一种基于特征映射的中文专家消歧方法
2016-05-04余正涛郭剑毅毛存礼杨秀贞
潘 霄,余正涛,郭剑毅,毛存礼,杨秀贞
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 智能信息处理重点实验室,云南 昆明 650500)
一种基于特征映射的中文专家消歧方法
潘 霄1,2,余正涛1,2,郭剑毅1,2,毛存礼1,2,杨秀贞1
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 智能信息处理重点实验室,云南 昆明 650500)
针对中文专家页面特点,以及用于消歧的基准专家页面中信息涵盖不全的问题,该文提出一种基于特征映射的中文专家消歧方法。首先,采用条件随机场模型,从基准专家页面和待消歧页面中提取出所定义的12维人物属性特征,并利用最大熵分类模型,结合已有消歧结果训练出各属性特征的权重;然后,针对某个专家的基准页面,计算待消歧页面与该页面的相似度,根据设定的阈值判断该页面是否单独成类,若不是单独成类,则利用特征映射,扩充该页面的属性特征,结合模糊聚类方法,得到与该页面为一类的页面。在“自然语言处理”及“机器学习”领域进行中文专家消歧实验,结果表明提出的方法能有效对中文专家页面进行消歧。
中文专家消歧;属性特征;特征映射;模糊聚类
1 引言
由于专家重名和表示方式多样性的问题,导致以某一专家姓名进行检索将返回多个不属于该专家的页面,为准确区分出该专家的专家页面,须对获取到的页面进行专家消歧。通常专家消歧可以转化成专家页面的聚类问题进行解决。当前的专家消歧方法主要有以下几类:一是基于特征向量相似度的聚类消歧方法,如Wang[1]利用网页内容向量空间模型对专家页面进行聚类消歧,Bollegala[2]提出利用上下文中的关键性短语相似度实现专家聚类消歧;二是基于属性相似度的聚类消歧方法,如Cohen[3]提出通过计算属性对间相似度实现专家聚类消歧, 周晓等[4]针对人名消歧的任务,提出基于人物属性互斥与非互斥的两阶段人名消歧的方法;三是基于特定关联关系的聚类消歧方法, 如郎君[5]提出的基于社会网络的人名重名消解, 利用页面标题和上下文片断中人名的共现关系构建社会网络,并通过聚类的方法实现消歧。Tang[6]提出的结合专家论文属性和论文合作关系的聚类消歧方法,选取文章标题、摘要、作者等作为特征,结合发表论文合作关系,通过基于 HMRF(Hidden Markov Random Field)的聚类方法,进行专家聚类消歧。
采用聚类的方法进行专家消歧,通常是以某个确定属于专家的页面作为基准页面,通过聚类,将与该基准页面聚为一类的页面挑选出来,作为专家页面。因此,消歧的正确性很大程度上依赖于基准页面中的信息,然而,由于页面信息量的限制以及信息更新速度较快,导致基准页面对专家信息涵盖不全,从而影响消歧的准确率。现有方法没有充分考虑基准页面的信息扩充,为解决这一问题,本文提出一种基于特征映射的中文专家消歧方法。
2 基于特征映射的中文专家消歧方法思想
