高效低存储DWT的VLSI结构设计
2016-05-05董明岩王柯俨李云松
董明岩,雷 杰,王柯俨,李云松
(西安电子科技大学综合业务网理论及关键技术国家重点实验室,陕西西安 710071)
高效低存储DWT的VLSI结构设计
董明岩,雷 杰,王柯俨,李云松
(西安电子科技大学综合业务网理论及关键技术国家重点实验室,陕西西安 710071)
摘要:随着航天器载荷相机图像分辨率的日益提高,迫切需要解决海量图像数据的在轨高速编码处理问题,空间数据系统咨询委员会提出了一种面向空间应用的图像编码标准.为了保证较高的图像编码性能,该标准采用小波的变换方法.小波变换的多级变换形式比较耗时,且需要较大的存储开销.针对这一问题,提出了一种高效低存储离散小波变换的超大规模集成电路结构.通过改进传统的小波提升结构,将二三级变换和缓存结构进行复用,在不降低数据处理速度的情况下,节省了逻辑资源开销;使用少量片上存储资源存储部分小波系数,按特定顺序连续地输出给后级熵编码器进行处理,避免了使用片外存储.所提出的超大规模集成电路结构在Xilinx型号为XC4VSX55的现场可编程门阵列得到了硬件实现,具有95.91 MPixels/s的数据处理性能.
关键词:图像处理;离散小波变换;现场可编程门阵列;超大规模集成电路
针对空间星载应用环境,空间数据系统咨询委员会(The Consultative Committee for Space DataSystems,CCSDS)提出了一种基于离散小波变换(Discrete Wavelet Transform,DWT)和分块比特平面熵编码的图像数据压缩标准(Image Data Compression,IDC).该标准兼顾了算法压缩性能和计算复杂度,以较低的计算复杂度取得了接近于JPEG2000的图像压缩性能[1].其核心组成部分的DWT具有便于图像渐进式传输、能量集中性好等优点[2],与离散余弦变换和离散傅里叶变换相比,在没有视觉质量巨大损失的情况下可提供显著的压缩比[3].传统DWT硬件结构为卷积结构,其运算量大,逻辑资源消耗多[4],而基于提升结构的DWT在一定程度上降低了计算复杂度,但是其多步提升和多级变换形式需要耗费较多的计算时间,且需要较大的片外存储空间.
为此,国内外学者进行了相关研究,并提出了一些降低DWT计算时间和资源开销的优化方法,文献[5]采用两个并行的一维DWT模块同时处理,用资源换取速度,文献[6]采用翻转结构提高时钟频率,文献[7-8]通过流水线设计提高数据处理速度.文献[5-8]虽然在一定程度上提高了数据处理速度,但却增加了逻辑资源开销.文献[9]通过复用一级DWT变换结构,降低了逻辑资源开销,但却未能提高数据处理速度.
因此,基于CCSDS-IDC的算法原理,在保证高速实时DWT数据处理的情况下,如何能更多地减少逻辑和存储资源,仍然是亟需解决的问题.针对该问题,笔者以9/7 DWT为例,提出一种高效低存储DWT的超大规模集成电路(Very Large Scale Integration,VLSI)结构,采用两个变换模块,第1个变换模块完成第1 级DWT行列变换,第2个变换模块以时分复用方式完成第2级和第3级DWT行列变换,两个变换模块并行工作,在保证实时数据处理速度的同时节约逻辑资源.此外,基于CCSDS-IDC分块比特平面熵编码的特点,使用少量片上存储替代片外存储,在DWT处理过程中,以流水线的方式将小波系数按特定顺序连续地输出给后级熵编码器进行处理.
