基于全局优化的中文事件时序关系推理方法
2016-05-04李培峰朱巧明
郑 新,李培峰,朱巧明
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006; 2. 江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
基于全局优化的中文事件时序关系推理方法
郑 新1,2,李培峰1,2,朱巧明1,2
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006; 2. 江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
近年来,越来越多的研究关注事件时序关系,但大多数工作集中于提高事件关系分类器的性能,忽略了分类器错误所造成的事件关系间不一致的问题。该文利用了一个全局优化的推理模型来解决这一问题,将事件时序关系全局优化看成整数线性规划问题,使用了自反性、传递性、同指性、时序连接词、事件类型对等多个约束条件。实验结果表明,该文的全局推理方法与分类器相比,F1值提高了3.56%。
事件;时序关系;推理
1 引言
事件时序关系识别是篇章理解研究的重要组成部分,广泛应用于信息抽取、文本摘要等多个自然语言处理应用领域。例如,在系列化的新闻报道中,了解各个事件之间发生的时序关系,可以更好地对文章内容进行归纳总结,方便人们快速获取有效信息;在文景转换系统中,需要知道文中事件发生的先后顺序,以此来排列动画场景,保证整个故事情节的连续性。
随着TimeBank等语料库的出现,机器学习方法逐渐应用到这一研究任务。给定一个事件对,根据它们的特征集合训练出一个分类器来预测事件对的时序关系。这种方法由于它每次只考虑一个单一事件对的时序关系,却忽略了同一文章中事件之间的联系。这种局部性方法往往会存在以下的缺点: 分类结果有时会违反时序关系集合中的逻辑约束条件。图1中,(a)表示的是一个分类器识别的关系图,其中事件e1发生在事件e2之前,事件e2发生在事件e3之前,而事件e1却发生在事件e3之后——很明显这是会产生一个时序逻辑关系矛盾。
为了消除分类器带来的这种矛盾,Chambers[1]、Do[2]等人提出一个全局推理模型,即使用传递性约束条件(e1 before e2 + e2 before e3 → e1 before e3),来优化事件对之间的关系,最终得到一个最优的事件关系图。然而,经过传递性约束限制后,得到的并不一定是正确的事件关系图,图1中,(b)、(c)、(d)均可能是(a)经过全局优化后的结果,而正确的结果只能是其中一个。因此,只有保证其中两个事件对关系的正确性,才能正确优化第三个事件对的关系。
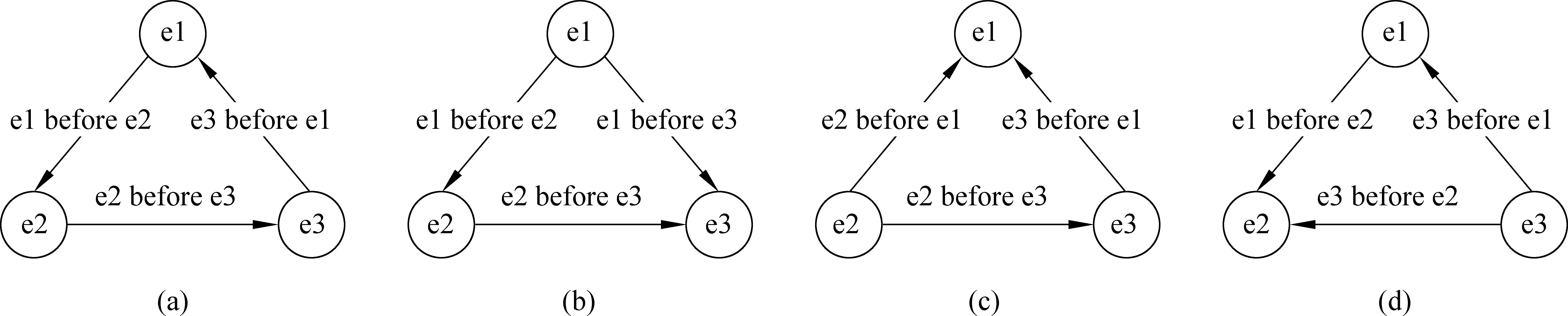
图1 事件时序关系图注: (a) 表示分类器识别的时序关系图; (b)、(c)、(d)分别为全局优化后的可能结果