基于特征映射的中文人名消歧方法的主要思想是先从基准页面和待消歧页面中提取出用于表征基准页面和待消歧页面的特征,并通过已有消歧结果得到各维特征的权重,然后,针对基准页面,利用基准页面属性与待消歧页面属性的相关性将基准页面与待消歧页面用带权重的特征表征成向量,计算待消歧页面与该基准页面的相似度,根据设定的阈值判断该基准页面是否单独成类,若不是单独成类,则寻找与该基准页面相似度最大的页面,利用特征映射的方法扩充该基准页面的特征向量,并将此页面归入该基准页面类,重复这一扩充过程,直至基准页面的特征向量不再被扩充为止,则将该基准页面与剩余的页面进行聚类,得到和该基准页面为一类的页面。该方法具体流程描述如下:
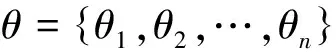
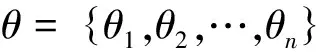
(2) 计算θi与ω的相似度σi,i=1,2,…,n;
(4) 利用σ*对应的召回页面θk的特征扩充ω的特征,扩充后的基准页面为ω*;
(5)ω=ω*,θ=θ-θk,θk归为ω类,判断此时的ω是否还能再扩充,若能扩充,则转步骤(2),若不能,则进入下一步;
(6) 将ω和θ进行聚类,得到θ中和ω聚为一类的页面,流程结束。
3 基于特征映射的中文专家消歧方法
3.1 特征提取与特征加权
由于中文专家页面信息中所包含的内容主要是对人物的描述,因此,选取人物相关属性作为表征基准页面与待消歧页面的特征,12维人物属性特征定义如下,分别为人名、地名、组织机构名、职称、性别、民族、学历、毕业院校、出生日期、研究方向、获奖荣誉、承担项目。提取这些人物属性实际上是一个人物属性实体的提取问题,由于条件随机场模型[7]不需要很严格的独立性假设,可以融入丰富的特征,故其在实体抽取中被广泛运用且具有较高的准确率,因此,本文采用条件随机场模型进行人物属性实体的提取。然而每维属性特征所起的作用是不同的,还需要得到各维特征的权重,本文利用已有消歧结果,将各维特征作为分类模型的特征函数,对已知消歧结果的页面进行所属专家标记,训练出分类模型特征函数的权重,从而得到各维特征的权重,由于最大熵模型[8]可以任意加入对最终分类有用的特征,而不用顾及它们之间的相互影响,并且最大熵模型能够较为容易地对多分类问题进行建模,基于以上优点,本文使用最大熵模型训练各维特征的权重。
3.2 基准页面与待消歧页面的向量表征
在获得各维属性特征的权重后,为将基准页面与待消歧页面用向量表征出来,则需利用基准页面的属性与待消歧页面属性的相关性,也即以某个基准页面为基础,将待消歧页面的属性与该基准页面对应维的属性进行匹配,若某一维匹配成功,则该维的值为所匹配的属性的权重值,若匹配不成功,则该维的值为0,各个待消歧页面的12维属性依次与基准页面进行匹配,直至把所有待消歧页面都表征为匹配结果对应的向量;基准页面的向量表征,则是根据其提取属性特征的情况而定,对于提取不到的属性特征,则对应维度的值为0,对于能够提取出的属性特征则其对应维度的值为该属性的权重值。针对属性特征的匹配,本文采用基于《知网》的词语相似度计算方法进行匹配,参照刘群在“基于《知网》的词汇语义相似度的计算”中提出的方法[9],综合考虑节点的共性信息和个性信息,给出如式(1)所示的义原语义相似度计算公式:
