁棒性,且分类性能优于传统的卡方统计量方法。
关键词:维吾尔文;卡方统计量;余弦相似度;特征选择
0引言
文本分类是从一系列数字文档中找到相关和及时信息的关键技术。随着新疆地区信息化建设的飞速发展,网络上包括维吾尔文等少数民族语种的大量数字化信息呈现指数级增长趋势。如何有效管理和利用这些纷繁杂芜的海量信息,并对大量少数民族语种文本数据进行自动归类,是当前重要的研究课题之一[1]。
特征选择是将能够有效表达文本内容的特征挑选出来建立学习样本,保留重要的信息,去除冗余信息,以降低特征空间维度的过程。一个好的学习样本是训练分类器的关键,样本中是否含有不相关或冗余信息直接影响着分类器的分类精度和泛化性能[2]。因此,寻求一种好的特征选择方法是提高文本分类性能的有效途径。
卡方统计量(chi-square statistic,CHI)方法以其时间复杂度低、便于理解和应用方便等优点已经成为文本分类中常用的特征选择模型。目前,针对CHI模型进行的改进研究受到了越来越多的关注[3-4]。文献[5]通过引入最大词频和采样方差对传统CHI方法进行修正,针对特征数目的不同,提出了两种基于词频和特征项分布的CHI特征选择方法。文献[6]通过设置最低词频阈值去除部分低频词对CHI的干扰,并将改进后的CHI特征选择公式引入特征权重计算中,不仅使文本表示更合理,而且有效提高了文本分类的准确率。文献[7]在不平衡的维吾尔文数据集上,提出了一种结合逆文档频率的改进卡方统计量方法。这些改进方法在中英文的文本分类中取得了很好的效果,但维吾尔文的语种特点[8]与中英文不同,采用该类方法不能达到很好的分类效果。因此,针对CHI的优缺点和维吾尔文语种特点进行深入研究,建立针对维吾尔文文本分类的新模型具有重要意义。本文通过分析传统CHI的优缺点,提出了一种新的结合余弦相似度的CHI特征选择方法,不仅克服了传统算法对低频词的偏袒以及特征项的类别分布不均匀问题,而且提高了分类性能。
1卡方统计量方法
卡方统计量(CHI)方法就是通过观察实际值与理论值的偏差来确定理论的正确与否。假设词条tk与类ci之间的独立关系服从具有一个自由度的χ2分布[9]。
假定T={tk|k=1,2,…,m}为训练样本集的特征集;ci为第i类训练样本,i=1,2,…,n。tk对于类ci的卡方统计量可表示为:
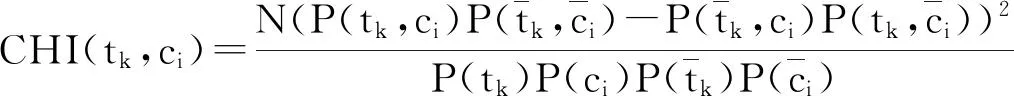
(1)
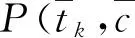
当特征项tk与类ci越相关时,其对应的CHI(tk,ci)值越大,代表特征项tk对分类的贡献越大;反之,特征项tk与类ci相互独立时,其对应的CHI(tk,ci)=0,代表特征项tk不包含任何有关类ci的信息。
对于多个类别的问题,应分别计算特征项tk对于每个类别的CHI(tk,ci),再对计算结果进行综合。综合的方式一般有两种:一种是加权平均,另一种是取最大值。本文选择取最大值的方式进行综合。
由式(1)可知CHI方法是基于文档频率(document frequency,DF)的特征选择方法,只考虑特征项在文档中是否出现,会更加偏向于将DF值高的词作为特征。
同时,在对多个类别进行分类时,若设定的阈值不合适,CHI容易选择对某特定类别区分度低而对其他类别具有强区分度的特征项,会导致某些类别选择的特征项过多或过少。
2改进的CHI特征选择方法
2.1特征项频数的改进