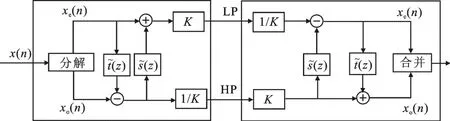
图1 正反提升小波变换原理框图
1 DWT的原理及分析
1.1 DWT提升结构原理
相比于传统的卷积结构,DWT提升结构在内存利用率和读取次数上都具有优势.提升小波的原理是将多相位小波滤波矩阵分解为两个连续的上三角矩阵、下三角矩阵及1个对角矩阵[10],即
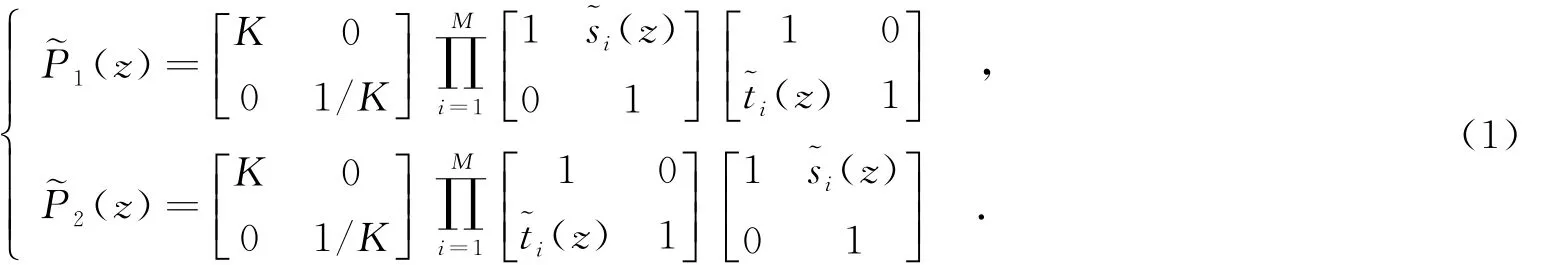
式(1)中两个等式分别对应于DWT的正变换及反变换,其结构的原理框图如图1所示,其中,xe(n)为偶样本,xo(n)为奇样本.
CCSDS-IDC采用的基于提升的9/7 DWT,其具体实现方式为
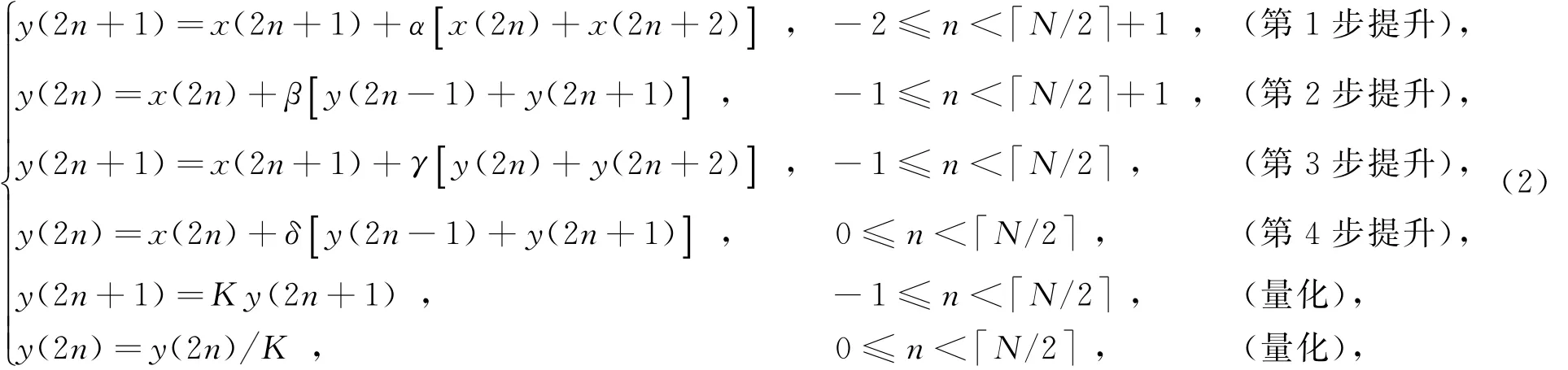
其中,x(n)为输入的图像数据,y(n)为按交织方式存放的小波系数,y(2n)为低通系数,y(2n+1)为高通系数,常系数α≈-1.586,β≈-0.053,γ≈0.883,δ≈0.444,K≈1.149.图像的DWT行变换与列变换都需要完成与式(2)相同的运算过程,行变换之后的结果再经过列变换才能完成1级DWT,1级DWT之后可以得到H H、HL、LH和LL共4个小波子带,选择其中的LL子带进行下一级DWT处理.依此方式,经过3 级DWT可以得到10个子带,分别为3级输出的HH,HL,LH等9个子带及第3级输出的LL3子带.