本文的主要贡献是: 为了保证传递性约束限制后结果的正确性,本文在Do[2]的基础上进一步提出了同指关系、时序连接词及事件类型对等多个约束条件。这些约束条件的加入,使得全局推理模型的实验性能有了显著提高。
本文组织结构如下: 第二节介绍相关工作;第三节讲述本文实验的基准系统;第四节提出了一种全局优化的推理方法来提高事件时序关系识别;第五节是实验结果与分析;最后是对本文工作的总结及下一步工作展望。
2 相关工作
目前,事件时序关系的研究绝大多数针对英文。早期研究采用基于规则方法,随着TimeML(Time Markup Language)标注体系的发展以及TimeBank[3]语料库的出现,统计机器学习方法开始广泛应用于事件时序关系识别方面。
Mani[4]等在TimeML语料库和Opinion语料库的基础上,提出了事件属性特征(称为“完美特征”): 事件类别、体态、形态、极性、时态等。Chambers[5]在Mani的基础上,进一步拓展了特征空间,引入了词法、句法等特征,使得分类器的结果有了很大的提高。D’Souza[6]等较全面地总结了事件时序关系识别的相关特征,并进一步提出了有关篇章级别的特征,使系统性能有了一定的提高。Ng[7]等借助修辞结构理论、篇章关系及话题文本分割等篇章结构方面的技术在很大程度上提高了事件时序关系识别的性能。
中文时序关系的研究相对较少,绝大多数的研究集中在事件与时间之间的关系。王昀[8]提出了一个基于转换的时间-事件映射关系的方法。林静[9]介绍了汉语文本中时间关系的抽取方法,并分别从时间与时间、时间与事件和事件与事件三个方面研究了时间关系的抽取与计算。事件映射关系的方法,并取得了较高的实验性能。仲兆满[10]提出了一种事件关系表示模型,并做了一个简单的事件关系推理实验。Cheng[11-12]借鉴TimeML的标注准则,构建了一个中文事件时序关系的语料库,并通过事件的类型来识别中文事件时序关系。谭红叶[13]总结了当前时间关系识别研究进展,并探讨了研究中存在的问题和未来研究的重点。王风娥[14]采用最大熵分类器识别句子内的事件时序关系,实验中使用了一些有助于提高同句内事件时序关系的语言特征。
近几年运用全局推理方法来提高事件时序关系识别的研究工作已有很多。Chambers[1]与Do[2]的做法类似,都是在有监督机器学习方法的基础上,运用了整数线性规划方法来提高实验性能。而Yoshikawa[15]使用的则是马尔可夫推理模型来提高机器学习的方法。Denis[16]通过用区间端点表示事件和时间的方法来控制Chambers[1]等人的联合推理方法的复杂性,并提出了一个图的分解方法来简化图的优化问题。然而,Chambers[1]、Do[2]等人的全局优化方法所使用的约束条件较为单一,仅包含反转性、传递性等规则。