(1)

(2)
其中,S11,S12,…,S1n为W1的n个概念,S21,S22,…,S2m为W2的m个概念。两个概念语义表达式的整体相似度为式(3)。
(3)
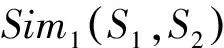
3.3 基准页面特征映射
在将基准页面和待消歧页面表征成属性权重值构成的向量后,需要通过特征映射的方法,借助待消歧页面属性特征对基准页面的属性特征进行扩充。首先是计算所有待消歧页面与基准页面的相似度,本文通过常用的余弦相似度来进行相似度的计算,公式如式(4)所示。
(4)
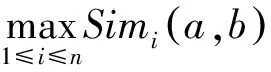
3.4 模糊聚类分析
3.4.1 模糊相似矩阵构建
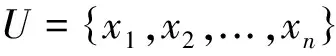
(5)
3.4.2 确定最佳聚类阈值

引入F统计量,如式(6)所示。

(6)
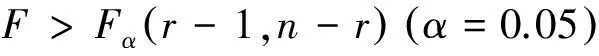
4 实验结果及分析
4.1 专家消歧数据集准备
对于实验数据集的准备,本文采用以下方式进行:首先从万方平台及与“自然语言处理”和“机器学习”领域相关的会议网站选取“自然语言处理”和“机器学习”领域专家各150人,利用GoogleAPI通过检索专家的姓名收集搜索引擎返回的前10个页面形成实验数据集,并选择10个页面中检索排序位于第一的页面作为该专家的基准页面。数据集基本情况如表1所示。
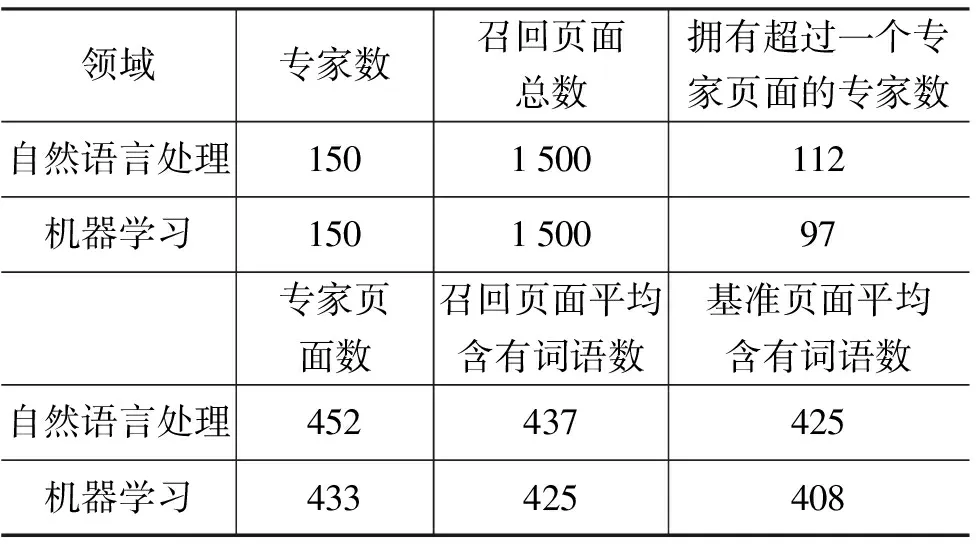
表1 专家消歧实验数据集
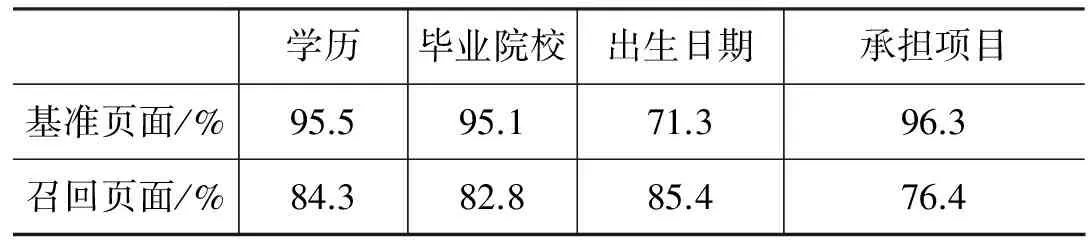
由表1中可以看出,以专家姓名进行检索所召回的页面中,有一半以上的页面并不属于该专家,通过对数据集的分析,发现这些不属于专家的页面中,一部分是属于与专家同名的人,一部分是与专家不相关且非描述人物信息的页面,可见在通过搜索引擎返回专家页面的过程中进行专家消歧具有重要的意义。同时,在数据集中,基准页面平均含有词语数略低于召回页面平均含有词语数,说明在包含的信息量上,有的基准页面可能要比召回页面少。为进一步说明基准页面涵盖信息不全的问题,本文对基准页面和召回页面中能够提取出各维特征的页面占各自页面集总数的比例分别进行了统计,结果如表2所示。
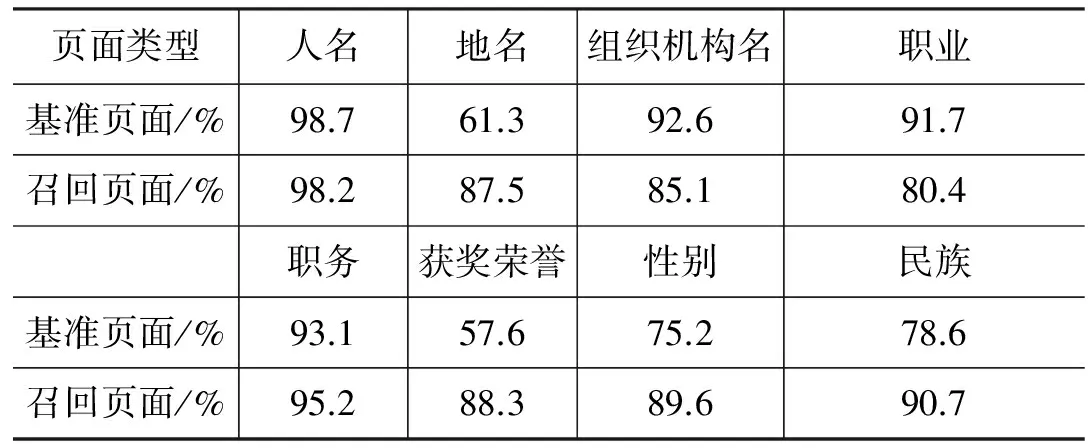
表2 含有各维特征页面所占比例
续表
由表2中可以看出,对于人名和职务这两类属性特征,基准页面和召回页面大多都能涵盖,而对于组织机构名、职业、学历、毕业院校和承担项目这五类属性特征则基准页面涵盖面更广一些,但是,对于地名、获奖荣誉、性别、民族、出生日期和承担项目这六类属性特征的涵盖面基准页面却不如召回页面,属性特征涵盖面的不足很可能导致消歧错误的产生。