10个子带的小波系数按照分层树的结构形式组织成独立的单元块,每个单元块中包含64个小波系数,包括1个直流电(Direct Current,DC)系数(LL3子带)和63个交流电(Alternating Current,AC)系数(来自其余9个子带).读取64个小波系数顺序为:LL3→HL3→LH3→HH3→HL2→LH2→HH2→HL1→LH1→H H1,第1、2、3级读取数据比例为16∶4∶1.
1.2 DWT多级变换的原理分析
DWT的第1级变换是对原始图像进行处理,而第2级变换是对第1级变换后得到的LL1子带进行处理,LL1子带的宽度和高度分别是原始图像宽度和高度的1/2,其分辨率大小是原始图像的1/4.对于分辨率为N×N的图像,若采用行列并行结构,那么完成第1级DWT需要近N2个时钟,而对于第2级和第3级DWT,其需要消耗的处理时间分别约为N2/4和N2/16个时钟.显然,第2级和第3级所需要的处理时间之和小于第1级所需的时间,即N2/4+N2/16<N2.由此可知,从处理时间上看,将第2级和第3级DWT可以时分复用同一个DWT模块,并可以与第1级DWT并行处理.实际上,由等比数列的求和公式可知,第2级及以上级的DWT所消耗的处理时间总和永远不会超过N2个时钟,即永远不会超过第1级DWT消耗的时间,所以,第2级及以上级二维DWT都可以时分复用同一个变换模块.基于此分析,文中设计了第2级和第3级DWT时分复用变换模块的VLSI结构.该结构具有良好的扩展性,只需要简单的控制参数修改便可适用于变换等级为2级以上的任意多级小波变换,也可应用于与9/7 DWT形式类似的5/3 DWT.
2 多级复用高速DWT的VLSI结构
2
.1 乘加器复用的DWT单步提升结构
对于DWT的提升结构,其各步提升均可采用同一种单步提升结构.这一点从式(2)所示的4步提升公式也可以看出,即各步提升的计算过程近似相同,均含有两次加法和1次乘法运算.其区别仅是各步输入的乘法系数互不相同.第1步提升过程的计算方法为
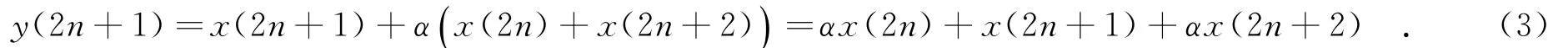
通过简单变形,可以看出,该提升过程可分为两次计算,即
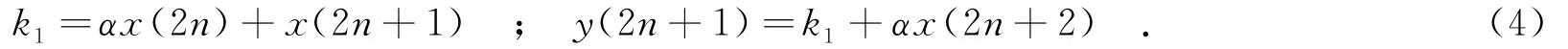
通过采用两次计算方式,可将乘法器和加法器进行时分复用,通过选择控制的方式由同一电路结构完成两次计算.
基于以上分析,设计了如图2(a)所示的电路结构,该结构由5个选择器、1个移位器、1个乘法器、1个加法器和1个寄存器构成.当两个数据到来时,该结构开始进行运算,将运算的中间结果k1存入图2(a)所示的寄存器中,在此结构中,对需要进行边界拓展的数据进行左移1位的操作.