为解决传统卡方统计量容易忽略文档频数低而词频高的缺陷,在传统的CHI特征选择的基础上,引入均值词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)特征权重计算来进行调节。
TF×IDF(k,j)=tfkj×idfj=tfkj×log(N/nj) ,
(2)
其中:tfkj为特征项tk在文档dj中出现的次数;idfj为包含特征项tk的逆文档频率;N为总文档数;nj为出现特征项tk的文档数。
本文采用均值TF-IDF来表征每个特征项,如下所示:

(3)
其中:Count(j)为数据集中文档的总数目。此时,可将式(1)改进为式(4):
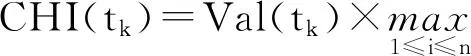
(4)
2.2特征项类别分布的改进
一般而言,具有较强类别表现能力的特征项在该类别内的频数不仅应该较大,而且这些特征项的数目在其相应的类内应保持均衡,这样不会使得某一个类别中最终保留的特征项过多或者过少。
引入以下公式,使得各个类中选取的特征项数均等,以保留更多的具有强区分度的特征项。
(5)
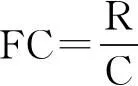
(6)
其中:CHIL(tk)为最终保留的特征项;CHI↓(tk)为文档集中降序排列的卡方值;N(ci)为ci类中包含保留的特征项tk的个数;FC为每个类中预选择的特征个数;R为整个语料库中缩减的特征项数目;C为类别的数目。
文献[10]提出使用CHI方法去权衡相似度,以及使用CHI测试来确定文本分类中两个随机样本中词向量的同质性,发现CHI和余弦相似性相结合可以提供更加可靠和有效的分类机制。文献[11]在改进的CHI的基础上采用余弦相似度计算阿拉伯文本间相似度,分类准确率明显提高。
因此,为了进一步消除文本噪声,引入余弦(Cosine)相似定理来计算文本间的相似度。计算公式如下:

(7)
其中:Di=(wi1,wi2,…,wiN);Dk=(wk1,wk2,…,wkN);wij,wkj分别为文本Di,Dk中的第j个特征词的TF-IDF权值;N为特征向量的维数。每篇文档作为一个向量,向量中的每一维就是文本中每个特征词的权重。计算两篇文档的相似度,当向量夹角的余弦值越接近于1,表明两篇文档越相似;反之,两篇文档越不相关。
为了解决个别噪声文档对分类准确率的影响,引入以下公式:

(8)

(9)
(10)
其中:S1为类内文档余弦相似度的平均值,这里忽略文档Di的自身余弦相似度值;Ncj为类Cj中包含的文档数;S2为文档Di与其他类中文档余弦相似度平均值。假设S1低于阈值α并且S2高于阈值β,那么文档Di不能有效表达所属类的信息,却与其他类相关,即认为该文档不适合用来表征所属类别的信息,应删除以减小带给分类器的噪声。
3实验与分析
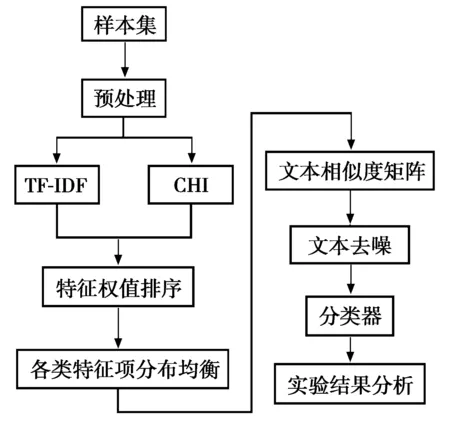
图1 改进的CHI方法的具体实现流程图
实验是在Intel(R) Core(TM) i5-4200U处理器、4 GB内存,操作系统为Windows 7的PC机上进行的,使用eclipse作为开发环境。
为了考察CHI的改进效果,在相同的实验条件下,将改进的CHI(CHI+Cosine)方法与传统卡方统计量(CHI)方法进行实验对比。改进的CHI方法的具体实现流程如图1所示。
3.1实验数据集
目前,针对中英文的文本分类研究,国内外已经有相对标准的、开放的文本分类语料库作为参考,可以在相同的数据集上比较不同的特征选择和分类方法的性能。由于维吾尔语文本分类的研究仍然处于起步阶段,因而目前并没有标准的、开放的维吾尔语文本集作为统一的参考。实验中所使用的维吾尔文文本数据为本实验室采集,数据来源于新疆政府网、天山网和Ulinix等主要维吾尔语门户网站[12]。实验数据描述见表1。