4.2 不同特征专家消歧对比实验
为验证利用提出的12维人物属性特征进行专家消歧的效果,在不进行基准页面特征映射的条件下,实验将使用12维属性特征作为特征进行聚类的方法与文献[2]中利用关键词相似度实现专家聚类消歧的方法进行了对比,但在这一实验中先忽略各维特征的重要程度,即不赋权重,实验的评价指标为召回率(R),准确率(P)和F值(F),公式如(7)~(9)所示。
(7)
(8)
(9)
实验结果如表3所示。
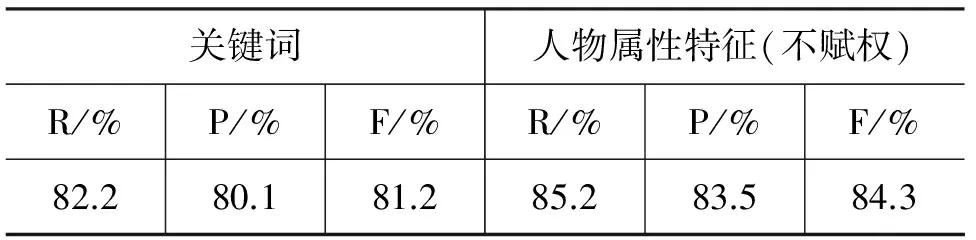
表3 不同特征消歧对比实验
从表3中数据可以看出,使用人物属性作为特征的聚类效果优于使用词频作为特征的聚类效果,所以,本文定义的12维人物属性特征能有效进行专家消歧。
以上实验是在各维属性特征等权重的条件下进行的,也即忽略了各维属性特征对消歧效果产生影响的程度不同,为证明对各维特征赋权重后的效果,实验将利用已知消歧结果得到的各维特征权重赋予各维特征,并和等权重的效果进行对比,对比结果如表4所示。
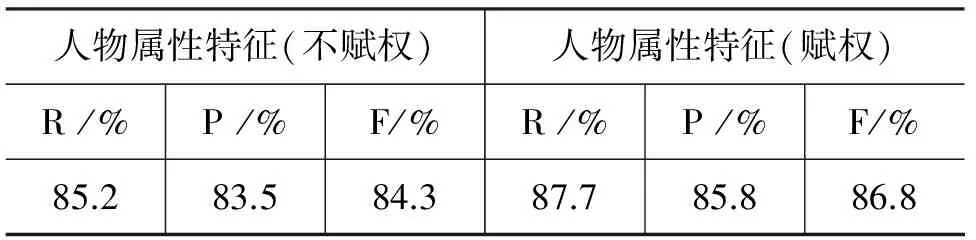
表4 权重因素对比实验
从表4中数据可以看出,对属性特征赋权重后的效果优于不赋权重的效果,可见考虑各维特征的对消歧的不同影响程度能有效提高消歧的召回率,准确率和F值。
4.3 特征映射对比实验
为验证特征映射方法的效果,将本文提出的基于特征映射的方法与文献[4]中的两阶段人名消歧方法和文献[6]中的基于HMRF的聚类消歧方法进行了对比,实验结果如表5所示。
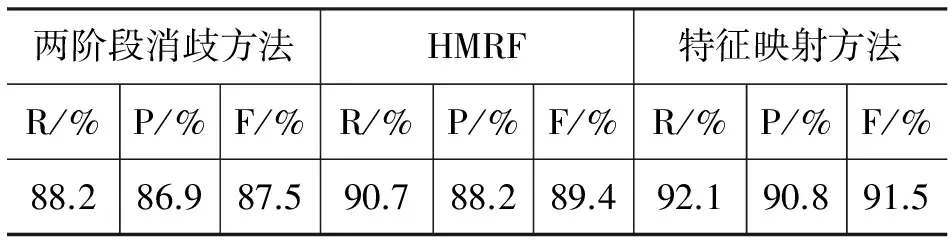
表5 特征映射对比实验
从表5中数据可以看出,相比于不进行特征映射的方法,基于特征映射的方法使得召回率、准确率和F值均有提高。
为验证数据集规模对消歧效果的影响,将本文提出的基于特征映射的方法与两阶段人名消歧方法和基于HMRF的聚类消歧方法在不同规模数据集上达到的F值进行了对比,实验结果如图1所示。
从图1中可以看出,随着数据集规模的不断扩大,特征映射方法的F值在0.915附近波动,未呈现出下降趋势,且在不同的数据集规模下,特征映射方法的F值都高于其他两种方法, 说明在不同的数据集规模下特征映射方法都能取得较好的效果,但其他两种不进行特征映射的方法的F值却随着数据集规模的扩大而下降,这是因为数据集规模越大,其基准页面涵盖信息不全的问题就越凸显,所得到的消歧效果就会越差。
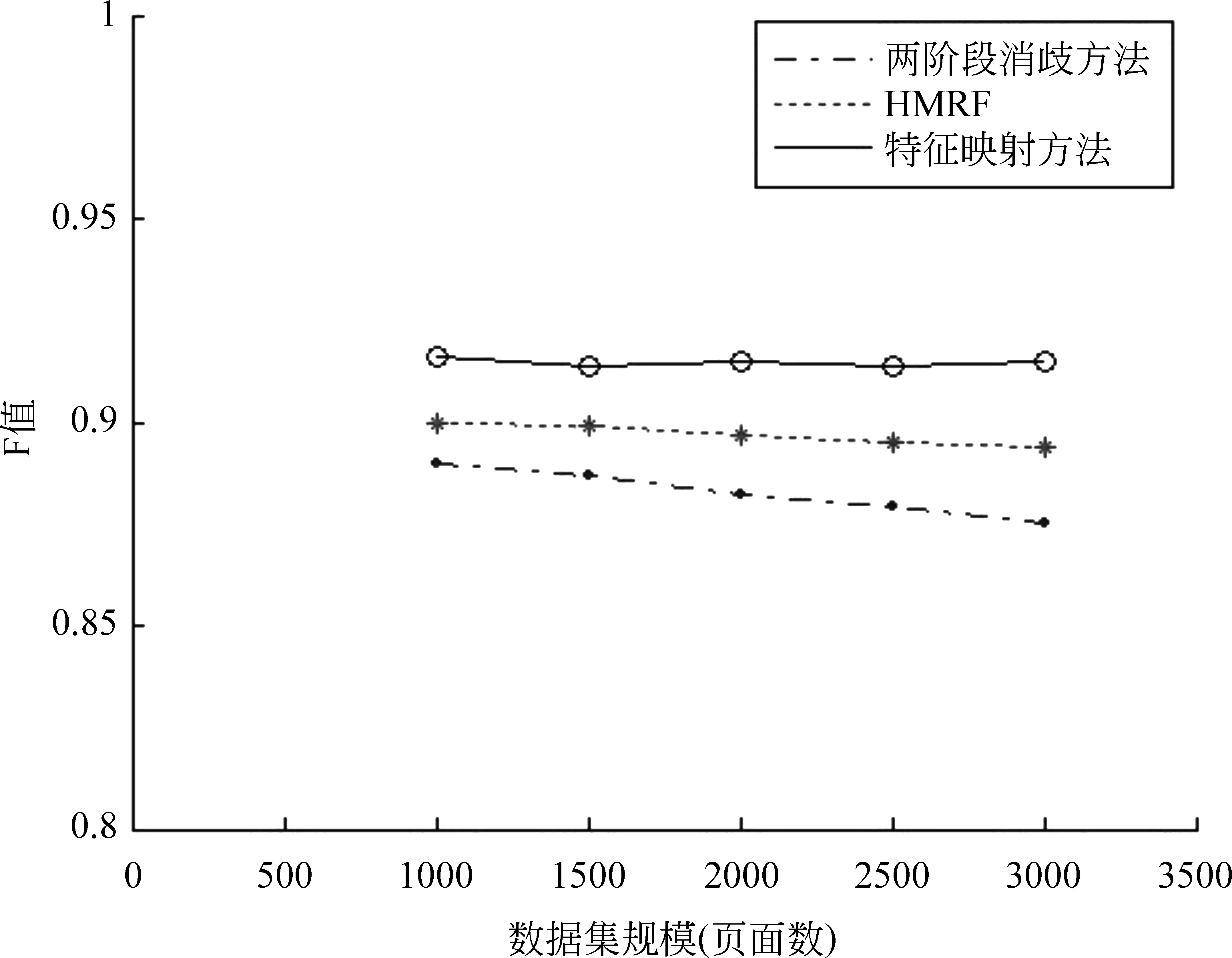
图1 不同数据集规模对比试验
5 结语
针对中文专家页面特点,以及用于消歧的基准专家页面中信息涵盖不全的问题,本文提出一种基于特征映射的中文专家消歧方法。该方法充分考虑了用于消歧的特征的选取,以及各维特征权重的确定,并且利用召回页面的特征对基准页面特征进行了扩充,实验证明所提出的方法取得了较好的消歧效果。下一步的工作,将考虑如何利用中文专家页面间的关联关系进行专家消歧,进一步提高消歧的效果。