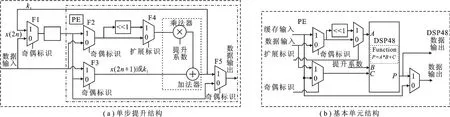
图2 PE的硬件结构图
图2(a)所示的DWT单步提升结构可划分为两个组成部分,即存储和运算部分,其中的运算部分是虚线标注的运算处理单元(Processing Element,PE).对于行变换和列变换,它们的PE结构相同,只是所用的存储结构不同.行变换使用D触发器存储数据,而列变换使用双端口随机存取存储器(Random Access Memory,RAM)存储数据.在Xilinx Virtex4之后的FPGA型号系列中,内嵌有DSP48的IP硬核可以实现乘加运算,具有更高的速度性能、更低的功耗和更佳的资源开销,用其代替图2(a)中的乘法器和加法器,可得到速度更快、面积更小的PE硬件结构,如图2(b)所示.
2.2 行变换电路结构
9/7 DWT的4步提升计算均可使用相同的单步提升PE结构来完成,只是输入数据和提升常系数不同.为提高4步提升的计算速度,通过将4个独立的单步提升PE结构级联起来并行计算,便可实时地实现1次行变换,如图3(a)所示.由图2(b)可知,数据输入到数据输出之间存在较长的存组合逻辑路径,如果将两个PE直接级联,将形成一块路径更长的组合逻辑,这会导致组合逻辑时延变大,降低系统的最大时钟频率.为避免该问题,在图3(a)所示的行变换结构中加入了流水线(Pipeline)设计,通过插入D触发器来缩短组合逻辑路径,即在PE之间使用D触发器进行连接.
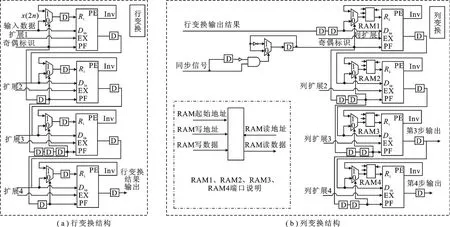
图3 行变换和列变换电路结构图
图3(a)中的奇偶标识信号将输入数据区分成两部分,分别为偶数位置数据x(2n)和奇数位置数据x(2n+1).第1步提升输出偶数位置的数据仍为x(2n),而奇数位置的数据是y(2n+1).当输入第1行第1个数据s时,数据存入第1个PE左端的寄存器中.输入第2个数据d时,读取上次存入寄存器中的数据s,用s与d进行运算,得到第1步提升的中间结果Inv,再将Inv重新存回该寄存器中,同时,行变换的第2步提升启动,将s写入第2个PE左端的寄存器中.以此方式按行进行小波变换.
2.3 列变换电路结构
行变换结果经过两个寄存器进入列变换模块,为实现行列并行运算,列变换需要对整行数据进行操作,因此,输入数据的缓存和中间结果的缓存不能使用寄存器存储,而需要使用双端口RAM存储整行数据.当输入第2行第1个数据时开始进行列变换,因此,RAM只需要缓存1行数据.列变换结构如图3(b)所示,对于第2级及以上级DWT,RAM需要缓存各级的中间结果,因此,需要标记各级DWT的起始地址.
2.4 多级复用DWT及小波系数缓存处理电路结构
行变换结构与列变换结构级联实现1级DWT.由1.2节分析可知,高级别DWT可时分复用同一个DWT模块来实现,该时分复用方法会增加一些控制模块的逻辑资源,相比于第1级DWT,所增加的逻辑资源是非常少的.复用控制模块功能主要包括产生奇偶标识信号、级别标识信号和RAM控制信号.因为高级别DWT会共用相同的数据线,所以需要一个级别标识信号来表明当前进行的DWT级别.文中所实现的多级DWT复用结构,通过简单的参数修改,便可应用于变换等级为二级以上的任意多级小波变换.