绝大多数研究使用的是TimeBank语料库,也有少数人使用的是ACE语料库*http://www.ldc.upenn.edu/Projects/ACE/docs/Chinese-Events-Guidelines_v5.5.1.pdf(如Do[2]、Ng[7]等),而这两种语料库的标注规则却大有不同。ACE语料库中标注的事件是一个具体发生的事情,往往是一个短语或一句话,并用触发词来表示该事件,而TimeBank语料库则是将大部分动词、动名词都标注为事件。因此,ACE语料库适用于信息抽取、问答系统等领域,TimeBank语料库则更适用于文景转换系统等研究。
此外,由于TimeBank语料库中只标注了同句及邻句中部分事件之间的关系,Chambers[17]对TimeBank语料库中部分语料重新标注了同句及邻句中所有事件之间可能的时序关系,构建了一个稠密的事件时序关系语料库。与之类似,Do[2]使用的也是一个稠密的事件时序关系语料库。本文所采用的实验语料库则是标注了同一篇文章中任意两个事件之间的时序关系。
3 基准系统
本文的基准系统采用有监督的机器学习方法构造一个事件时序关系分类器,即给定一个事件对,构造一个分类器能够预测它们之间属于哪一种时序关系。具体表示如式(1)。
(1)
其中,ei,ej分别表示第i个和第j个事件。
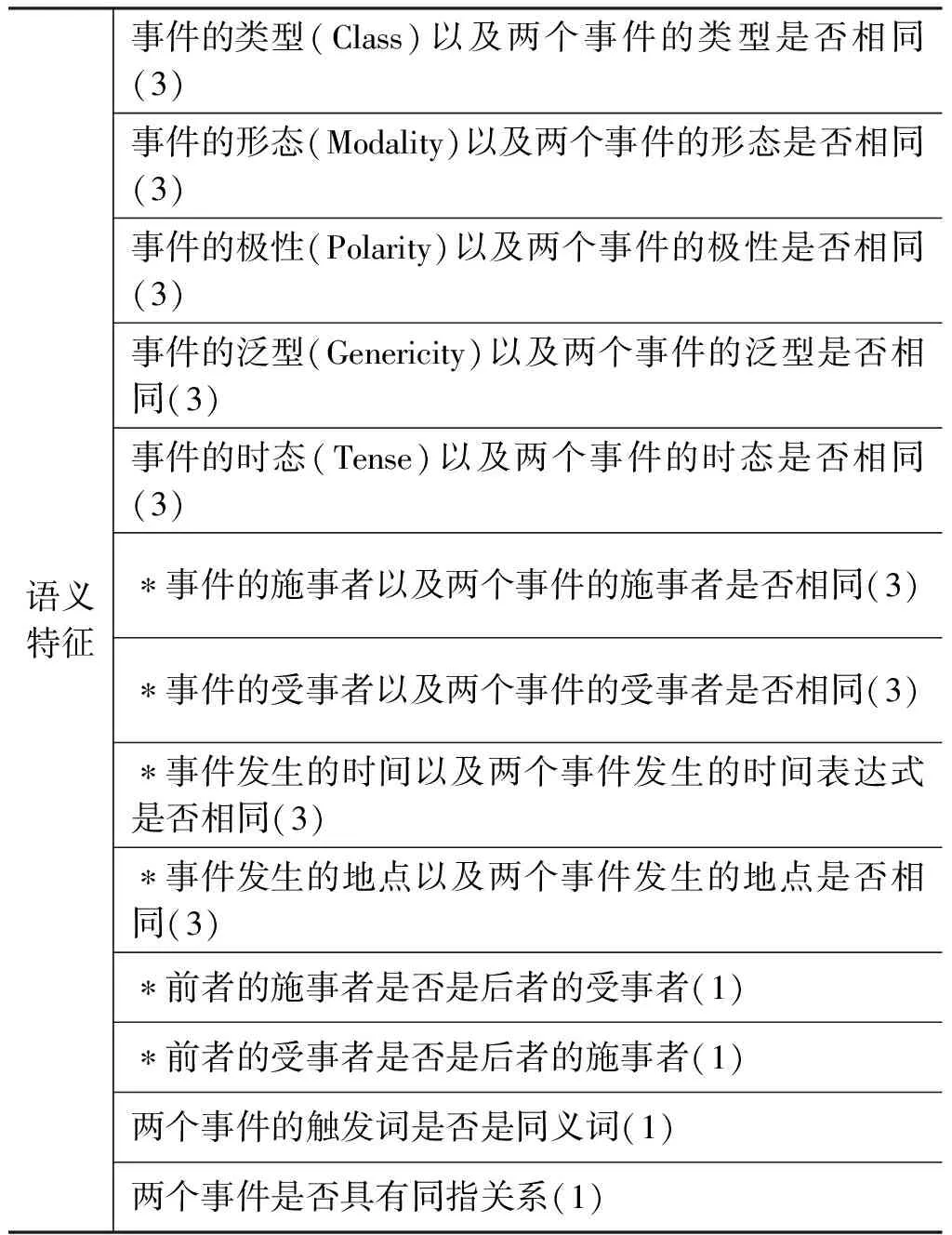
为了训练这样的分类器,本文定义了一个特征空间,包括词法特征、句法特征、语义特征等,如表1所示。这些特征一部分是英文时序关系识别用到的特征[2,4-5],另一部分是根据中文语言特征总结的一些有用的特征(用*标记)。

表1 时序关系识别特征集合
续表
注: 表中(4)、(2)、(1)等表示对应的特征数目。
4 全局推理模型
由于分类器独立地对每一对事件关系进行分类,忽略了事件对之间的联系,因而有可能会产生事件关系对之间的逻辑性矛盾;而已有的全局优化方法仅使用了自反性和传递性约束条件,并不能保证优化后结果的正确性,如图1所示。因此,本文在全局优化策略的基础上,提出多个有效地约束条件,进一步提升事件时序关系识别性能。
本文提出的全局推理模型分为两步: 1)训练一个时序关系分类器(见第三节);2)利用分类器的预测概率以及约束条件,转化成最优化问题,最终得到一个全局最优的结果。本文使用整数线性规划(Integer Linear Programming)法来解决这一问题。
4.1 目标函数
目标函数被定义为事件时序关系分类器预测概率的对数之和,如式(2)所示。
(2)
其中,x(eiej,r)是一个二元变量,取值为1时,表示ei与ej之间的关系为r;p(eiej,r)表示分类器CE-E预测ei与ej之间的关系为r的概率;ε={e1,e2,…,en}表示同一篇文章中所有事件的集合;εε={(ei,ej)∈ε×ε|ei∈ε,ej∈ε,i≠j}表示同一篇文章中的事件对集合;R={before,after,overlap,unknown}表示时序关系集合。
本文的目标函数是概率p的对数之和,而不是直接求概率p之和,因为取对数后,变量x的权重更离散化(p的取值为[0,1], 而logp取值为[-,0]),从而更有利于区分事件对之间属于哪一种时序关系。
4.2 基本约束条件
1) 唯一性