[1] Houfeng Wang, Zheng Mei. Chinese Multi-document Person Name Disambiguation [J]. High Technology Letters, 2005, 11(3): 280-283.
[2] Bollegala D, Matsuo Y,Ishizuka M. Disambiguating Personal Names on the Web Using Automatically Extracted Key Phrases[J]. Frontiers in Artificial Intelligence and Applications, 2006: 553-557.
[3] Cohen W, Ravikumar P, Fienberg S. A Comparison of String Distance Metrics for Name-matching Tasks[C]//Proceedings of the IJCAI Workshop on Information Integration on the Web, Acapulco, Mexico, 2003: 73-78.
[4] 周晓, 李超, 胡明涵, 等. 基于人物互斥属性的中文人名消歧[C]// 第六届全国信息检索学术会议, 2010.
[5] 郎君, 秦兵, 宋巍等. 基于社会网络的人名检索结果重名消解[J]. 计算机学报, 2009,(7): 1365-1375.
[6] Jie Tang, Limin Yao, Duo Zhang. A Combination Approach to Web User Profiling[J]. ACM Transactions on Knowledge Discovery from Data , 2010, 5(1): 2.
[7] Lafferty J, McCallum A, Pereira F. Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]// Proceedings of the 18th International Conference on Machine Learning, Wil-liamstown, USA, 2001: 282-289.
[8] Liyan Zhang. A Chinese Word Segmentation Algorithm Based on Maximum Entropy[C]// Machine Learning and Cybernetics (ICMLC), 2010 International Conference on. IEEE, 2010(3): 1264-1267.
[9] 刘群, 李素建. 基于《 知网》 的词汇语义相似度计算[J]. 中文计算语言学, 2002, 7(2): 59-76.