根据分块比特平面熵编码的特点,当LL3数据到来时即可开始进行熵编码.换句话说,缓存少量的小波系数便可将其按特定顺序输出给熵编码器进行处理,而不需要等到所有小波系数都得到之后才开始熵编码.因此,文中将DWT与熵编码之间的缓存使用片内双端口RAM来实现,而不用片外DRAM存储器,这样可以节省大量的片外存储资源.由于使用RAM需要额外的控制逻辑,RAM的个数应该尽量少.文中将各级输出的LH和HH分量合并到一起,从而减少RAM的个数,因此,共用了3个双端口RAM(如图4所示的RAM5,RAM6,RAM7)来缓存DWT最终得到的小波系数,并在条件满足时及时地将这些小波系数输出给后级熵编码器进行处理.将RAM5划分为6块存储区域,分别存储各级输出的HH和LH子带数据,将RAM6划分为3块存储区域,存储各级输出的HL子带数据,而RAM7只存储第3级输出的LL3子带数据.小波系数缓存处理结构如图4所示,通过子带分离器将输出的小波系数分离,并乘以相应的K系数.通过写控制器将数据写入对应的存储器中,并且3个RAM写入数据时的地址变化由同一份逻辑产生,可进一步节约逻辑资源.读控制器根据LL3同步信号判断读取的起始时间,3个存储器的读取结果进行或运算作为进入熵编码器的输入数据,其同步信号是通过将各个存储器读使能信号进行或运算并延迟1个时钟得到的.
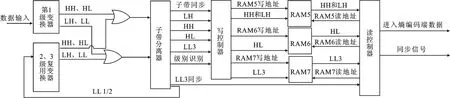
图4 DWT系数处理结构图
3 性能与仿真
将文中提出的9/7 DWT提升结构与其他文献所提出的结构进行对比,在逻辑规模和计算时间等方面的对比结果如表1所示.表1中,Tm和Ta分别代表乘法器和加法器时延,S为并行处理单元的个数,图像的分辨率为N×N.由表1可以看出,文中结构所需存储器、加法器和乘法器都相对较少,关键路径也很短.相对于乘法器和加法器使用较少的文献[11-13],其输出时延也是最短的.
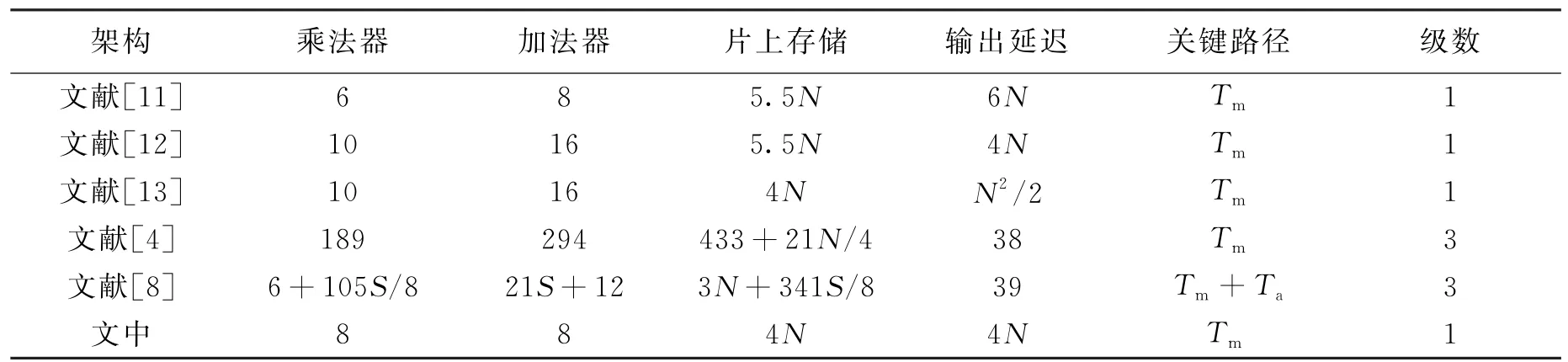
表1 DWT资源以及性能对比
文中所提出的VLSI结构在Xilinx型号为XC4VSX55的现场可编程门阵列(Field Programmable Gata Array,FPGA)中得到了硬件实现,具有95.91 MPixels/s的数据处理性能.表2为文中结构与其他文献Slices资源的对比情况,由表2可以看出,文中结构在分辨率、位宽和级数等指标都较大的情况下,消耗FPGA的Slices资源最少,且不需要片外缓存.由此可见,文中结构有明显的资源优势.