表1 维吾尔文文本数据集信息描述
3.2分类性能评估
本文选取常用的准确率、召回率和F1值作为实验评价指标[13]。这里假设a为属于类Ci而被分至类Ci的文档数;b为属于类Ci而被分至非类Ci的文档数;c为不属于类Ci而被分至类Ci的文档数;d为不属于类Ci而被分至非类Ci的文档数。那么,准确率p和召回率r定义为:

(11)
F1值为关于r和p的函数,是两者的调和平均值,具体计算公式为:
(12)
宏平均F1值 (Macro-F1)是每个类别性能指标F1值的算术平均值,计算公式为:
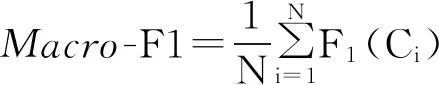
(13)
本文采用宏平均F1值来综合衡量分类效果。
3.3实验结果
维吾尔文与中文不同,却相似于英文。对于维吾尔文来说,不存在分词的问题,因为词语之间已经自然地用空格隔开。通过去除非维吾尔语文本以及停用词等预处理之后,建立了由77 591个特征项组成的候选特征项集合。分别采用两种算法(CHI方法和CHI+Cosine方法)对预处理后的数据集进行特征选择,最后采用开放数据挖掘WEKA平台的LibSVM分类算法进行分类。其中,α取值为0.2,β取值为0.7。为测试算法的准确性,这里采用十折交叉验证方法。
特征维数为3 000的情况下,CHI方法以及CHI+Cosine方法在每个类别中的分类准确率,如表2所示。
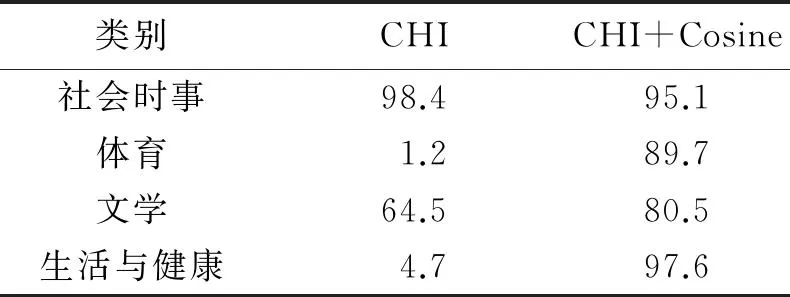
表2 两种方法的分类准确率对比 %
在表2的4类实例数据中,CHI+Cosine方法与CHI方法相比,除了社会时事类别,其他类别维吾尔文文本分类的准确率均有不同程度的提高,尤其是体育类和生活与健康类提高效果显著。由表2数据可知:CHI方法在特征项数目保留过低时,如体育类和生活与健康类的特征包含较少,因而导致其分类准确率过低,而CHI+Cosine方法刚好克服了这一缺点。
图2是支持向量机(support vector machine,SVM)分类器采用CHI和CHI+Cosine两种特征选择方法,在实验数据集上的Macro-F1曲线。从图2a中可以看出:在特征数低于4 000时,CHI+Cosine方法的分类性能已经远远高于CHI方法。这是因为改进的CHI+Cosine方法在选取的特征数目较低时,明显克服了传统CHI方法选择的特征项在某些类别中过多,而在其他类别的特征项数目过少的不足。从图2b中可以看出:CHI+Cosine方法在特征数为45 000时,使分类器的性能达到最优并趋于稳定;CHI方法在选取35 000个特征时,分类器的Macro-F1值达到最高(0.930)。而且随着特征数目的变化,CHI+Cosine方法使得分类器的性能始终优于CHI方法。
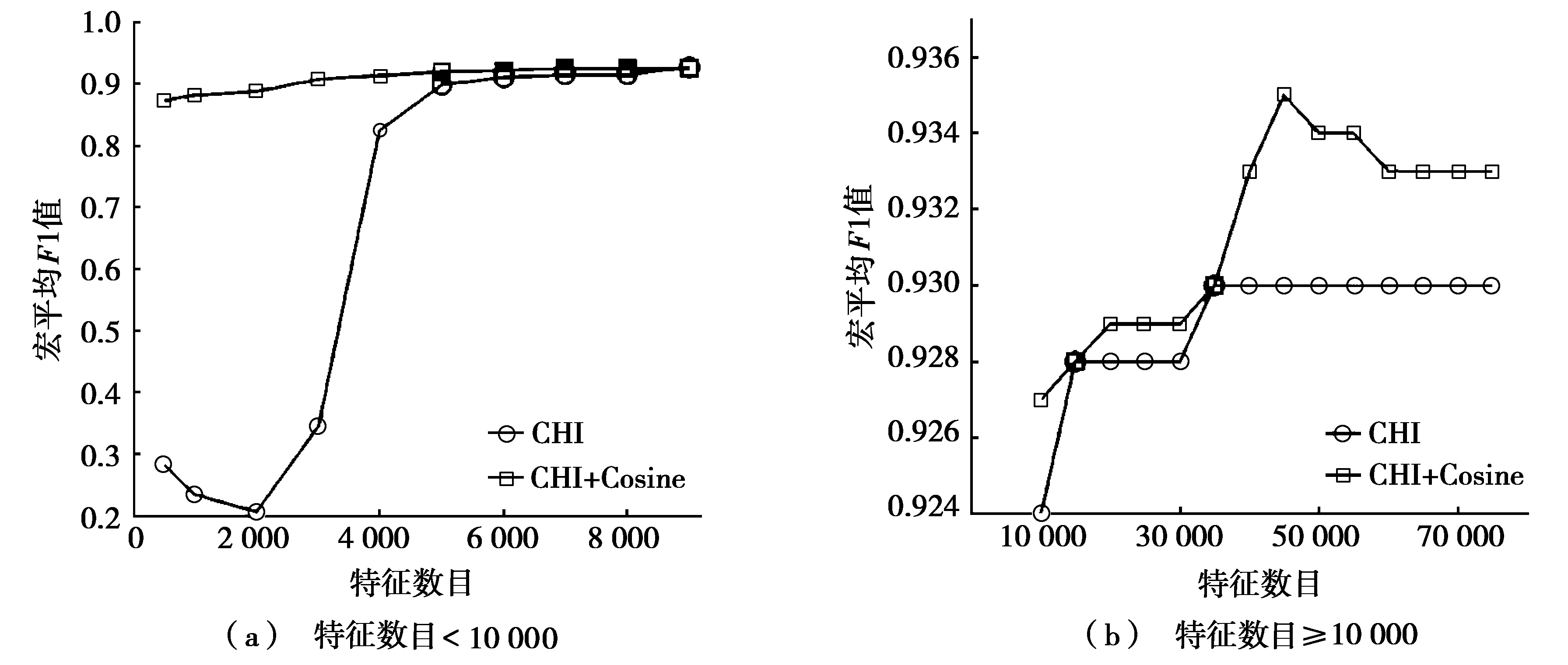
图2 采用两种不同特征选择方法的SVM分类器性能比较
4结束语
本文提出了一种结合余弦相似度的卡方统计量方法,分别从特征项出现的频数以及类别分布对CHI算法进行修正。通过引入一个调整公式来平衡类间选择的特征数目,避免某一个类别中最终保留的特征项过多或者过少,解决了传统CHI方法对低频词的偏倚以及特征项的类别分布的问题。在开放数据挖掘平台WEKA中,使用LibSVM对收集的维吾尔文数据集进行分类,改进的CHI+Cosine方法使得分类器性能优于传统的CHI方法,具有很好的鲁棒性,有效地克服了传统CHI方法在选择较少特征数目时分类性能过低的问题。