[10] Botía J F, Isaza C, Kempowsky T, et al. Automaton based on Fuzzy Clustering Methods for Monitoring Industrial Processes[J]. Engineering Applications of Artificial Intelligence, 2012, 4(26): 1211-1220.
A Chinese Expert Disambiguation Method Based on Feature Mapping
PAN Xiao1,2, YU Zhengtao1,2, GUO Jianyi1,2, MAO Cunli1,2, YANG Xiuzhen1
(1. School of Information Engineering and Automation, Kunming University of Science and Technology, Kunming, Yunan 650500, China;2. Key Laboratory of Intelligent Information Processing, Kunming University of Science and Technology,Kunming, Yunan 650500, China)
A Chinese expert page disambiguation method based on feature mapping is proposed according to the characteristics of the Chinese expert page. Firstly, with the help of CRFs model, 12 predefined character attributes are extracted from the standard and the candidate page, and their weights are decided by a ME classifier. Then, the page similarity is calculated to decide if the candidate page attributes should be appended Experiments on NLP and ML expert pages show the effectiveness of the proposed method in disambiguation.
Chinese experts page disambiguation; attributive character; feature mapping; fuzzy clustering
1003-0077(2016)02-0026-06
2013-01-08 定稿日期: 2014-01-05
国家自然科学基金(61175068);云南省软件工程重点实验室开放性基金(2011SE14);国家教育部留学回国人员科研启动基金。
TP391
A