表2 DWT的Slices资源对比
4 结束语
通过DWT提升结构复用和级间复用,在保证数据处理速度的同时减少了逻辑资源的使用.此外,根据分块比特平面熵编码的特点,改变了传统的DWT输出数据缓存处理方式,将输出数据所需的片外存储资源用片内少量RAM缓存替换,在不降低处理速度的情况下,节省了片外存储,减少了系统体积和功耗,非常适合空间环境下图像数据高速处理的应用需求.
参考文献:
[1]李进,金龙旭,韩双丽,等.适于空间TDICCD相机的图像压缩系统设计[J].电子技术应用,2013,39(1):17-19.LI Jin,JIN Longxu,HAN Shuangli,et al.Design of Image Compression System for Space TDICCD Camera[J].Application of Electronic Technique,2013,39(1):17-19.
[2]王前,吕东强,李晶,等.新型9/7小波基构造及快速实现[J].电子与信息学报,2009,31(5):1210-1213.WANG Qian,LÜ Dongqiang,LI Jing,et al.New Construction for 9/7 Wavelet Basis and Fast Implementation[J].Journal of Electronics and Information Technology,2009,31(5):1210-1213.
[3]SANI J,MANU J.Optimized Implementation of Discrete Wavelet Transform with Area Efficiency[C]//Proceedings of the IEEE International Multi-Conference on Automation,Computing,Control,Communication and Compressed Sensing.Washington:IEEE Computer Society,2013:796-800.
[4]MOHANTY B K,MEHER P K.Memory-efficient High-speed Convolution-based Generic Structure for Multilevel 2-D DWT[J].IEEE Transactions on Circuits and Systems for Video Technology,2012,23(2):353-363.
[5]DARJI A,SHUKLA S,MERCHANT S N.Hardware Efficient VLSI Architecture for 3-D Discrete Wavelet Transform [C]//Proceedings of the IEEE International Conference on VLSI Design.Washington:IEEE Computer Society,2014: 348-352.
[6]HUANG C T,TSENG P C,CHEN L G.Flipping Structure:an Efficient VLSI Architecture for Lifting-based Discrete Wavelet Transform[J].IEEE Transactions on Signal Processing,2004,52(4):1080-1089.
[7]MOHANTY B K.Memory Efficient Modular VLSI Architecture for High throughput and Low-Latency Implementation of Multilevel Lifting 2-D DWT[J].IEEE Transactions on Signal Processing,2011,59(5):2072-2084.
[8]HU Y S.A Memory-efficient High-throughput Architecture for Lifting-based Multi-level 2-D DWT [J].IEEE Transactions on Signal Processing,2013,61(20):4975-4987.
[9]张学全,陈晓敏.CCSDS中二维整数小波变换的FPGA实现方法[J].半导体光电,2012,33(5):747-751.ZHANG Xuequan,CHEN Xiaomin.FPGA Base Design of Integer 2D-DWT in CCSDS Standard[J].Semiconductor Optoelectronics,2012,33(5):747-751.