参考文献:
[1]艾海麦提江·阿布来提,吐尔地·托合提,艾斯卡尔·艾木都拉.基于Naive Bayes的维吾尔文文本分类算法及其性能分析[J].计算机应用与软件,2012,29(12):27-29.
[2]姚旭,王晓丹,张玉玺,等.特征选择方法综述[J].控制与决策,2012,27(2):161-166,192.
[3]邱云飞,王威,刘大有,等.基于方差的CHI特征选择方法[J].计算机应用研究,2012,29(4):1304-1306.
[4]王光,邱云飞,史庆伟.集合CHI与IG的特征选择方法[J].计算机应用研究,2012,29(7):2454-2456.
[5]JIN C,MA T,HOU R,et al.Chi-square statistics feature selection based on term frequency and distribution for text categorization[J].IETE journal of research,2015,61(4):1-12.
[6]肖雪,卢建云,余磊,等.基于最低词频CHI的特征选择算法研究[J].西南大学学报(自然科学版),2015,37(6):137-142.
[7]董瑞,周喜.面向维吾尔文不平衡数据分类的特征选择方法[J].计算机工程与设计,2013,34(1):349-352.
[8]李敏强,哈力旦·阿布都热依木,闫轲.一种改进型局部二值模式的维吾尔文定位算法[J].河南科技大学学报(自然科学版),2015,36(3):43-47.
[9]李明江.结合类词频的文本特征选择方法的研究[J].计算机应用研究,2014,31(7):2024-2026.
[10]CHEN Y T,CHEN M C.Using chi-square statistics to measure similarities for text categorization[J].Expert systems with applications,2011,38(4):3085-3090.
[11]HAEASHIN B,MANSOUR A M,ALJAWARNEH S.An efficient feature selection method for Arabic text classification[J].International journal of computer applications,2013,83(17):1-6.
[12]陈洋,哈力旦·阿布都热依木,伊力亚尔·达吾提,等.基于加权改进贝叶斯算法的维吾尔文文本分类[J].计算机工程与设计,2014,35(6):1999-2003.
[13]伍洋,钟鸣,姜艳,等.面向审计领域的短文本分类技术研究[J].微电子学与计算机,2015,32(1):5-10.
中图分类号:TP391.1
文献标志码:A
收稿日期:2015-09-02
作者简介:何燕(1991-),女,新疆塔城人,硕士生;哈力旦·阿布都热依木(1959-),女,维吾尔族,新疆乌鲁木齐人,教授,硕士生导师,主要从事图像处理、数据挖掘等方面的研究.
基金项目:国家自然科学基金项目(61163026,60865001)
文章编号:1672-6871(2016)03-0042-05
DOI:10.15926/j.cnki.issn1672-6871.2016.03.010