式(3)保证x(eiej,r)是一个二元变量,它的取值只能是0或1。式(4)是为了确保ei与ej之间只存在一种时序关系,即其中一种关系取值为1,其余均为0。
例如,relation(ei,ej)只能是{before,after,overlap,unknown}四种关系中的一种。
2) 自反性
如果已知relation1(ei,ej),那么很容易就知道relation2(ej,ei)。例如,若e1beforee2,则必有e2aftere1。具体可表示为式(5)。
(5)

3) 传递性
由(Bramsen[18],Chambers[1],Do[2])等人的工作可知,事件时序关系之间存在传递闭包的性质。如果已知relation1(ei,ej)且relation2(ej,ek),那么可以推出relation3(ei,ek)。即relation1(ei,ej)+relation2(ej,ek)⟹relation3(ei,ek)。如式(6)所示。
(6)
其中(r1,r2,r3)∈{(b,b,b),(a,a,a)}。
例如,before(ei,ej)+before(ej,ek)⟹before(ei,ek)。
4.3 扩展约束条件
1) 同指性
① 若ei与ej互为同指关系,则必有overlap(ei,ej)。
② 若已知ei与ej互为同指关系且relation1(ei,ek),则有relation1(ej,ek)。
以上两条性质可表示为式(7)和式(8)。
例如,已知e1beforee2且e3为e1的同指事件,则必有e3beforee2。
2) 时序连接词
如果两个相邻事件之间存在特定的时序连接词,那么就可以根据该连接词确定它们之间的时序关系。例如,ei与ej之间存在时序连接词“之后”,那么就有eibeforeej。
若某时序连接词在训练集中出现三次以上,则加入到时序连接词词表中;然后,使用开发集筛选词表中的时序连接词;最终得到一个最优的时序连接词词表,部分时序连接词见表2。
公式化为式(9)所示。
(9)
其中,conj为时序连接词,Conj_List为时序连接词词表,r1为conj对应的时序关系。
例如,一些巴勒斯坦人从清真寺出来后在老城狮子门处同以军警发生了冲突。由于事件“出来”与“冲突”之间存在时序连接词“后”,那么很容易判断事件“出来”发生在事件“冲突”之前。
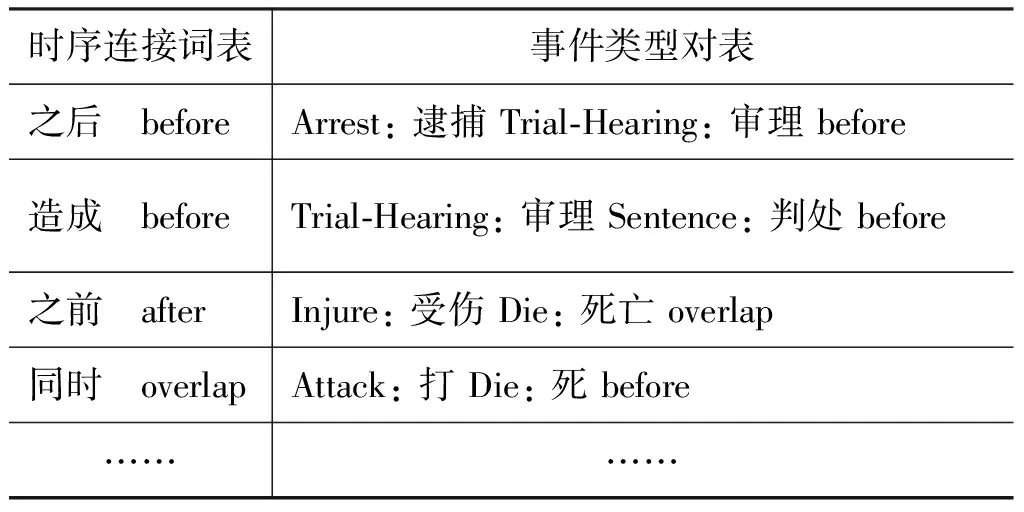
表2 部分时序连接词词表与事件类型对表
3) 事件类型对
一篇文章中通常围绕某个话题来阐述,随着话题的推演与发展,与之相关的事件也不断发生与结束。某些特定类型的事件对之间往往具有特定的时序关系,例如,Arrest,逮捕→Trial-Hearing: 审理→Sentence: 判处。
若某事件类型对在训练集中出现五次以上且均被分为同一种关系,则加入到事件类型对列表中;然后,使用开发集筛选列表中的事件类型对,最终得到一个最优的事件类型对列表(表2)。
公式化为式(10)所示。
(10)
其中,typei,typej分别为ei,ej的类型,r1为对应的时序关系。