[10]唐垚,曹剑中,刘波,等.航天器图像压缩小波变换的FPGA设计[J].计算机科学,2010,37(9):261-263.TANG Yao,CAO Jianzhong,LIU Bo,et al.FPGA Design of Wavelet Transform in Spatial Aircraft Image Compression [J].Computer Science,2010,37(9):261-263.
[11]WU B F,LIN C F.A High-performance and Memory-efficient Pipeline Architecture for the 5/3 and 9/7 Discrete Wavelet Transform of JPEG2000 Codec[J].IEEE Transactions on Circuits and Systems for Video Technology,2005,15(12):1615-1628.
[12]LAI Y K,CHEN L F,SHIH Y C.A High-performance and Memory-efficient VLSI Architecture with Parallel Scanning Method for 2-D Lifting-based Discrete Wavelet Transform [J].IEEE Transactions on Consumer Electronics,2009,55(2):400-407.
[13]WANG C,WU Z L,CAO P,et al.An Efficient VLSI Architecture for Lifting-based Discrete Wavelet Transform[C]// Proceedings of the IEEE International on Multimedia and Expo.Piscataway:IEEE,2007:1575-1578.
[14]DARJI A D,LIMAYE A.Memory Efficient VLSI Architecture for Lifting-based DWT[C]//Proceedings of the IEEE 57th Midwest Symposium on Circuits and Systems.Picataway:IEEE,2014:182-192.
[15]SUN Q,JIANG J,ZHU Y X.A Reconfigurable Architecture for 1-D and 2-D Discrete Wavelet Transform[C]// Proceedings of the 21st Annual International Conference IEEE Symposium on Field-Programmable Custom Computing Machines.Washington:IEEE Computer Society,2013:81-84.
(编辑:齐淑娟)
Highly efficient VLSI architecture for DWT with low-storage implementation
DONG Mingyan,LEI Jie,WANG Keyan,LI Yunsong
(State Key Lab.of Integrated Service Networks,Xidian Univ.,Xi’an 710071,China)
Abstract:With the gradual increase in image resolution of the spacecraft camera,it is highly required to figure out the problem how to process a huge amount of image data on board at a high speed.As a solution,the CCSDS proposes a space-oriented image-coding standard.For the sake of high image-coding performance,it adopts wavelet transformation as a method of image data transformation.However,wavelet transformation contains multi-level data processing,which causes more computational time consumption and more memory utilization.In order to solve this problem,we propose a highly efficient VLSI architecture for DWT with low-storage.By revising the traditional lifting structure and employing time-multiplex data processing strategy to perform the second and third level of wavelet transformation by the same logic module,the usage of logic resource is reduced with no sacrifice on speed.Using a small amount of on-chip memory instead of off-chip memory to save certain parts of DWT coefficients and sending the coefficients in a specific sequence to entropy coder timely,the off-chip memory for storage of DWT coefficients is no longer required.The proposed VLSIarchitecture of DWT is already implemented on the Xilinx FPGA XC4VSX55,which can achieve a high performance,in terms of data throughput,reaching 95.91MPixels/s.
Key Words:image processing;discrete wavelet transform(DWT);field programmable gate array (FPGA);very large scale integration(VLSI)
通讯作者:雷 杰(1981-),男,副教授,E-mail:jielei@mail.xidian.edu.cn
作者简介:董明岩(1990-),男,西安电子科技大学硕士研究生,E-mail:962383739@qq.com.
基金项目:国家优秀青年基金资助项目(61222101);国家自然科学基金资助项目(61301287,61301291);高等学校学科创新引智计划资助项目(B08038);中央高校基本科研业务费专项资金资助项目(K5051301043)
收稿日期:2014-11-11 网络出版时间:2015-05-21
doi:10.3969/j.issn.1001-2400.2016.02.007
中图分类号:TN919.81
文献标识码:A
文章编号:1001-2400(2016)02-0035-06
网络出版地址:http://www.cnki.net/kcms/detail/61.1076.TN.20150521.0902.004.html