例如,法院今天公开开庭审理了一起杀人案。…… 据悉,法院择日对此进行宣判。司法类话题中不同类型的事件一般是按序进行的,只有先审理才能进行宣判,即事件“审理”通常发生在事件“宣判”之前。
5 实验
本节中,首先介绍本文的实验设置及基准系统,然后给出详细的实验结果与分析,最后讨论与英文相关工作的异同。
5.1 实验设置与基准系统
本文实验所用的语料共包含271篇新闻文本,其中103篇取自ACE 2005中文语料库,其余168篇语料的原文选自Chinese TreeBank 6.0 和Chinese Gigaword语料库,并遵循ACE 2005中文语料库的标注规则,进行事件标注。然后人工标注了每篇文本中任意两个事件之间的时序关系(本文将事件时序关系分为四种: before,after,overlap,unknown)。语料最终共标注了2 291个事件,20 632对事件关系。
本文的实验语料由两位标注者完成,其中before、after和overlap三类标注结果的Kappa值均达到0.7,由于unknown关系歧义性较大,Kappa值仅0.5。对于标注不一致的事件关系对,邀请第三位标注者共同商量决定最终的结果。
本文实验中随机选取187篇语料作训练集,30篇作开发集,54篇作测试集,采用常用的准确率(Precision)、召回率(Recall)及F1值作为评价准则。基准系统中使用最大熵分类器;在推理阶段,使用Gurobi Optimizer构建全局推理模型。
本文将第三节中提到的有监督机器学习方法作为实验的一个基准系统。此外,为了与全局推理方法对比,本文实现了一个强规则推理方法。即利用第四节中的约束规则来修正违反约束规则的时序关系。具体操作为: 首先,将测试集分为可信集与不可信集两部分,即设定一个阀值K*本文实验中,经开发集调参后,K取0.9,若事件对(ei,ej)的预测概率大于K时,则被分到可信集中,否则被分到不可信集中;然后,把可信集中的事件对关系当作已知条件,根据约束条件,推出不可信集中的事件对关系。
5.2 实验结果与分析
实验结果如表3所示,其中,“Do”是在本文数据集上重现Do[2]原文中的方法。不过,Do[2]还将事件与时间表达式关系的识别结果作为一个约束条件,本文未涉及此研究内容,故表3中Do与本文方法的实验结果均未使用此约束条件。

表3 各方法实验性能比较
首先,比较本文的全局推理方法与基准系统的实验结果,可以看出,本文的全局推理方法的F1值比基准系统高了3.56%。这表明使用全局约束条件的全局优化模型处理事件时序关系识别问题的有效性。本文采用McNemar检验法对实验结果进行显著性检验,求得P值<0.000 1,因此,本文方法较基准系统有显著性提升。
然后,比较本文全局推理方法与强规则推理方法的实验结果发现,基于全局优化推理方法要明显优于强规则的局部推理方法,而强规则推理方法较基准系统其F1值仅提高了0.91%。经分析实验数据发现,强规则推理方法根据预测概率划分可信集与不可信集,而可信集中仍然含有大量的错误样例。当把错误样例作为已知条件进行推理时,这不仅不能够正确推出不可信集中样例的结果,甚至会将原本分类器分类正确的样例推理成错误的。因而,强规则推理方法的性能提升相对较小。
整数线性规划是一种寻找一组最优解使目标函数最大化且满足一系列限制约束条件的数学推理方法。全局优化推理方法综合考虑了各事件关系对之间的联系,而不是将每个事件对单独来处理。加入有效地约束条件后,在保证了部分事件关系对正确的情况下,尽可能的修正错误的事件关系对,使得最终的结果达到最优,因此,性能提升较大。
最后,比较本文方法与Do方法的实验性能。本文方法是在Do的基础之上,加入了同指关系、时序连接词及事件类型对多个约束条件,F1值比Do高了1.96%。这表明,本文提出的几个约束条件非常有效。
另外,约束条件的不同对全局推理模型的性能有着很大的影响,表4给出了不同约束条件之间对ILP的贡献度。
表4中,贡献度最大的是传递性约束条件,其次是同指关系约束条件,因为这二者是多个事件对之间的约束条件,充分利用了事件对之间的联系,而“连接词”、“事件类型对”则是针对单个事件对的约束条件。然而,“自反性”约束条件的贡献度为0,经分析分类器的实验结果发现,互为逆反关系的两个事件对要么都被正确分类,要么都被分到同一个错误类别中去,因此“自反性”并没有对实验性能产生影响。
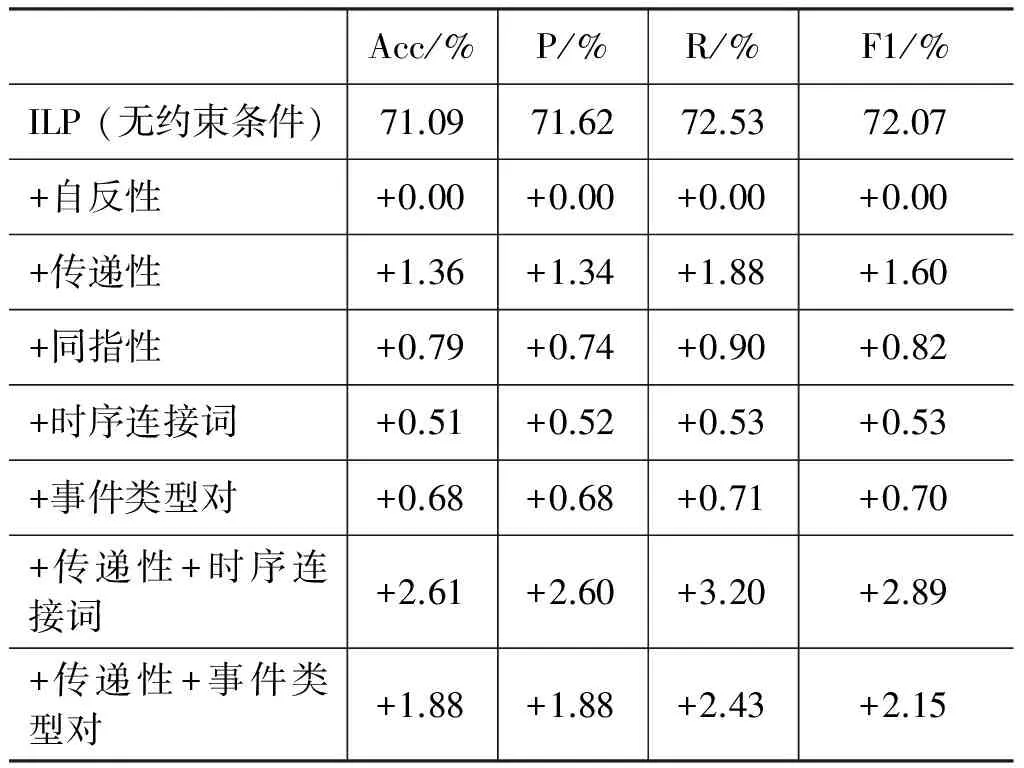
表4 各约束条件对实验性能的贡献度
此外,“传递性”+“时序连接词”的贡献度要大于它们各自贡献度之和(2.89>1.60+0.53),因为“时序连接词”的加入提升了“传递性”中部分事件关系对的正确率,从而保证了其余事件关系对能够被正确约束。而“传递性”+“事件类型对”的贡献度却小于它们各自贡献度之和(2.15<1.60+0.70),主要原因在于特定类型的事件对之间的关系不如含有时序连接词的事件对关系明确,例如,一个攻击类事件发生后造成受伤类事件,可能之后又发生了攻击类事件,再如审理之后对被告判决,可能由于被告不服,会再次审理。
本文所用约束条件中,“自反性”、“传递性”和“同指性”为强规则约束条件,理论上是完全正确的;而“时序连接词”和“事件类型对”仅仅是在绝大多数情况下成立的,并不能保证完全正确,例如,“近几起冲突共造成10人死亡”中,虽有时序标志词“造成”,但事件“冲突”的发生时间是一个时间段,所以“冲突”与“死亡”是overlap关系。若“时序连接词”和“事件类型对”与强规则约束条件发生冲突时,则以强规则约束条件为准;若“时序连接词”与“事件类型对”发生冲突时,以“时序连接词”为准,因为“时序连接词”的正确率相对较高。
5.3 讨论
本文实验所采用的时序关系分类方法与文献[2]中类似,实验语料均为ACE新闻语料,并且都使用全局推理方法,但是,本文实验改进了目标函数,并引入了更多更有效地约束条件。
两次实验均表明,全局推理方法能有效提高事件时序关系识别性能。文献[2]中,实验结果表明,在仅使用自反性、传递性等少量约束条件时,全局推理方法较机器学习方法就有很大的提升。而本文实验在仅使用文献[2]中的约束条件时,提升的结果并不是很高。其原因主要有: 一、本文中的机器学习分类方法实验性能要远高于文献[2]的实验性能(F1值高了将近15%);二、文献[2]所用语料较为稀疏,仅仅20篇文档, 324个事件,实验结果偶然性较大,而本文实验语料包含271篇文档,2 291个事件。
此外,本文提出了几个约束条件使实验性能有很大的提高,这几个约束条件的加入,保证了传递闭包性质的有效性。因此,有效地约束条件能更好地提升全局推理模型的性能。
6 总结与展望
本文提出了一个全局推理方法来进一步提升中文事件时序关系识别的性能。特别是在构建全局推理模型时,提出了同指关系、时序连接词及事件类型对多个有效约束条件。实验结果表明,本文的全局推理方法在有监督的机器学习方法的基础上有了较大的提高,且本文提出的几个约束条件起到了很大的作用。
在下一步研究工作中,一方面提高“时序连接词”和“事件类型对”的正确率;另一方面引入更多的语义和篇章知识等信息加入到全局推理模型中,进一步提高系统的性能。
[1] Nathanael Chambers, DanJurafsky. Jointly Combining Implicit Constraints Improves Temporal Ordering[C]//Proceedings of the Conference on EMNLP, 2008: 698-706.
[2] Quang Xuan Do, Wei Lu, Dan Roth. Joint Inference for Event Timeline Construction[C]//Proceedings of the 2012 Joint Conference on EMNLP, 2012: 677-687.
[3] James Pustejovsky, Patrick Hanks, Roser Sauri, et al. The TimeBank Corpus[C]//Proceedings of the Corpus Linguistics, 2003: 647-656.
[4] Inderjeet Mani, Marc Verhagen, Ben Wellner, et al. Machine Learning of Temporal Relations [C]//Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics, 2006: 753-760.
[5] Nathanael Chambers, Shan Wang, DanJurafsky. Classifying Temporal Relations between Events [C]//Proceedings of the 45th Annual Meeting of the ACL on Interactive Poster and Demonstration Sessions, 2007: 173: 176.
[6] Jennifer D’Souza, Vincent Ng. Classifying Temporal Relations with Rich Linguistic Knowledge[C]//Proceedings of NAACL-HLT, 2013: 918-927.
[7] Jun-Ping Ng, Min-YenKan, Ziheng Lin, et al. Exploiting Discourse Analysis for Article-Wide Temporal Classification[C]//Proceedings of EMNLP, 2013: 12-23.
[8] 王昀, 苑春法. 基于转换的时间-事件关系映射[J]. 中文信息学报, 2004, 18(4): 23-30.
[9] 林静, 苑春法. 汉语时间关系抽取与计算[J]. 中文信息学报, 2009, 23(5): 62-67.
[10] 仲兆满, 刘宗田, 周文, 付剑锋. 事件关系表示模型[J]. 中文信息学报, 2009, 23(6): 56-60.
[11] Y C Cheng, M Asahara, Y Matsumoto. Constructing a Temporal Relation Tagged Corpus of Chinese based on Dependency Structure Analysis[C]//Proceedings of Temporal Representation and Reasoning, In 14th International Symposium on Temporal Representation and Reasoning, 2007: 59-69.
[12] Y C Cheng, M Asahara, Y Matsumoto. Use of Event Types for Temporal Relation Identification in Chinese Text[C]//Proceedings of IJCNLP, 2008: 31-38.
[13] 谭红叶, 郑家恒, 梁吉业. 时间关系识别研究进展[J]. 中文信息学报, 2011,, 25(5): 44-52.
[14] 王风娥, 谭红叶, 钱揖丽. 基于最大熵的句内时间关系识别[J]. 计算机工程, 2012, 38(4): 37-39.
[15] Katsumasa Yoshikawa, Sebastian Riedel. Jointly Identifying Temporal Relations with Markov Logic[C]//Proceedings of the 47th Annual Meeting of the ACL and the 4th IJCNLP of the AFNLP, 2009: 405-413.
[16] Pascal Denisand Philippe Muller. Predicting globally-coherent temporal structures from texts via endpoint inference and graph decomposition[C]//Proceedings of the Conference on IJCAI, 2011: 1788-1793.
[17] Nathanael Chambers, Taylor Cassidy, Bill McDowell, et al. Dense Event Ordering with a Multi-Pass Architecture[C]//Proceedings of the Transactions of the Association for Computational Linguistics, 2014: 273-284.
[18] PhilipBramsen, Pawan Deshpande, Yoong Keok Lee, et al. Inducing Temporal Graphs[C]//Proceedings of the 2006 Conference on EMNLP, 2006: 198-198.
Global Inference for Temporal Relations Between Chinese Events
ZHENG Xin1,2, LI Peifeng1,2, ZHU Qiaoming1,2
(1. School of Computer Science and Technology, Soochow University, Suzhou,Jiangsu 215006,China; 2. Key Lab of Computer Information Processing Technology of Jiangsu Province, Suzhou, Jiangsu 215006, China)
In recently years, more and more studies are devoted to temporal relations between events, with a focuse on improving pairwise classifiers, ignoring the obvious inconsistent problems in the global space of events when misclassifications occur. In this paper, we use a global inference model to resolve such problem bytreating temporal relations recognition as Integer Linear Program. We use many constraints, such as reflexivity, transitivity, event coreference, temporal conjunctions, pairs of event types, etc. The experimental results show that the global inference model outperformed the local classifiers by 3.56% in F1.
event; temporal relation; inference

郑新(1990—),硕士研究生,主要研究领域为自然语言处理,中文信息处理。E⁃mail:358581959@qq.com李培峰(1971—),博士,教授,主要研究领域为自然语言处理,中文信息处理,Web信息处理和嵌入式系统。E⁃mail:pfli@suda.edu.cn朱巧明(1963—),博士,博士生导师,主要研究领域为自然语言处理,中文信息处理,Web信息处理和嵌入式系统。E⁃mail:qmzhu@suda.edu.cn
1003-0077(2016)05-0129-07
2014-02-29 定稿日期: 2015-03-30
国家自然科学基金(61472265);国家自然科学基金(61331011);江苏省前瞻性联合研究项目(BY2014059-08)
TP391
A
